我可以使用一个Spout本身做同样的事情,但是我想要跨多个分支分享负载.我无法得到扩展负载的逻辑.由于消息的偏移量将不会被知道,直到特定的出口完成消耗部分(即基于缓冲区大小设置).
任何人都可以在逻辑/算法上如何解决这个问题吗?
提前感谢你的时间.
更新响应答案:
现在在卡夫卡使用多分区(即5)
以下是使用的代码:
builder.setSpout(“spout”,new KafkaSpout(cfg),5);
在每个分区上用800 MB数据进行淹水测试,花费〜22秒完成阅读.
再次使用parallelism_hint = 1的代码
即builder.setSpout(“spout”,新的KafkaSpout(cfg),1);
现在需要更多〜23秒!为什么?
根据Storm Docs setSpout()声明如下:
public SpoutDeclarer setSpout(java.lang.String id,IRichSpout spout,java.lang.Number parallelism_hint)
哪里,
parallelism_hint – 是执行此喷口应分配的任务数.每个任务将在群集周围某个进程的线程上运行.
解决方法
阅读Relationship between Spout parallelism and number of kafka partitions.
在使用kafka-spout进行风暴时需要注意两件事情
>在KafkaSpout上可以拥有的最大并行度是分区数.
>我们可以将负载拆分成多个kafka主题,并为每个主题分别提供spout实例.即.每个喷口处理一个单独的主题.
因此,如果我们有一个情况,每个主机的kafka分区配置为1,主机数为2.即使我们将喷嘴并行度设置为10,预期的最大值只有2是分区数.
如何提到Kafka喷口中的分区数?
List<HostPort> hosts = new ArrayList<HostPort>();
hosts.add(new HostPort("localhost",9092));
SpoutConfig objConfig=new SpoutConfig(new KafkaConfig.StaticHosts(hosts,4),"spoutCaliber","/kafkastorm","discovery");
可以看到,这里的经纪人可以使用hosts.add添加,而且在新的KafkaConfig.StaticHosts(hosts,4)代码片段中将partion号指定为4.
如何提及卡夫卡喷嘴的并行提示?
builder.setSpout("spout",spout,4);
在使用setSpout方法将拓扑添加到拓扑中时,您可以提及相同的方法.这里4是并行提示.
更多可能有帮助的链接
Understanding-the-parallelism-of-a-Storm-topology
what-is-the-task-in-twitter-storm-parallelism
免责声明:!我是新来的风暴和java !!!!所以pls编辑/添加如果它需要一些在哪里.
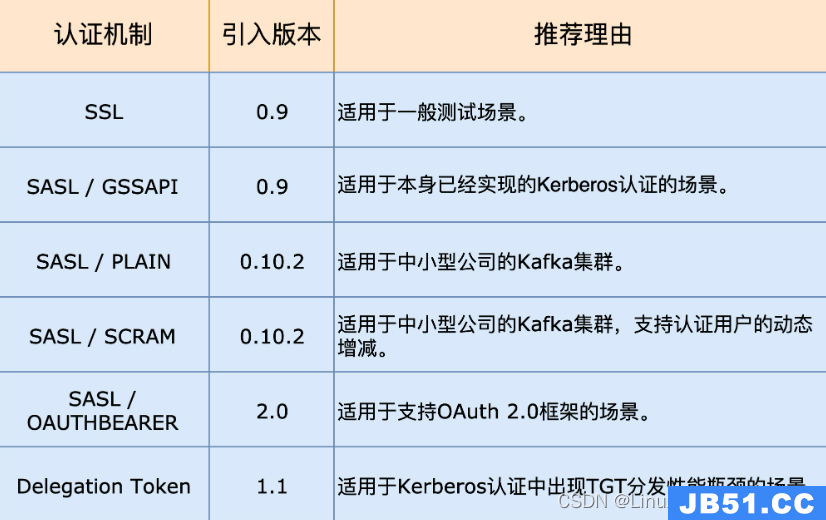 文章浏览阅读4.1k次。kafka认证_kafka认证
文章浏览阅读4.1k次。kafka认证_kafka认证 文章浏览阅读1.4k次,点赞25次,收藏10次。Kafka 生产者发送...
文章浏览阅读1.4k次,点赞25次,收藏10次。Kafka 生产者发送... 文章浏览阅读854次,点赞22次,收藏24次。点对点模型:适用于...
文章浏览阅读854次,点赞22次,收藏24次。点对点模型:适用于...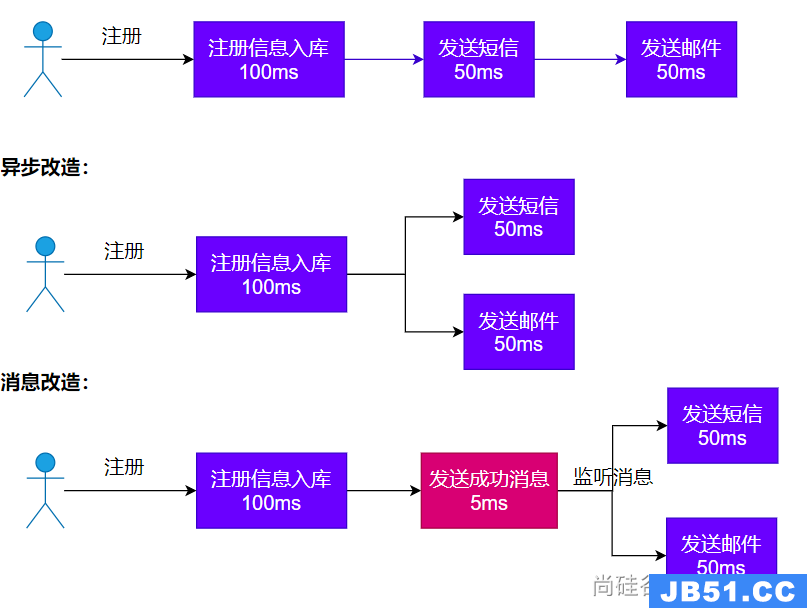 文章浏览阅读1.5k次,点赞2次,收藏3次。kafka 自动配置在Ka...
文章浏览阅读1.5k次,点赞2次,收藏3次。kafka 自动配置在Ka... 文章浏览阅读1.3w次,点赞6次,收藏33次。Offset Explorer(...
文章浏览阅读1.3w次,点赞6次,收藏33次。Offset Explorer(...