Fetcher解析
回顾
上一篇介绍了消费者KafkaConsumer两个主要方法,一个对外可以调用的poll方法和一个内部私有的pollForFetches方法。
我们知道pollForFetches方法主要是抓取数据的实现细节,里面多次出现Fetcher对象,其中最主要的两个方法是 fetcher.sendFetches() 和 fetcher.fetchedRecords()。接下来让我们揭开他们的面纱。
Fetcher概述
官方定义:该类使用代理管理获取过程,线程安全。
此类主要有三部分组成。
- 成员变量
- 静态内部类
- 方法
接下来我们依次介绍。
成员变量
private final Logger log; // 日志
private final LogContext logContext; // 日志信息
private final ConsumerNetworkClient client; // 消费者网络客户端
private final Time time; // 时间
private final int minBytes; // 最小字节大小
private final int maxBytes; // 最大字节大小
private final int maxWaitMs; // 最大等待时长
private final int fetchSize; // 抓取数据的大小
private final long retryBackoffMs;
private final long requestTimeoutMs;
private final int maxPollRecords; // 每一次获取的最大记录条数
private final boolean checkCrcs;
private final Metadata metadata; // 元数据
private final FetchManagerMetrics sensors; // 度量管理类
private final SubscriptionState subscriptions;
private final ConcurrentLinkedQueue<CompletedFetch> completedFetches; // 已完成的获取类的一个基于链接节点的无界线程安全队列
private final BufferSupplier decompressionBufferSupplier = BufferSupplier.create();
private final Deserializer<K> keyDeserializer; // 反序列化后的key
private final Deserializer<V> valueDeserializer;
private final IsolationLevel isolationLevel;
private final Map<Integer, FetchSessionHandler> sessionHandlers;
private final AtomicReference<RuntimeException> cachedListOffsetsException = new AtomicReference<>();
有些成员一眼看不出来职业,伪装的很好,我们先放着,待后续补充。
静态内部类
之所以先介绍静态内部类,因为方法中会频频用到。这里只介绍几个简单和常用的。
复杂的我也看不懂阿,嘻嘻。
OffsetData
偏移量类,表示关于代理返回的偏移量的数据。
private static class OffsetData {
final long offset; // 偏移量
final Long timestamp; // null if the broker does not support returning timestamps
final Optional<Integer> leaderEpoch; // empty if the leader epoch is not known
OffsetData(long offset, Long timestamp, Optional<Integer> leaderEpoch) {
this.offset = offset;
this.timestamp = timestamp;
this.leaderEpoch = leaderEpoch;
}
}
此类比较简单,点到为止。
ListOffsetResult
偏移量结果列表类,顾名思义是记录偏移量结果的集合。
private static class ListOffsetResult {
private final Map<TopicPartition, OffsetData> fetchedOffsets; // 主题分区和偏移量结果的map集合
private final Set<TopicPartition> partitionsToRetry; // 主题分区的set集合
public ListOffsetResult(Map<TopicPartition, OffsetData> fetchedOffsets, Set<TopicPartition> partitionsNeedingRetry) {
this.fetchedOffsets = fetchedOffsets;
this.partitionsToRetry = partitionsNeedingRetry;
}
public ListOffsetResult() {
this.fetchedOffsets = new HashMap<>();
this.partitionsToRetry = new HashSet<>();
}
}
PartitionRecords
分区记录类,此类代码较长就不提供源码了,大概说下本文中用到的属性和方法。
- TopicPartition 主题分区
- CompletedFetch 已完成的获取类
- nextFetchOffset 下一个获取消息的偏移量
- isFetched = false 被获取标识,默认没有被获取过。
- fetchRecords(int maxRecords) 获取消息的方法,返回消费的消息列表。
CompletedFetch
已完成的获取类,虽然名字不好听,但是便于理解。它的内容很少,如下:
private static class CompletedFetch {
private final TopicPartition partition; // 主题分区
private final long fetchedOffset; // 偏移量
private final FetchResponse.PartitionData<Records> partitionData; //分区数据
private final FetchResponseMetricAggregator metricAggregator; //响应聚合器类,另一个静态内部类,下面会介绍
private final short responseVersion; // 响应版本
// 私有构造器
private CompletedFetch(TopicPartition partition,
long fetchedOffset,
FetchResponse.PartitionData<Records> partitionData,
FetchResponseMetricAggregator metricAggregator,
short responseVersion) {
this.partition = partition;
this.fetchedOffset = fetchedOffset;
this.partitionData = partitionData;
this.metricAggregator = metricAggregator;
this.responseVersion = responseVersion;
}
}
已完成的获取类结构很简单,就只有五个成员变量和一个私有构造器。
作用就是记录已经完成的获取,包括主题分区,偏移量等信息。
方法
这里只介绍几种重要方法。即回顾中说到的两个方法。
sendFetches方法
官方定义:为已经分配分区的节点设置一个获取请求,该节点没有正在运行的获取或挂起的获取数据。
public synchronized int sendFetches() {
// 定义一个节点和请求数据的map集合
// 为所有节点创建获取请求,我们为这些节点分配了分区,这些分区没有正在运行的现有请求。
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
// 遍历集合
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
// 获取该节点对象
final Node fetchTarget = entry.getKey();
// 获取抓取的数据
final FetchSessionHandler.FetchRequestData data = entry.getValue();
// 创建一个获取数据的请求
final FetchRequest.Builder request = FetchRequest.Builder
.forConsumer(this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel)
.setMaxBytes(this.maxBytes)
.metadata(data.metadata())
.toForget(data.toForget());
if (log.isDebugEnabled()) {
log.debug("Sending {} {} to broker {}", isolationLevel, data.toString(), fetchTarget);
}
// 消费客户端向该节点发送获取数据请求
client.send(fetchTarget, request)
// 添加请求结果监听
.addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) {
// 给fetcher对象加上同步锁
synchronized (Fetcher.this) {
// 获取请求响应体
FetchResponse<Records> response = (FetchResponse<Records>) resp.responseBody();
// 维护连接到代理的fetch会话状态
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler == null) {
log.error("Unable to find FetchSessionHandler for node {}. Ignoring fetch response.",
fetchTarget.id());
return;
}
if (!handler.handleResponse(response)) {
return;
}
// 获取响应数据的主题分区对象,放入set集合中
Set<TopicPartition> partitions = new HashSet<>(response.responseData().keySet());
// 这是静态内部类
FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
// 遍历请求响应体的数据集
for (Map.Entry<TopicPartition, FetchResponse.PartitionData<Records>> entry : response.responseData().entrySet()) {
// 获取主题分区
TopicPartition partition = entry.getKey();
// 获取偏移量
long fetchOffset = data.sessionPartitions().get(partition).fetchOffset;
// 获取分区数据,里面包括消费的数据
FetchResponse.PartitionData fetchData = entry.getValue();
log.debug("Fetch {} at offset {} for partition {} returned fetch data {}",
isolationLevel, fetchOffset, partition, fetchData);
// 将完成的请求记录到集合中
completedFetches.add(new CompletedFetch(partition, fetchOffset, fetchData, metricAggregator,
resp.requestHeader().apiVersion()));
}
sensors.fetchLatency.record(resp.requestLatencyMs());
}
}
@Override
public void onFailure(RuntimeException e) {
synchronized (Fetcher.this) {
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler != null) {
// 处理发送请求时出现的异常
handler.handleError(e);
}
}
}
});
}
// 返回抓取数据请求的数量
return fetchRequestMap.size();
}
fetchedRecords方法
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
// 定义一个消费的主题分区和数据map集合
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>();
// 维护一个剩下的记录数,便于控制消费最大的记录数
int recordsRemaining = maxPollRecords;
try {
// 只要剩下的记录数大于0,就继续消费
while (recordsRemaining > 0) {
// 判断分区记录是否为空 或者 它是否被获取过
if (nextInLineRecords == null || nextInLineRecords.isFetched) {
// 获取但不删除队列的头元素
CompletedFetch completedFetch = completedFetches.peek();
// 如果已完成的获取对象为空,跳出循环
if (completedFetch == null) break;
try {
// 如果为空是获取分区记录对象。如果被获取过就是更新分区记录对象
nextInLineRecords = parseCompletedFetch(completedFetch);
} catch (Exception e) {
// Remove a completedFetch upon a parse with exception if (1) it contains no records, and
// (2) there are no fetched records with actual content preceding this exception.
// The first condition ensures that the completedFetches is not stuck with the same completedFetch
// in cases such as the TopicAuthorizationException, and the second condition ensures that no
// potential data loss due to an exception in a following record.
// 如果遇到异常,取出刚才的已完成的获取对象里面的分区数据
FetchResponse.PartitionData partition = completedFetch.partitionData;
// 判断该map集合是否为空
// 判断分区数据的记录是否为空或者记录大小是否为0
if (fetched.isEmpty() && (partition.records == null || partition.records.sizeInBytes() == 0)) {
// 如果该map集合为空并且已完成的获取对象的分区数据里面的消息为空或者为0,则删除队列的头元素
completedFetches.poll();
}
throw e;
}
// 获取并删除队列的头元素
completedFetches.poll();
// 如果分区记录对象不为空且没有被获取过
} else {
// 获取消费数据集
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineRecords, recordsRemaining);
// 获取主题分区
TopicPartition partition = nextInLineRecords.partition;
if (!records.isEmpty()) {
// 通过主题分区获取到当前的消费数据集
List<ConsumerRecord<K, V>> currentRecords = fetched.get(partition);
// 判断获取的数据集是否为空
if (currentRecords == null) {
// 如果为空就将主题分区和消费数据集放入map集合中
fetched.put(partition, records);
} else {
// this case shouldn't usually happen because we only send one fetch at a time per partition,
// but it might conceivably happen in some rare cases (such as partition leader changes).
// we have to copy to a new list because the old one may be immutable
// 如果不为空,这种情况通常不会发生,因为每个分区一次只发送一个fetch,但是在一些罕见的情况下(例如分区leader更改),这种情况可能会发生。我们必须复制到一个新的列表,因为旧的列表可能是不可变的
// 新建一个集合,大小为两个消息数据集合大小之和
List<ConsumerRecord<K, V>> newRecords = new ArrayList<>(records.size() + currentRecords.size());
// 添加当前消费的数据集
newRecords.addAll(currentRecords);
// 添加消费的数据集
newRecords.addAll(records);
// 将合并后的数据集添加到map集合中
fetched.put(partition, newRecords);
}
// 可消费的剩下数据条数减去刚才消费到的数据集的大小
recordsRemaining -= records.size();
}
}
}
} catch (KafkaException e) {
if (fetched.isEmpty())
throw e;
}
// 返回该map集合
return fetched;
}
此方法有点绕,我们来顺顺。
- 定义一个map,key为主题分区,value为消费到的数据集。
- 记录剩下的消费数据量N,每次获取都有一个最大获取数据的量。
- 进入循环,判断条件是 N大于0。
- 如果分区记录等于空或者它被获取过,进入第5步,否则进入第6步。
- 获取但不删除队列的头元素,如果为空则跳出循环,不为空则设置分区记录对象(之前为空则是初始化,不为空就是更新),最后删除队列的头元素。
- 获取消息数据集 records,根据分区记录对象获取主题分区 partition
- 如果 records 不为空,通过 partition去map集合找对应的消息数据集,一般情况每个分区一次只发送一个fetch,因此都是找不到的,那么将 partition,records 添加到map集合中
- 特殊情况:比如分区的leader更改,那么map里面如果有该 partition 对应的消息数据集 currentRecords,则将 records 和 currentRecords合并,再添加到map集合中。
- 更新剩下的消费数据量N = N - records 大小 ,这里为什么只减 records 不减 currentRecords,因为只要是 records 不为空,就都会在 N 除去 records 大小,不管map里面有没有对应分区的数据,即使有 currentRecords,那么在 currentRecords被添加到map之后也会立即 在 N 中除去。
- 最后返回map集合
小结
本文至此,关于Fetcher类就介绍完了。以上,如有不对之处欢迎指正。
接下来打算介绍下ConsumerNetworkClient消费网络客户端这个类。
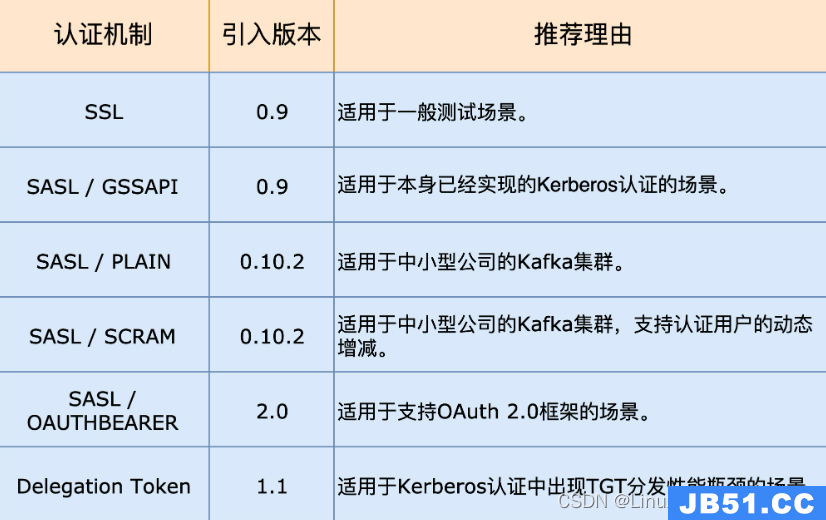 文章浏览阅读4.1k次。kafka认证_kafka认证
文章浏览阅读4.1k次。kafka认证_kafka认证 文章浏览阅读1.4k次,点赞25次,收藏10次。Kafka 生产者发送...
文章浏览阅读1.4k次,点赞25次,收藏10次。Kafka 生产者发送... 文章浏览阅读854次,点赞22次,收藏24次。点对点模型:适用于...
文章浏览阅读854次,点赞22次,收藏24次。点对点模型:适用于...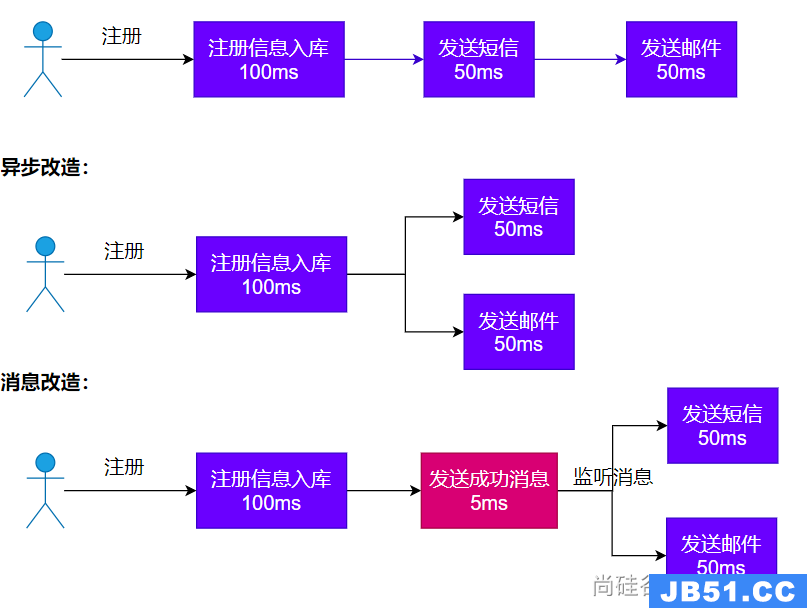 文章浏览阅读1.5k次,点赞2次,收藏3次。kafka 自动配置在Ka...
文章浏览阅读1.5k次,点赞2次,收藏3次。kafka 自动配置在Ka... 文章浏览阅读1.3w次,点赞6次,收藏33次。Offset Explorer(...
文章浏览阅读1.3w次,点赞6次,收藏33次。Offset Explorer(...