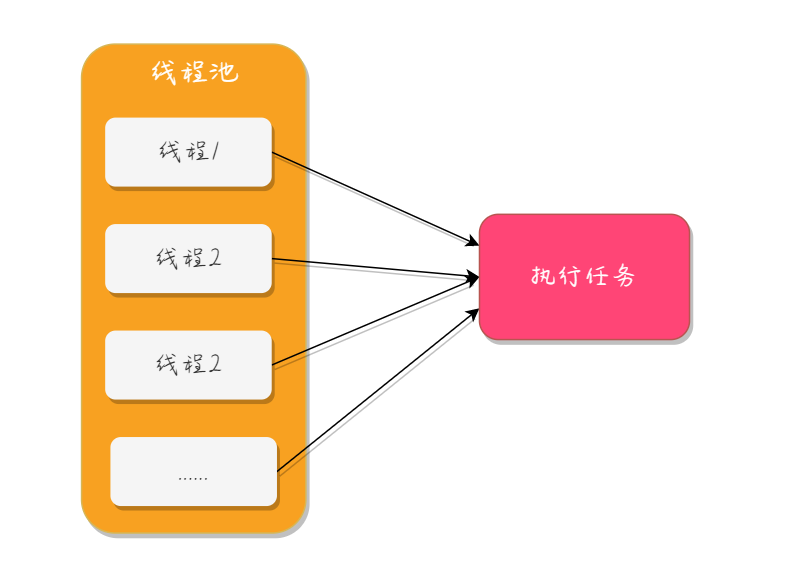
 在 Java 语言中,提高程序的执行效率有两种实现方法,一个是...
在 Java 语言中,提高程序的执行效率有两种实现方法,一个是...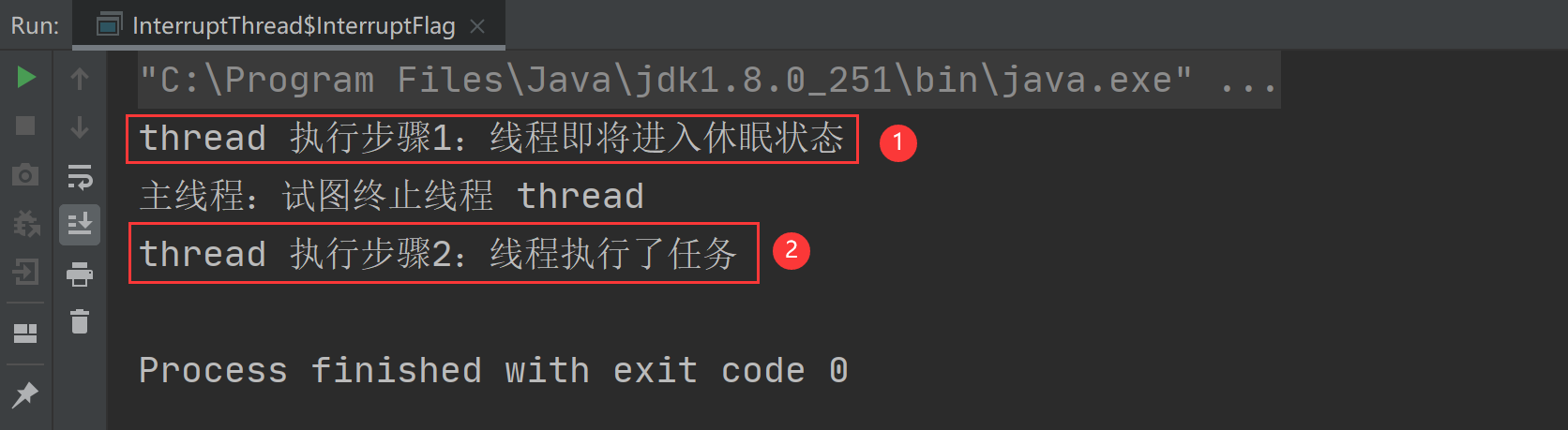 在 Java 中停止线程的实现方法有以下 3 种: 自定义中断标识...
在 Java 中停止线程的实现方法有以下 3 种: 自定义中断标识...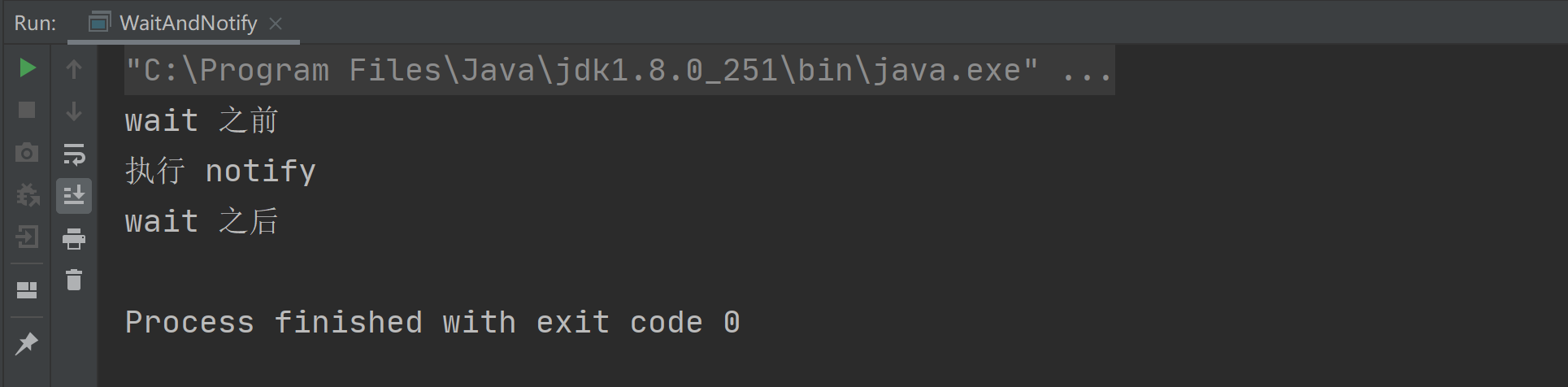 在多线程编程中,wait 方法是让当前线程进入休眠状态,直到另...
在多线程编程中,wait 方法是让当前线程进入休眠状态,直到另...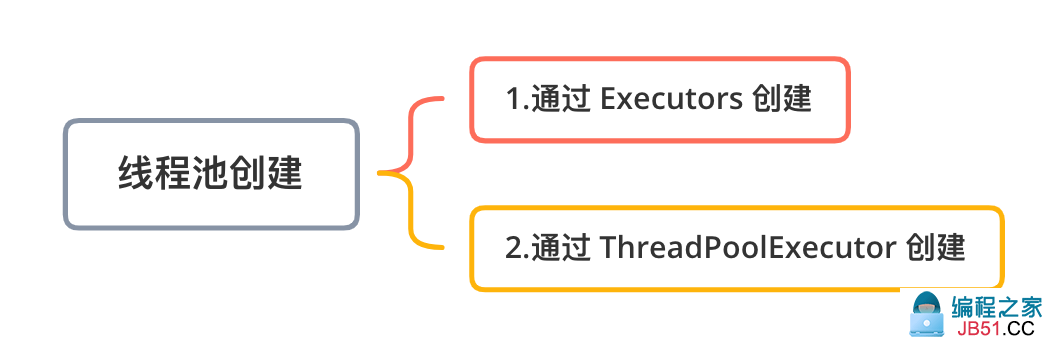 在 Java 语言中,并发编程都是通过创建线程池来实现的,而线...
在 Java 语言中,并发编程都是通过创建线程池来实现的,而线... sleep 方法和 wait 方法都是用来将线程进入休眠状态的,并且...
sleep 方法和 wait 方法都是用来将线程进入休眠状态的,并且...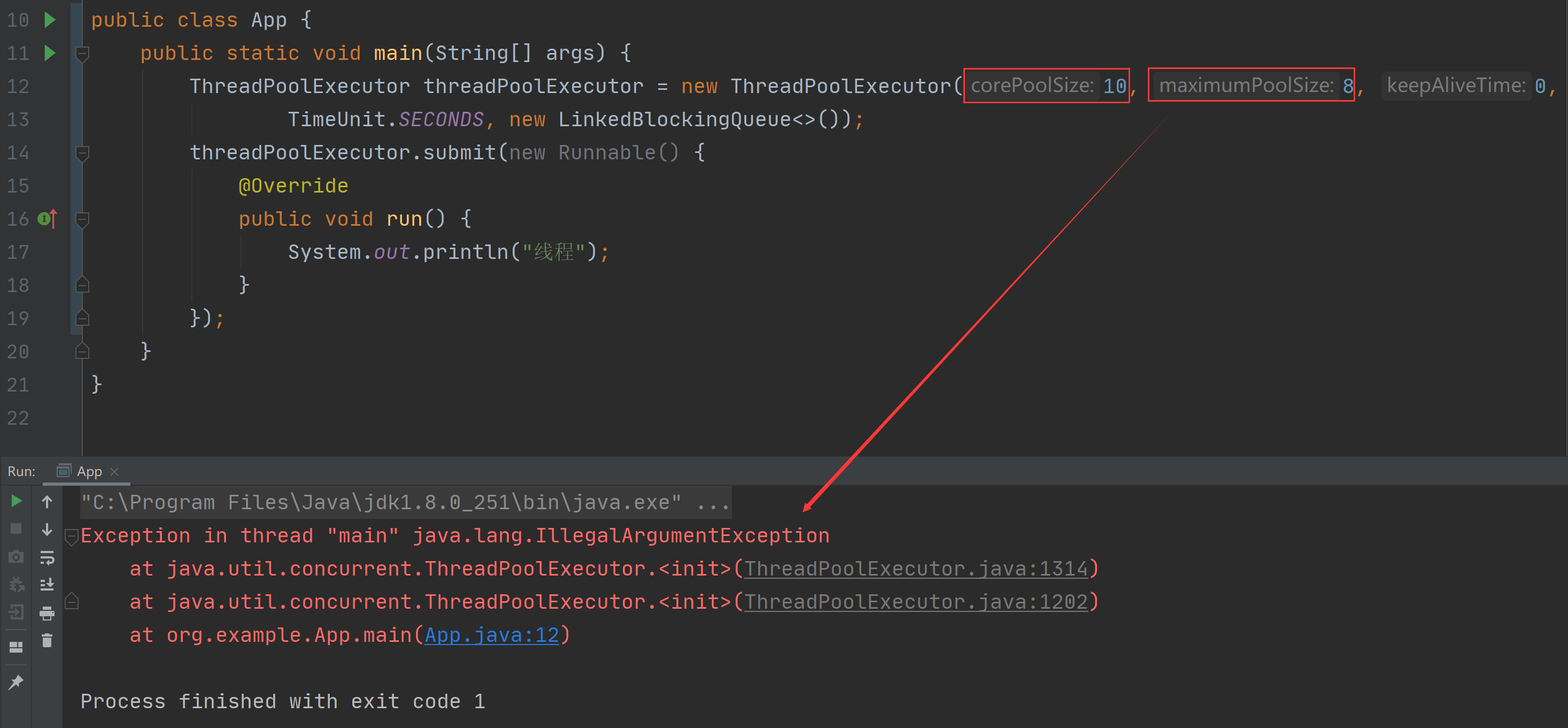 所谓的线程池的 7 大参数是指,在使用 ThreadPoolExecutor 创...
所谓的线程池的 7 大参数是指,在使用 ThreadPoolExecutor 创...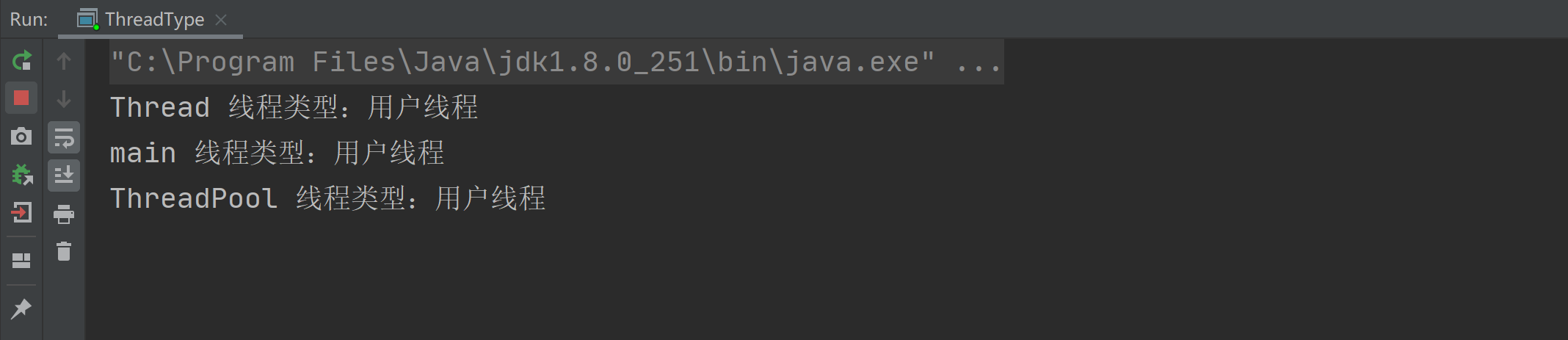 在 Java 语言中,线程分为两类:用户线程和守护线程,默认情...
在 Java 语言中,线程分为两类:用户线程和守护线程,默认情...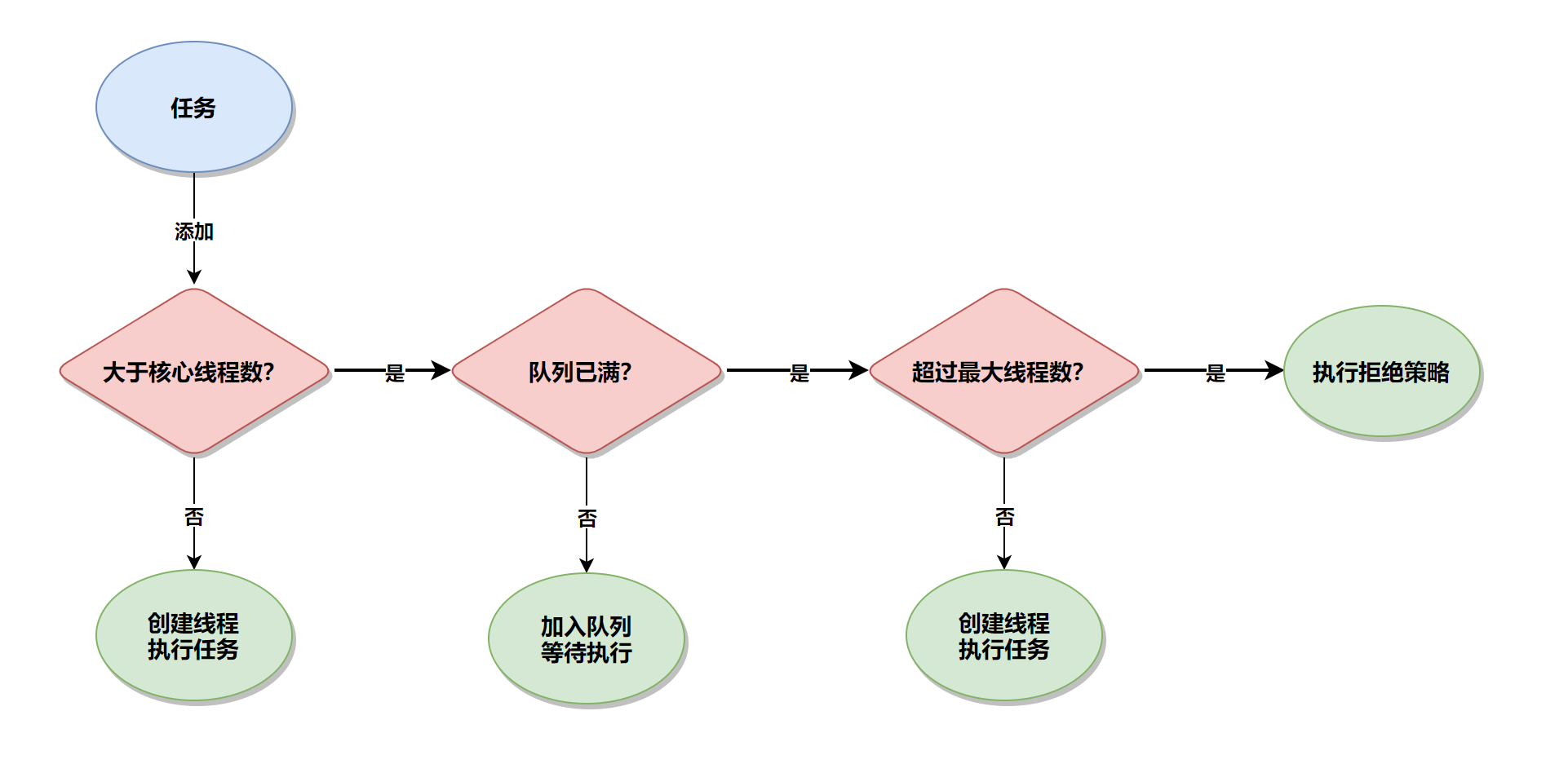 聊到线程池就一定会聊到线程池的执行流程,也就是当有一个任...
聊到线程池就一定会聊到线程池的执行流程,也就是当有一个任...