HoloClean <strong>HoloClean 实践</strong> 介绍
脏数据和错误数据是数据分析工作的主要瓶颈,数据清理和修复约占数据科学家工作的60%。最近出现一个新的开源项目 HoloClean
,这是一个半自动数据修复框架,依赖于统计学习和推理来修复结构化数据中的错误。HoloClean
建立在弱监督范式的基础上,利用各种信号,包括用户定义的启发式规则(如通用数据完整性约束)和外部词典,来修复错误的数据。
HoloClean 关键特性:
检测和修复错误数据
公司,组织和研究人员收集的数据常常充满错误,错误和不完整的信息,这被称为 脏数据
,这些脏数据对下游应用程序来说可能是一个巨大的障碍。例如,芝加哥市出版的 Food inspections 数据集中的一个片段:

此数据集中的错误包括拼写错误的条目(例如,“芝加哥”拼写为“Cicago”)和相同地址的冲突邮政编码值(例如,芝加哥同一地址的“60608”与“60609”)相对应为异常值关键属性(例如,“Johnnyo’s”而不是“John
Veliotis Sr.”)。
HoloClean 专注于 结构化数据集 ,如上所示。它的目标是识别和修复所有单元格数据,由于其初始 观察值 与其
真实值 不同,而真实值可能是未知的。我们称这些 错误的单元格数据 。鉴于上述情况,数据清理分为两个任务:
数据清理是一种统计学习和推理问题。
HoloClean 将数据清理作为统计学习和推理问题。输入脏数据集的每个单元格与随机变量相关联。如果未检测到相应的单元是错误的,则该随机变量可以具有
固定值 ,或者如果检测到相应的单元是错误的,则该随机变量可以具有 未知值 。HoloClean 使用具有固定值的随机变量作为
训练数据 来学习用于修复错误单元格数据的概率模型,错误单元格数据的随机变量具有未知值。
通过弱监督进行数据清理
在HoloClean中,用户只需要指定高级断言,捕获关于输入数据需要满足的不变量的域专业知识。无需其他监督!
如何有效地训练数据清理的概率模型?与任何其他大规模机器学习问题一样,用户无法负担起迭代具有数百万元组的数据集中的所有单元格来识别错误单元格并建议修复的算力。这便是弱监督的用武之地!
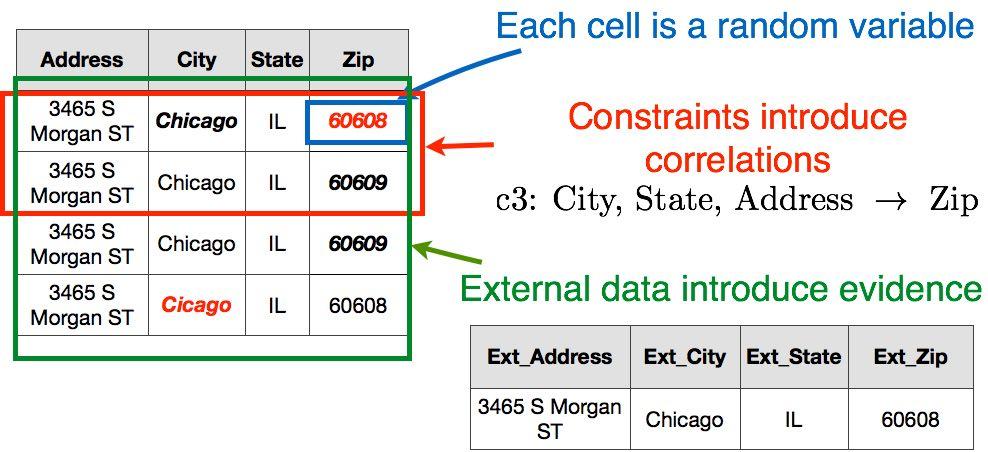
HoloClean 利用各种微弱信号来解决错误检测和数据修复问题:
-
在HoloClean中,用户可以指定拒绝约束(一种常规的完整性约束方法)来检测报告冲突信息的元组。例如,在 Food inspections 数据集中,功能依赖性 City,State,Address→Zip 可用于识别由元组 t1 提供的信息与元组 t2 和 t3 的信息冲突。拒绝约束是捕获用户域专业知识的高级一阶逻辑规则。这些规则可以由用户指定,甚至可以自动发现。
-
用户还可以选择使用外部数据集或词典,并指定高级规则,将可信外部数据集提供的数据与要清理的输入数据集相匹配。
-
HoloClean 使用最先进的异常值检测方法,利用 定量统计数据 查找其值不符合输入数据总体分布特性的单元格。异常值检测自动运行,无需用户输入。
-
拒绝约束引入了随机变量集的相关性。例如,如果元组 t1 和 t2 中单元格 Address,City 和 State 的随机变量具有匹配值,则 t1.Zip 和 t2.Zip 的随机变量应采用相同的值。
-
外部数据确定不同单元格的正确值的先验。例如,在外部数据集中将地址“3465 S Morgan St,Chicago,IL”分配给邮政编码“60608”的事实提供了证据,即最初观察到的邮政编码“60609”是错误的。
-
最后,HoloClean 使用可用的标记数据(通过上述弱信号生成)来学习输入数据的一系列定量统计(例如,对属性值对的共现统计)。定量统计用于形成对应于错误单元的随机变量的分配的先验。
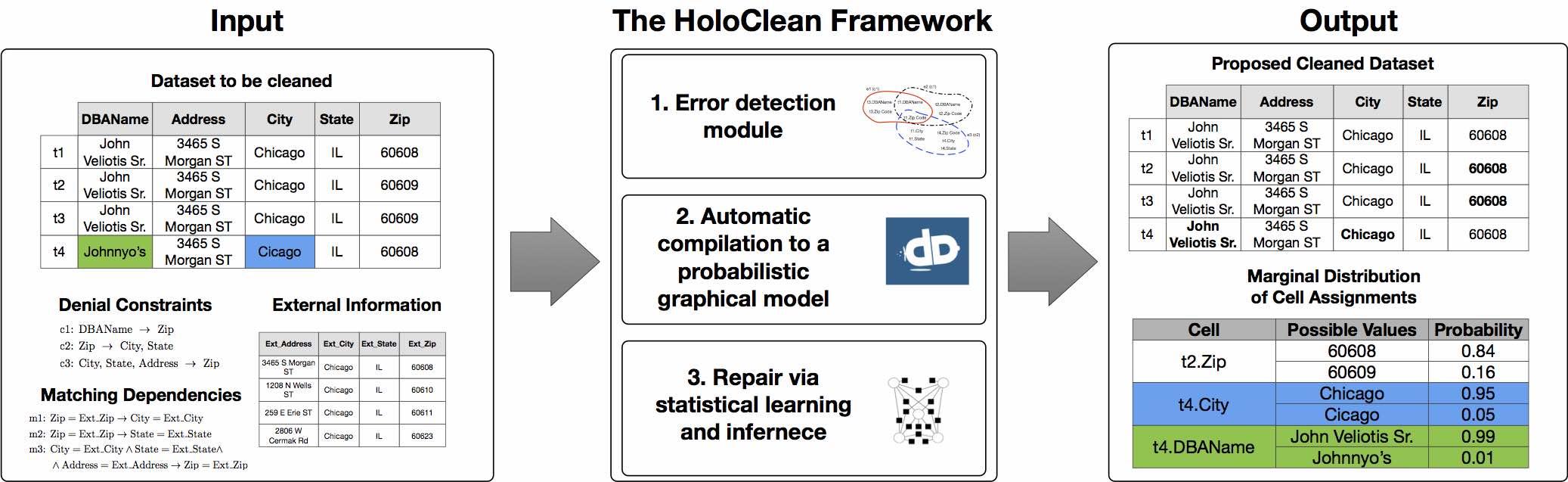
总的来说,HoloClean 是一个数据清理框架,它将脏数据集,完整性约束集合以及可能的外部数据集合作为输入,并形成数据清理的概率模型。HoloClean
以通用推理引擎 DeepDive
为基础,对其模型进行学习和推理。对于每个随机变量,HoloClean
估计其最大后验分配以及其域中值的边际分布。后者可用于以低置信度识别修复并以原则方式请求额外的用户反馈。
HoloClean 实践
在HoloClean 团队的论文中,在各种真实数据集上评估
HoloClean,包括上面提供的 Food inspections 数据集。将 HoloClean
与各种最先进的数据清理方法进行比较。所有现有方法都被设计成单独使用上面给出的每个信号。另一方面,由于概率模型的灵活性和可扩展性,HoloClean
可以在统一的框架中组合所有信号。
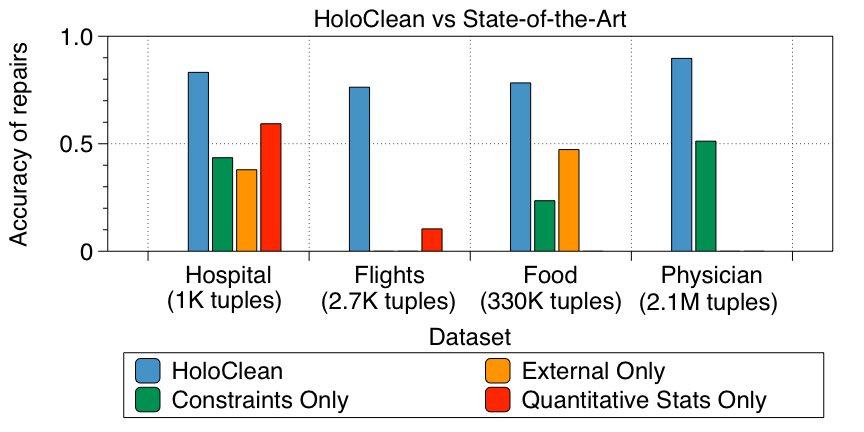
在上面的实验中,HoloClean 发现数据修复的平均精度约为
90%,并且在表现出不同类型错误的各种数据集中平均召回率高于76%。相对于最先进的方法,这使得平均 F1 改善超过2倍。
扩展概率推理
硬约束(例如,完整性约束)导致复杂且不可扩展的修复模型。
HoloClean
的主要技术挑战是对用于数据清理的概率模型进行缩放推理。众所周知,存在约束时的推断是#P-complete。这是因为在推理期间,需要考虑相关的随机变量集的所有可能的联合分配。例如,考虑下图中显示的数据集:

此例中显示的用户指定的完整性约束引入了对应于元组t1和t3的单元的四个随机变量的相关性。如果我们通过将完整性约束转换为一阶逻辑约束来简单地编码这种相关性,我们需要枚举这四个随机变量的所有可能的赋值。很容易看出,对于具有数百万元组的复杂约束和数据清理实例以及具有大域的随机变量,这种简单的方法很难进行扩展。
HoloClean 将对数据单元集的约束放宽到单个数据单元上的简单特征。这给出了仅具有独立随机变量的可扩展修复模型。
为确保可伸缩性,HoloClean 对输入数据集应用完整性约束,以识别提供冲突信息的元组,并使用完整性约束来学习与对应于这些元组的单元格相关联的随机变量的
特征 。HoloClean 生成的最终概率模型对应于 独立随机变量 的 投票模型 ,该 模型
确保分配给不同单元的值的局部一致性。
凭经验发现,当在观察数据集中单元格的正确值时有足够的冗余时,HoloClean的近似模型获得更准确的修复,并且在概率模型中对随机变量域的错误指定更加稳健。
下一步
-
积极探索 HoloClean 轻松模型与其他结构化预测任务之间的联系。具体而言,关注的是由于观察数据的冗余,可以用局部一致的先验替换全局一致约束的情况。事实上,权衡约束特征一直是结构模型概率推理领域的一个开放研究领域。
-
将 HoloClean 与新的数据编程引擎 Snorkel 相结合,为用户提供指定和修改弱信号的交互方式,以构建数据清理模型。
本文翻译自 HoloClean 团队的文章