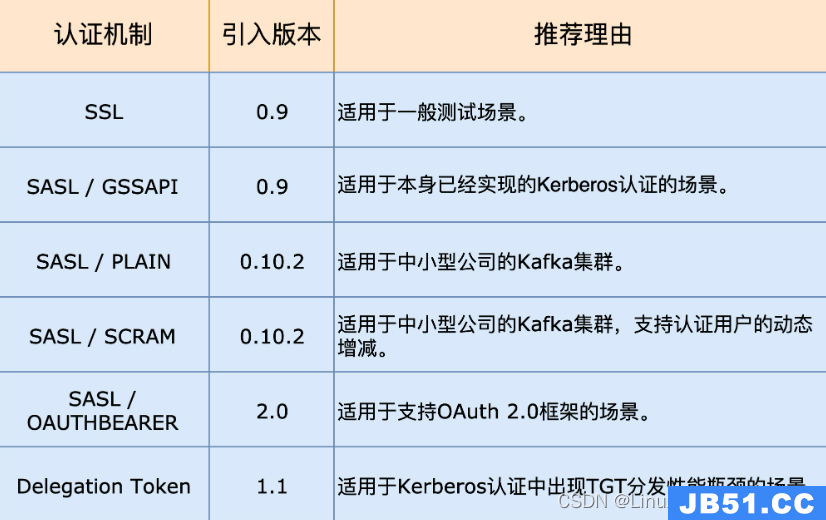
 文章浏览阅读4.1k次。kafka认证_kafka认证
文章浏览阅读4.1k次。kafka认证_kafka认证 文章浏览阅读1.4k次,点赞25次,收藏10次。Kafka 生产者发送...
文章浏览阅读1.4k次,点赞25次,收藏10次。Kafka 生产者发送... 文章浏览阅读854次,点赞22次,收藏24次。点对点模型:适用于...
文章浏览阅读854次,点赞22次,收藏24次。点对点模型:适用于...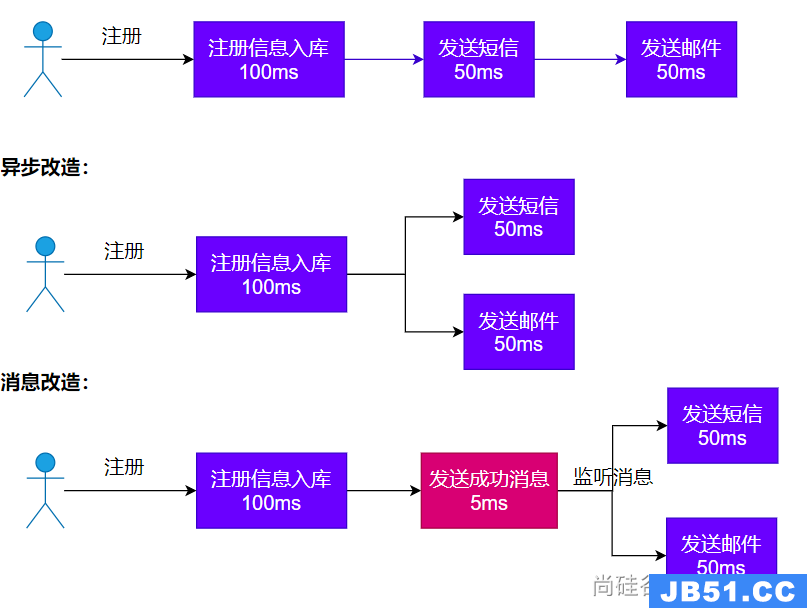 文章浏览阅读1.5k次,点赞2次,收藏3次。kafka 自动配置在Ka...
文章浏览阅读1.5k次,点赞2次,收藏3次。kafka 自动配置在Ka... 文章浏览阅读1.3w次,点赞6次,收藏33次。Offset Explorer(...
文章浏览阅读1.3w次,点赞6次,收藏33次。Offset Explorer(... 文章浏览阅读1.3k次,点赞12次,收藏19次。kafka broker 在启...
文章浏览阅读1.3k次,点赞12次,收藏19次。kafka broker 在启... 文章浏览阅读3.5k次,点赞42次,收藏56次。对于Java开发者而...
文章浏览阅读3.5k次,点赞42次,收藏56次。对于Java开发者而...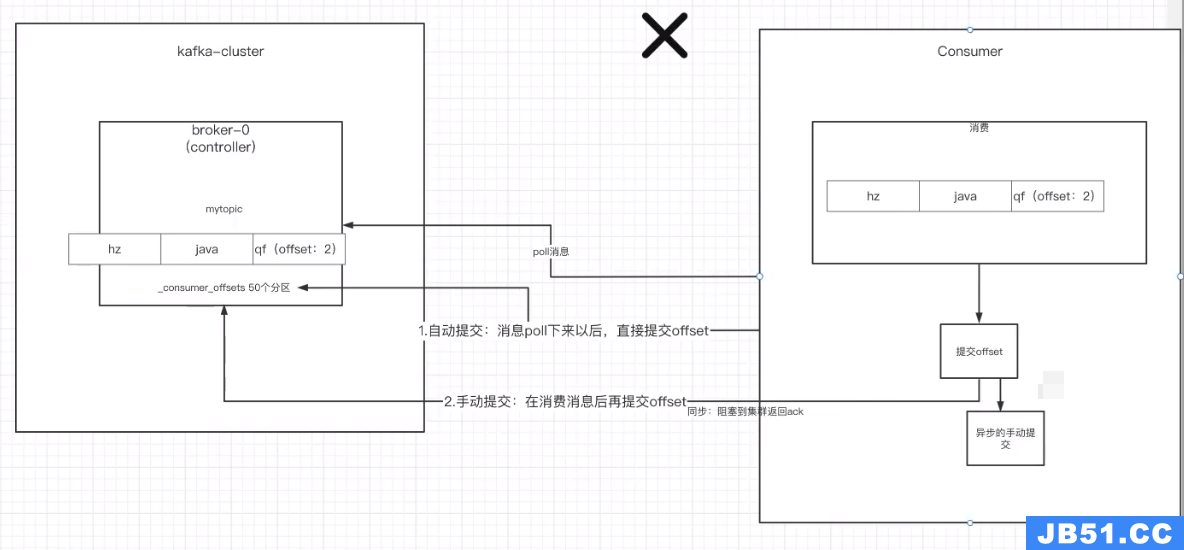 文章浏览阅读1.1k次,点赞14次,收藏16次。一、自动提交offs...
文章浏览阅读1.1k次,点赞14次,收藏16次。一、自动提交offs...