
这是python3实战入门系列的第三篇文章,要学习这一篇需要了解前两篇,要不学起来比较费劲
《python3实战入门Python爬虫篇001---网页爬虫,图片爬虫,文章爬虫,新闻网站爬虫》
《python3操作数据库002 借助pycharm快速连接并操作MysqL数据库》
下面来正式开始把我们第一节爬取到的新闻数据保存到MysqL数据中
通过定义一个MysqLCommand类来配置数据库连接参数,并定义一个connectMysqL方法连接数据库
# -*- coding: utf-8 -*-
# 作者微信:2501902696
import pyMysqL
# 用来操作数据库的类
class MysqLCommand(object):
# 类的初始化
def __init__(self):
self.host = 'localhost'
self.port = 3306 # 端口号
self.user = 'root' # 用户名
self.password = "" # 密码
self.db = "home" # 库
self.table = "home_list" # 表
def connectMysqL(self):
try:
self.conn = pyMysqL.connect(host=self.host, port=self.port, user=self.user,
passwd=self.password, db=self.db, charset='utf8')
self.cursor = self.conn.cursor()
except:
print('connect MysqL error.')
二,连接完数据库后我们需要插入数据了
插入数据之前我们有两个问题
1,重复的数据如何去重2,新数据的主键id应该从哪里开始针对上面的两个问题我贴出一部分代码来看解决思路# 插入数据,插入之前先查询是否存在,如果存在就不再插入
def insertData(self, my_dict):
table = "home_list" # 要操作的表格
# 注意,这里查询的sql语句url=' %s '中%s的前后要有空格
sqlExit = "SELECT url FROM home_list WHERE url = ' %s '" % (my_dict['url'])
res = self.cursor.execute(sqlExit)
if res: # res为查询到的数据条数如果大于0就代表数据已经存在
print("数据已存在", res)
return 0
# 数据不存在才执行下面的插入操作
try:
cols = ', '.join(my_dict.keys())#用,分割
values = '"," '.join(my_dict.values())
sql = "INSERT INTO home_list (%s) VALUES (%s)" % (cols, '"' + values + '"')
#拼装后的sql如下
# INSERT INTO home_list (img_path, url, id, title) VALUES ("https://img.huxiucdn.com.jpg"," https://www.huxiu.com90.html"," 12"," ")
try:
result = self.cursor.execute(sql)
insert_id = self.conn.insert_id() # 插入成功后返回的id
self.conn.commit()
# 判断是否执行成功
if result:
print("插入成功", insert_id)
return insert_id + 1
except pyMysqL.Error as e:
# 发生错误时回滚
self.conn.rollback()
# 主键唯一,无法插入
if "key 'PRIMARY'" in e.args[1]:
print("数据已存在,未插入数据")
else:
print("插入数据失败,原因 %d: %s" % (e.args[0], e.args[1]))
except pyMysqL.Error as e:
print("数据库错误,原因%d: %s" % (e.args[0], e.args[1]))
通过上面代码我们来看如何去重
我们在每次插入之前需要查询下数据是否已经存在,如果存在就不在插入,我们的home_list表格的字段有 id,title,url,img_path。通过分析我们抓取到的数据titlehe和img_path字段都可能为空,所以这里我们通过url字段来去重。知道去重原理以后再去读上面的代码,你应该能容易理解了三,查询数据库中最后一条数据的id值,来确定我们新数据id的开始值
通过下面的getLastId函数来获取home_list表里的最后一条数据的id值
# 查询最后一条数据的id值
def getLastId(self):
sql = "SELECT max(id) FROM " + self.table
try:
self.cursor.execute(sql)
row = self.cursor.fetchone() # 获取查询到的第一条数据
if row[0]:
return row[0] # 返回最后一条数据的id
else:
return 0 # 如果表格为空就返回0
except:
print(sql + ' execute Failed.')
# -*- coding: utf-8 -*-
# 作者微信:2501902696
import pyMysqL
# 用来操作数据库的类
class MysqLCommand(object):
# 类的初始化
def __init__(self):
self.host = 'localhost'
self.port = 3306 # 端口号
self.user = 'root' # 用户名
self.password = "" # 密码
self.db = "home" # 库
self.table = "home_list" # 表
def connectMysqL(self):
try:
self.conn = pyMysqL.connect(host=self.host, port=self.port, user=self.user,
passwd=self.password, db=self.db, charset='utf8')
self.cursor = self.conn.cursor()
except:
print('connect MysqL error.')
# 插入数据,插入之前先查询是否存在,如果存在就不再插入
def insertData(self, my_dict):
table = "home_list" # 要操作的表格
# 注意,这里查询的sql语句url=' %s '中%s的前后要有空格
sqlExit = "SELECT url FROM home_list WHERE url = ' %s '" % (my_dict['url'])
res = self.cursor.execute(sqlExit)
if res: # res为查询到的数据条数如果大于0就代表数据已经存在
print("数据已存在", res)
return 0
# 数据不存在才执行下面的插入操作
try:
cols = ', '.join(my_dict.keys())#用,分割
values = '"," '.join(my_dict.values())
sql = "INSERT INTO home_list (%s) VALUES (%s)" % (cols, '"' + values + '"')
#拼装后的sql如下
# INSERT INTO home_list (img_path, url, id, title) VALUES ("https://img.huxiucdn.com.jpg"," https://www.huxiu.com90.html"," 12"," ")
try:
result = self.cursor.execute(sql)
insert_id = self.conn.insert_id() # 插入成功后返回的id
self.conn.commit()
# 判断是否执行成功
if result:
print("插入成功", insert_id)
return insert_id + 1
except pyMysqL.Error as e:
# 发生错误时回滚
self.conn.rollback()
# 主键唯一,无法插入
if "key 'PRIMARY'" in e.args[1]:
print("数据已存在,未插入数据")
else:
print("插入数据失败,原因 %d: %s" % (e.args[0], e.args[1]))
except pyMysqL.Error as e:
print("数据库错误,原因%d: %s" % (e.args[0], e.args[1]))
# 查询最后一条数据的id值
def getLastId(self):
sql = "SELECT max(id) FROM " + self.table
try:
self.cursor.execute(sql)
row = self.cursor.fetchone() # 获取查询到的第一条数据
if row[0]:
return row[0] # 返回最后一条数据的id
else:
return 0 # 如果表格为空就返回0
except:
print(sql + ' execute Failed.')
def closeMysqL(self):
self.cursor.close()
self.conn.close() # 创建数据库操作类的实例
# -*- coding: utf-8 -*-
# 作者微信:2501902696
from bs4 import BeautifulSoup
from urllib import request
import chardet
from db.MysqLCommand import MysqLCommand
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
# 连接数据库
#这里每次查询数据库中最后一条数据的id,新加的数据每成功插入一条id+1
dataCount = int(MysqLCommand.getLastId()) + 1
for news in allList: # 遍历列表,获取有效信息
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
try: # 如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href = ''
try:
imgurl = aaa[0].select('img')[0]['src']
except Exception:
imgurl = ""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = ""
news_dict = {
"id": str(dataCount),
"title": title,
"url": href,
"img_path": imgurl
}
try:
# 插入数据,如果已经存在就不在重复插入
res = MysqLCommand.insertData(news_dict)
if res:
dataCount=res
except Exception as e:
print("插入数据失败", str(e))#输出插入失败的报错语句
MysqLCommand.closeMysqL() # 最后一定要要把数据关闭
dataCount=0
python3实战入门Python爬虫篇---网页爬虫,图片爬虫,文章爬虫,Python爬虫爬取新闻网站新闻
到此我们的python3爬虫+python3数据库篇就完事了,看下操作效果图
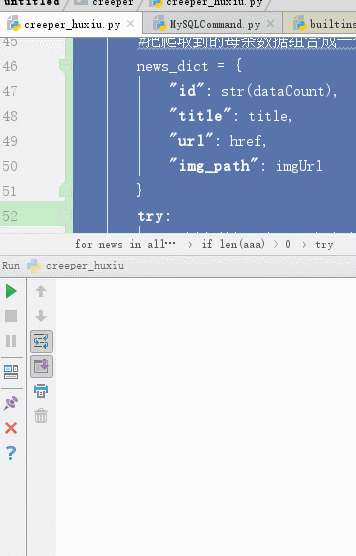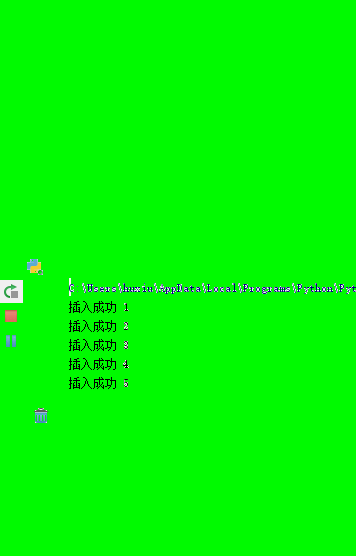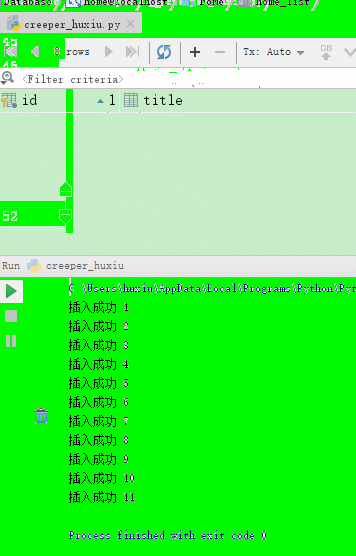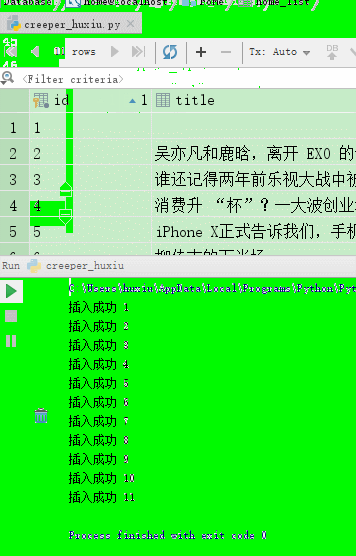
gif图片质量不是很好,大家凑合着看吧☺☺☹☎
编程小石头,为分享干货而生!据说,每个年轻上进,颜值又高的互联网人都关注了编程小石头。
