Dataframe将每一列数据绘制成折线图
解决办法
1.在jupyter notebook实现。
import pandas as pd
import os
from sklearn import datasets
from pandas import DataFrame
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
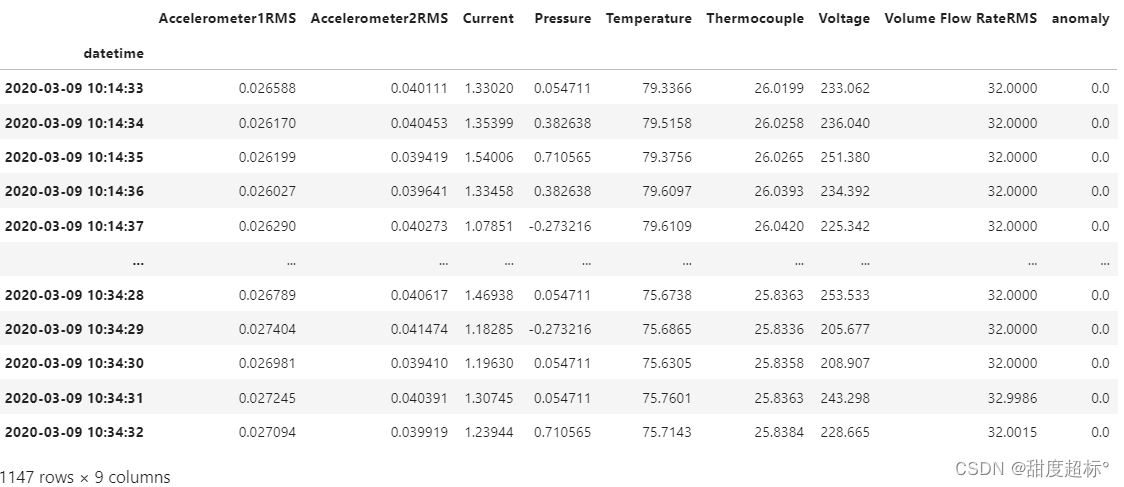
data = pd.read_csv('./0.csv', sep=';',index_col='datetime', parse_dates=True).drop(['changepoint'], axis=1)
data
###绘图###
x = np.arange(len(data))
plt.figure(figsize=(20,8))
names = locals()
for j in range(9):
names[f'y{j + 1}'] = data[data.columns[j]].values.tolist()
plt.plot(x, names[f'y{j + 1}'],label = data.columns[j])
plt.legend()
plt.grid()
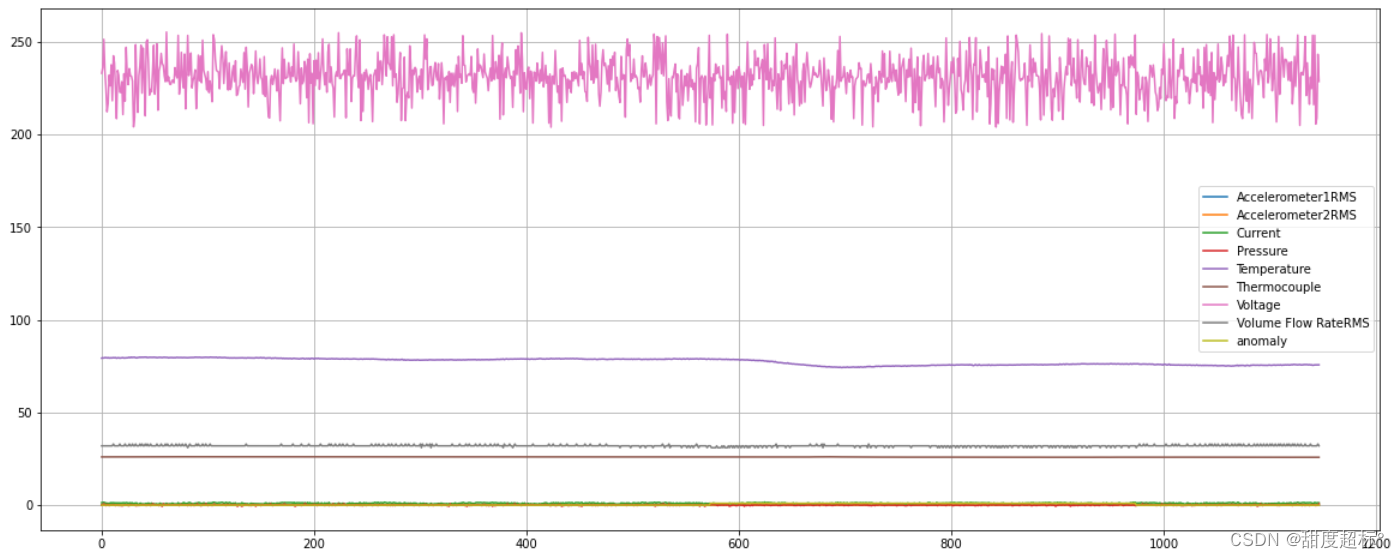
完成!
2.想要把文件夹里所有.csv文件,都绘制一个数据折线图。代码如下:
###获取csv文件的路径pathname_list和文件名字metric_list###
dir = '../value1'
metric_list =[]
pathname_list = []
for root, dirs, files in os.walk(dir, topdown = True):
for name in files:
####选择以cvs结尾的文件
if name.endswith('.csv'):
####返回文件的路径####
pathname = os.path.join(root, name).replace("\\", "/")
print(pathname)
pathname_list.append(pathname)
(_filename, suffix) = name.split('.')
# print(_filename.split('_'))
##指标名字列表##
metric_list.append(_filename)
# pathname_list

###绘图并获取表格信息###
for i in range(len(pathname_list)):
data = pd.read_csv(pathname_list[i], sep=';',index_col='datetime', parse_dates=True).drop(['changepoint'], axis=1)
x = np.arange(len(data))
plt.figure(figsize=(20,8))
names = locals()
for j in range(9):
title = metric_list[i]
plt.title("table%s"%(title))
names[f'y{j + 1}'] = data[data.columns[j]].values.tolist()
plt.plot(x, names[f'y{j + 1}'],label = data.columns[j])
plt.legend()
plt.grid()
data.info()
展示部分截图

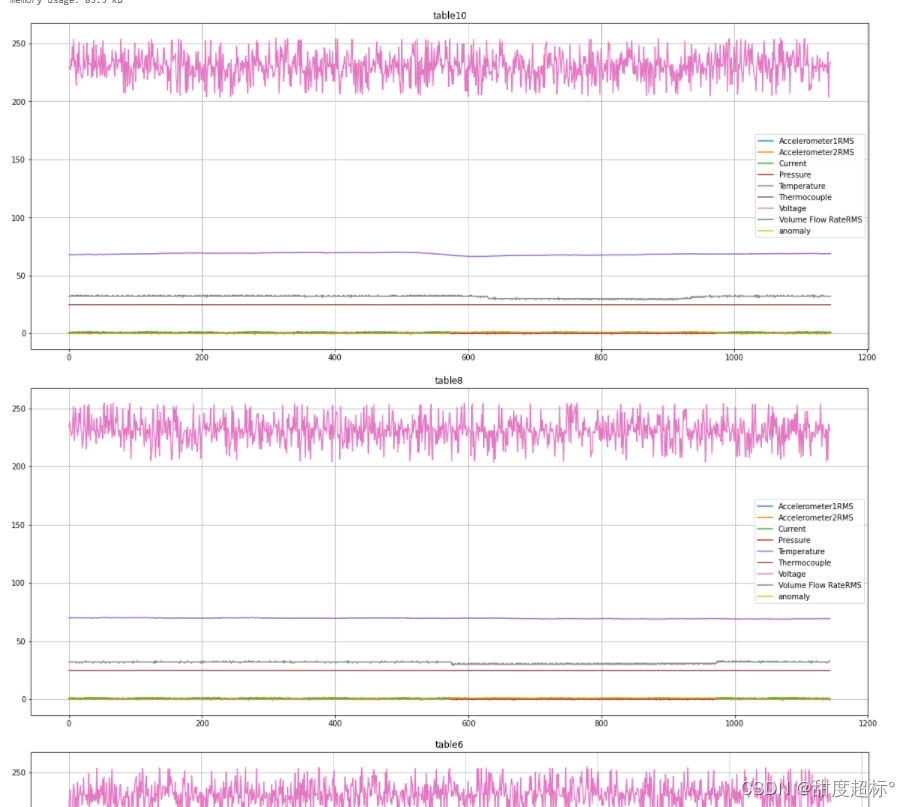
挺好,便于数据分析!
完整代码:
import pandas as pd
import os
from sklearn import datasets
from pandas import DataFrame
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
###获取csv文件的路径pathname_list和文件名字metric_list###
dir = '../value1'
metric_list =[]
pathname_list = []
for root, dirs, files in os.walk(dir, topdown = True):
for name in files:
####选择以cvs结尾的文件
if name.endswith('.csv'):
####返回文件的路径####
pathname = os.path.join(root, name).replace("\\", "/")
print(pathname)
pathname_list.append(pathname)
(_filename, suffix) = name.split('.')
# print(_filename.split('_'))
##指标名字列表##
metric_list.append(_filename)
###绘图并获取表格信息###
for i in range(len(pathname_list)):
data = pd.read_csv(pathname_list[i], sep=';',index_col='datetime', parse_dates=True).drop(['changepoint'], axis=1)
x = np.arange(len(data))
plt.figure(figsize=(20,8))
names = locals()
for j in range(9):
title = metric_list[i]
plt.title("table%s"%(title))
names[f'y{j + 1}'] = data[data.columns[j]].values.tolist()
plt.plot(x, names[f'y{j + 1}'],label = data.columns[j])
plt.legend()
plt.grid()
data.info()





