SQL TypeC/C++ Type
[root@localhost zhxilin]#
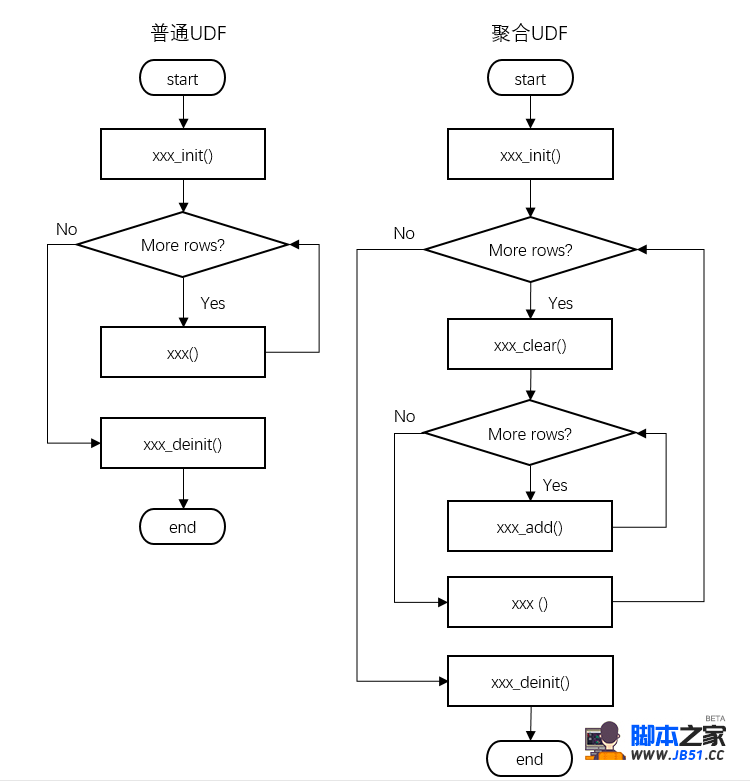
我们定义一个最简单的UDF主函数:
args[args[
由于mysql提供的接口是C实现的,我们在C++中使用时需要添加:
接下来编译成动态库.so:
[zhxilin@localhost mysql-redis-test]$ g++ -shared -fPIC -I /usr/include/mysql -o simple_add.so simple.
-shared 表示编译和链接时使用的是全局共享的类库;
-fPIC编译器输出位置无关的目标代码,适用于动态库;
-I /usr/include/mysql 指明包含的头文件mysql.h所在的位置。
编译出simple_add.so后用root拷贝到/usr/lib64/mysql/plugin下:
[root@localhost mysql-redis-test]#
紧接着可以在MySQL中创建函数执行了。登录MySQL,创建关联函数:
mysql
测试UDF函数:
mysql
可以看到,UDF正确执行了加法。
创建UDF函数的语法是CREATE FUNCTION xxx RETURNS [INTEGER/STRING/REAL] SONAME '[so name]';
删除UDF函数的语法是 DROP FUNCTION simple_add;
mysql
三. 在UDF中访问Redis
跟上述做法一样,只需在UDF里调用Redis提供的接口函数。Redis官方给出了,封装了Redis的基本操作。
源码是依赖boost,需要先安装boost:
[root@localhost dev]#
然后下载redis cpp client源码:
[root@localhost dev]# git clone https:
使用时需要把redisclient.h、anet.h、fmacros.h、anet.c 这4个文件考到目录下,开始编写关于Redis的UDF。我们定义了redis_hset作为主函数,连接Redis并调用hset插入哈希表,redis_hset_init作为初始化,检查参数个数和类型。
args && args->args[args[args[hset(args->args[args[args[arg_type[arg_type[arg_type[arg_type[arg_type[arg_type[ptr =
编译链接:
[zhxilin@localhost mysql-redis-test]$ g++ -shared -fPIC -I /usr/include/mysql -lboost_serialization -lboost_system -lboost_thread -o libmyredis.so anet.c test.cpp
编译时需要加上-lboost_serialization -lboost_system -lboost_thread, 表示需要链接三个动态库:libboost_serialization.so、libboost_system.so、libboost_thread.so,否则在运行时会报缺少函数定义的错误。
编译出libmyredis.so之后,将其拷贝到mysql的插件目录下并提权:
[root@localhost mysql-redis-test]#
完成之后登录MySQL,创建关联函数测试一下:
mysql
mysql<span style="color: #808080">> <span style="color: #0000ff">CREATE <span style="color: #0000ff">FUNCTION redis_hset <span style="color: #0000ff">RETURNS STRING SONAME <span style="color: #ff0000">'<span style="color: #ff0000">libmyredis.so<span style="color: #ff0000">'<span style="color: #000000">;
Query OK,<span style="color: #800000; font-weight: bold">0 rows affected (<span style="color: #800000; font-weight: bold">0.02 sec)
先删除老的UDF,注意函数名加反引号(``)。调用UDF测试,返回0,执行成功:
mysql
打开redis-cli,查看结果:
四. 通过MySQL触发器刷新Redis
在上一节的基础上,我们想让MySQL在增删改查的时候自动调用UDF,还需要借助MySQL触发器。触发器可以监听INSERT、UPDATE、DELETE等基本操作。在MySQL中,创建触发器的基本语法如下:
trigger_time表示触发时机,值为AFTER或BEFORE;
trigger_event表示触发的事件,值为INSERT、UPDATE、DELETE等;
trigger_statement表示触发器的程序体,可以是一句SQL语句或者调用UDF。
在trigger_statement中,如果有多条SQL语句,需要用BEGIN...END包含起来:
由于MySQL默认的结束分隔符是分号(;),如果我们在BEGIN...END中出现了分号,将被标记成结束,此时没法完成触发器的定义。有一个办法,可以调用DELIMITER命令来暂时修改结束分隔符,用完再改会分号即可。比如改成$:
mysql> DELIMITER $
我们开始定义一个触发器,监听对Student表的插入操作,Student表在上一篇文章中创建的,可以查看文章。
mysql AFTER
创建完触发器可以通过show查看,或者drop删除:
mysql SHOW TRIGGERS;
mysql
接下来我们调用一句插入语句,然后观察Redis和MySQL数据的变化:
mysql
MySQL的结果:
mysql
Redis的结果:
以上结果表明,当MySQL插入数据时,通过触发器调用UDF,实现了自动刷新Redis的数据。另外,调用MySQL插入的命令,可以通过C++实现,进而就实现了在C++的业务逻辑里,只需调用MySQL++的接口就能实现MySQL数据库和Redis缓存的更新,这部分内容在已经介绍过了。
总结
通过实践,能体会到MySQL和Redis是多么相亲相爱吧!^_^
本篇文章讲了从最基础的UDF开始,再到通过UDF连接Redis插入数据,再进一步介绍通过MySQL Trigger自动更新Redis数据的整个思路,实现了一个目标,即只在业务代码中更新MySQL数据库,进而Redis能够自动同步刷新。
MySQL对UDF函数和触发器的支持,使得实现Redis数据和MySQL自动同步成了可能。当然UDF毕竟是通过插件的形式运行在MySQL中的,并没有过多的安全干预,一旦插件发生致命性崩溃,有可能MySQL也会挂,所以在编写UDF的时候需要非常谨慎!
以上内容来自:http://www.cnblogs.com/zhxilin/archive/2016/09/30/5923671.html
相关文章
在笔者近 3 年的 Java 一线开发经历中,尤其是一些移动端、用...
这一篇文章拖了有点久,虽然在项目中使用分布式锁的频率比较...
本文梳理总结了一些 Java 互联网项目中常见的 Redis 缓存应用...
书接上回,消息通知系统(notification-system)作为一个独立...
Redis 是目前互联网后端的热门中间件之一,在许多方面都有深...
在Java Spring 项目中,数据与远程数据库的频繁交互对服务器...