1 Solr
1.1 简介
Solr采用Lucene搜索库为核心,提供全文索引和搜索开源企业平台,提供REST的HTTP/XML和JSON的API,本教程以solr8.11作为测试环境,jdk版本需要1.7及以上版本
1.2 入门使用
1.2.1 下载及准备
Solr 可从https://solr.apache.org/downloads.html获得:最新版 Solr 下载。
有三个独立的包:
- solr-8.11.0.tgz 适用于 Linux/Unix/OSX 系统
- solr-8.11.0.zip 适用于 Microsoft Windows 系统
- solr-8.11.0-src.tgz包 Solr 源代码
解压:
解压后目录布局:
bin
此目录中包含几个重要的脚本,这些脚本将使使用 Solr 更容易。solr和solr.cmd
这是Solr的控制脚本,也称为bin/solr(对于 Linux)或者bin/solr.cmd(对于 Windows)。这个脚本是启动和停止Solr的首选工具。也可以在运行SolrCloud模式时创建集合或内核、配置身份验证以及配置文件。post
Post Tool,它提供了用于发布内容到Solr的一个简单的命令行界面。solr.in.sh和solr.in.cmd
这些分别是为 Linux 和 Windows 系统提供的属性文件。在这里配置了Java、Jetty 和 Solr的系统级属性。许多这些设置可以在使用bin/solr或者bin/solr.cmd时被覆盖,但这允许你在一个地方设置所有的属性。install_solr_services.sh
该脚本用于Linux 系统以安装 Solr 作为服务
contrib
Solr的contrib目录包含 Solr 专用功能的附加插件。dist
该dist目录包含主要的Solr.jar文件。docs
该docs目录包括一个链接到在线 Javadocs 的 Solr。example
该example目录包括演示各种Solr功能的几种类型的示例licenses
该licenses目录包括Solr使用的第三方库的所有许可证。server
此目录是Solr应用程序的核心所在。此目录中的 README 提供了详细的概述,但以下是一些特点:Solr的Admin UI(server/solr-webapp)Jetty库(server/lib)- 日志文件(
server/logs)和日志配置(server/resources) - 示例配置(
server/solr/configsets)
1.2.2 启动关闭
解压后进入cmd进入bin目录执行 solr.cmd start(或者 solr start)命令,命令行显示如下,启动成功,默认端口8983,也可通过-p指定端口启动

浏览器访问:
http://localhost:8983/solr/,你看到的就是solr的管理界面
关闭使用solr.cmd stop -p 8983 (或者solr stop -p 8983)命令
1.2.3 solr core创建
如果没有使用示例配置启动Solr,则需要创建一个核心才能进行索引和搜索,在创建后通过solr.cmd status 查看状态
core就是solr的一个实例,一个solr服务下可以有多个core,每个core下都有自己的索引库和与之相应的配置文件。命令行和管理页面都可以创建core,在这通过命令行创建。
在命令行输入solr create -c "自定义core_name"
1.2.4 solr配置安全验证
由于启动后默认是不用登入即可访问 Solr 管理界面,这样暴露了Solr核心库,易引起他人删除索引库数据,故配置登入权限才可访问 Solr 管理界面,步骤如下
1.2.4.1 新建security.json(推荐)
创建该security.json文件并将其放在$SOLR_HOME你的安装目录中(这与你所在的位置相同solr.xml,通常为 server/solr )。以下配置用户名密码是:solr:SolrRocks
{
"authentication":{
"blockUnknown": true,
"class":"solr.BasicAuthPlugin",
"credentials":{
"solr":"IV0EHq1OnNrj6gvRCwvFwTrZ1+z1oBbnQdiVC3otuq0= Ndd7LKvVBAaZIF0QAVi1ekCfAJXr1GGfLtRUXhgrF8c="
},
"realm":"My Solr users",
"forwardCredentials": false
},
"authorization":{
"class":"solr.RuleBasedAuthorizationPlugin",
"permissions":[
{
"name":"security-edit",
"role":"admin"
}
],
"user-role":{
"solr":"admin"
}
}
}
配置文件说明
authentication: 启用了基本身份验证和基于规则的授权插件。blockUnknown: 该参数true表示不允许未经身份验证的请求通过。credentials: 定义了一个名为solr的用户,并带有密码,密码是由密码和盐值中间一个空格组成(空格多了登录不成功)"realm":"My Solr users": 我们覆盖该realm属性以在登录提示上显示另一个文本forwardCredentials: 该参数false表示我们让Solr的PKI身份验证处理分布式请求,而不是转发Basic Auth标头。
authorization授权permissions"name":"security-edit""role":"admin"角色已被定义,它有权编辑安全设置。
user-role"solr":"admin"用户已被定义为admin角色。
修改配置文件中用户密码
import org.apache.commons.codec.binary.Base64;
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
import java.util.Random;
public class SolrDemo {
public static void main(String[] args) {
// 密码
String password = "SolrRocks";
MessageDigest digest;
try {
digest = MessageDigest.getInstance("SHA-256");
final Random random = new SecureRandom();
byte[] salt = new byte[32];
random.nextBytes(salt);
digest.reset();
digest.update(salt);
byte[] btPass = digest.digest(password.getBytes(StandardCharsets.UTF_8));
digest.reset();
btPass = digest.digest(btPass);
System.out.println(Base64.encodeBase64String(btPass) + " " + Base64.encodeBase64String(salt));
} catch (NoSuchAlgorithmException e) {
System.err.println("Unknown algorithm: " + e.getMessage());
}
}
}
1.2.4.2 用户增删改(仅作参考)
请求方式:post,Content-Type:application/json
请求路径:http://已有用户名:密码@127.0.0.1:8983/solr/admin/authentication
#新增或修改密码(如果用户名存在,就修改密码,否则就创建用户)
curl --user solr:SolrRocks http://localhost:8983/solr/admin/authentication -H 'Content-type:application/json' -d '{"set-user": {"tom":"TomIsCool", "harry":"HarrysSecret"}}'
#删除用户
curl --user solr:SolrRocks http://localhost:8983/solr/admin/authentication -H 'Content-type:application/json' -d '{"delete-user": ["tom", "harry"]}'
#设置属性
curl --user solr:SolrRocks http://localhost:8983/solr/admin/authentication -H 'Content-type:application/json' -d '{"set-property": {"blockUnknown":false}}'
注意:用户名和密码尽量不要带特殊字符,否则使用地址栏传用户名密码的时候访问不了
1.2.4.3 jetty配置验证
1.2.4.3.1 etc内添加
在解压后的安装目录solr-8.11.1\server\etc内,在此目录下新建verify.properties 配置文件(名字随意),如图
打开文件进行编辑 , 内容如下(格式为:
用户名:密码,权限)
#用户名 密码 权限
user:pass,admin
#也可配置多用户,内容如下:
user: pass,admin
user1: pass,admin
user3: pass,admin
1.2.4.3.2 solr-jetty-context.xml
接着找到目录:solr-8.11.1\server\contexts下的文件solr-jetty-context.xml
<?xml version="1.0"?>
<!DOCTYPE Configure PUBLIC "-//Jetty//Configure//EN" "http://www.eclipse.org/jetty/configure_9_0.dtd">
<Configure class="org.eclipse.jetty.webapp.WebAppContext">
<Set name="contextPath"><Property name="hostContext" default="/solr"/></Set>
<Set name="war"><Property name="jetty.base"/>/solr-webapp/webapp</Set>
<Set name="defaultsDescriptor"><Property name="jetty.base"/>/etc/webdefault.xml</Set>
<Set name="extractWAR">false</Set>
<!-- 添加以下代码 -->
<Get name="securityHandler">
<Set name="loginService">
<New class="org.eclipse.jetty.security.HashLoginService">
<Set name="name">verify-name</Set>
<Set name="config"><SystemProperty name="jetty.home" default="."/>/etc/verify.properties</Set>
</New>
</Set>
</Get>
</Configure>
1.2.4.3.3 web.xml
路径在:solr-8.11.1\server\solr-webapp\webapp\WEB-INF下的web.xml文件
在文件中找到security-constraint的配置,内容如下
<!-- Get rid of error message -->
<security-constraint>
<web-resource-collection>
<web-resource-name>Disable TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method>TRACE</http-method>
</web-resource-collection>
<auth-constraint/>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Enable everything but TRACE</web-resource-name>
<url-pattern>/</url-pattern>
<http-method-omission>TRACE</http-method-omission>
</web-resource-collection>
</security-constraint>
在之后追加如下代码(删除security-constraint,会导致登录的配置无效),具体配置如下,在auth-constraint节点添加角色 admin,并添加登录配置
<security-constraint>
<web-resource-collection>
<web-resource-name>Solr</web-resource-name>
<url-pattern>/</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
</auth-constraint>
</security-constraint>
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>verify-name</realm-name>
</login-config>
1.3 查询页面参数说明
1.3.1 基本查询
| 参数 | 意义 |
|---|---|
| q | 查询的关键字,此参数最为重要,例如,q=id:1,默认为q=:, |
| fl | 指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort |
| start | 返回结果的第几条记录开始,一般分页用,默认0开始 |
| rows | 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页 |
| sort | 排序方式,例如id desc 表示按照 “id” 降序 |
| wt (writer type) | 指定输出格式,有 xml, json, php等 |
| fq(filter query) | 过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的 |
| df | 默认的查询字段,一般默认指定。 |
| qt (query type) | 指定那个类型来处理查询请求,一般不用指定,默认是standard。 |
| indent | 返回的结果是否缩进,默认关闭,用 indent=true |
| version | 查询语法的版本,建议不使用它,由服务器指定默认值。 |
1.3.2 Solr检索运算符
| 符号 | 意义 |
|---|---|
: |
指定字段查指定值,如返回所有值: |
? |
表示单个任意字符的通配 |
* |
表示多个任意字符的通配(不能在检索的项开始使用*或者?符号) |
~ |
表示模糊检索,如检索拼写类似于”roam”的项这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的记录。 |
+ |
存在操作符,要求符号”+”后的项必须在文档相应的域中存在 |
() |
用于构成子查询 |
[] |
包含范围检索,如检索某时间段记录,包含头尾,date:[201507 TO 201510] |
{} |
不包含范围检索,如检索某时间段记录,不包含头尾date:{201507 TO 201510} |
1.3.3 高亮
| 符号 | 意义 |
|---|---|
| h1 | 是否高亮,hl=true,表示采用高亮 |
| hl.fl | 设定高亮显示的字段,用空格或逗号隔开的字段列表。要启用某个字段的highlight功能,就得保证该字段在schema中是stored。如果该参数未被给出,那么就会高亮默认字段 standard handler会用df参数,dismax字段用qf参数。你可以使用星号去方便的高亮所有字段。如果你使用了通配符,那么要考虑启用hl.requiredFieldMatch选项。 |
| hl.requireFieldMatch | 如果置为true,除非用hl.fl指定了该字段,查询结果才会被高亮。它的默认值是false。 |
| hl.usePhraseHighlighter | 如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮。 |
| hl.highlightMultiTerm | 如果使用通配符和模糊搜索,那么会确保与通配符匹配的term会高亮。默认为false,同时hl.usePhraseHighlighter要为true。 |
| hl.fragsize | 返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且整个字段的值会被返回。 |
1.3.4 分组(Field Facet)
facet 参数字段必须被索引,facet=on 或 facet=true
| 符号 | 意义 |
|---|---|
| facet.field | 分组的字段 |
| facet.prefix | 表示Facet字段前缀 |
| facet.limit | Facet字段返回条数 |
| facet.offict | 开始条数,偏移量,它与facet.limit配合使用可以达到分页的效果 |
| facet.mincount | Facet字段最小count,默认为0 |
| facet.missing | 如果为on或true,那么将统计那些Facet字段值为null的记录 |
| facet.sort | 表示 Facet 字段值以哪种顺序返回 .格式为 true(count)或false(index,lex),true(count) 表示按照 count 值从大到小排列,false(index,lex) 表示按照字段值的自然顺序 (字母 , 数字的顺序 ) 排列 . 默认情况下为 true(count) |
1.3.5 分组(Date Facet)
对日期类型的字段进行 Facet. Solr 为日期字段提供了更为方便的查询统计方式 .注意 , Date Facet的字段类型必须是 DateField( 或其子类型 ). 需要注意的是 , 使用 Date Facet 时 , 字段名 , 起始时间 , 结束时间 , 时间间隔这 4 个参数都必须提供 。
| 符号 | 意义 |
|---|---|
| facet.date | 该参数表示需要进行 Date Facet 的字段名 , 与 facet.field 一样 , 该参数可以被设置多次 , 表示对多个字段进行 Date Facet. |
| facet.date.start | 起始时间 , 时间的一般格式为 ” 2015-12-31T23:59:59Z”, 另外可以使用 ”NOW”,”YEAR”,”MONTH” 等等 , |
| facet.date.end | 结束时间 |
| facet.date.gap | 时间间隔,如果 start 为 2015-1-1,end 为 2016-1-1,gap 设置为 ”+1MONTH” 表示间隔1 个月 , 那么将会把这段时间划分为 12 个间隔段 . |
| facet.date.hardend | 表示 gap 迭代到 end 时,还剩余的一部分时间段,是否继续去下一个间隔. 取值可以为 true |
1.4 基本使用
1.4.1 使用Post上传文件
1.4.1.1 Linux下使用
Solr 包含一个简单的命令行工具,即 Post 工具(bin/post 工具),用于将各种类型的内容发布到 Solr 服务器。
bin/post 工具是一个 Unix shell 脚本;对于 Windows使用情况不支持
1.4.1.1.1 索引XML
将文件扩展名为 .xml 的所有文档添加到命名为 gettingstarted 的集合或核心中。
bin/post -c gettingstarted *.xml
将所有带有文件扩展名为 .xml 的文档添加到在端口 8984 上运行的 Solr 上的 gettingstarted 集合/内核。
bin/post -c gettingstarted -p 8984 *.xml
发送 XML 参数以从 gettingstarted 中删除文档。
bin/post -c gettingstarted -d '<delete><id>42</id></delete>'
1.4.1.1.2 索引 CSV
将所有 CSV 文件索引到 gettingstarted
bin/post -c gettingstarted *.csv
将制表符分隔的文件索引到 gettingstarted:
bin/post -c signals -params "separator=%09" -type text/csv data.tsv
内容类型(-type)参数是需要将文件视为正确的类型,否则将被忽略,并记录一个警告,因为它不知道 .tsv 文件是什么类型的内容。该 CSV 处理器支持 separator 参数,并通过使用 -params 设置传递。
1.4.1.1.3 索引 JSON
将所有 JSON 文件编入索引 gettingstarted。
bin/post -c gettingstarted *.json
1.4.1.1.4 索引丰富的文档(PDF、Word、HTML等)
将 PDF 文件索引到 gettingstarted。
bin/post -c gettingstarted a.pdf
自动检测文件夹中的内容类型,并对其进行递归扫描,以便为编入 gettingstarted 的文档进行索引。
bin/post -c gettingstarted afolder/
自动检测文件夹中的内容类型,但将其限制为 PPT 和 HTML 文件并将其索引到 gettingstarted。
bin/post -c gettingstarted -filetypes ppt,html afolder/
1.4.1.1.5 索引到受密码保护的 Solr(基本身份验证)
索引一个 PDF 作为用户 solr 使用密码 SolrRocks:
bin/post -u solr:SolrRocks -c gettingstarted a.pdf
1.4.1.2 Windows下使用
由于bin/post 目前仅作为 Unix shell 脚本存在,但是它将其工作委派给了一个具有跨平台能力的 Java 程序。该 SimplePostTool 可以直接在支持的环境,包括 Windows 上运行。
1.4.1.2.1 SimplePostTool
该 bin/post 脚本目前委托给一个名为 SimplePostTool 的独立 Java 程序。
捆绑到可执行 JAR 中的这个工具可以直接运行 java -jar example/exampledocs/post.jar。可以直接发送命令到 Solr 服务器。
java -jar example/exampledocs/post.jar -h
SimplePostTool version 5.0.0
Usage: java [SystemProperties] -jar post.jar [-h|-] [<file|folder|url|arg> [<file|folder|url|arg>...]]
索引文件示例:
上传csv文件到指定核心实例 : java -Dc=test_core -Dtype=text/csv -jar example/exampledocs/post.jar example/exampledocs/books.csv

如果是上传
xml文件,则xml示例如下所示
<add>
<doc>
<field name="id">USD</field>
<field name="name">One Dollar</field>
<field name="manu">Bank of America</field>
<field name="manu_id_s">boa</field>
<field name="cat">currency</field>
<field name="features">Coins and notes</field>
<field name="price_c">1,USD</field>
<field name="inStock">true</field>
</doc>
<doc> ... </doc>
</add>
1.4.2 Dataimport页面报错
当选中一个核心实例时,Dataimport页面报错
The solrconfig.xml file for this index does not have an operational DataImportHandler defined!
1.4.2.1 修改solrconfig.xml
修改方法在当前核心实例的下操作,比如选中test_core,在路径server\solr\test_core\conf下打开文件solrconfig.xml,在里边加入如下内容,放置的位置你可以放到其他requestHandler 旁边:
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
1.4.2.2 data-config.xml
data-config.xml文件配置在和solrconfig.xml同样位置即可
<dataConfig>
<dataSource name="jdbcDataSource" type="JdbcDataSource"
driver="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:@localhost:1521:orcl"
user="test" password="test"/>
<document>
<entity dataSource="jdbcDataSource" name="country"
query="select * from test" >
<field column="ID" name="id"></field>
<field column="SORT" name="sort"></field>
</entity>
</document>
</dataConfig>
dataconfig的结构不是一成不变的,entity和field元素中的属性是随意的,这主要取决于processor和transformer
以下是entity的默认属性:
name(必需的):name是唯一的,用以标识entityprocessor:只有当datasource不是RDBMS时才是必需的。默认值是SqlEntityProcessortransformer:转换器将会被应用到这个entity上pk:entity的主键,它是可选的,但使用“增量导入”的时候是必需。它跟schema.xml中定义的uniqueKey没有必然的联系,但它们可以相同。rootEntity:默认情况下,document元素下就是根实体了,如果没有根实体的话,直接在实体下面的实体将会被看做跟实体。对于根实体对应的数据库中返回的数据的每一行,solr都将生成一个document
SqlEntityProcessor的属性
query (required):sql语句deltaQuery: 只在“增量导入”中使用parentDeltaQuery: 只在“增量导入”中使用deletedPkQuery: 只在“增量导入”中使用deltaImportQuery: (只在“增量导入”中使用) . 如果这个存在,那么它将会在“增量导入”中导入phase时代替query产生作用。
数据源也可以配置在solrconfig.xml中
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost/dbname" user="db_username" password="db_password"/>
driver(必需的):jdbc驱动名称url(必需的):jdbc链接user:用户名password:密码type指定了实现的类型。它是可选的。默认的实现是JdbcDataSourcename是datasources的名字,当有多个datasources时,可以使用name属性加以区分
其他的属性都是随意的,根据你使用的DataSource实现而定。- 多数据源
一个配置文件可以配置多个数据源。增加一个dataSource元素就可以增加一个数据源了。name属性可以区分不同的数据源。如果配置了多于一个的数据源,那么要注意将name配置成唯一的
<dataSource type="JdbcDataSource" name="ds-1" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://db1-host/dbname" user="db_username" password="db_password"/>
<dataSource type="JdbcDataSource" name="ds-2" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://db2-host/dbname" user="db_username" password="db_password"/>
然后这样使用 ..
<entity name="one" dataSource="ds-1" ...>
..
</entity>
<entity name="two" dataSource="ds-2" ...>
..
</entity>
1.4.2.3 迁移jar包
在解压后的solr压缩包dist文件夹内的包(如下所示)迁移到解压后的server\solr-webapp\webapp\WEB-INF\lib文件夹内
1.5 添加中文分词器
1.5.1 下载分词器
下载地址: https://mvnrepository.com/artifact/com.github.magese/ik-analyzer/8.3.0
或者通过maven更新下载
<dependency>
<groupId>com.github.magese</groupId>
<artifactId>ik-analyzer</artifactId>
<version>8.4.0</version>
</dependency>
1.5.2 复制jar包
把下载好的jar包放到以目录:server\solr-webapp\webapp\WEB-INF\lib
1.5.3 修改schema
在solr 6.6之前是schema.xml文件,之后则是managed-schema
添加以下内容
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
1.5.4 重启验证
重启solr服务solr.cmd restart -p 8983
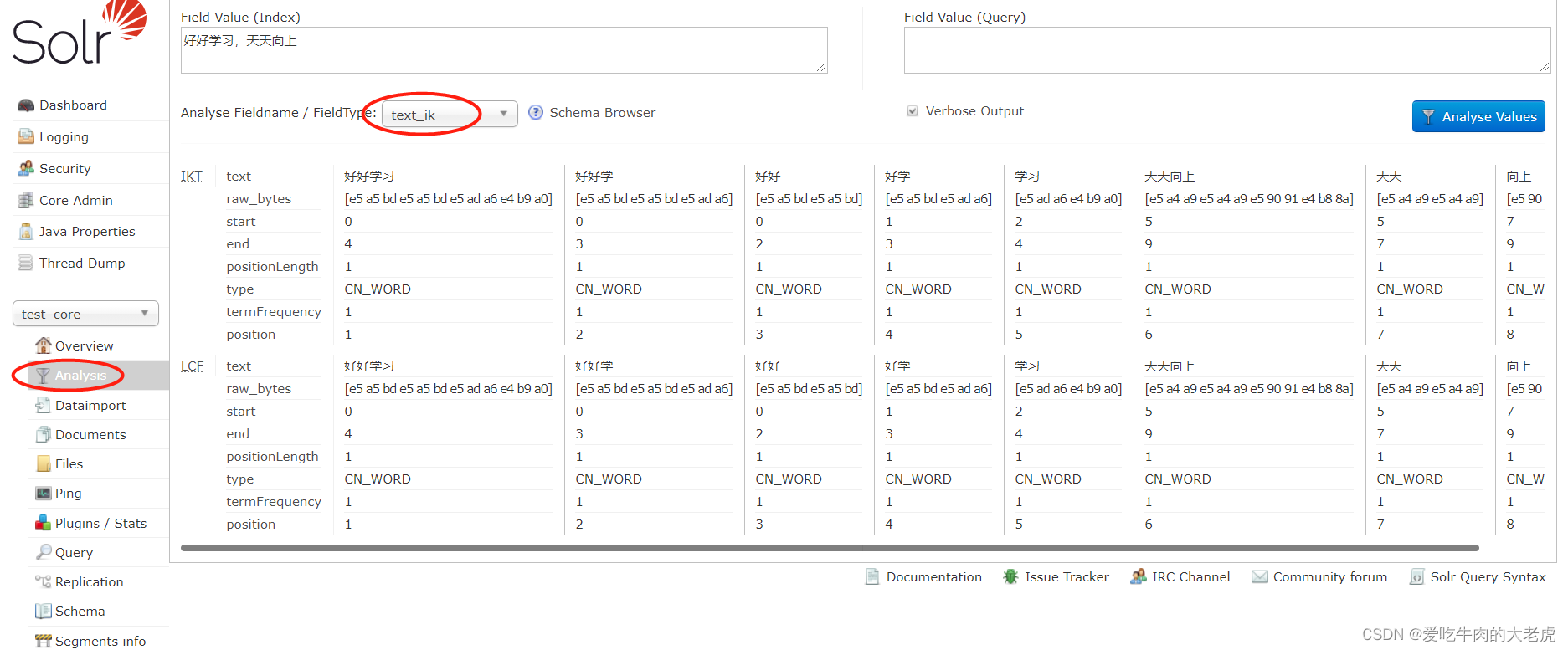
验证
- 打开solr本地地址:
http://127.0.0.1:8983/solr - 分词界面中有text_ik这个选项就说明已经添加成功了, 如下图所示:
 XML轻松学习手册
XML轻松学习手册