直入主题,一般的Map会包含两个主要结构:
- 数组:数组里的值指向一个链表
- 链表:目的解决hash冲突的问题,并存放键值

key
|
v
+------------------------------------+
| key通过hash函数得到key的hash |
+------------------+-----------------+
|
v
+------------------------------------+
| key的hash通过取模或者位操作 |
| 得到key在数组上的索引 |
+------------------------------------+
|
v
+------------------------------------+
| 通过索引找到对应的链表 |
+------------------+-----------------+
|
v
+------------------------------------+
| 遍历链表对比key和目标key |
+------------------+-----------------+
|
v
+------------------------------------+
| 相等则返回value |
+------------------+-----------------+
|
v
value
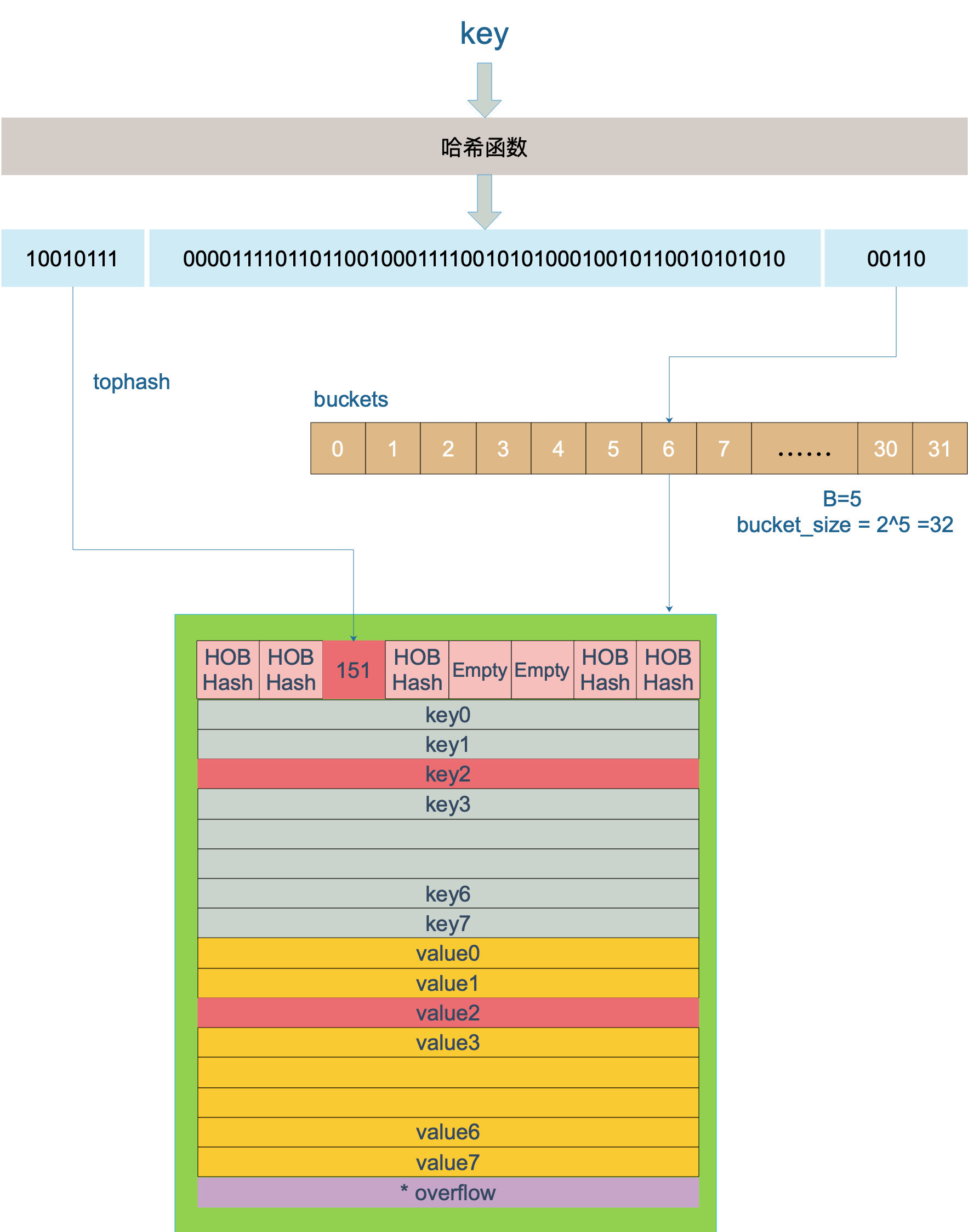
Go语言解决hash冲突不是链表,实际主要用的数组(内存上的连续空间),如下图所示:
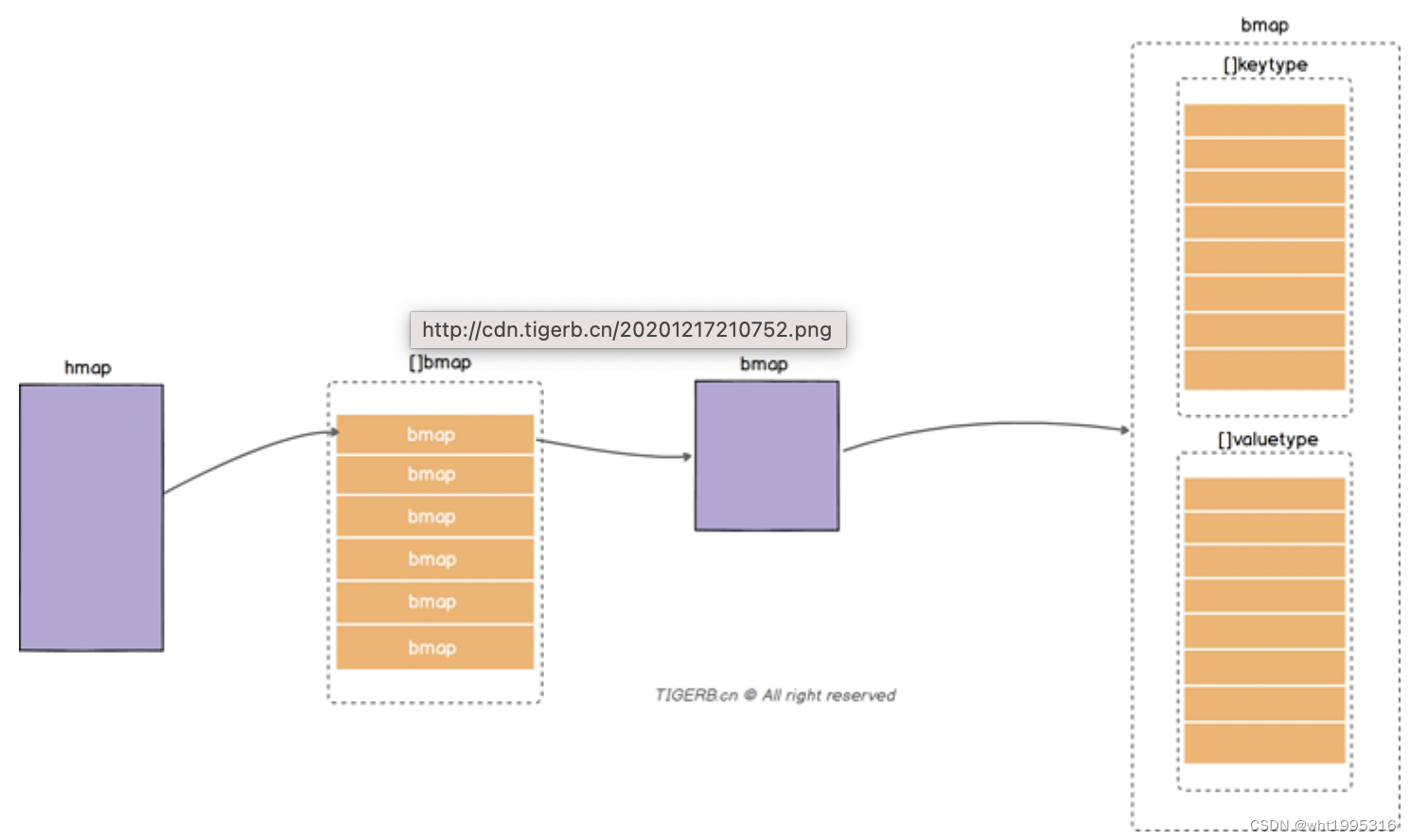
// https://github.com/golang/go/blob/go1.13.8/src/runtime/map.go
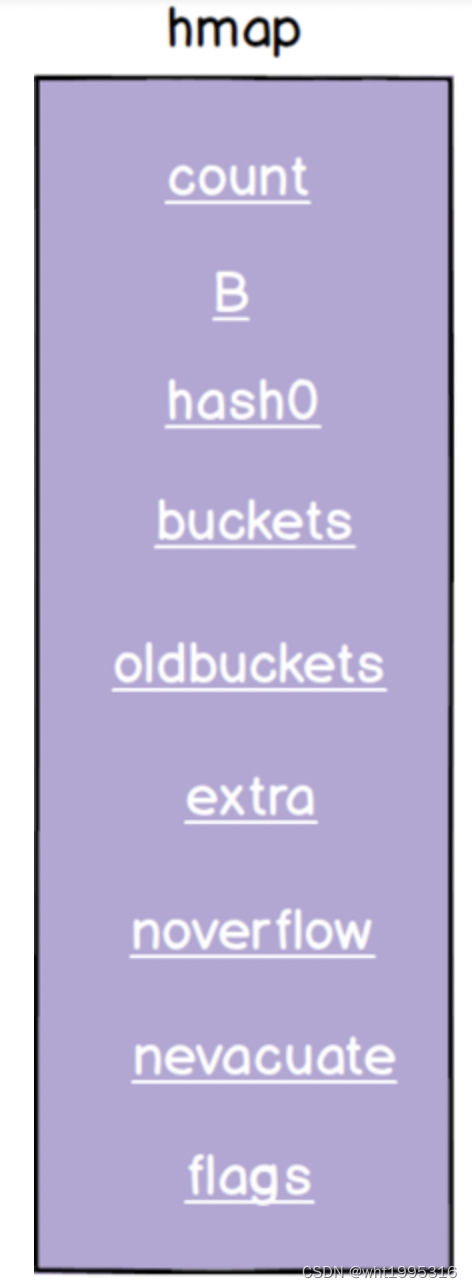
type hmap struct {
count int // 数组长度
flags uint8 // 表示是否正在写,如果是,则进行panic
B uint8 // 桶的长度 哈希过后,取哈希值的后B位,定位桶的位置
noverflow uint16 //
hash0 uint32 // 哈希因子
buckets unsafe.Pointer //桶的地址
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra // 额外桶
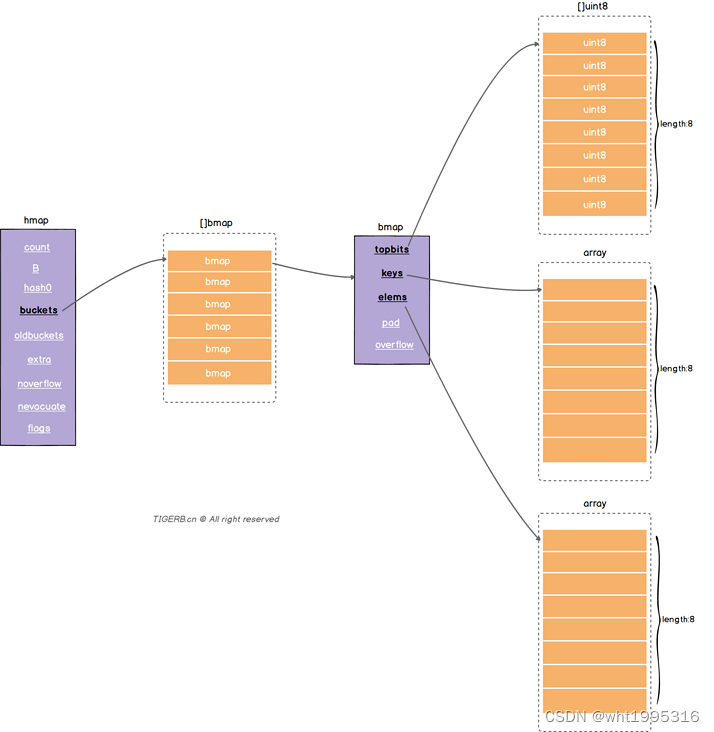
}核心结构体bmap
正常桶hmap.buckets的元素是一个bmap结构。bmap的具体字段如下图所示:
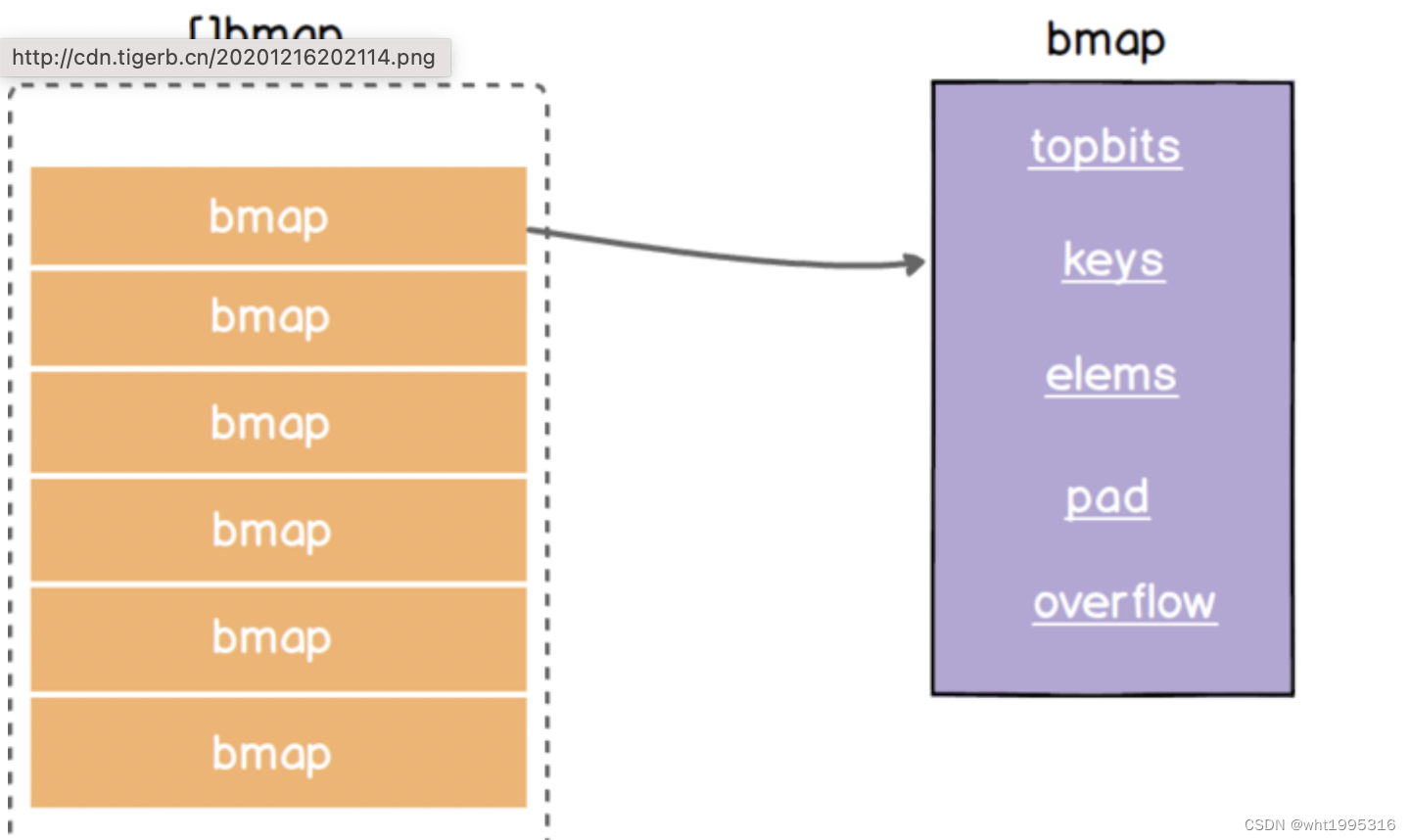
| 字段 | 解释 |
|---|---|
| topbits | 长度为8的数组,[]uint8,元素为:key获取的hash的高8位,遍历时对比使用,提高性能。如下图所示 |
| keys | 长度为8的数组,[]keytype,元素为:具体的key值。如下图所示 |
| elems | 长度为8的数组,[]elemtype,元素为:键值对的key对应的值。如下图所示 |
| overflow | 指向的hmap.extra.overflow溢出桶里的bmap,上面的字段topbits、keys、elems长度为8,最多存8组键值对,存满了就往指向的这个bmap里存 |
| pad | 对齐内存使用的,不是每个bmap都有会这个字段,需要满足一定条件 |
上面讲bmap的时候,我们不是得到了个结论么“每个bmap结构最多存放8组键值对。”,所以问题来了:
正常桶里的
bmap存满了怎么办?
解决这个问题我们就要说到hmap.extra结构了,hmap.extra是个结构体,结构图示和字段释义如下:
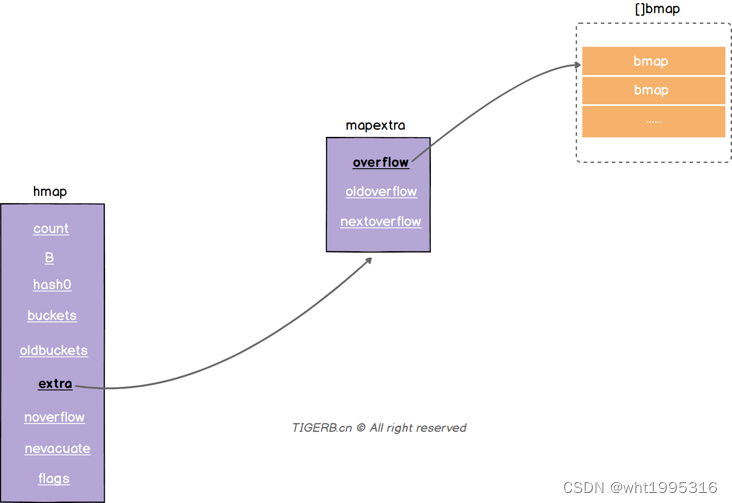
| 字段 | 解释 |
|---|---|
| overflow | 称之为溢出桶。和hmap.buckets的类型一样也是数组[]bmap,当正常桶bmap存满了的时候就使用hmap.extra.overflow的bmap。所以这里有个问题正常桶hmap.buckets里的bmap是怎么关联上溢出桶hmap.extra.overflow的bmap呢?我们下面说。 |
| oldoverflow | 扩容时存放之前的overflow(Map扩容相关字段) |
| nextoverflow | 指向溢出桶里下一个可以使用的bmap
|
// https://github.com/golang/go/blob/go1.13.8/src/runtime/map.go
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}答:就是我们介绍bmap结构时里的bmap.overflow字段(如下图所示)。bmap.overflow是个指针类型,存放了对应使用的溢出桶hmap.extra.overflow里的bmap的地址。
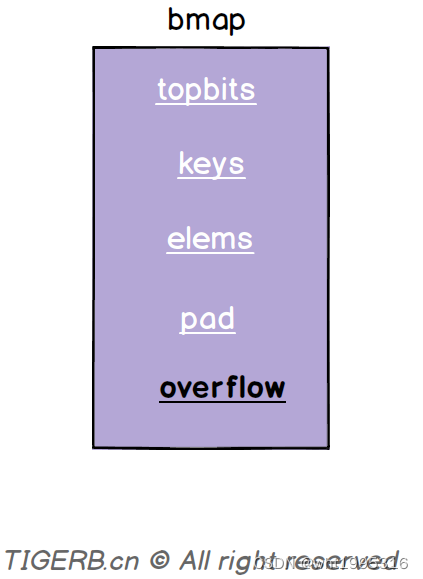
问题:正常桶hmap.buckets里的bmap是什么时候关联上溢出桶hmap.extra.overflow的bmap呢?
Map写操作的时候。这里直接看关键代码:
// https://github.com/golang/go/blob/go1.13.8/src/runtime/map.go
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// 略
again:
// 略...
var inserti *uint8
// 略...
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
// key的hash高8位不相等
if b.tophash[i] != top {
// 当前位置bmap.tophash的元素为空且还没有写入的记录(inserti已经写入的标记为)
if isEmpty(b.tophash[i]) && inserti == nil {
// inserti赋值为当前的hash高8位 标记写入成功
inserti = &b.tophash[i]
// 略...
}
// 略...
continue
}
// 略...
goto done
}
// 正常桶的bmap遍历完了 继续遍历溢出桶的bmap 如果有的话
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// 略...
// 没写入成功(包含正常桶的bmap、溢出桶的bmap(如果有的话))
if inserti == nil {
// 分配新的bmap写
newb := h.newoverflow(t, b)
// 略...
}
// 略...
}
// 继续看h.newoverflow的代码
func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap {
var ovf *bmap
// 如果hmap的存在溢出桶 且 溢出桶还没用完
if h.extra != nil && h.extra.nextOverflow != nil {
// 使用溢出桶的bmap
ovf = h.extra.nextOverflow
// 判断桶的bmap的overflow是不是空
// 这里很巧妙。为啥?
// 溢出桶初始化的时候会把最后一个bmap的overflow指向正常桶,值不为nil
// 目的判断当前这个bmap是不是溢出桶里的最后一个
if ovf.overflow(t) == nil {
// 是nil
// 说明不是最后一个
h.extra.nextOverflow = (*bmap)(add(unsafe.Pointer(ovf), uintptr(t.bucketsize)))
} else {
// 不是nil
// 则重置当前bmap的overflow为空
ovf.setoverflow(t, nil)
// 且 标记nextOverflow为nil 说明当前溢出桶用完了
h.extra.nextOverflow = nil
}
} else {
// 没有溢出桶 或者 溢出桶用完了
// 内存空间重新分配一个bmap
ovf = (*bmap)(newobject(t.bucket))
}
// 生成溢出桶bmap的计数器计数
h.incrnoverflow()
// 略...
// 这行代码就是上面问题我们要的答案:
// 正常桶`hmap.buckets`里的`bmap`在这里关联上溢出桶`hmap.extra.overflow`的`bmap`
b.setoverflow(t, ovf)
return ovf
}
// setoverflow函数的源码
func (b *bmap) setoverflow(t *maptype, ovf *bmap) {
// 这行代码的意思:通过偏移量计算找到了bmap.overflow,并把ovf这个bmap的地址赋值给了bmap.overflow
*(**bmap)(add(unsafe.Pointer(b), uintptr(t.bucketsize)-sys.PtrSize)) = ovf
}下面代码这段代码解释了,上面的源码中为何如此判断预分配溢出桶的bmap是最后一个的原因。
// https://github.com/golang/go/blob/go1.13.8/src/runtime/map.go
// 创建hmap的正常桶
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
// 略...
if base != nbuckets {
// 略...
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
// 把溢出桶里 最后一个 `bmap`的`overflow`指先正常桶的第一个`bmap`
// 获取预分配的溢出桶里`bmap`时,可以通过判断overflow是不是为nil判断是不是最后一个
last.setoverflow(t, (*bmap)(buckets))
}
// 略...
}