本篇内容主要讲解“Spark Shuffle和Hadoop Shuffle有哪些区别”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Spark Shuffle和Hadoop Shuffle有哪些区别”吧!
Shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。其在MapReduce中所处的工作阶段是map输出后到reduce接收前,具体可以分为map端和reduce端前后两个部分。
在Shuffle之前,也就是在map阶段,MapReduce会对要处理的数据进行分片(split)操作,为每一个分片分配一个MapTask任务。接下来map会对每一个分片中的每一行数据进行处理得到键值对(key,value)此时得到的键值对又叫做“中间结果”。此后便进入reduce阶段,由此可以看出Shuffle阶段的作用是处理“中间结果”。
由于Shuffle涉及到了磁盘的读写和网络的传输,因此Shuffle性能的高低直接影响到了整个程序的运行效率。
我们先放一张图,下图说明了二者shuffle的主要区别:
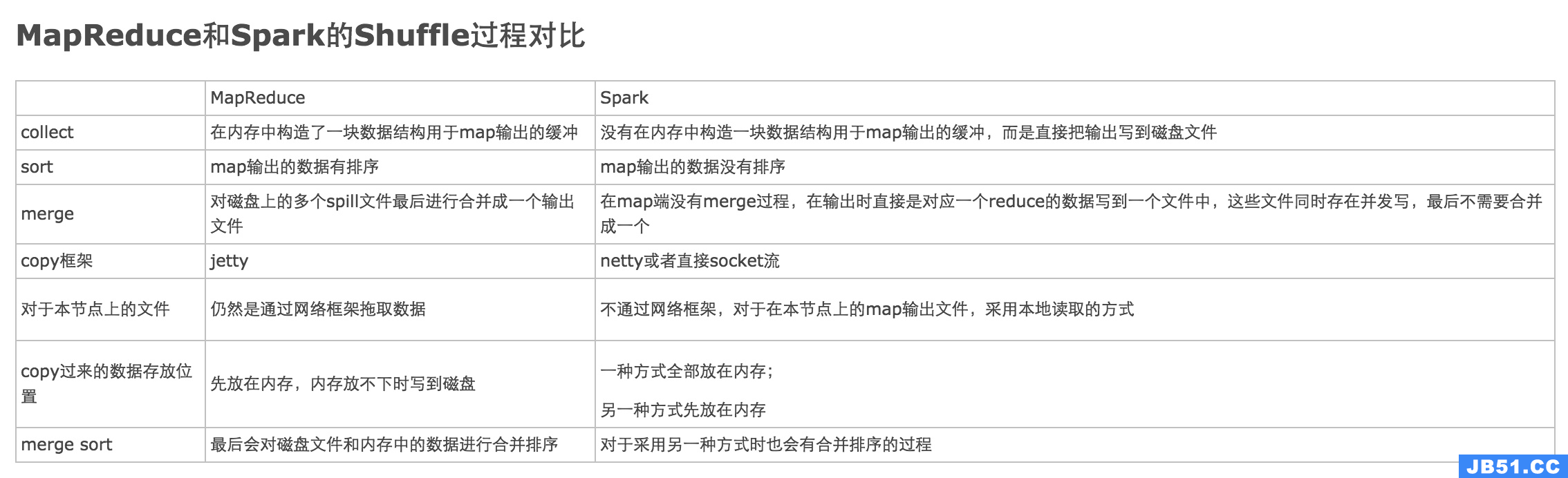
MapReduce Shuffle
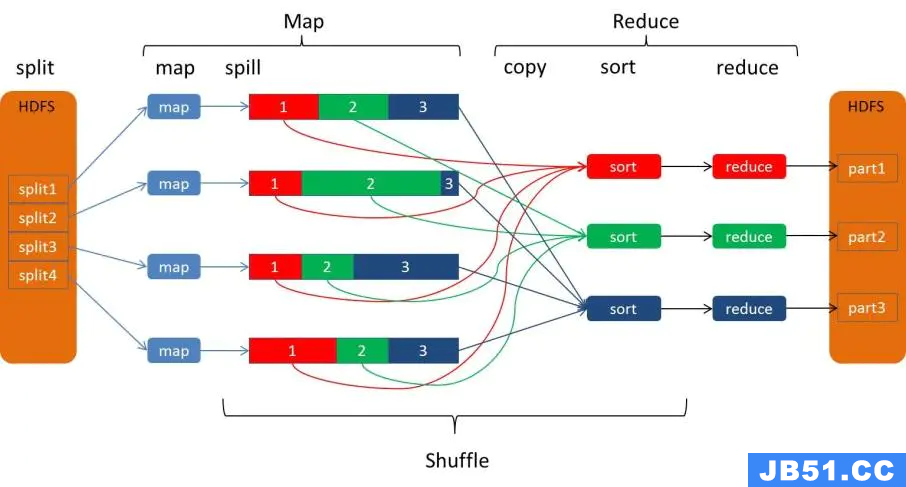
我们在《大数据哔哔集20210107》中详细讲解过MapReduce的shuffle过程:
在map task执行时,它的输入数据来源于HDFS的block,当然在MapReduce概念中,map task只读取split。Split与block的对应关系可能是多对一,默认是一对一。
在经过mapper的运行后,我们得知mapper的输出是这样一个key/value对: key是“hello”, value是数值1。因为当前map端只做加1的操作,在reduce task里才去合并结果集。这个job有3个reduce task,到底当前的“hello”应该交由哪个reduce去做呢,是需要现在决定的。
分区(partition) MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。 一个split被分成了3个partition。
排序sort 在spill写入之前,会先进行二次排序,首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序。partition的目是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner(如果设置了的话),combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。
溢写(spill) Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中, 缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。 当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。 这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8。 将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,MapReduce任务结束后就会被删除)。
合并(merge) 每个Map任务可能产生多个spill文件,在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个文件。这个操作就叫merge(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。一个map最终会溢写一个文件。 至此,Map的shuffle过程就结束了。
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
copy 首先要将Map端产生的输出文件拷贝到Reduce端,但每个Reducer如何知道自己应该处理哪些数据呢?因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),**所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。**每个Reducer会处理一个或者多个partition,但需要先将自己对应的partition中的数据从每个Map的输出结果中拷贝过来。
merge Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。
这里需要强调的是:
merge阶段,也称为sort阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归并排序。
merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。
当copy到内存中的数据量到达一定阈值,就启动内存到磁盘的merge,即第二种merge方式,与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。这种merge方式一直在运行,直到没有map端的数据时才结束。然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
reduce 不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。至于怎样才能让这个文件出现在内存中,参见性能优化篇。 然后就是Reducer执行,在这个过程中产生了最终的输出结果,并将其写到HDFS上。
Spark Shuffle
我们在之前的文章《Spark性能优化总结》中提到过,Spark Shuffle 的原理和演进过程。
Spark在DAG阶段以宽依赖shuffle为界,划分stage,上游stage做map task,每个map task将计算结果数据分成多份,每一份对应到下游stage的每个partition中,并将其临时写到磁盘,该过程叫做shuffle write。
下游stage做reduce task,每个reduce task通过网络拉取上游stage中所有map task的指定分区结果数据,该过程叫做shuffle read,最后完成reduce的业务逻辑。
下图中,上游stage有3个map task,下游stage有4个reduce task,那么这3个map task中每个map task都会产生4份数据。而4个reduce task中的每个reduce task都会拉取上游3个map task对应的那份数据。

< 0.8 hashBasedShuffle 每个map端的task为每个reduce端的partition/task生成一个文件,通常会产生大量的文件,伴随大量的随机磁盘IO操作与大量的内存开销M * R
0.8.1 引入文件合并File Consolidation机制 每个executor为每个reduce端的partition生成一个文件E*R
0.9 引入External AppendOnlyMap combine时可以将数据spill到磁盘,然后通过堆排序merge
1.1 引入sortBasedShuffle 每个map task不会为每个reducer task生成一个单独的文件,而是会将所有的结果写到一个文件里,同时会生成一个index文件,reducer可以通过这个index文件取得它需要处理的数据M
1.4 引入Tungsten-Sort Based Shuffle 亦称unsafeShuffle,将数据记录用序列化的二进制方式存储,把排序转化成指针数组的排序,引入堆外内存空间和新的内存管理模型
1.6 Tungsten-sort并入Sort Based Shuffle 由SortShuffleManager自动判断选择最佳Shuffle方式,如果检测到满足Tungsten-sort条件会自动采用Tungsten-sort Based Shuffle,否则采用Sort Based Shuffle
2.0 hashBasedShuffle退出历史舞台 从此Spark只有sortBasedShuffle
总结
到此为止,我们已经把二者的原理完完整整的讲了一遍。最后,总结引用ITStar总结过的二者的不同精简要点版本:
Hadoop Shuffle:通过Map端处理的数据到Reduce端的中间的过程就是Shuffle.
Spark Shuffle:在DAG调度过程中,stage阶段的划分是根据shuffle过程,也就是存在ShuffleDependency宽窄依赖的时候,需要进行shuffle,(这时候会将作业Job划分成多个stage;并且在划分stage的时候,构建shuffleDependency的时候进行shuffle注册,获取后续数据读取所需要的shuffleHandle),最终每一个Job提交后都会生成一个ResultStage和若干个ShuffleMapStage.
shuffle过程排序次数不同
Hadoop Shuffle过程中总共发生3次排序,详细分别如下:
第一次排序行为:在map阶段,由环形缓冲区溢出到磁盘上时,落地磁盘的文件会按照key进行分区和排序,属于分区内有序,排序算法为快速排序.
第二次排序行为:在map阶段,对溢出的文件进行combiner合并过程中,需要对溢出的小文件进行归档排序,合并,排序算法为归并排序.
第三次排序行为:在map阶段,reduce task将不同map task端文件拉取到同一个reduce分区后,对文件进行合并,排序,排序算法为归并排序.
spark shuffle过程在满足shuffle manager为sortshuffleManager,且运行模式为普通模式的情况下才会发生排序行为,排序行为发生在数据结构中保存数据内存达到阀值,再溢出磁盘文件之前会对内存数据结构中数据进行排序;
spark中sorted-Based Shuffle在Mapper端是进行排序的,包括partition的排序和每个partition内部元素进行排序,但是在Reducer端没有进行排序,所有job的结果默认情况下不是排序的.Sprted-Based Shuffle 采用 Tim-Sort排序算法,好处是可以极为高效的使用Mapper端的排序成果完成全局排序.
shuffle 逻辑流划分
Hadoop是基于文件的数据结构,Spark是基于RDD的数据结构,计算性能要比Hadoop要高。
Shuffle Fetch后数据存放位置
Hadoopreduce 端将 map task 的文件拉取到同一个reduce分区,是将文件进行归并排序,合并,将文件直接保存在磁盘上。
SparkShuffle Read 拉取来的数据首先肯定是放在Reducer端的内存缓存区中的,现在的实现都是内存+磁盘的方式(数据结构使用 ExternalAppendOnlyMap),当然也可以通过Spark.shuffle.spill=false来设置只能使用内存.使用ExternalAppendOnlyMap的方式时候如果内存的使用达到一定临界值,会首先尝试在内存中扩大ExternalAppendOnlyMap(内部有实现算法),如果不能扩容的话才会spil到磁盘.
什么时候进行Shuffle Fetch操作
Hadoop Shuffle把数据拉过来之后,然后进行计算,如果用MapReduce求平均值的话,它的算法就会很好实现。Spark Shuffle的过程是边拉取数据边进行Aggregrate操作。
Fetch操作与数据计算粒度
Hadoop的MapReduce是粗粒度的,Hadoop Shuffle Reducer Fetch 到的数据record先暂时被存放到Buffer中,当Buffer快满时才进行combine()操作。Spark的Shuffle Fetch是细粒度的,Reducer是对Map端数据Record边拉取边聚合。
性能优化的角度
Hadoop MapReduce的shuffle方式单一.Spark针对不同类型的操作,不同类型的参数,会使用不同的shuffle write方式;而spark更加全面。
到此,相信大家对“Spark Shuffle和Hadoop Shuffle有哪些区别”有了更深的了解,不妨来实际操作一番吧!这里是编程之家网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
 本篇内容介绍了“Spark通讯录相似度计算怎么实现”的有关知识...
本篇内容介绍了“Spark通讯录相似度计算怎么实现”的有关知识... 本篇内容主要讲解“Spark Shuffle和Hadoop Shuffle有哪些区别...
本篇内容主要讲解“Spark Shuffle和Hadoop Shuffle有哪些区别... 这篇文章主要介绍“TSDB的数据怎么利用Hadoop/spark集群做数...
这篇文章主要介绍“TSDB的数据怎么利用Hadoop/spark集群做数...