numactl使用
numactl 通过将 CPU 划分多个 node 减少 CPU 对总线资源的竞争,一般使用在高配置服务器部署多个 CPU 消耗性服务使用。
#numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22
node 0 size: 64141 MB
node 0 free: 52822 MB
#curl http://127.0.0.1:6999/v2/system/numa/info
{"code":200,"message":"OK","data":{"nodenums":2,"cpulist":["0,2,4,6,8,10,12,14,16,18,20,22","1,3,5,7,9,11,13,15,17,19,21,23"],"memsize":["67257405440","67614638080"]}}Intel的NUMA解决方案,放弃了总线的访问方式,将CPU划分到多个Node中,每个node有自己独立的内存空间。NUMA和内存槽间的对应关系是硬件(整机厂商)决定的,如果有的numa没有内存(内存条没插满), 那分配到这个node上的进程性能就变差了。(因为CPU访问内存的通路变长了)
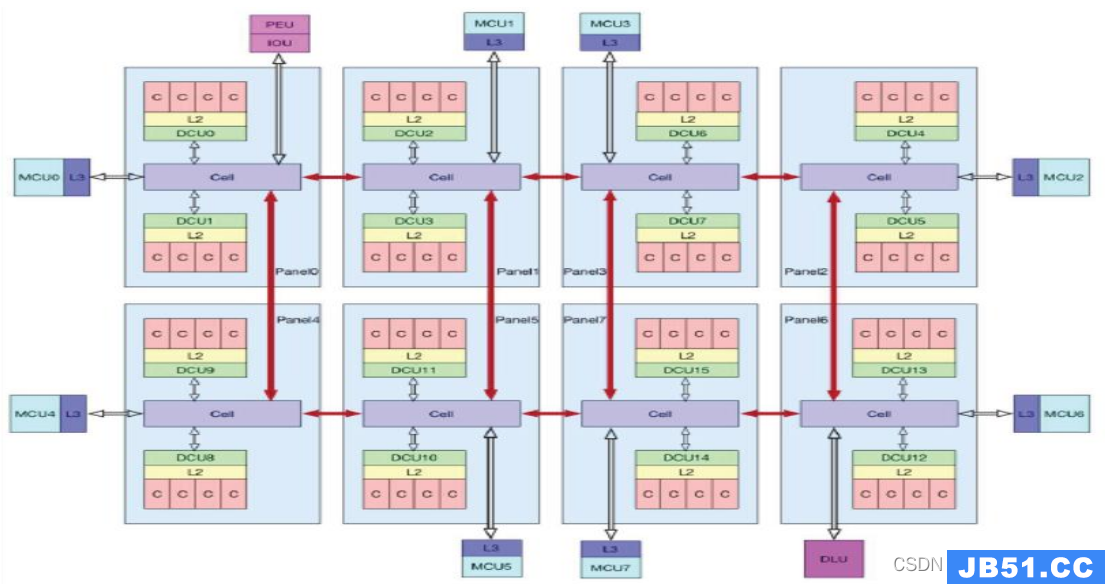
云原生应用
在多CPU架构上,应用程序可以在不同的处理器上运行,应用程序在不同的Socket间调度运行时,访问之前的Socket的内存,这种访问属于远端内存访问,和访问Socket直接连接的内存相比,远端内存访问会增加应用程序的延迟,把这个架构称为非统一内存访问架构(Non-Uniform Memory Access,NUMA架构),NUMA架构下,访问远端内存延迟要比本地内存高,因此在k8s集群中对于某些对性能要求比较高的业务,我们需要通过绑定NUMA来避免远端内存访问;同时,将不同的容器绑定到不同的numa node,有助于减少容器之间的负载争抢,减少高负载容器的影响半径,增强隔离性。
NUMA绑定
-
不绑定。不限制容器运行的numa node,容器内进程可以被调度到任意cpu上,默认会优先在调度到的cpu本地申请内存。
-
只绑定CPU。通过cgroup限制容器的cpu set为某个numa node,容器内进程只会被调度到该numa node对应的cpu上,默认会优先在调度到的cpu本地申请内存。
-
CPU和MEM都绑定同一个NUMA node。限制容器的cpu set和mem set,容器内进程只会被调度到该numa node对应的cpu上,并且只会申请该numa node的本地内存,如果本地内存不足,会使用到swap/申请远端内存(通过内核参数控制)。
Kubernetes调度
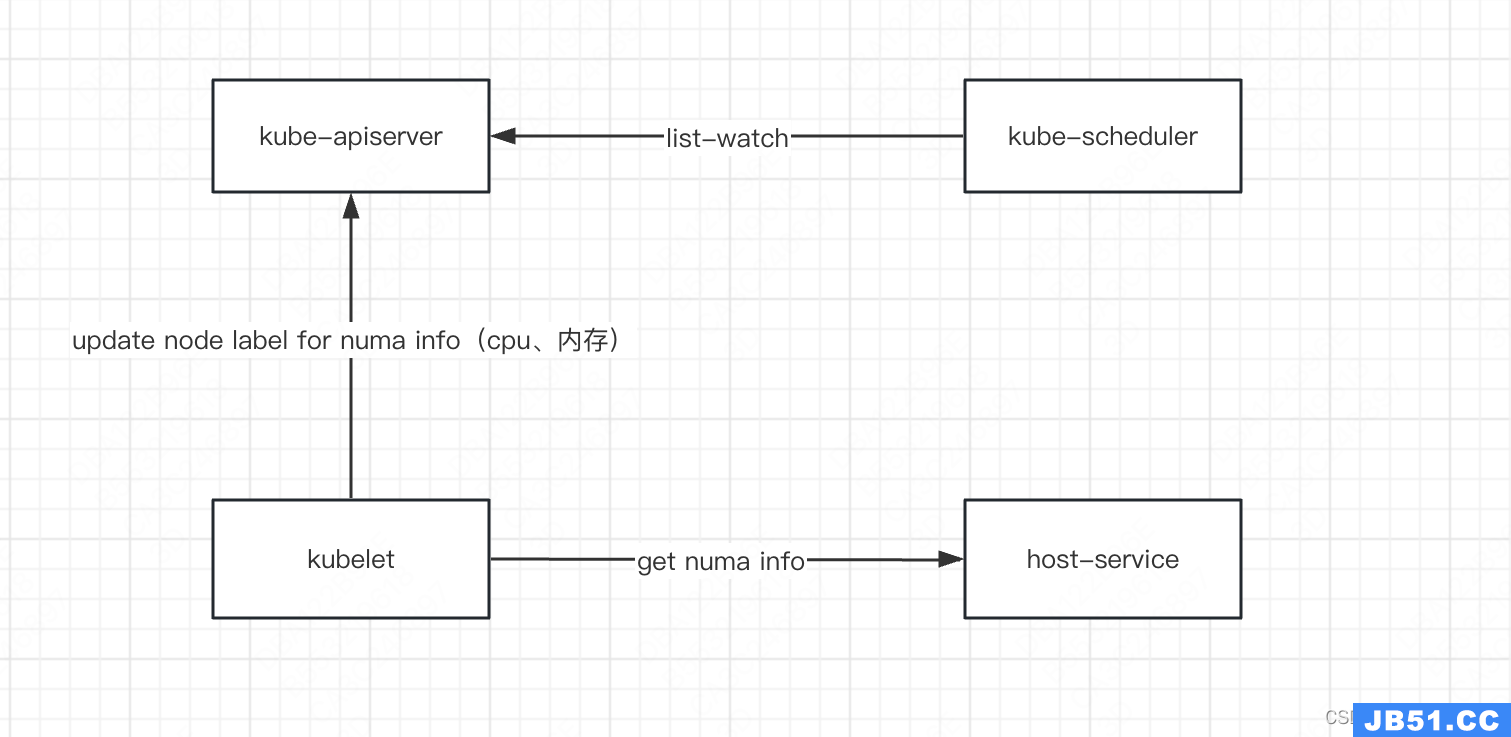
numa信息上报
Annotations: numa.kubernetes.io/numacpu=0,22|1,23
numa.kubernetes.io/numamem=67257405440|67614638080
调度
scheduler cache中每个node存储了当前node的numa节点的分配信息(cpu/mem request),在预选阶段,scheduler会根据当前已经调度并且绑定了numa的pod的cpu/mem request,以及每个numa node的cpu/mem容量,来计算当前某个numa node可分配的资源量,如果pod要求cpu绑定numa,则会计算numa node的cpu余量是否大于pod的cpu request,具体计算如下:
NumaNodei CpuAllocable = NumaNodeiCpuTotal * oversale - sum(Podi cpu request);其中podi为调度到该node并且绑定了该numa node cpu的pod。oversale是node cpu超卖系数
pod同时要求mem绑定numa,则会计算numa node的mem余量是否大于pod的mem request,具体计算如下:
NumaNodei MemAllocable = NumaNodeiMemTotal - sum(Podi mem request);其中podi为调度到该node并且绑定了该numa node mem的pod(绑定了numa cpu但是没有绑定numa mem的pod不在其中)
在pod选定node后的assume阶段,会为pod选定具体绑定到哪个numa node,规则如下:
- 如果Pod只绑定numa cpu:选择cpu allocable最大的numa node
- 如果Pod绑定了numa mem:选择mem allocable最大的numa node(前提是该numa node的cpu allocable > pod cpu request)
scheduler给pod选定好numa node后,会把选定的结果写入到pod的annotation中:
numa.kubernetes.io/numacpu:1,7 指定pod绑定的numa cpu node
numa.kubernetes.io/numamem:1 指定pod绑定的numa mem node
兼容非NUMA调度
上面的调度设计在进行numa调度时,只关心了numa node资源的申请量,没有关注具体numa node的使用量,正常情况集群节点都是绑定numa和不绑定numa的pod混部的,不绑定numa的pod同样会使用到numa node的资源(包括一些系统组件也会使用),因此调度时只能看到一部分pod(指明绑定numa的pod)对numa node资源的使用,导致选择的numa node并不是最优。
-
忽略了没有绑定numa node的pod资源
-
忽略了只绑定cpu的pod占用的numa node的mem资源(绑定了cpu的pod默认会申请本地内存,因此绑定了cpu的pod的mem request也会影响numa node整体的mem allocable)
对于cpu来说,这种分配方式并不会有太大问题,因为cpu可以灵活调度,numa调度时我们只计算绑定了numa cpu的pod是可以接受的,但是对于内存来说,numa node上申请了的内存无法做到随时迁移,这就会导致调度器视角numa node的mem资源足够,但是等到pod真正使用时,由于没有绑定numa node的pod申请的内存,导致numa node的mem资源不足,造成swap中断或者远端内存申请,这会对绑定mem的pod来带来性能损耗。
kubelet启动
kubelet会根据pod的annotation为pod绑定指定的numa node,分别设置到cgroup的cpuset.cpus和cpuset.mems中。
[root@test docker-d541bfb739228.scope]# cat cpuset.cpus
1,23
[root@test docker-d541bfb739228.scope]# cat cpuset.mems
1 文章浏览阅读3.8k次。上篇文章详细介绍了弹性云混部的落地历...
文章浏览阅读3.8k次。上篇文章详细介绍了弹性云混部的落地历... 文章浏览阅读897次。对于cpu来说,这种分配方式并不会有太大...
文章浏览阅读897次。对于cpu来说,这种分配方式并不会有太大... 文章浏览阅读763次。但是此时如果配置成 NONE, 租户创建成功...
文章浏览阅读763次。但是此时如果配置成 NONE, 租户创建成功...