机器之心报道
编辑:泽南、杜伟
最高端的 RTX4090 性价比最高,你没想到吧?
虽然因为产品太贵而被吐槽,但提起最强 AI 芯片、高端游戏 GPU,人们还是首先要看英伟达。9 月 20 日晚,GTC 大会在线上召开,万众期待的 RTX 40 系列显卡终于正式发布了。
与以往稍有不同,这场重要的 Keynote 显得朴实无华而且「简短」,黄仁勋直接站在空旷的元宇宙里开讲:

一个半小时收工。
在这场活动中,英伟达展示了 RTX、AI 芯片和元宇宙产品线 Omniverse 的最新进展,还包括它们对人工智能领域新突破的帮助,以及大量应用落地。
在一切开始之前,老黄先展示了一段全可交互的模拟环境 RacerX,它用 Omniverse 构建,物理材质特性、光线追踪、烟雾火焰一个不少。最重要的是「全部没有预渲染过,是跑在单块 GPU 上的」:

黄仁勋说,全部实时处理,这才是未来游戏的该有的样子。
能跑得起 RacerX 的肯定是最新 RTX 40 系显卡,AMD 也要发布新一代 GPU 了,英伟达这次会保持领先吗?如果 N 卡性能更强,代价是什么?
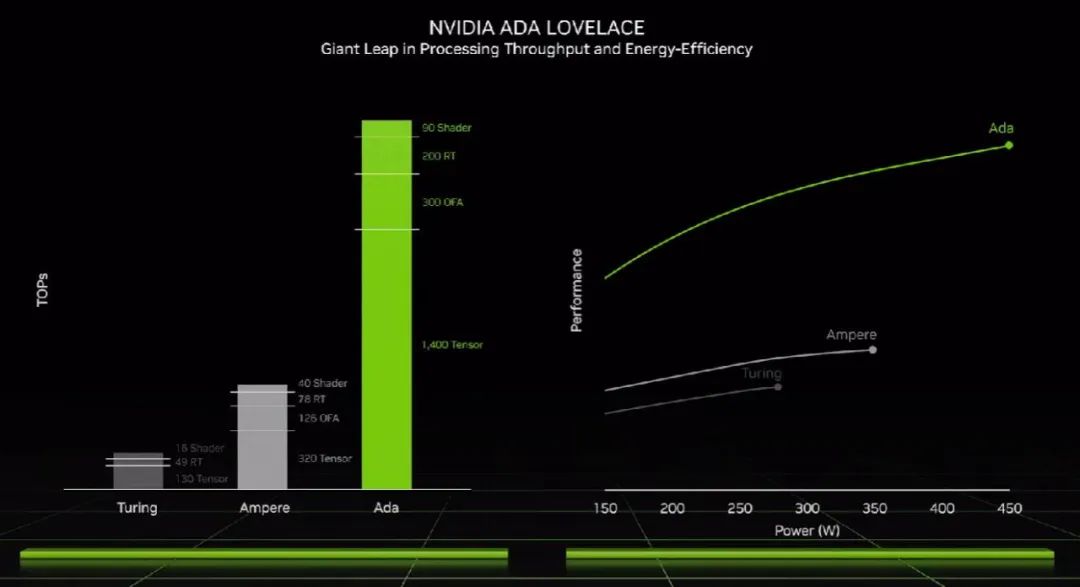
RTX 40 系列 GPU:性能翻倍,光追能力翻倍
这就是英伟达的第三代 RTX 显卡,采用全新的 Ada lovelace 架构。

英伟达转投台积电后,使用定制版 4N 制程加成的 RTX40 系 GPU 被塞进了 760 亿个晶体管,比上一代 Ampere 多了 70%。

25 年前,英伟达推出了可编程着色的 GPU,彻底改变了计算机 3D 图形的世界。到 2018 年,英伟达推出 RTX 架构,新增的 RT Core 用于加速实时光线追踪,Tensor Core 用于处理矩阵运算,又实现了前所未有的效果。在刚刚推出的 Ada lovelace 架构中,三种处理器均有改进和提升,其中:
1、SM 流处理器新增着色器重排序执行能力(Shader Execution Recording),可以实时重新调度任务,把光追速度提升 2-3 倍,在 4090 上能输出 90TFLOPS,性能较上代提升两倍。
2、第三代 RT Core 实现了两倍的光线与三角形求交性能,全新的 Opacity Micromap 引擎可以把 Alpha-test 几何性能提升 2 倍,Micro-Mesh 引擎可提升几何图形的丰富度,而不会带来 BVH 构建和存储资源的更多消耗。
3、新的第四代 Tensor Core 可以实现 1.4 petaFLOPs 算力,AI 性能翻倍。
「Shader Execution Recording 和当年的 cpu 乱序执行一样,是一项重大创新,」黄仁勋说道。「光线追踪很难并行处理,而 GPU 具有高度并行性,SER 通过即时重新安排着色器负载来提升效率,可以提升 2 到 3 倍光追性能,游戏性能提升 25%。」
但我们知道,光线追踪曾经被英伟达前首席科学家 David Krik 说成是「永远不会到来」的技术,性能翻倍也不能让 GPU 保证在如今的各种大型单机游戏中保持高帧率,这个时候就需要 AI 算法了。
DLSS 使用卷积自动编码器 AI 模型,可以在 GPU 输出的低分辨率画面基础上自动脑补出高分辨率,大幅降低性能需求。英伟达在 Ada 架构中引入了 DLSS 3,其可以在分辨率提升的同时自动补帧。DLSS 3 包含四个组件:新的光流加速器、游戏引擎运动矢量、卷积自动编码 AI 帧生成器和 Reflex 低延迟流水线。
DLSS 3 同时处理当前帧和上一帧,光流加速器为神经网络提供运动方向和速度信息,结合图形和像素的运动矢量,输入神经网络就可以生成中间帧了。
「DLSS 3 在不涉及图形管线处理的前提下生成全新帧,相较于单纯的渲染可以将性能提升多至 4 倍,」黄仁勋表示。「而且不论 cpu 还是 GPU 有瓶颈的游戏都可以从中受益。」
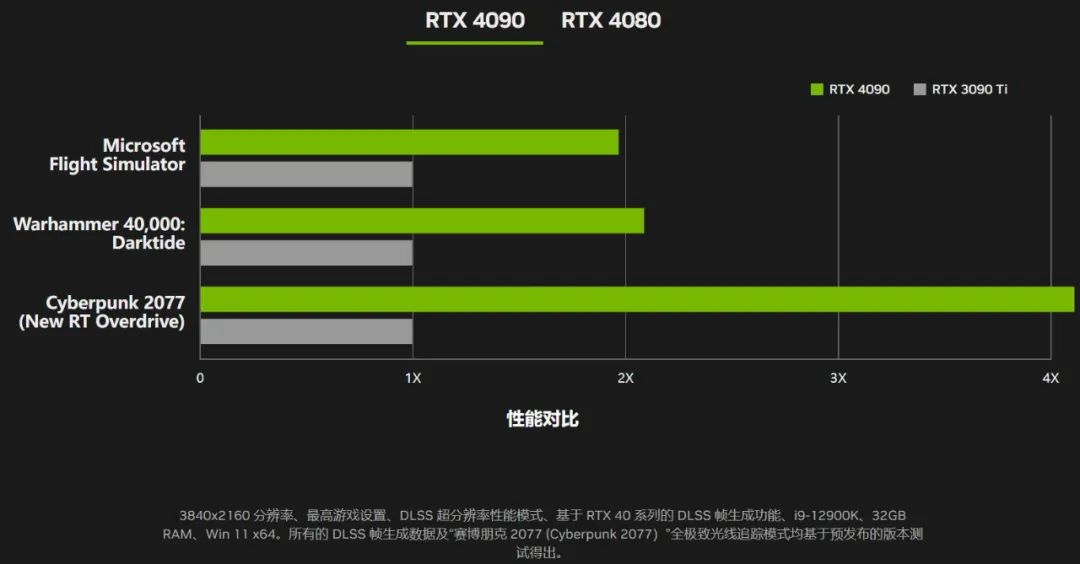
英伟达展示了开 DLSS 3 的赛博朋克 2077、微软模拟飞行等游戏的运行效果:

4 年来,RTX 的数据量提升了 16 倍,现在的一些像素是计算得出,大多数是 AI 推测出来的。
在演示中,几个游戏都是帧数直接乘以二。但值得注意的是,DLSS 3 和新硬件特性高度绑定,30 和 20 系的用户无法享受这样的性能。
英伟达公布了 40 系显卡的多项常规硬件规格:RTX 4090 采用 AD102 GPU,拥有 16384 个 CUDA 核心和 24GB GDDR6X 显存,默认 TDP 为 450W;RTX 4080 16GB 版拥有 9728 个 CUDA 核心,TDP 为 320W;RTX 4080 12G 版拥有 7680 个 CUDA 核心,TDP 为 285W。从功耗上看,从三星 8nm 换到台积电 4N 工艺效率提升显著,同级性能提升了,电源要求没有提升。
性能相比上代提升了多少?通过 SER 优化、更大规模芯片,再加上芯片加速频率从 1.7GHz 提升到 2.52GHz,综合起来可以让 RTX 4090 相比 3090Ti 性能翻一倍;如果看光线追踪,性能则提升了 4 倍。黄仁勋表示,Ada 的同功耗性能是 Ampere 的两倍。
再往下,RTX 4080 可在开 DLSS 时达到 3080Ti 的两倍性能。
最后是价格:RTX 4090 公版售价 1599 美元,10 月 12 日开始售卖;RTX 4080 16GB 售价 1199 美元,12GB 版售价 899 美元。
总结一下就是 90 的价格几乎没涨,80 的价格涨了 500 美元。对于国内用户来说,RTX 40 系的售价是这个样子:4090 12999 元起,4080(16GB)9499 元,4080(12GB)7199 元。
看起来非公版的 RTX 4090 价格将在 15000 左右。
不过,这一代显卡有个需要注意的地方:看起来 12G 版的 4080 似乎是把原定的 70Ti 改了名字。
英伟达 Omniverse 连接了 3D 世界
除了 GPU 和 AI,英伟达也是元宇宙的引领者,黄仁勋介绍了 Omniverse 的一系列进步。
Omniverse 是英伟达构建和运行元宇宙应用的平台,在数字和现实世界交汇之处产生作用。Omniverse 还是一个实时的大型 3D 数据库,构建一个可共享的 3D 世界。Omniverse 更是一个计算平台,你可以编写在其上运行的应用,这些应用成为进入虚拟世界的门户。

今日,黄仁勋发布了关于其 Omniverse 平台的一系列重大更新,它支持了 Ada lovelace GPU,在光线追踪和大型场景性能方面实现巨大飞跃。
首先是基于 GAN 和扩散模型的新型神经渲染工具。OmniGraph 是一个图形渲染引擎,通过程序化的方式控制行为、动作和行动。
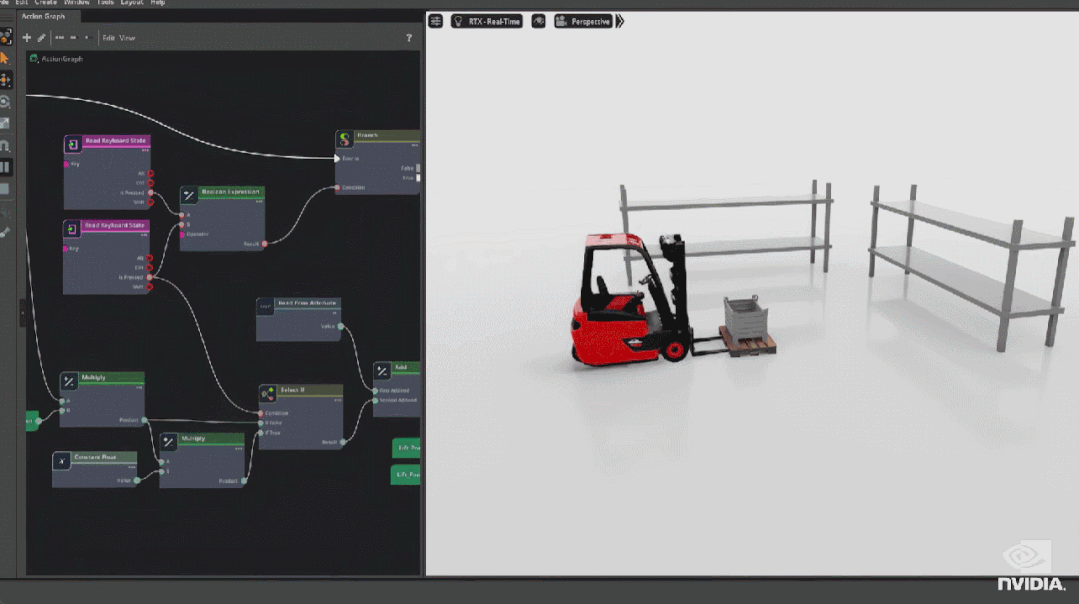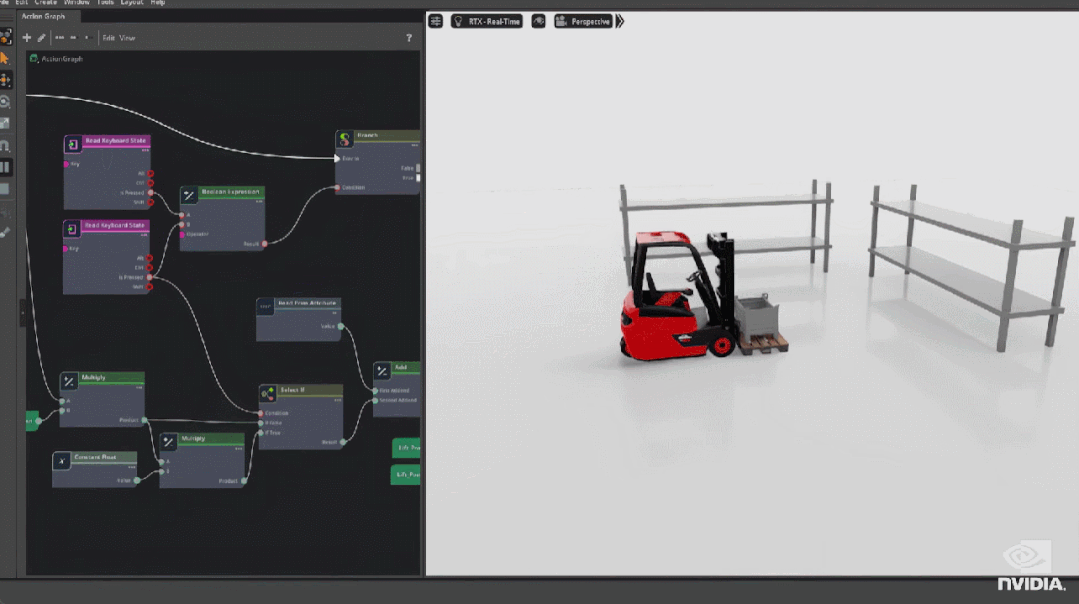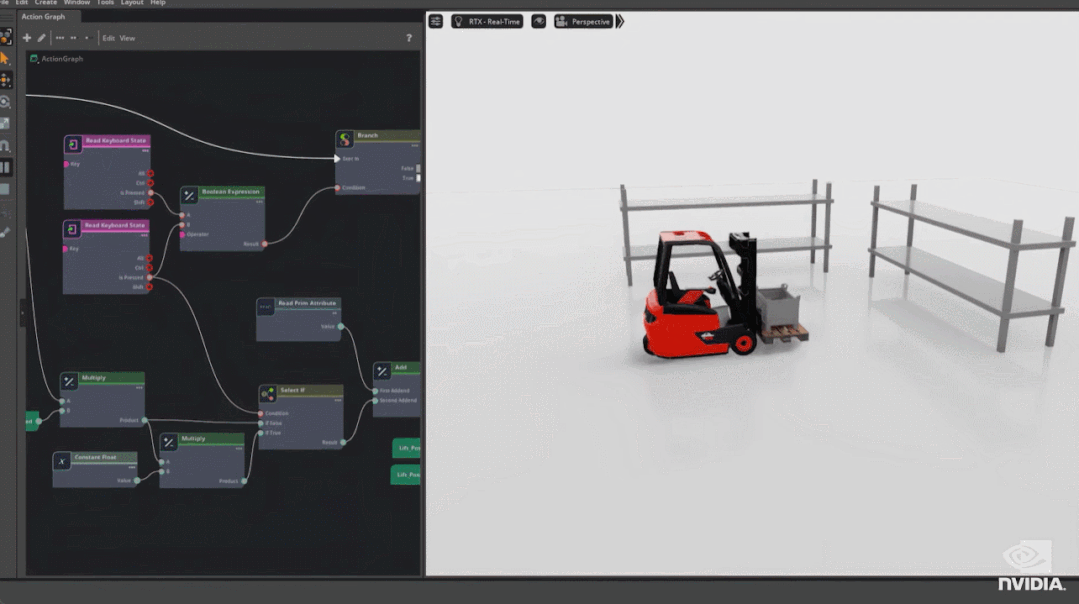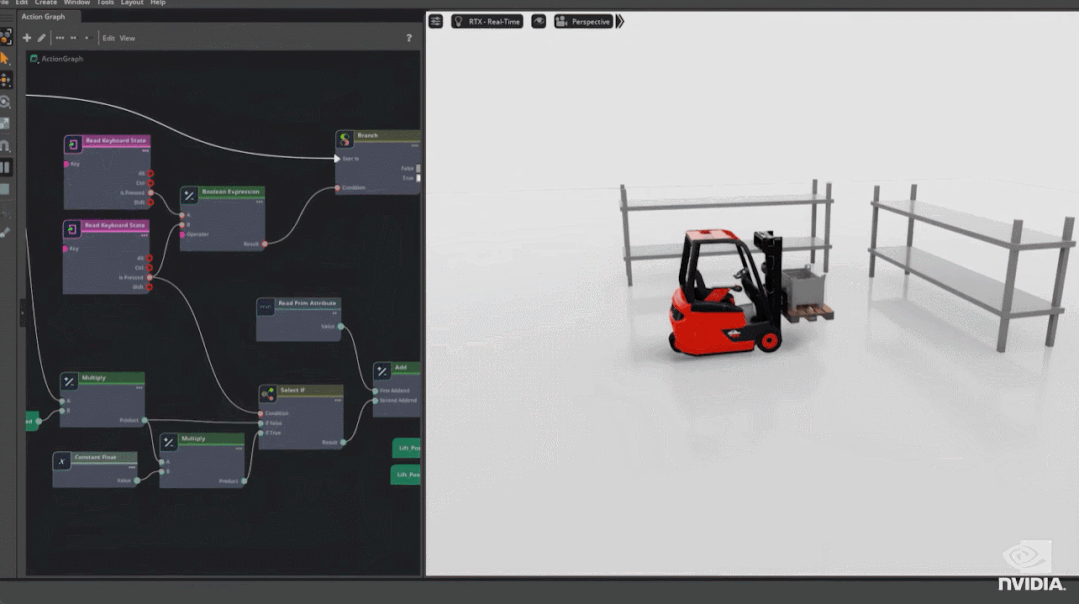
其次是 Omniverse Physics 的重大更新,它可以用来处理复杂的多连接部件对象的运动情况。

然后是全新的 Cloud XR,支持在 VR 中实现 Ada 的强大光线追踪功能。还有首个用于数据生成和数字孪生模拟的 SimReady 素材库。

Replicator 是备受青睐的 Omniverse 应用之一,用来生成合成数据,从而训练自动驾驶汽车、机器人和各种计算机视觉模型。最后是新的 Omniverse JT 连接器,它是一款大型应用,使得工业和制造业可以运用 Omniverse。

可以这么说,Omniverse 是一个企业平台,适用于从产品设计和造型到工程策划、制造、营销和运营的整个产品生命周期。正如互联网连接了各个网站,Omniverse 连接了 3D 世界。
黄仁勋在会上了展示了一些公司利用 Omniverse 为工厂、物流仓库、自动化生产线和工业厂房创建数字孪生的情况。我们可以从以下一些场景案例中探知一二。


Omniverse 计算平台由三部分组成:RTX 计算机,供创作者、设计师和工程师使用;OVX 服务器,用来托管与 Nucleus 数据库的连接并运行虚拟世界模拟;NVIDIA GDN,进入 Omniverse 的门户。
通过 GeForce Now,英伟达构建了一个全球图形交付网络(即 GDN)。该网络覆盖了 100 个地区,提供响应灵敏的超快 RTX 图形内容交付网络(即 CDN),高效串联互联网视频。而 NVIDIA GDN 能够高效串联交互式图形,并结合 NVIDIA RTX PC、云端的 NVIDIA GPU 打造覆盖全球的 Omniverse 计算平台。

NVIDIA Omniverse Cloud 则是一套软件和基础设施即服务套件,用于随时随地在任何设备上设计、发布和体验元宇宙应用。黄仁勋在会上展示了超级跑车和高级电动车解决方案的先行者 Rimac 公司,以及它是如何利用 Omniverse Cloud 为 3D 团队实现协作工作流,并为用户提供先进的 3D 体验。

黄仁勋表示,NVIDIA Omniverse Cloud 是一款 IaaS 产品,可以连接在云上、本地和单个设备上,运行 Omniverse 应用。Replicator 和 Farm 也可以在云上运行,其中 Farm 是渲染农场的扩展引擎。目前,用户可以在 AWS 上使用 Replicator 和 Farm 容器。

新一代自动驾驶芯片 Drive Thor
在自动驾驶领域,车企都需求更强的算力,而英伟达产品的每代性能都要翻倍。
当前,智能机器开发掀起了一波 AI 浪潮,深度学习的参与更为系统能力的提升打开了新的大门。从软件的开发方式到运行方式,一切都变得截然不同。因此,打造新一代处理器势在必行。英伟达 Xavier 是世界上第一款专为深度学习设计的自动驾驶超级芯片,之后每两年便在处理器性能上完成一次巨大飞跃。
同时,为了拓展自动驾驶领域,提升驾驶的安全性,传感器在数量和分辨率上面临同步增长。同时引入更复杂的 AI 模型,所有这些因素都驱使英伟达不断提升性能。
2021 年,英伟达推出了 1000 TOPS 的 SoC——Atlan。今天,黄仁勋表示它的位置已被 Thor 取代。Thor 的吞吐量是 Atlan 的两倍,交付性能也是 Atlan 的两倍以上。实现这些目标离不开三个因素:Grace、Hopper 和 Ada lovelace,其中 Grace 提供了令人惊叹的 Transformer 引擎、ViT 的快速变革,Ada 中的多实例 GPU 有助于车载计算资源的集中化,将成本降低数百美元。
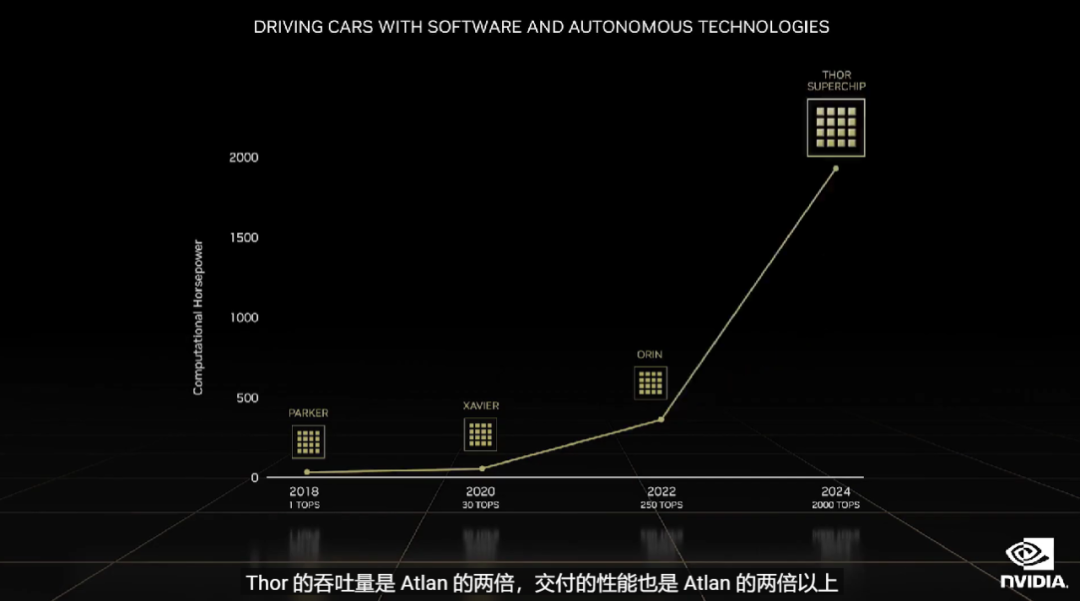
Nvidia Drive Thor 采用很多新技术,它可以被配置为多种模式,将其 2000 TOPS 和 2000 TFLOPs 全部用于自动驾驶工作流。同时可以将其配置为一部分用于驾驶舱 AI 和信息娱乐,一部分用于辅助驾驶。Thor 中的多计算域隔离允许并发、对时间敏感的多进程无中断运行。你可以在一台计算机上同时运行 Linux、QNX 和 Android。
此外,Thor 还集中了众多计算资源,降低成本与功耗的同时实现功能飞跃。目前,汽车的停车、主动安全、驾驶员监控、摄像头镜像、集群和信息娱乐均由不同的计算设备控制。而未来,这些功能将不再由单独的计算设备控制,而是由在 Thor 上运行、并随时间推移不断改进的软件统一控制。
Thor 芯片预计 2025 年上车使用。

NVIDIA Drive 是一个面向自动驾驶汽车开发与部署的端到端平台,在开发方面包含了 Replicator 合成数据生成、Drive Sim 和 Drive Map,在部署方面包含了全栈驾驶和车内 AI 应用、AI 计算机和 Hyperion 自动驾驶汽车参考架构。
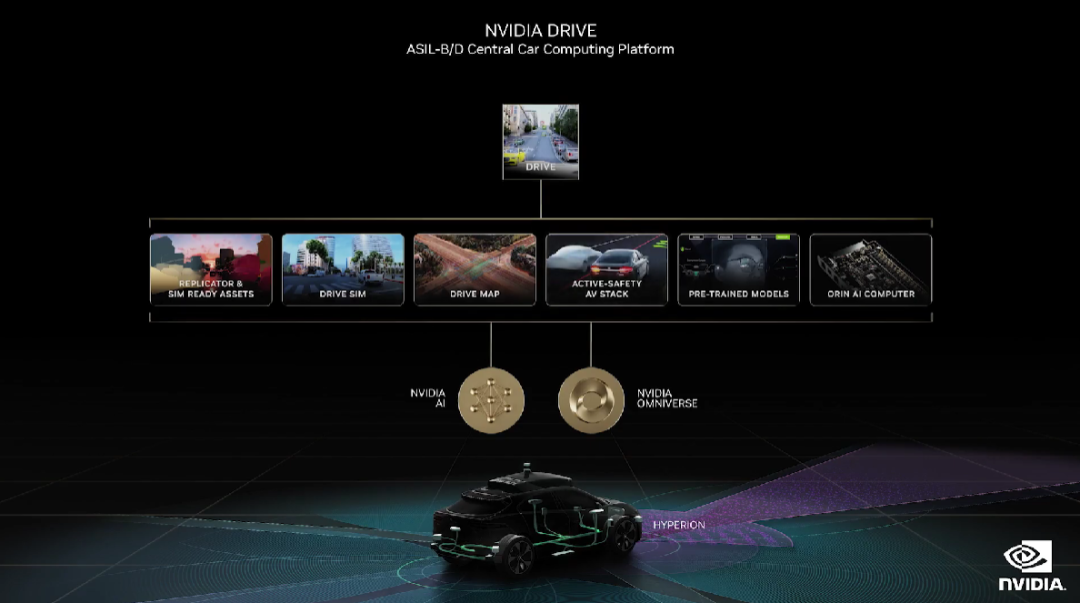
NVIDIA Drive 迎来了一系列功能更新,首先是名为 Neural Reconstruction Engine 的 AI 工作流,已成为了 Drive Sim 的一项主要功能。它可以根据记录的传感器数据构建 3D 场景,在将 3D 场景导入 Drive Sim 之后通过人工创建或 AI 生成的内容对其进行增强。另外,这个从视频到 3D 几何图形的工作流可以在 OVX 系统上运行。

从视频到 3D 工作流的动态展示。
Drive Sim 的另一项重要功能是硬件在环,意味着我们可以在 AI 工厂运行整个车载软件栈。它还可以模拟车内环境,未来的汽车不仅有简单的仪表板,还有将数字设计与物理设计相结合的环绕显示屏,这样汽车工程师、软件工程师和电子工程师可以在 Drive Sim 中展开协作,同时运行所有的实际计算机与软件栈。

Drive Sim 成为了虚拟设计工作室。
此外,英伟达还在开发 Drive 端到端自动驾驶系统的其他方面取得了出色进展,比如 Replicator 合成数据生成、AI 模型改进、Drive Map 自动驾驶车队地图构建、城市和高速公路驾驶及停车。

Drive Map 的自动驾驶车队地图构建。
全新微型机器人系统级模块
Drive Orin 是英伟达推出的第二代自动驾驶汽车计算芯片,目前看来非常成功,已经被 40 多家汽车、卡车和无人驾驶出租车使用。Jetson 是英伟达的机器人计算机,拥有 100 万开发者,使用的公司约为 6000 家。
今日的 GTC 大会上,黄仁勋宣布推出一款微型机器人系统级模块芯片 Jetson Orin Nano,它的速度较之前的 Jetson Nano 快了 80 倍。Jetson Orin Nano 可以运行 NVIDIA Isaac 机器人堆栈,并具有 ROS 2 GPU 加速框架。

黄仁勋还介绍了其边缘 AI 平台 Metropolis,它可解读摄像头、激光雷达和其他物联网传感器的数据,提高仓库、工厂、零售商店和城市的安全性与效率。
从工业到科研,自动驾驶到元宇宙,英伟达的业务早已从 GPU 拓展到了无数领域,并在很多地方都有引领地位。对于普通消费者来说,显卡也早已不是玩游戏用的了。
现在,新一代 GPU 已经推出,你会选择降价后的 RTX30,还是买新不买旧呢?





