基本概念:
1)可以动态保存多个对象
一、集合框架图
1、集合主要分为单列机和和双列集合
2、Collection接口有两个重要的子接口,List和set,他们实现的子类都是单列集合
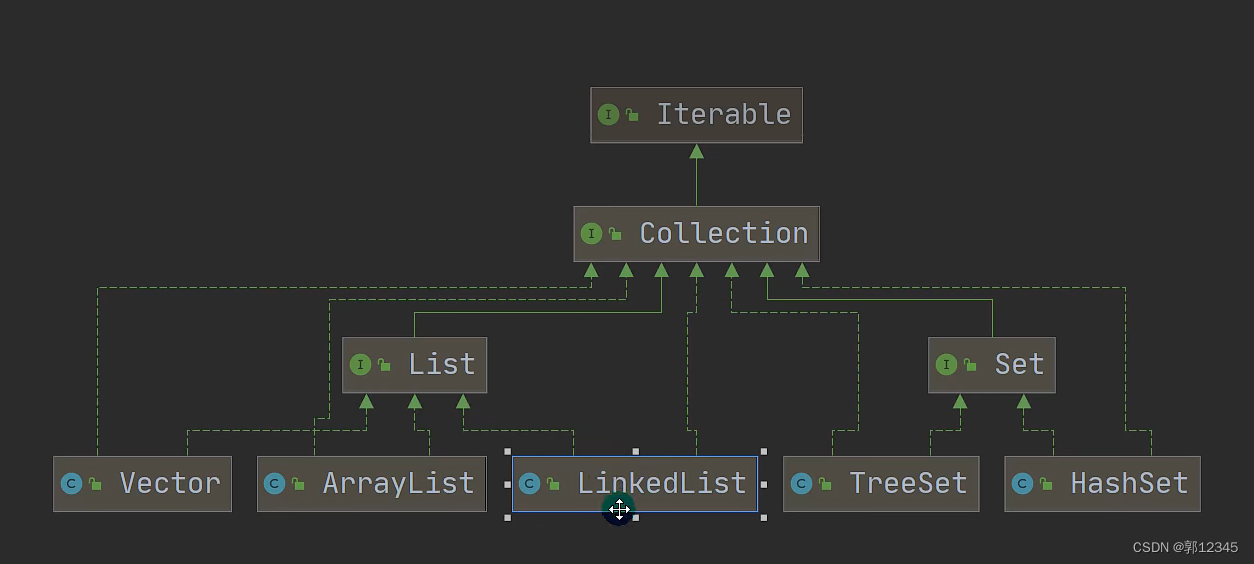
3、Map实现的子类是双列集合
二、Collection接口的常用方法
1、Collection接口常用方法:
1)add:添加元素
2)remove:删除指定元素
3)contains:查找元素是否存在
4)size:获取元素个数
5)isEmpty:判断是否为空
6)clear:清空
7)addAll:添加多个元素
8)containAll:查找多个元素是否都存在
9)removell:删除多个元素
2、Collection接口遍历元素的方式
使用Iterator迭代器
1)Iterator对象称之为迭代器,主要用于遍历Collection集合中的所有元素。
2)所有实现了Collection的接口的集合类都有一个iterator()方法,用于返回一个实现了Iterator接口的对象,即可以返回一个跌迭代器。
3)iterator的结构图
4)iterator仅用来遍历元素,本身并不是用来存储对象;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
public class Teat13{
public static void main(String[] args) {
List list=new ArrayList();
list.add(new Book("Jack",12));
list.add(new Book("Tom",22));
list.add(new Book("Lala",32));
Iterator it=list.iterator();
while(it.hasNext()) {//判断集合内还有无数据
Object tmp=it.next();//将提取出的元素赋给tmp
System.out.println(tmp);
}
}
}
class Book{
private String name;
private int price;
public Book(String name, int price) {
super();
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
@Override
public String toString() {
return "Book [name=" + name + ", price=" + price + "]";
}
}3、List接口
List接口常用方法

List接口中的sort方法
public class Test2 {
public static void main(String[] args) {
List list = new ArrayList();
list.add(new A2(99L, "zhangsan"));
list.add(new A2(77L, "lisi"));
list.add(new A2(99L, "wangwu"));
list.sort(new Comparator<A2>() {
public int compare(A2 o1, A2 o2) {
// 自定义比较规则,按照id从小到大,如果id相等则按照name从大到小
int res = o1.getId().compareto(o2.getId());
if (res == 0)
res = (o1.getName().compareto(o2.getName())) * -1;
return res;
}
});
list.forEach(System.out::println);
}
}
class A2 {
private Long id;
private String name;
public A2(Long id, String name) {
this.id = id;
this.name = name;
}
// ===================================
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "A2 [id=" + id + ", name=" + name + "]";
}
}4、ArrayList源码分析
/*
* ### ArrayList的使用和实现
* List list=new ArrayList();
*
* public class ArrayList<E>
* extends AbstractList<E> 通过继承抽象类可以共享所有公共方法
implements List<E>, 实现List接口
RandomAccess, 实现随机访问接口
Cloneable, 实现克隆接口
java.io.Serializable 实现序列化接口
* transient Object[] elementData; Arraylist真实存储数据的地方在elementData中;
*
* private int size; 当前集合中存储的元素个数
*
* 构造器
* public ArrayList() {
* //针对存储数据的数组进行初始化操作
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;先定义一个空数组
//常量定义为DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};空数组
//如果使用无参构造器,则不会直接创建数组,而是采用空数组,当第一次添加元素时才创建数组
//使用无参构造器时ArrayList会构建一个空数组用于未来存放数据,这里是一种对内存消耗的优化处理
}
带参构造器 List list=new ArrayList(18)
18就是初始化容积,这里的初始化参数值必须为[0,int的最大值)
public ArrayList(int initialCapacity) { //参数为初始化容积
if (initialCapacity > 0) { 如果初始化容积大于0,则按照指定的容积创建数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA; 空数组,长度为0的数组
} else { //初始化容积值小于0则报异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
add方法的定义[重点]
protected transient int modCount = 0;
public boolean add(E e) {
modCount++; 用于统计当前集合对象的修改次数
add(e, elementData, size); 参数1:新增元素;参数2:存储数据的数组;参数3:当前集合中存储的元素个数
return true; 返回true表示添加成功
}
private void add(E e, Object[] elementData, int s) {
//如果数组已经存满了,则首先进行扩容处理
if (s == elementData.length) 判断当前集合中存储的元素个数是否和数组长度相等
elementData = grow(); 如果相等则进行扩容处理
elementData[s] = e; 在数组的指定位置存储元素
size = s + 1; 集合中所存储的元素个数
}
private Object[] grow() { //扩容处理方法
return grow(size + 1); //继续调用其它扩容方法,参数为 当前存储个元素个数+1---最小容积
}
private Object[] grow(int minCapacity) {
//调用Arrays工具类中的方法进行数组的拷贝,同时调用newCapacity方法计算所需要的新容积值
return elementData = Arrays.copyOf(elementData,newCapacity(minCapacity));
}
private static final int DEFAULT_CAPACITY = 10;
private int newCapacity(int minCapacity) { 计算所需要的新容积值
int oldCapacity = elementData.length; 计算原来数组的长度
//计算新容积值
int newCapacity = oldCapacity + (oldCapacity >> 1); 相当于是老容积增加50%,这就是扩容比
//计算出的新容积值是否满足所需要的最小容积值
if (newCapacity - minCapacity <= 0) {
//如果存储数据的数组为初始化时的空数组,则计算默认初始化容积10和所需要最小容积值则最大值
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // OOM内存溢出
throw new OutOfMemoryError();
return minCapacity;
}
//如果计算出的新容积值大于所需要的最小容积值
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
//如果计算出的新容积值小于最大允许的容积值,则返回计算出的新容积
(minCapacity > MAX_ARRAY_SIZE)
? Integer.MAX_VALUE
: MAX_ARRAY_SIZE;
//如果计算出的新容积值大于最大允许的容积值并且minCapacity大于MAX_ARRAY_SIZE,则返回最大整数值,否则返回最大允许的容积值
}
//数组长度的上限值
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;//减8是为了不爆内存
*
*
* 数组的拷贝操纵定义在Arrays工具类中,copyof会新建一个指定长度newLength的数组,并且将原始数组中的所有元素拷贝到新数组中,同时返回新创建的数组
* 参数1是原始数组,参数2为所需要的新长度
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
结论:如果直接初始化Arraylist,则采用延迟化处理【初始化数组长度为0】的方式节约内存,当添加数据时数据的数组长度不足时候,数组会自动变长,变长的长度为原来的50%;
private void fastRemove(Object[] es, int i) {
modCount++; 修改次数+1
final int newSize;
if ((newSize = size - 1) > i) //size - 1就是可以删除元素的最大下标
System.arraycopy(es, i + 1, es, i, newSize - i); 通过数组拷贝的方式覆盖掉指定位置的元素
es[size = newSize] = null; //最后位置赋null值
{1,2,3,4,5} 执行arraycopy方法需要覆盖下标为2的元素{1,2,4,5,5}
}
结论:
- 使用数组元素移动的方式实现元素的删除。注意:这里没有变小容积
- 修改元素个数时会有modCount的修改--快速失败
get方法的实现
public E get(int index) {
Objects.checkIndex(index, size);针对索引下标进行合法性验证
return elementData(index);
}
private void checkForComodification(final int expectedModCount) {
if (modCount != expectedModCount) {//期待的修改次数和实际修改次数是否相同
throw new ConcurrentModificationException(); 并发修改异常
}
}
结论:首先要求index应该在[0,size-1]的范围内,否则异常
如果index正确则按照下标从数组中获取元素
*/5、vector底层源码分析
/*
* Vector
*
* 类定义
* @since 1.0 从JDK1.0开始提供的实现类
* public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
*
*属性:
* protected Object[] elementData; 内部的数据存储采用的是Object[],数据存储在elementData数组之中;
*
* protected int elementCount; 存储的元素个数
*
* protected int capacityIncrement;容积增长的步长值
*
*构造器
* public Vector() {
this(10);
}
public Vector(int initialCapacity) { 参数为初始化容积
this(initialCapacity, 0);
}
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0) 初始化容积不能小于0
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity]; 初始化数组,不是ArrayList中的延迟初始化
this.capacityIncrement = capacityIncrement;
}
成员方法:
public synchronized boolean add(E e) { 方法上有synchronized,基本上所有的修改方法上都有synchronized关键字,所以线程安全的
modCount++; 修改次数+1
add(e, elementData, elementCount); 参数1为需要添加的元素,参数2为具体存储数据的数组,参数3为元素个数
return true;
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length) 如果当前存储的元素个数和数据相等则先进行扩容处理
elementData = grow();
elementData[s] = e;
elementCount = s + 1;
}
private Object[] grow() {
return grow(elementCount + 1);
}
//具体的扩容处理,调用newCapacity方法获取新容积
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}
private int newCapacity(int minCapacity) {
int oldCapacity = elementData.length; 获取原始容积值,也就是存储数据的数组长度
//新容积值的算法:
* 如果设置了容积增长的步长值,则新容积为原始容积+步长值
* 如果没有设置容积增长的步长值,则扩容增长100%
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity <= 0) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
*/6、linkedList源代码分析
/*
* LinkedList:双向链表实现,增删快,查询慢 (线程不安全)
*
* 属性:
* transient int size = 0; 存储的元素个数
* transient Node<E> first; 头节点first
* transient Node<E> last; 尾节点last
*
* 节点的定义
* private static class Node<E> { 静态内部类
E item; 节点上存储的具体数据
Node<E> next; 指向下一个节点
Node<E> prev; 指向上一个节点
//创建节点对象的参数
* prev前一个节点的引用 element具体存储的数据 next下一个节点引用
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
构造器方法
public LinkedList() {
}
没有指定容积的构造器,理论上来说,链表实际上没有长度限制,但是int size属性要求元素个数必须在[0,Integer.max-value]范围内
add方法的定义:在双向链表的末尾新增元素(增)
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last; 缓存尾节点
final Node<E> newNode = new Node<>(l, e, null); 创建新的节点,新节点的下一个节点为null
last = newNode; 将尾指针执行新创建的节点
if (l == null) 如果原来的尾节点为null,则新增的节点应该是链表的第一个节点
first = newNode; 将头指针指向新创建的节点
else
l.next = newNode; 如果原来的尾节点不为null,则表示已经有元素了,将原来的尾节点指向新创建的节点,这样就将新节点加入到链表中
size++; 链表中元素个数加1
modCount++; 修改次数加1
}
--------------------------------------------------------------------------------
add(int,Object) 在指定位置新增元素,原来位置上的元素后移
public void add(int index, E element) {
checkPositionIndex(index); 检查index的合法性,要求index应该是在[0,size]的范围内
index >= 0 && index <= size;如果不合法则抛出异常indexoutofboundsexception
if (index == size) 如果索引值index等于size,则在链表默认添加元素
linkLast(element);
else 在指定下标位置之前添加元素
linkBefore(element, node(index));
}
//获取指定位置上的节点对象
Node<E> node(int index) {
if (index < (size >> 1)) { 如果序号值小于size/2则从头指针开始遍历链表,查找指定索引值的元素Node
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next; 从前向后遍历
return x;
} else { 如果序号值大于等于size/2则从尾指针开始遍历链表,查找指定索引值的元素Node
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev; 从后向前遍历
return x;
}
}
//在指定节点对象之前添加e数据
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev; 获取指定位置的前一个节点
final Node<E> newNode = new Node<>(pred, e, succ); 创建节点对象,参数1是原始节点的前一个节点,参数2是具体存储的数据,参数3是原始位置上的节点
succ.prev = newNode; 设置原始位置上的node对象的前一个节点为新创建的节点【双向链表】
if (pred == null) 如果指定位置的节点的前一个节点为null,则插入的新节点应该就是头节点
first = newNode; 使头指针指向新创建的节点
else 设置前一个节点的下一个节点指针指向新创建的节点
pred.next = newNode;
size++; 元素个数加1
modCount++; 修改次数加1
}
--------------------------------------------------------------------------------
删除和参数相等的第一个元素,删除成功返回true,否则返回false
public boolean remove(Object o) {
if (o == null) { 删除值为null的元素,使用==判断
for (Node<E> x = first; x != null; x = x.next) {从头指针开始执行遍历,查找第一个值为null的节点
if (x.item == null) { //判断当前节点的值是否为null
unlink(x); 删除指定的Node节点,并且返回Node中存储的数据
return true;
}
}
} else { 删除值非null的元素,判断使用equals方法
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) { 判断当前需要删除的数据和节点中的数据是否相等
unlink(x); 删除指定的Node节点,并且返回Node中存储的数据
return true;
}
}
}
return false;
}
删除指定的Node节点,并且返回Node中存储的数据
E unlink(Node<E> x) {
final E element = x.item; 获取节点中的数据
final Node<E> next = x.next; 获取节点的下一个节点对象的引用
final Node<E> prev = x.prev; 获取上一个节点
if (prev == null) { 如果当前节点的前一个节点为null,则表示当前节点为头节点
first = next; 使头指针指向当前节点的下一个节点
} else { 如果不是头节点
prev.next = next; 上一个节点的下一个节点为当前节点的下一个节点,将当前节点从链表中剔除出来
x.prev = null; 当前节点的上一个节点赋null值
}
if (next == null) {如果当前节点的下一个节点为null,则表示当前节点为尾节点
last = prev; 使尾指针指向当前节点的上一个节点
} else { 如果不是尾节点
next.prev = prev; 下一个节点的上一个节点引用值为当前节点的上一个节点,将当前节点从链表中剔除出来
x.next = null; 当前节点的下一个节点赋null值
}
x.item = null; 将当前节点的数据赋null值
size--; 链表中的元素个数-1
modCount++; 修改次数+1
return element; 返回当前节点原来的数据
}
--------------------------------------------------------------------------------
按照指定的索引序号删除对应的元素,同时返回删除元素的具体数据值
public E remove(int index) {
checkElementIndex(index); 检查序号值是否合法,不合法抛出异常indexoutofboundsexception index >= 0 && index < size
return unlink(node(index)); 首先查找指定索引序号对应的节点对象,然后删除对应的节点,返回原来节点上存储的具体数据
}
修改操作
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item; //获取原始节点存储的数据
x.item = element; //修改节点上的数据为新值
return oldVal; //返回原始存储的数据
}
查找操作,如果找到则返回索引序号,如果没有找到则返回-1
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
*/7、关于LinkedList、Arraylist、vector的对比
## 常见的List接口的实现类
* - ArrayList:数组实现,查询快,增删慢,轻量级;(线程不安全)
* - LinkedList:双向链表实现,增删快,查询慢 (线程不安全)
* - Vector:数组实现,重量级 (线程安全、使用少)





