在并发式的项目当中,一定要考虑一个缓存穿透的情况。那么什么是缓存穿透呢?简单的说来,就是当大量请求的key根本不在缓存当中,所以导致了请求直接到了数据库上,根本没有经过缓存这一层。比如一个黑客故意制造我们缓存中不存在的key发送大量的请求,就会导致请求直接落到数据库上。
也就是说,缓存穿透就是:1.缓存层不命中。2,存储层不命中,不将空的结果写回缓存。3,返回空结果给客户端。
一般mysql的默认最大连接数是150左右,当然这个是可以用show variables like ‘%max_connections%’命令来查看。
当然这只是一个指标,cpu磁盘内存网络等等原因都影响了他的并发能力,所以一般3000的并发请求就可以杀死大部分的数据库。
那么出现缓存穿透的时候需要怎么应对呢?
1)最基本的方式就是做好参数校检,比如不合法的请求就直接抛出异常信息给客户端,就比如设置查询条件id不能小于0或者传入邮箱格式不正确时直接返回错误消息给客户端。但是这样还是会出现缓存穿透的现象。那么还可以通过下面几个方案来解决:
2)缓存无效的key,如果数据库和缓存都找不到某个key的数据,就直接写一个到redis中并设置它的过期时间 set key value EX 10086。这种方式可以解决请求的key变化不频繁的情况,如果遇到专门的黑客攻击就不能解决这个情况。但是如果依然想用这个方法的话,那么在设置过期时间的时候,时间短一点,比如是一分钟。多说一句设置key的格式一般是:表名:列名:主键名:主键。
3)利用布隆过滤器:布隆过滤器是一个非常神奇的数据结构,通过这个过滤器可以帮助我们非常方便的去判断一个给定的数据是否存在于海量的数据当中。所以布隆过滤器在针对数据去重和验证数据的合法性时是非常有用的,布隆过滤器的实质就是一个bit(位)数组。也就是说每一个存进的数据都仅仅只占一位,在数据结构上来说相当于List、Map、Set等数据结构,但是占用的空间更少而且效率更高,但是缺点是它返回的值是概率性的,并不是多么的准确。当一个元素加入到布隆过滤器的时候:1.使用布隆过滤器当中的哈希函数对元素值进行计算,得到哈希值。2.根据得到的哈希值,在位数组中把对应的下标改为1。那么设置完成之后,我们要怎么判断一个元素是否存在于布隆过滤器当中呢?
首先我们要根据给定的元素再次进行hash计算;得到值之后判断数组中的每个元素是否都为1,如果值都为1的话,那么说明这个值在过滤器当中,如果不为1的话,就说明不再过滤器当中。
举个非常简单的例子
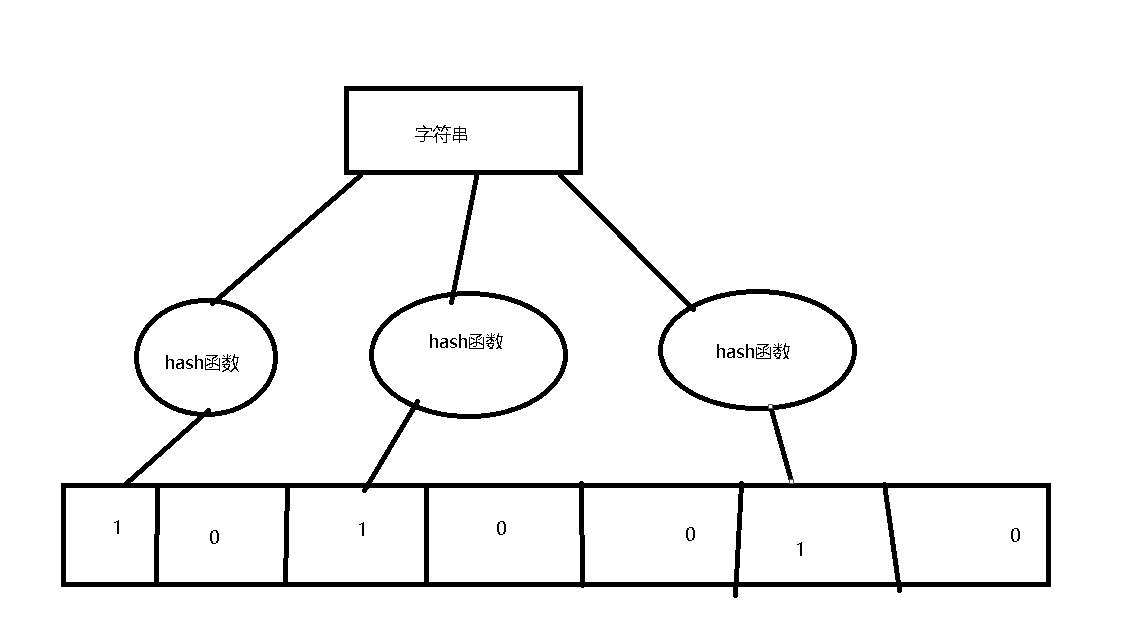
如上图所示,当字符串要加入到布隆过滤器当中时,该事务首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下标的元素设置位1,当二次存储相同的字符串时,因为先前的对应位置已经存在,所以在去重的时候非常方便。如果我们需要判断某个字符串是否在布隆过滤器当中时,只需要对给定的字符串再次进行相同的哈希计算,得到的值判断是否为1,从而判断数据是否存在于布隆过滤器当中,那么假如布隆过滤器说明一个数据存在时,很小的概率会误判,但是如果说明一个数据不存在时,那么一定是不存在的。
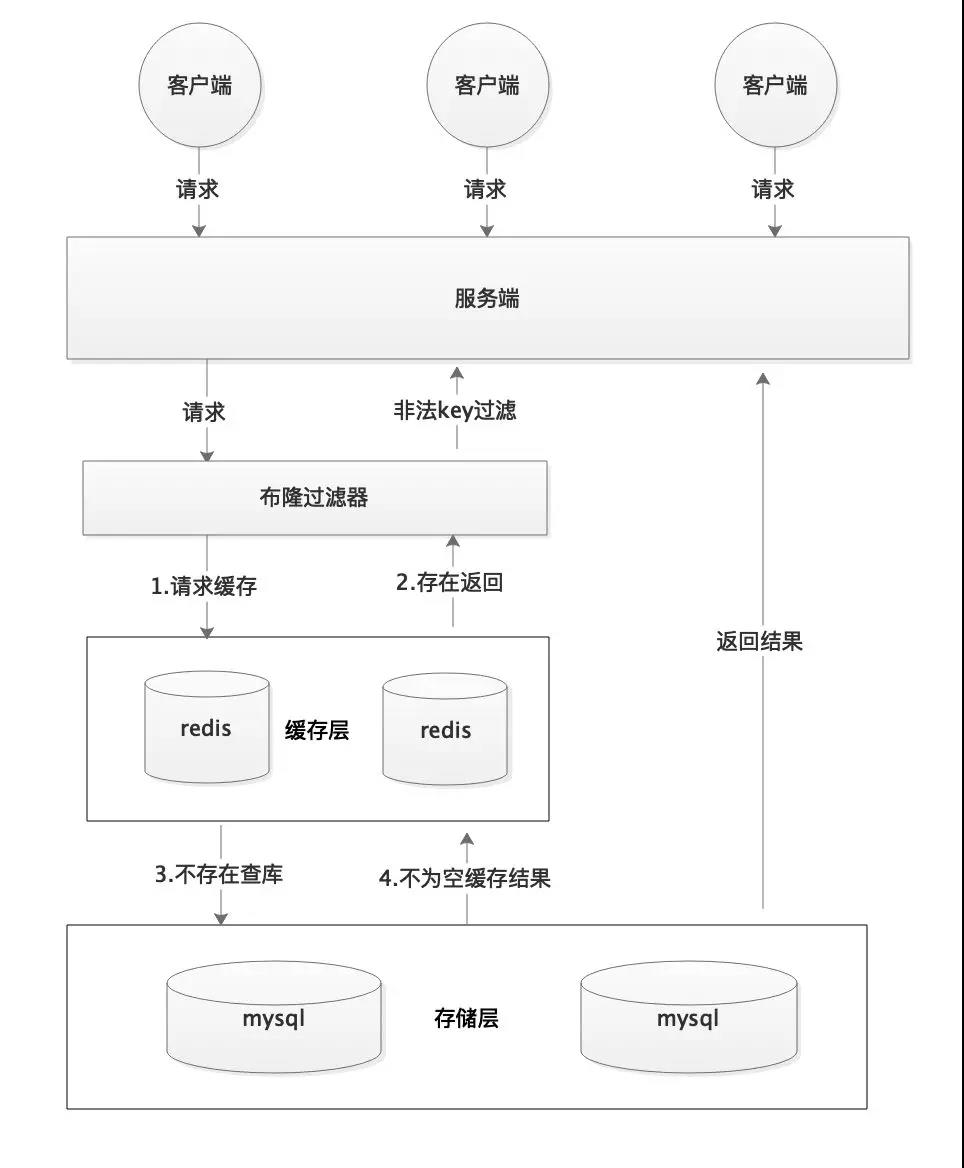
那么通过这个原理,利用redis布隆过滤器来将所有可能存在请求的值放在布隆过滤器当中,当用户请求时,直接判断用户发送来的请求是否存在于布隆过滤器中,不存在的话,直接返回请求参数错误信息给客户,存在的话就继续往下面走流程。
 文章浏览阅读1.3k次。在 Redis 中,键(Keys)是非常重要的概...
文章浏览阅读1.3k次。在 Redis 中,键(Keys)是非常重要的概... 文章浏览阅读3.3k次,点赞44次,收藏88次。本篇是对单节点的...
文章浏览阅读3.3k次,点赞44次,收藏88次。本篇是对单节点的... 文章浏览阅读978次,点赞25次,收藏21次。在Centos上安装Red...
文章浏览阅读978次,点赞25次,收藏21次。在Centos上安装Red... 文章浏览阅读1.2k次,点赞21次,收藏22次。Docker-Compose部...
文章浏览阅读1.2k次,点赞21次,收藏22次。Docker-Compose部... 文章浏览阅读2.2k次,点赞59次,收藏38次。合理的JedisPool资...
文章浏览阅读2.2k次,点赞59次,收藏38次。合理的JedisPool资...