机器之心报道
演讲:胡超
近日,在 WAIC 2022 AI 开发者论坛上,联通(上海)产业互联网有限公司 AI 技术总监胡超发表了主题演讲《从监督学习走向自我学习:无监督目标级表征学习》。
在演讲中,胡超主要介绍了他们在深度学习领域的应用和发展,以及无监督技术的应用案例。演讲分别从无监督学习、VAE & MIM(Masked Image Modeling) & GAN、图像修复与对比学习、流模型和扩散模型,以及无监督学习场景应用等五个方面展开。在介绍应用场景时,胡超主要谈到了无监督学习在智慧城市领域应用。最后,胡超认为,基于海量无标签数据,有别于强监督的数据瓶颈,无监督学习反而正在此基础上蓬勃发展,而且规模在不断的扩大,正如元宇宙的浪潮一样,无监督将成为打破数据瓶颈未来的应用技术。

联通(上海)产业互联网有限公司 AI 技术总监胡超
以下为胡超在 WAIC 2022 AI 开发者论坛上的演讲内容,机器之心进行了不改变原意的编辑、整理。
今天,我给大家带来的题目是《从强监督走向自我监督:无监督目标级表征学习》,主要介绍我们在深度学习领域的应用和发展,以及无监督技术应用案例。
首先,简单介绍一下目前深度学习领域无监督和强监督学习的例子。目前,强监督发展比较蓬勃,落地项目比较多,性能也比较好。但存在一个问题——在数据爆发的信息时代,数据累积速度远远超过数据处理速度,无监督学习(因此)应运而生,它不依赖负样本和数据标签,只依赖于正样本(正样本极易获取)。目前,无监督学习发展快速,也有一些应用和研究。
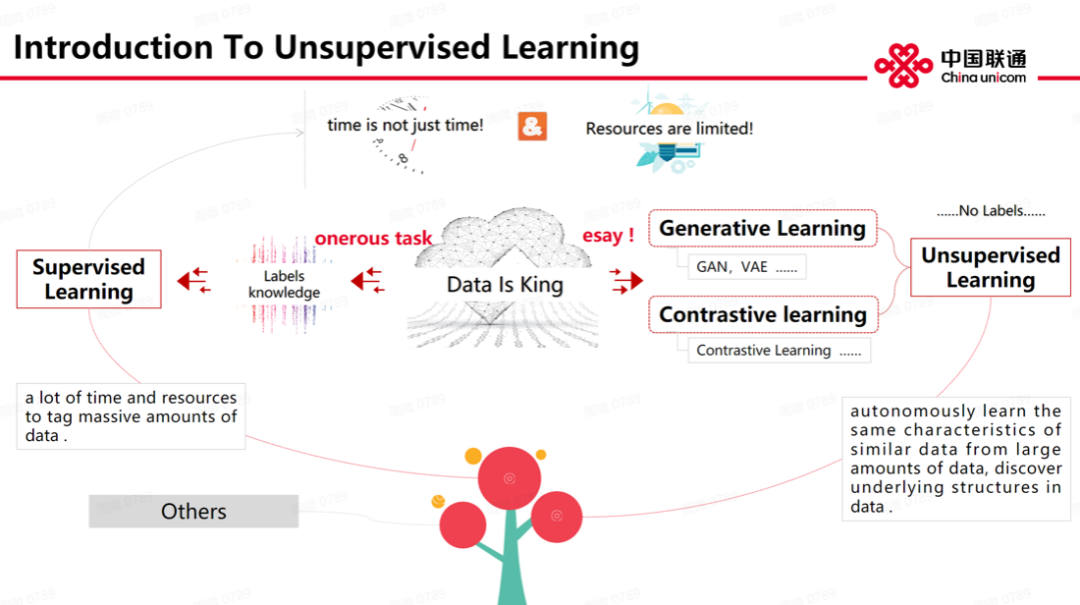
接下来,我们了解下图象生成中的传统 AE 和 VAE 路线。首先,传统 AE 重建路线主要聚焦在自动编码器 - 解码器,分别对应数据输入和数据的重建(或者说,恢复)。还有一个技术路线就是 VAE,它和 AE 的区别在于背后原理——主要依赖图形模型方法,它的输入不是映射成一个向量,而是一个独立分布,服从某一个特定分布,比如高斯分布、正态分布等等。基于 VAE 技术发展,也有很多衍生创新,比如 VQ-VAE 等。但是,它们围绕的创新主要聚焦在潜在特征向量创新,主要是为了寻找一个好的表征,或者潜在特征向量,这样的特征向量是独立、可分解的。通过训练好的模型,我们可以捕捉到人脸表情、肤色等独立因素,这样的因素是可分解的,有利于在图象生成领域获得比较好的图象生成效果。
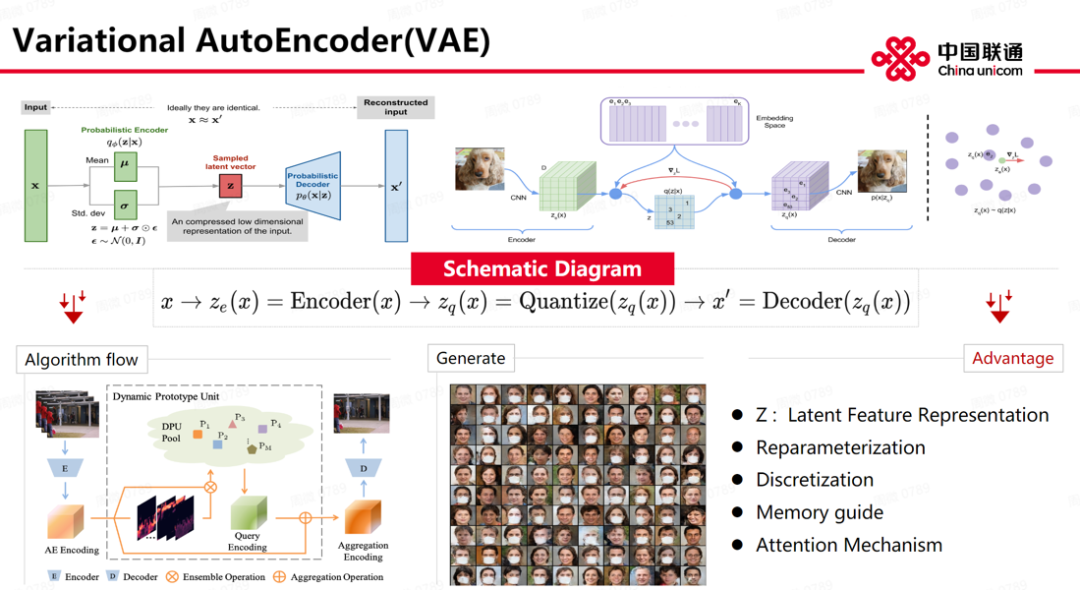
Masked lmage Modeling ( MIM )最近也比较火。这里也有 encoder- decoder 结构,但采用了非对称结构设计,好处在于大大缩短整个模型训练时间,基于 masked weights 选取,精度也有一定提升。目前学术界有 Image level 和 feat level 两种方式,当然,这里还是基于 patch based 。
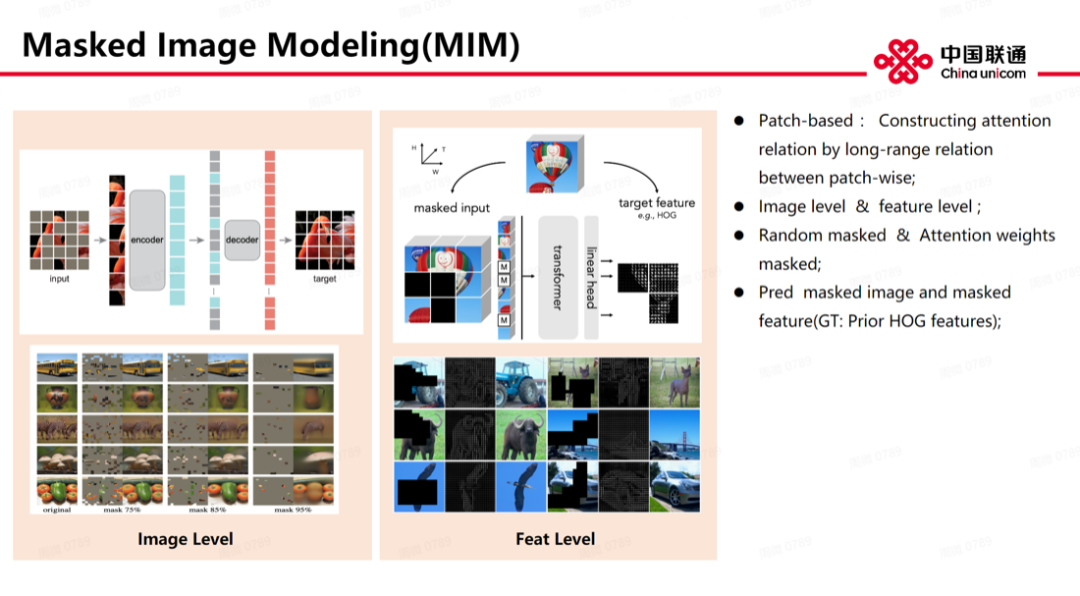
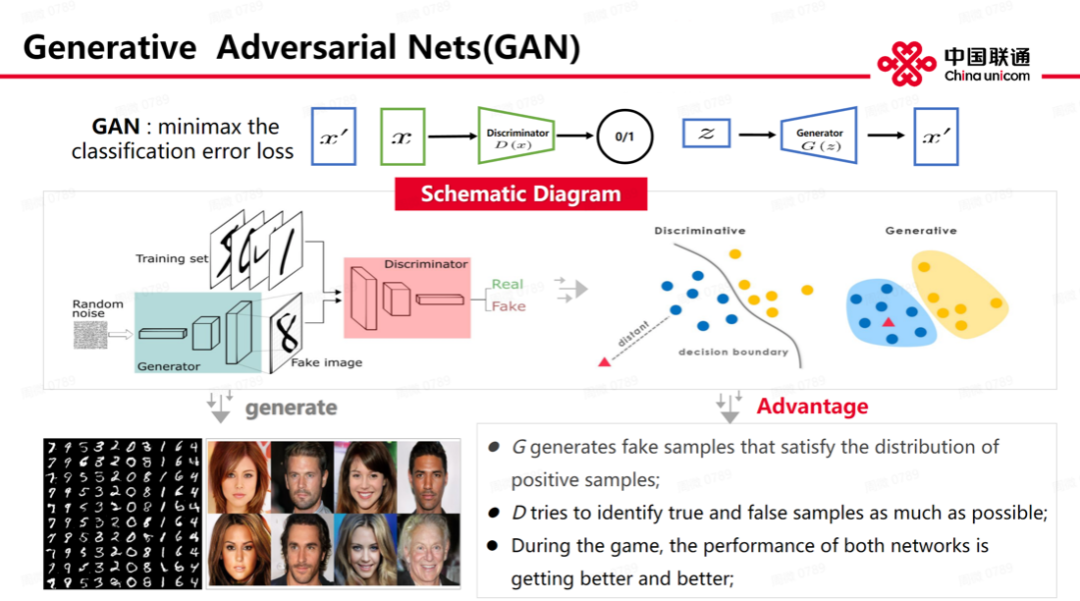
当前,生成任务有两大问题。第一个问题是真实世界中生成任务需要依赖真实世界建模,建模需要先验知识包括知识分布。第二个问题是,真实世界数据计算量往往很大,我们很难支付得起。GAN 模型可有效避免这两个问题。它也有两个模型——生成模型和判别模型。生成模型根据训练任务生成相关数据,判别模型主要是判别生成模型结果真伪,两个模型是一个博弈过程。不过,GAN 也有个缺点——难训练。训练过程中很难有效学习,生成器也很容易崩溃导致难以学习,生成器一旦崩溃,判别器也会退化。
下面我们来看看基于图象生成技术路线的无监督应用。例如图象修补领域。(从右往左)分别是原图,对图象进行破坏,以及根据无监督图象修补技术生成的结果。

借用上下文信息,填充原图缺失的像素。传统做法核心思想是复制和粘贴。通过图象中相似像素,或者基于百万级的数据库搜索相应图象,补充到相应缺失地方。这样的搜索方法不仅耗时,效率和性能也值得怀疑,有很大改善余地。
无监督技术在这个领域有很大优势。它基于无监督相应的生成网络结构,生成相应原图的各种图象,它输入的也是原图,输出(结果)也是基于原图相同分辨率。但是,这类无监督技术使得提取的特征在全局特征、局部特征、空间特征更加合理,让修补出来的细节更加细腻、逼真。目前,无监督图象生成技术在图像修补领域应用非常广。
对比学习也是比较火的方向。由于无监督学习是无标签信息,因此,学习的手段多种多样,包括聚类,降维等等,它是通过对比去学习数据有效特征,着重实现相同实例之间的共同特征,区别不同实例之间的不同之处。代理任务和目标函数是对比学习和强监督学习最主要区别。无监督学习主要是通过代理任务来解决强监督遇到损失问题,与生成式学习最大的不同点在于前几种方法更多关注实例上的烦琐细节,对比学习更关注高维特征。因此,这种模型的架构设计比较简单,优化也比较容易,泛化性也很强。
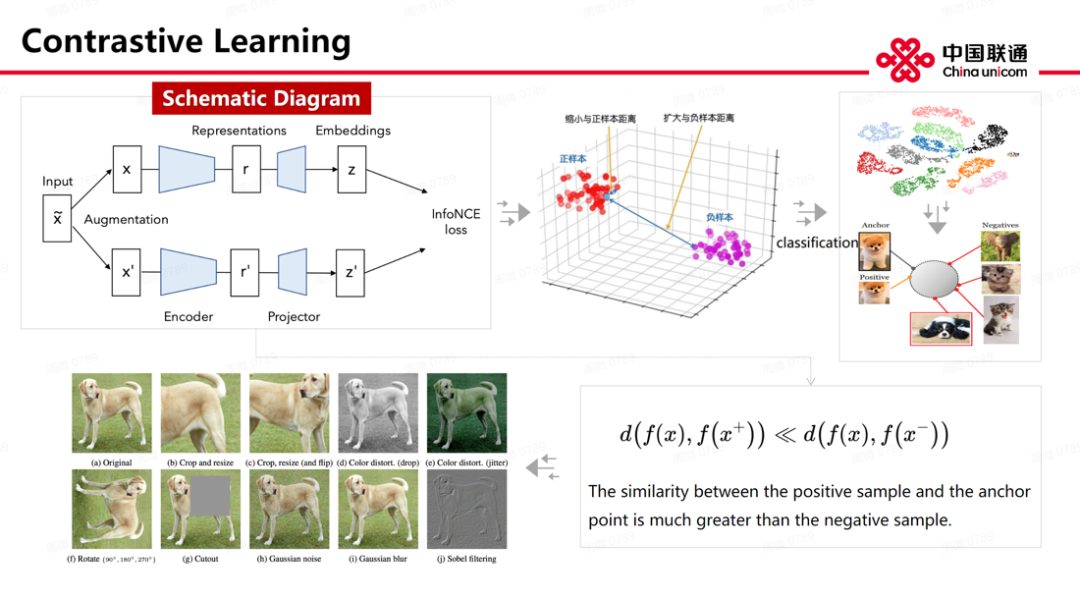
除了前面几种生成技术路线的方法,目前研究较为热门的或者有发展趋势的就是流模型和扩散模型。流模型是由一连串可逆变化模型搭建,整个网络结构可逆,这也是它与前面几个模型的本质区别。当然,这个可逆需要人工设计,设计出来的函数也是可逆的,因此,代价也是明显的——你要找一个可逆的函数,一定是可逆计算的,并且一定要灵活,有强大表示能力,这是流模型的特点。这里解释一下可逆模型与其他模型最主要区别:它要学习数据分布,相当于找到 A、B 两部之间的通道。当下,它在相应无监督图象生成领域也比存在较大潜力,能使生成出来的图象更加逼真、细腻。

扩散模型。扩散的本质就是模型迭代过程,属于图象生成领域中的技术应用。我们也可以看到,从左到右整个网络结构可逆,但是它有两个分支,一个是退化,一个是恢复,但整体流程有一个特征,就是必须以固定的方式去学习。相比 GAN、VAE 和基于流的生成模型,扩散模型在性能上有不错的权衡,最近已被证明在图像生成方面有很大的潜力,尤其是它与某些技术结合后兼得保真度和多样性。
@H_404_78@
接下来简单介绍一下无监督领域的应用和我们公司无监督学习的具体应用。首先,技术肯定要服务于实际应用,而我们聚焦的智慧城市领域积累了大量数据,这些数据都是无标签,虽然有一些数据团队在做标注,但数据采集速度远远大于数据应用速度,存在数据瓶颈。其次,当下的业务应用中主要聚焦在强监督学习的具体应用,无监督应用落地范围比较小,主要聚焦在正样本获取,而我们通过大量正样本积累,也在不断夯实无监督应用基础。
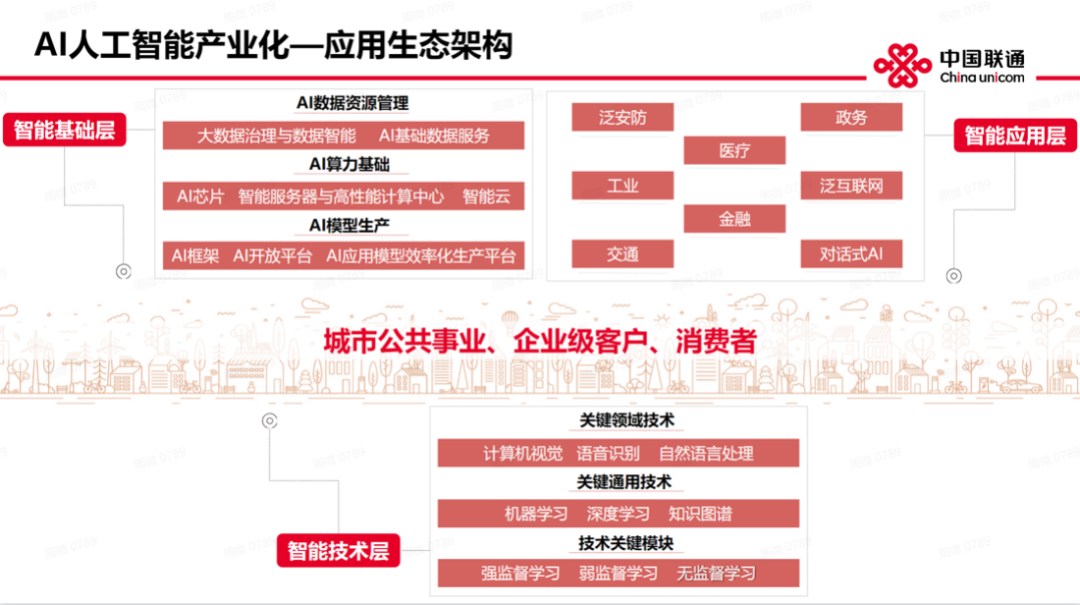
从人工智能产业化应用生态架构来看,主要包括智能应用层,里面主要包括数据的资源管理、算力基础设施、AI 模型生产,以(这些)基础层为基石,围绕相应关键技术,建成一个应用体系,最终服务于城市的公共事业,为企业级和客户提供应用层的一些服务。这是整个生态的应用架构。
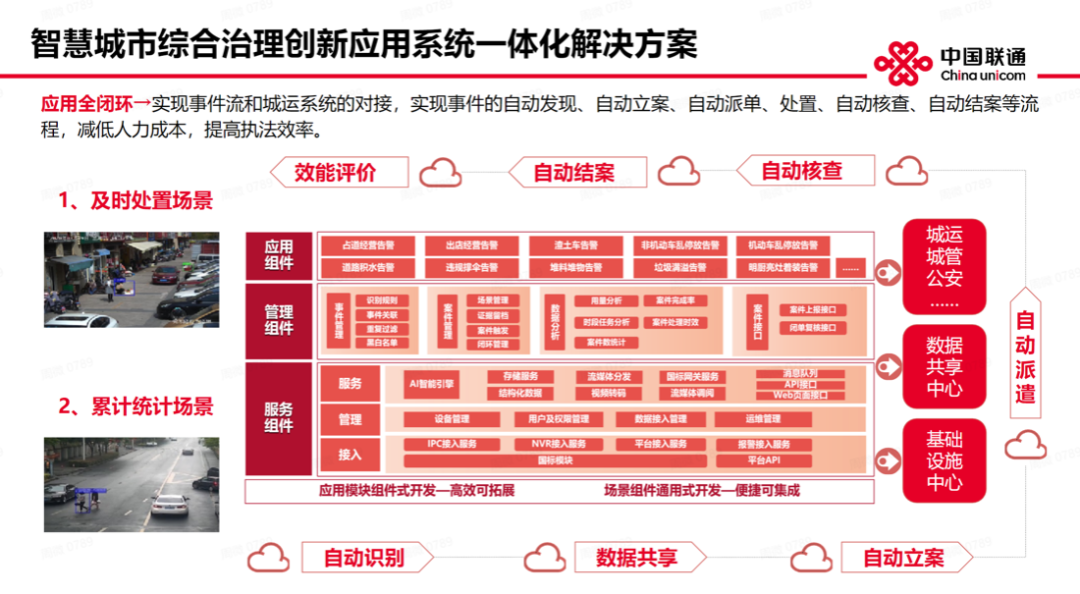
我们公司主要聚焦在智慧城市。许多客户还是希望我们能够提供一体化解决方案。但必须以基础设施为前提、数据共享为中心,以人工智能技术为支撑,搭建一套一体化的解决方案平台。这是智慧城市综合治理应用的一套全闭环应用流程,以人工智能技术框架建设围绕城运城管公安等治理需求侧,以基础设施中心为前提,基于数据共享中心,搭建从自动识别、数据共享,自动立案、自动派遣、自动核查、自动结案以及数字化效能评价的智能全闭环应用体系,打通执法端侧,从发现到执法,提升 90% 以上的执行效率,从处置到结案,减少 60% 以上的人力巡查,实现降本增效的产业化高新技术增值。
在当下,无监督学习在智慧城市领域有哪些应用呢?我们主要聚焦城市交通领域、生态环境监测、智慧校园领域的行为分析,还有医疗领域、园区企业的资产管理等。我们也积累了包括文旅、生活、交通、公共安全等在内的大量数据,此类数据都是无标签的。如果花大量人力做数据标签,会造成人力、资源和时间上的浪费。无监督应运而生,它不依赖于负样本,同时(我们)以数据中心为基础,不断积累数据,夯实无监督应用基础。
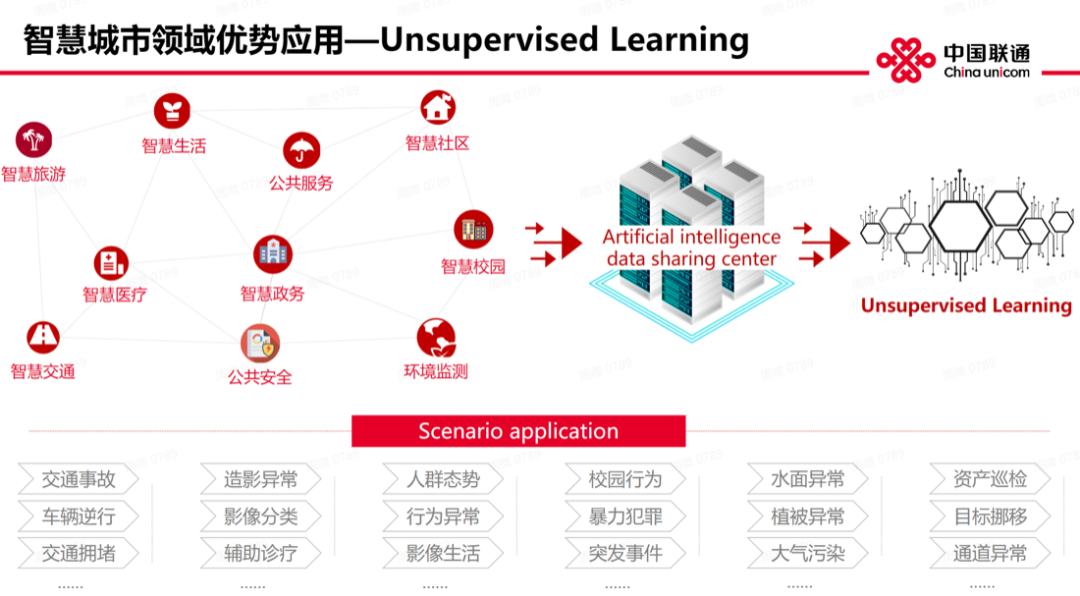
以下正是我们基于海量数据的共享,完成的部分优秀应用,包括了室内通道的异常应用,消防通道的异常检测,交通道路的异常事件甚至交通事故检测应用,以及行人轨迹的异常检测,通过此类无监督的技术应用,有效打破了海量数据造成的资源壁垒,为城市综合治理的技术应用提供了除强监督以外的无监督技术应用流,高效、有效、适用以及实用。

以点破全局,一叶而知秋,目前的无监督技术正在蓬勃发展,其应用范围正在不断扩大,正如不断加速发展的元宇宙浪潮一样,包括多元化数据应用趋势不可避免,未来,无监督也将成为打破数据瓶颈的应用技术。





