 文章浏览阅读5.3k次,点赞10次,收藏39次。本章详细写了mysq...
文章浏览阅读5.3k次,点赞10次,收藏39次。本章详细写了mysq... 文章浏览阅读1.8k次,点赞50次,收藏31次。本篇文章讲解Spar...
文章浏览阅读1.8k次,点赞50次,收藏31次。本篇文章讲解Spar...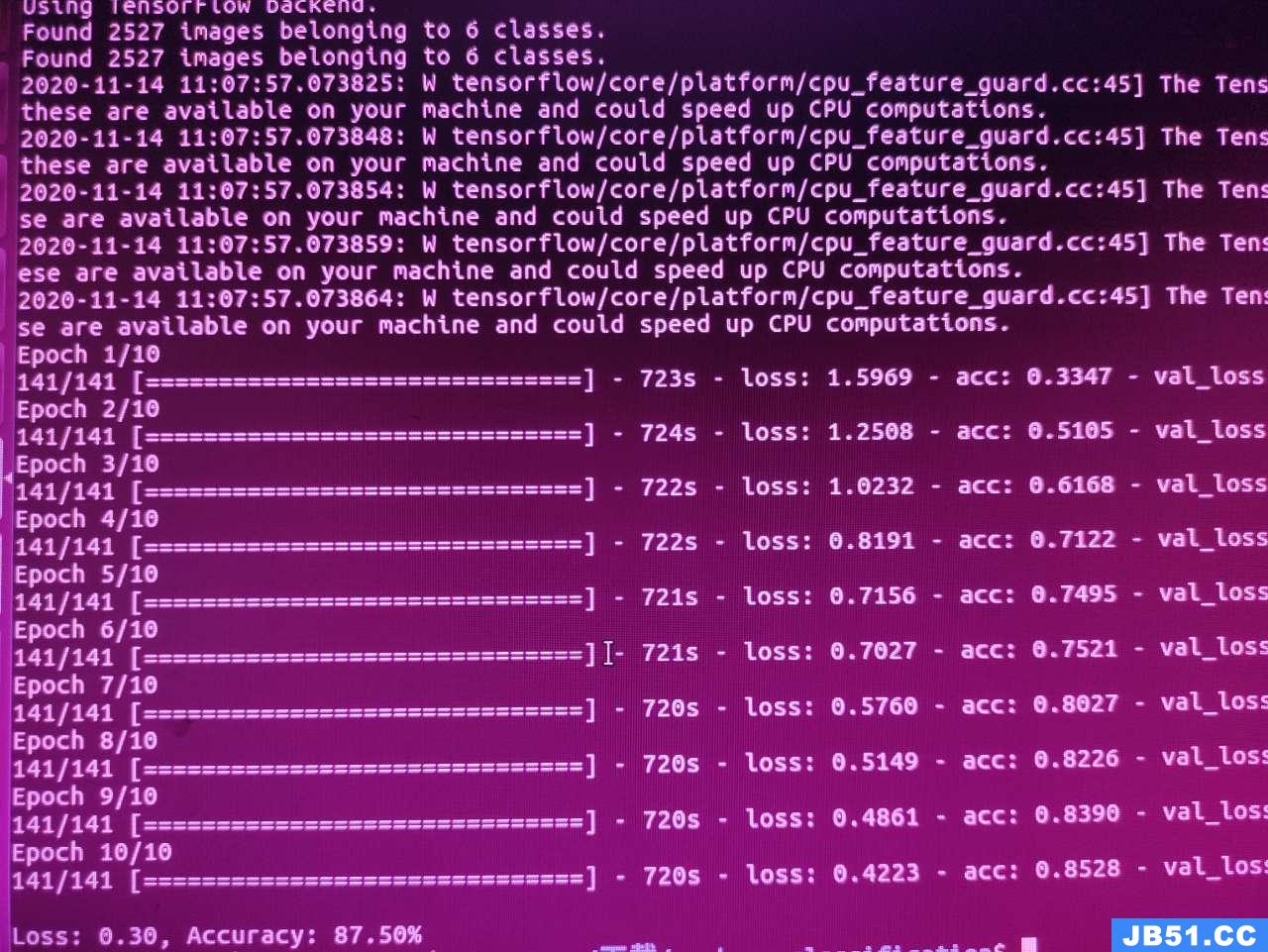 文章浏览阅读928次,点赞27次,收藏18次。
文章浏览阅读928次,点赞27次,收藏18次。 文章浏览阅读1.1k次,点赞24次,收藏24次。作用描述分布式协...
文章浏览阅读1.1k次,点赞24次,收藏24次。作用描述分布式协... 文章浏览阅读1.5k次,点赞26次,收藏29次。为贯彻执行集团数...文章浏览阅读1.2k次,点赞26次,收藏28次。在安装Hadoop之前...
文章浏览阅读1.5k次,点赞26次,收藏29次。为贯彻执行集团数...文章浏览阅读1.2k次,点赞26次,收藏28次。在安装Hadoop之前...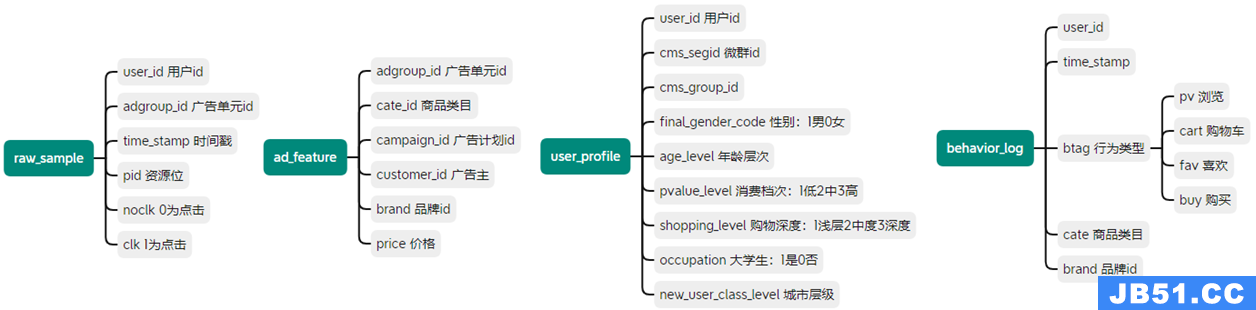 文章浏览阅读974次,点赞19次,收藏24次。# 基于大数据的K-...
文章浏览阅读974次,点赞19次,收藏24次。# 基于大数据的K-...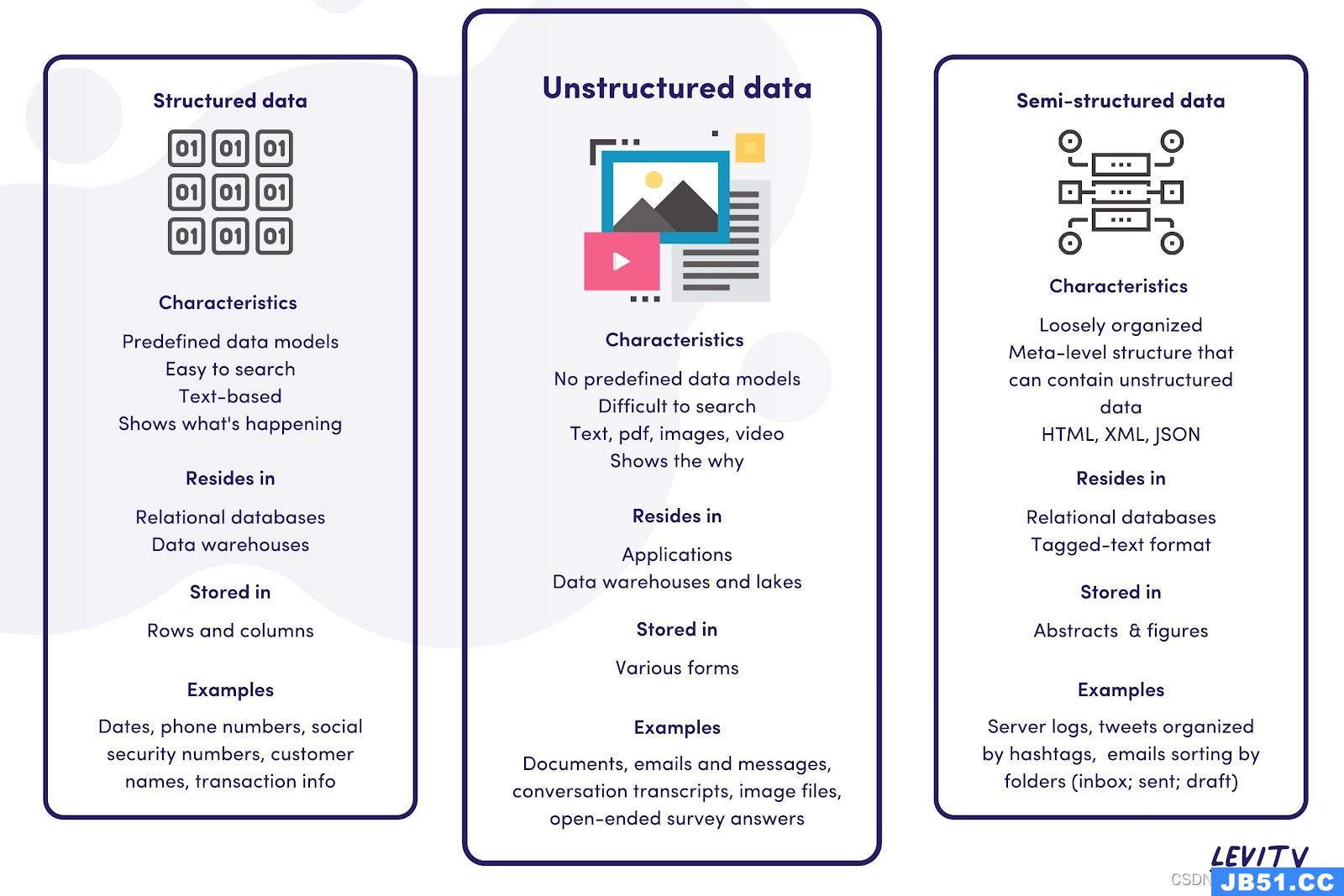 文章浏览阅读1.7k次,点赞6次,收藏10次。Hadoop入门理论
文章浏览阅读1.7k次,点赞6次,收藏10次。Hadoop入门理论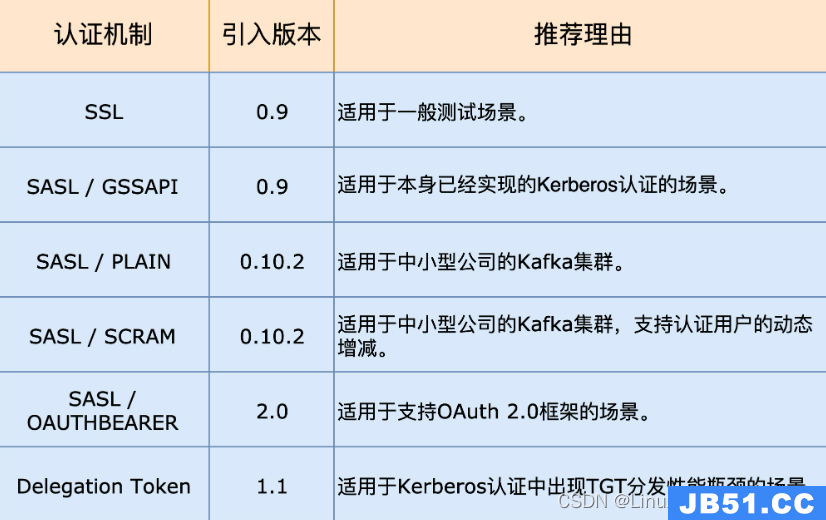 文章浏览阅读4.1k次。kafka认证_kafka认证
文章浏览阅读4.1k次。kafka认证_kafka认证