【前言:本文主要介绍redis,内容丰富且实用,旨在帮助大家对redis有一个更深入、全面的了解以及在实际工作中更好的应用redis,篇幅较长,建议大家收藏,仔细阅读】
Redis简介
Redis是用C语言开发的一个基于内存的、高性能key-value键值对的、开源nosql数据库。目前,redis的key是字符串类型的,但value支持多种数据类型:字符串(string)、哈希(hash)、列表(list)、集合(set)、有序集合(sortedset),通过提供多种键值数据类型来适应不同场景下的存储需求。
Redis应用场景
介绍几种常见的应用:
1. 构建队列系统
可以用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统
2. pub、sub发布订阅构建实时消息系统、消息队列
3. 计数器应用
redis的命令如INCR,DECR都是原子性的,可以通过这些命令来构建计数器系统4.分布式集群架构中session共享
Redis特性
1. 基于内存存储,数据访问速度快,性能好
根据官方提供的测试数据:50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s【数据仅供参考,根据服务器配置会有不同结果】
2. 数据持久化机制
目前支持APF和RDB两种持久化机制,下文会详细阐述
3. 支持集群模式,容量可以线性扩展
注意:Redis3.X开始才支持集群模式
4.支持丰富的数据结构
这一点是相比其他缓存工具如memcache比较鲜明的优势
Redis数据结构
首先强调一点,redis的key是字符串类型,但value支持多种数据类型。关于key的定义,有几点建议:
1.key不要太长,太长不仅消耗内存还会降低查找效率。建议不要超过1024个字节
2.key不要太短,要具有可读性3.在实际项目中,key最好有一个统一的命名规范
下面详细介绍一下redis的value目前支持的数据类型:
>> string类型
字符串是redis支持的最基础的数据类型,它在redis中是二进制安全的,应用最多。
操作redis的string类型数据常用命令:
set(设置)、get(获取)、getset(获取并设置)、del(删除)
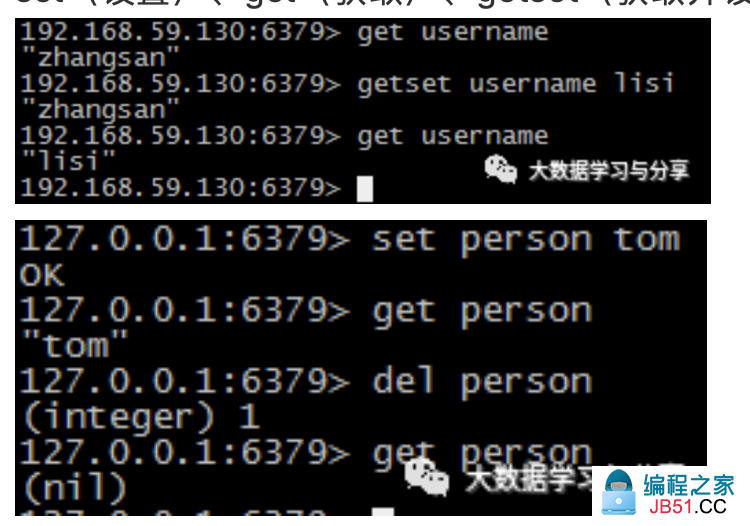
一次性插入或者获取多条数据:
MGET key1 key2
MSET key1 value1 key2 value2 …..
在插入一条string类型数据的同时为它指定一个存活期限:
setex username 10 张三对string类型数据进行增减操作的几个命令:
incr:将指定的key的value原子性的递增1。如果该key不存在,其初始值为0,在incr之后其值为1
decr:将指定的key的value原子性的递减1。如果该key不存在,其初始值为0,在decr之后其值为-1
incrby key increment:将指定的key的value原子性增加increment。如果该key不存在,其初始值为0,在incrby之后,该值为increment
decrby key decrement:将指定的key的value原子性减少decrement,如果该key不存在,其初始值为0,在decrby之后,该值为decrement。
append key value:拼凑字符串。如果该key存在,则在原有的value后追加该值;如果该key不存在,则重新创建一个key/value。
注意:
decr incr decrby incrby 都是原子性操作。进行增减前提是:key可以转换为整型否则报错。相信做过SparkStreaming流式计算统计pv、uv中,中间状态存储会熟悉该特性的应用。
>> list类型
笔者强调一点:redis中list底层是双端链表结构,这个在面试中经常会问。redis为什么这么快,其实不仅仅是因为基于内存存储,底层还多了很多的优化,这只是其中之一,下图是对双端链表的一个图形描述:

常用的操作命令:
lpush:从头部(左边)插入数据
rpush:从尾部(右边)插入数据
lrange key start end:读取list中指定范围的values。start、end从0开始计数;也可为负数,若为-1则表示链表尾部的元素,-2则表示倒数第二个,依次类推…
lpop:从头部弹出一个元素
rpop:从尾部弹出一个元素
rpoplpush:从一个list的尾部弹出一个元素插入到另一个list。原子性操作,没有key2会创建key2,一旦key1的list元素被取完,key1会被清除
llen key:返回指定的key关联的链表中的元素的数量
list数据类型应用案例:消息队列比如有这样一个需求:实现一个任务调度系统==>生产者不断产生任务,放入task-queue排队,消费者不断拿出任务来处理,同时放入一个tmp-queue暂存,如果任务处理成功,则清除tmp-queue;否则,将任务弹回task-queue。笔者这里提供一个实现思路,就不贴代码了,其实就是上述API的简单应用:
1. 生产者将生产的任务lpush进task-queue中
2. 消费者通过rpoplpush将taks-queue中取任务并暂存任务到tmp-queue中
3. 如果任务处理成功,tmp-queue通过rpop清除相应任务;任务处理失败,则rpoplpush将任务从tmp-queue中清除并存入task-queue中
4. 为了避免消费者程序在处理任务失败之后没有及时将rpoplpush失败的任务时就已经挂掉,可以加入一个管理tmp-queque的角色,以便在这种情况时也能将处理失败的任务lpush进task-queue中。
>> hash类型
redis中的hash类型可以看成具有map容器,适合存储值对象的信息。如username、password等。
常用命令:
hset key field value:为指定的key设定field/value对(键值对)
hmset key field value [field2 value2 …]:设置key中的多个filed/value
hincrby key field increment:设置key中filed的值增加increment
hexists key field:判断指定的key中的filed是否存在
>> set类型
无序、无重复元素。和list类型相比,set类型在功能上还存在着一个非常重要的特性,即在服务器端完成多个set之间的聚合计算操作,如并集、交集、差集的计算。由于这些操作均在服务端完成,因此效率极高,而且也节省了大量的网络IO开销。
常用命令:
添加: sadd key values[value1、value2…] [多个value间空格分隔]
删除:srem key members[member1、member2…] 删除set中指定的成员(成员可以是多个)[]
查询:smembers key 查看指定key的set中的数据
判断:sismember key value [判断参数中指定的成员是否在该set中,1表示存在,0表示不存在或者该key本身就不存在。(无论集合中有多少元素都可以极速的返回结果)]
统计set元素个数:scard key [指定key对应的set的元素数]srandmember key:随机返回set中的一个成员
sdiff、sunion、sinter:差集、并集、交集
>> sortedset类型
sortedset中的每一个元素都会有一个分数与之关联,redis正是通过分数来为集合中的元素进行排序,默认正序。注意:sortedset中的数据不能重复,但分数却可以重复。
常用命令:
zadd key score member score2 member2 … :将所有成员以及该成员的分数存放到sorted-set中。如果该元素已经存在则会用新的分数替换原有的分数。返回值是新加入到集合中的元素个数,不包含之前已经存在的元素。(score可以重复,member不可以重复)
zscore key member:返回指定成员的分数
zcard key:获取集合中的成员数量zrem key member[member…]:移除集合中指定的成员,可以指定多个成员
zrange key start end [withscores]:获取集合中脚标为start-end的成员,[withscores]参数表明返回的成员包含其分数。(withscores可选参数)
zrevrange key start stop [withscores]:按照元素分数从大到小的顺序返回索引从start到stop之间的所有元素(包含两端的元素)
Redis事务
首先强调一点,redis2.X是弱事务,redis3.X无事务。
1. 在事务中的所有命令都将会被串行化的顺序执行,事务执行期间,redis不会再为其它客户端的请求提供任何服务,从而保证了事物中的所有命令被原子的执行
2. 和关系型数据库中的事务相比,在redis事务中如果有某一条命令执行失败,其后的命令仍然会被继续执行。
3. 我们可以通过MULTI命令开启一个事务,可以将其理解为关系型数据库的"BEGIN TRANSACTION"语句。在该语句之后执行的命令都将被视为事务之内的操作,最后我们可以通过执行EXEC/DISCARD命令来提交/回滚该事务内的所有操作。这两个Redis命令可被视为等同于关系型数据库中的COMMIT/ROLLBACK语句。
4. 在事务开启之前,如果客户端与服务器之间出现通讯故障并导致网络断开,其后所有待执行的语句都将不会被服务器执行。然而如果网络中断事件是发生在客户端执行EXEC命令之后,那么该事务中的所有命令都会被服务器执行。
5. Append-Only模式时,redis会通过调用系统函数write将该事务内的所有写操作在本次调用中全部写入磁盘。然而如果在写入的过程中出现系统宕机,导致数据丢失。redis服务器会在重新启动时执行一系列必要的一致性检测,一旦发现类似问题,就会立即退出并给出相应的错误提示。此时,我们就要充分利用redis工具包中提供的redis-check-aof工具,该工具可以帮助我们定位到数据不一致的错误,并将已经写入的部分数据进行回滚。修复之后我们就可以再次重新启动redis服务器了
命令解释:
multi:开启事务用于标记事务的开始,其后执行的命令都将被存入命令队列,直到执行EXEC时,这些命令才会被原子的执行,类似于关系型数据库中的:begin transaction ,相当于MySQL的 start transaction
exec:提交事务,类似与关系型数据库中的:commit
discard:事务回滚,类似与关系型数据库中的:rollback
Redis持久化
>> RDB快照
根据一定的配置规则,将内存中的数据快照持久化到磁盘。除了自动的快照方式,也可以通过命令进行快照持久化:
1. save
redis会先阻塞所有客户端的请求,然后将数据同步保存到磁盘
2. bgsave
将数据异步保存到磁盘。通过fork出子进程,父进程继续处理请求,子进程将数据异步保存到磁盘
3. lastsave
返回上次成功将数据保存到磁盘的时间戳
4. shundown
将数据同步保存到磁盘,然后关闭服务

1/10/10000个键被更改是指触发了某些规则(如事务,写,插入等操作)的次数。由于快照方式是在一定间隔时间做一次的,所以如果redis意外宕机的话,就会丢失最后一次快照后的所有修改。
>> AOF
将对redis操作的每一个命令记录在appendonly.aof文件中,应用的较多。
开启方式:在redis.conf中,appendonly yes。
aof方式的缺点:时间久了,appendonly.aof文件会越来越大,在恢复的时候很耗时==>如可能操作了500w次,但最终只是更新了1000个key,即很多命令是冗余的。
可以通过在客户端执行命令bgrewriteaof,将冗余命令进行删除
AOF具体配置方式:
1. 修改redis.conf配置文件 :执行命令vim redis.conf,输入/aof搜索appendonly no
2. 输入命令i进入编辑模式,将appendonly no修改为appendonly yes 保存退出 esc ==>Shift zz或者:wq
3. 把之前的数据删掉dump.rdb 执行命令 rm -rf dump.rdb
4. 启动 ./redis-server redis.conf,查看启动状态 ps -ef | grep redis
5. 输入命令 ll,出现appendonly.aof文件
AOF应用示例:
启动客户端 ./redis-cli,执行命令set a a ,set b b,不小心输入误操作flushall,将所有数据清除了。恢复步骤:
a. 先关闭redis服务器,查看aof文件中的数据
b. 将appendonly.aof中误删除的操作删掉然后保存退出
c. 重新启动redis服务器,然后登陆redis客户端查询还原后的数据
通过上述的介绍会发现,AOF相对RDB持久化更安全,但效率稍微低一些,恢复慢
Redis主从配置
修改redis.conf配置
1)master不需要修改
2)slave修改以下标签
如:#slaveof <masterip> <masterport>
启动服务器时先启动master,通过info命令查看主从服务状态命令。实际生产环境中,仅仅如此配置主从还不行,还要考虑单点故障问题,实现主从容错自动切换,这需要用到哨兵模式。
Redis主从灾难恢复策略
1. master宕机
步骤:
a)修改主从配置文件:redis.conf中的daemonize no改为yes
b)使用命令:redis-cli -p 端口号==》slaveof NO ONE(关掉主从,转为主服务器)
c)等到出问题的服务器修复好后,在修复好的服务器上使用命令slaveof ip port让其变为从,这样数据就可以同步了
2. master和slave同时崩溃
启动服务器后,将备份服务器最新的AOF备份拷贝到master端,启动master,一切完成后,再启动slave(否则在master没有完全启动时启动slave,slave发现master数据比自身还少,会删除掉自身携带的”多余”的数据)
哨兵模式
哨兵通过监控master,如果master无法心跳回应,哨兵进行投票从slave中(如果多个)选出一个master,然后进行容错切换。

哨兵配置
首先介绍几个配置文件:
sentinel.conf:redis哨兵模式配置文件
redis-sentinel:哨兵启动脚本
启动:./redis-sentinel /usr/local/redis-cluster/sentinel.conf
|
port 26379 #端口daemonize yes #后台运行 守护进程
#当前机器监测master名字及端口号,2:当有几台哨兵监控到主机出错后执行主从切换(sentinel做决策的时候需要投赞同票的最少的sentinel的数量) sentinel monitor master1 ip port 2#当哨兵对master执行ping操作时,超过指定时间没有回应即认为master处于(s_down状态)subjectively #down默认30秒 sentinel down-after-milliseconds master1 30000/**failover-timeout 可以用在以下这些方面:1.同一个sentinel对同一个master两次failover之间的间隔时间2.当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据的时间3.当想要取消一个正在进行的failover所需要的时间4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了*/ #sentinel在该配置值内未能完成failover操作(即故障时master/slave自动切换),则认为本次failover失败 sentinel failover-timeout master1 900000#在执行故障转移时,最多可以有多少个从服务器同时对新的主服务器进行同步 sentinel config-epoch master1 0#sentinel auth-pass mymaster 123456#如果你的redis集群有密码 logfile "/usr/local/log/sentinel.log" #当前哨兵模式存放的日志文件 (哨兵模式一旦启动,会在后台修改sentinel.conf文件,所以此时不要去手动修改配置文件了) |
哨兵作用
哨兵监测master状态通过心跳
|
1.不时地监控redis是否按照预期良好地运行2.如果发现某个redis节点运行出现状况,能够通知另外一个进程(例如它的客户端)3.能够进行自动切换。当一个master节点不可用时,能够选举出master的多个slave(如果有超过一个slave的话)中的一个来作为新的master,其它的slave节点会将它所追随的master的地址改为被提升为master的slave的新地址
4.哨兵为客户端提供服务发现,客户端链接哨兵,哨兵提供当前master的地址然后提供服务,如果出现切换,也就是master挂了,哨兵会提供客户端一个新地址 |
Redis安全性
redis.conf文件中添加:requirepass 密码,以后在客户端登录的时候必须得给出密码:./redis-cli.sh 密码。一般公司环境都会设置密码
在redis主从配置中,密码一般相同。如果master设置了密码,slave需要授权master密码,如:#masterauth <master-password>
Redis数据迁移
介绍几种常用的方式:
1.RDB方式
如mini2机器挂掉,将正常运行的机器mini1上的数据同步到mini2上:使用命令scp -r dump.rdb mini2:$PWD,将mini1上dump.rdb文件发送到mini2上,重启mini2上的redis服务
注意:这种方式必须修改redis.conf文件中appendonly yes改为no
2.使用第三方工具进行数据恢复或者迁移
|
先安装 yum install ruby rubygems ruby-devel gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org/ gem install redis-dump -V 命令(直接在linux命令行输入): redis-dump -u mini1:6379 > dump.json #将dump.rdb文件拷贝成一份dump.json < dump.json redis-load -u mini1:6379然后重新进入客户端查看数据是否迁移成功 |
Redis回收策略
可以通过配置redis回收策略,淘汰redis中的冷数据,保持redis中是经常用到的热数据。配置文件redis.conf,#maxmemory <bytes> (redis当前缓存的最大内存数);#maxmemory-policy volatile-lru(移除超过生命周期的key)
|
maxmemory-policy: 1) volatile-lru 从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰2) volatile-ttl 从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰3) volatile-random 从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰4) allkeys-lru 从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰5) allkeys-random 随机移除一个任意key6) no-enviction 禁止驱逐数据 |
关注微信公众号:大数据学习与分享,获取更对技术干货
 文章浏览阅读1.3k次。在 Redis 中,键(Keys)是非常重要的概...
文章浏览阅读1.3k次。在 Redis 中,键(Keys)是非常重要的概... 文章浏览阅读3.3k次,点赞44次,收藏88次。本篇是对单节点的...
文章浏览阅读3.3k次,点赞44次,收藏88次。本篇是对单节点的... 文章浏览阅读978次,点赞25次,收藏21次。在Centos上安装Red...
文章浏览阅读978次,点赞25次,收藏21次。在Centos上安装Red... 文章浏览阅读1.2k次,点赞21次,收藏22次。Docker-Compose部...
文章浏览阅读1.2k次,点赞21次,收藏22次。Docker-Compose部... 文章浏览阅读2.2k次,点赞59次,收藏38次。合理的JedisPool资...
文章浏览阅读2.2k次,点赞59次,收藏38次。合理的JedisPool资...