thingsboard规则链调用外部API——kafka
因为只是测试一下这个流程,就不做集群了,下面是kafka以及zookeeper的软件安装包
链接:https://pan.baidu.com/s/1VXHAMJ7lKUJvs6Zc6zNKjg?pwd=t5xq
提取码:t5xq
一、安装zookeeper
因为kafka依赖于zookeeper,首先安装zookeeper,下面是步骤:
(1)拷贝zookeeper安装包到/opt/module下面
(2)解压缩:tar -zxvf 安装包名称,使用 “mv “ 指令可以重命名文件夹
(3)修改配置文件:
#将/opt/module/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg
mv zoo_sample.cfg zoo.cfg
#打开 zoo.cfg 文件,修改 dataDir 路径:
vim zoo.cfg
dataDir=/opt/module/zookeeper-3.5.7/zkData
#在/opt/module/zookeeper-3.5.7/创建文件夹zkData
mkdir zkData
(4)启动zookeeper:./bin/zkServer.sh start
(5)查看启动状态:./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: standalone
有时候启动不成功(通过jps也可以查看是否启动成功),看看是不是8080端口被占用了(在logs文件夹下面查看启动日志),如果是,在zoo.cfg添加一条配置,修改zookeeper的端口:
#serverport
admin.serverPort=你想使用的端口号
(6)zookeeper相关指令:
#启动:
./zkServer.sh start
#查看状态
./zkServer.sh status
#关闭
./zkServer.sh stop
#进入客户端
./zkCli.sh
#推出客户端
quit
#显示客户端所有保存的文件
ls /
#删除某个数据文件夹
deleteall xxx
二、安装kafka
安装步骤,相同的部分省略了:
(1)上传安装包,解压缩
(2)修改配置文件
vi config/server.properties
#修改下面几个参数:
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas
advertised.listeners=PLAINTEXT://服务器ip地址:9092
#配置连接Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
#示例:zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
zookeeper.connect=localhost:2181/kafka
(3)配置环境变量:
vim /etc/profile.d/my_env.sh
增加如下内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#刷新环境变量
source /etc/profile
(4)启动kafka:./bin/kafka-server-start.sh -daemon config/server.properties
(5)停止kafka:./bin/kafka-server-stop.sh
(6)查看启动状态:jps
(7)相关指令:
#1.启动
./bin/kafka-server-start.sh -daemon config/server.properties
#2.停止
./bin/kafka-server-stop.sh
#3.查看所有的topic:
bin/kafka-topics.sh --bootstrap-server 自己ip:9092 --list
#4.创建主题
bin/kafka-topics.sh --bootstrap-server 自己ip:9092 --create --partitions 1 --replication-factor 3 --topic first
#选项说明:
--topic 定义 topic 名
--replication-factor 定义副本数
--partitions 定义分区数
#5.修改分区数(注意:分区数只能增加,不能减少)
bin/kafka-topics.sh --bootstrap-server 自己ip:9092 --alter --topic first --partitions 3
#6.查看first 主题的详情
bin/kafka-topics.sh --bootstrap-server 自己ip:9092 --describe --topic first
#7.删除主题
bin/kafka-topics.sh --bootstrap-server 自己ip:9092 --delete --topic first
#8.启动消费者
bin/kafka-console-consumer.sh --bootstrap-server 自己ip:9092 --topic first
#9.启动生产者
bin/kafka-console-producer.sh --bootstrap-server 自己ip:9092 --topic first
三、thingsboard配置
(1)准备模拟遥测数据,这是我准备的数据格式:
{
"alarmType": "0",
"deviceAddress": "9",
"deviceSn": "19_bxj_cqzx_9",
"directionInfo": "cqzz",
"highAlarm": "45",
"id": "19_bxj_cqzx_9",
"lowAlarm": "5",
"section": "19",
"sensorName": "温度",
"sensorValue": "40",
"symbols": "temperature",
"tunnel": "bxj",
"unitValue": "40 °C"
}
(2)我用springboot的@Scheduled注解定时发送,我使用http和mqtt两种协议推送数据:
@Scheduled(cron = "0/5 * * * * ?")
public void doTask() {
if (flag) {
//http数据推送
String newData = getNewData();
pushData(newData);
//mqtt数据推送
String mqttData = getNewData();
mqttPushData(mqttData);
}
}
public String getNewData() {
int max = list.size();
//生成随机数[a,b],公式:int num = min + (int)(Math.random() * (max-min+1));
int r = (int) (Math.random() * max);
return JSONObject.toJSONString(list.get(r));
}
(3)责任链配置:
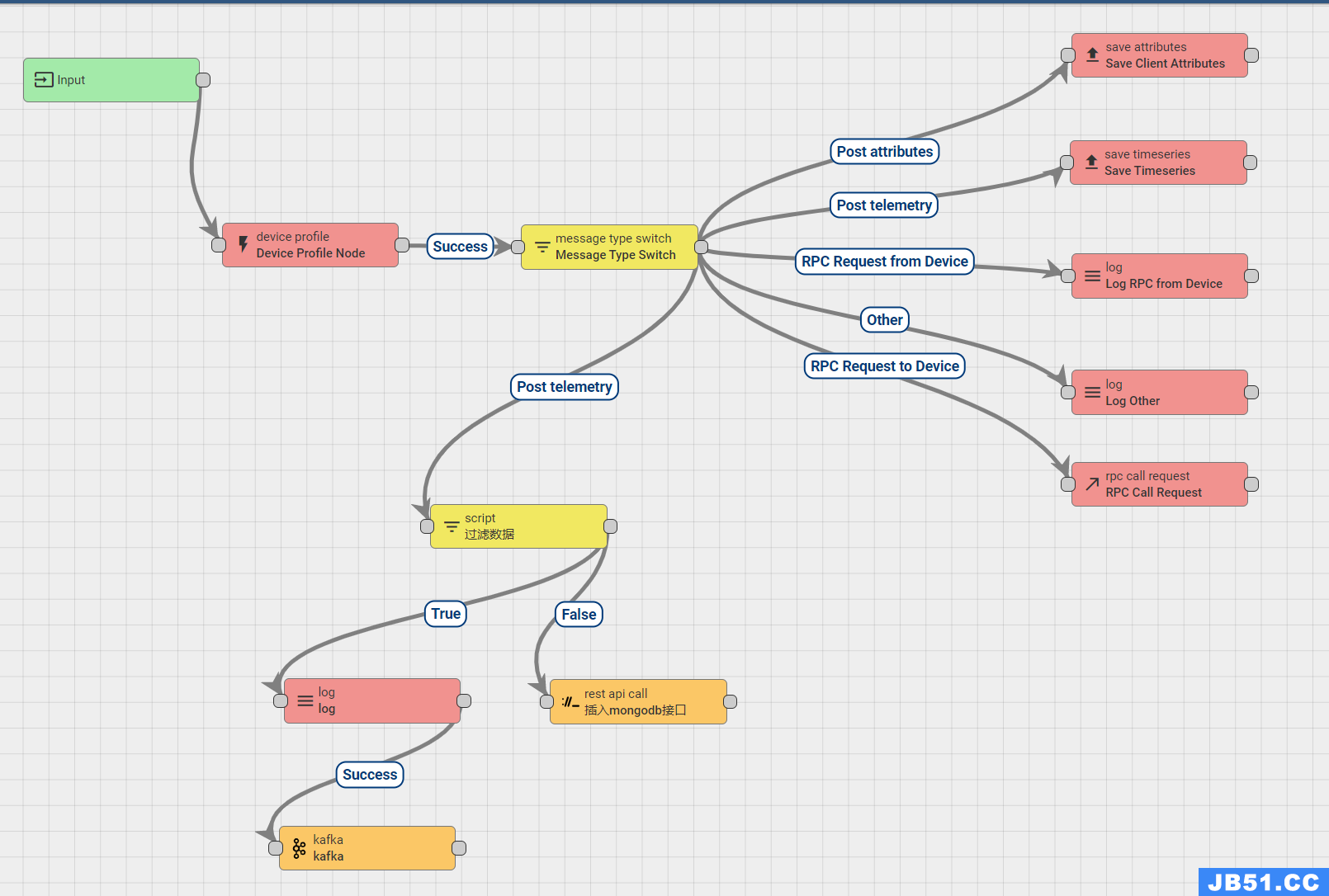
#1.过滤数据:
return msg.sensorName == "氧气";
#2.log
return '推送到kafka数据:\n' + JSON.stringify(msg) + '\n推送到kafka元素据:\n' + JSON.stringify(metadata);
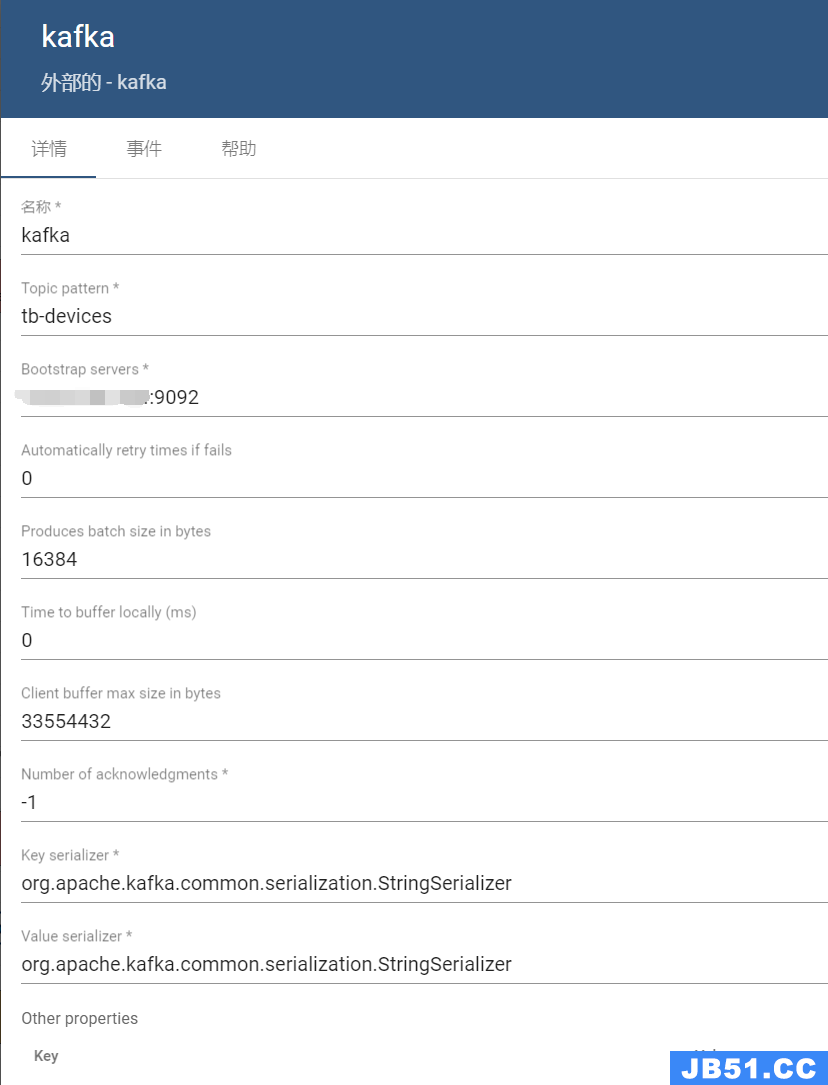
四、springboot集成kafka消费数据
(1)依赖:
<!--kafka begin-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!--kafka end-->
(2)application配置
###########【Kafka集群】###########
spring.kafka.bootstrap-servers=ip:9092
###########【初始化生产者配置】###########
# 重试次数
spring.kafka.producer.retries=0
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
spring.kafka.producer.acks=1
# 批量大小
spring.kafka.producer.batch-size=16384
# 提交延时
spring.kafka.producer.properties.linger.ms=0
# 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
# linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory = 33554432
# Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 自定义分区器
# spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
###########【初始化消费者配置】###########
# 默认的消费组ID
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
# 是否自动提交offset
spring.kafka.consumer.enable-auto-commit=true
# 提交offset延时(接收到消息后多久提交offset)
spring.kafka.consumer.auto.commit.interval.ms=1000
# 当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
spring.kafka.consumer.auto-offset-reset=latest
# 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
# 消费请求超时时间
spring.kafka.consumer.properties.request.timeout.ms=180000
# Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费端监听的topic不存在时,项目启动会报错(关掉)
spring.kafka.listener.missing-topics-fatal=false
# 设置批量消费
# spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
# spring.kafka.consumer.max-poll-records=50
(3)简单消费者
@Component
@Slf4j
public class SimpleConsumer {
/**
* 简单消费
* @param record record
*/
@KafkaListener(topics = {"tb-devices"})
public void onMessage(ConsumerRecord<?, ?> record){
// 消费的哪个topic、partition的消息,打印出消息内容
log.warn("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
}
(4)日志:

至此,thingboard发送遥测数据到kafka的简单demo已经实现,下面是我参考的文章:
#springboot集成kafka
https://blog.csdn.net/weixin_70730532/article/details/125425798
#kafka安装部署
https://www.jianshu.com/p/61b224cea03b
#thingsboard中文网
http://www.ithingsboard.com/
我的代码地址:
https://gitee.com/ayu-elephant/envmonitoring.git
 文章浏览阅读4.1k次。kafka认证_kafka认证
文章浏览阅读4.1k次。kafka认证_kafka认证 文章浏览阅读1.4k次,点赞25次,收藏10次。Kafka 生产者发送...
文章浏览阅读1.4k次,点赞25次,收藏10次。Kafka 生产者发送... 文章浏览阅读854次,点赞22次,收藏24次。点对点模型:适用于...
文章浏览阅读854次,点赞22次,收藏24次。点对点模型:适用于... 文章浏览阅读1.5k次,点赞2次,收藏3次。kafka 自动配置在Ka...
文章浏览阅读1.5k次,点赞2次,收藏3次。kafka 自动配置在Ka... 文章浏览阅读1.3w次,点赞6次,收藏33次。Offset Explorer(...
文章浏览阅读1.3w次,点赞6次,收藏33次。Offset Explorer(...