文章目录
前言
今天这篇文章来聊一聊数据库扩容相关的话题,这不仅是实际项目中可能会面临的问题,也是面试时常问的话题,希望看完能对彼此有所启发,能提供一些思路。
1. 初版
一般来说,如果我们的线上服务体量还没有那么大,通常单体的数据库DB来存储数据即可。

- 优点:简单,省事,方便。
- 缺点:数据并发性,稳定性都有问题。
2. 进阶
随着数据量的不断增大,一般我们要对数据进行水平切分,水平切分的规则你可以简单根据用户id 或者 用户IP 对数据进行取模,实现路由功能。当然也可以增加Slave跟KeepAlived来实现高可用。
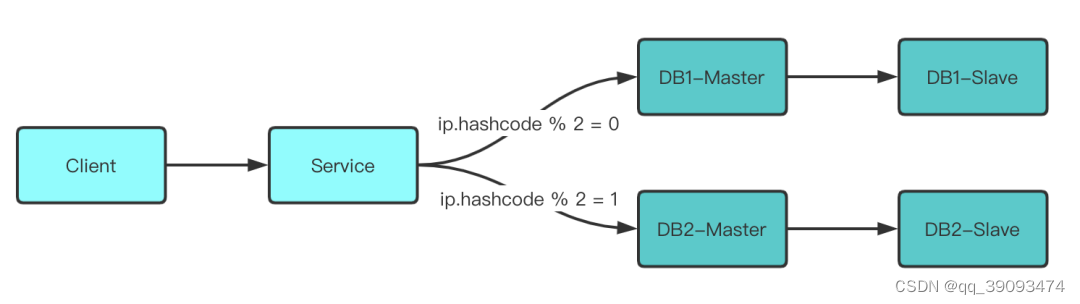
但问题是,如果随着业务发展,目前我们2个库的性能扛不住了,还要继续水平拆分,造出更多库咋办?你一般是如何实现丝滑扩容的呢?
3. 扩容
3.1 第一版:停机扩容
简单直接暴力的方法。
- 优点:简单
- 缺点:中间停服务了,无法保证高可用。数据切换前跟切换过程中需确保无任何出错。
3.2 第二版:在线双写
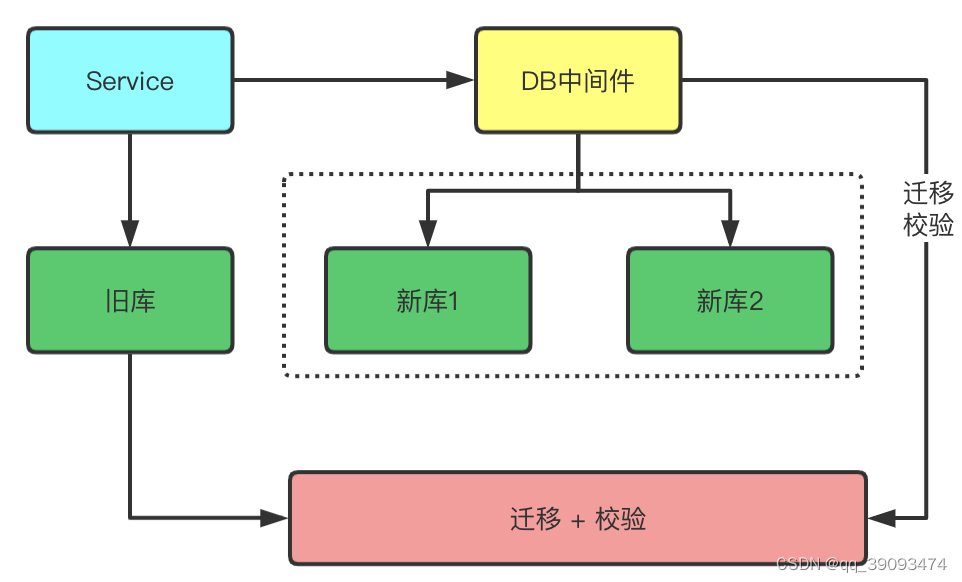
- 建立好新的数据库,然后接下来用户在写原有数据库的同时也写一份数据到我们的新库中。
- 写个数据迁移程序,实现旧库中的历史数据迁移到新库中。
- 迁移过程中,每次插入数据时,需检测数据的更新情况,比如,如果新的表中没有当前的数据,则直接新增,如果新表有数据并且没有我们要迁移的数据新的话,我们就更新为当前数据,只能允许新的数据覆盖旧的数据,推荐使用
Canal这样到中间件。 - 经过一段时间后需要校验新库跟旧库两边数据是否一样。如果检查到一样了,则直接切换即可。
- 优点:高可用了。
- 缺点:不够丝滑,来回挪动数据较大。
3.3 丝滑般扩容
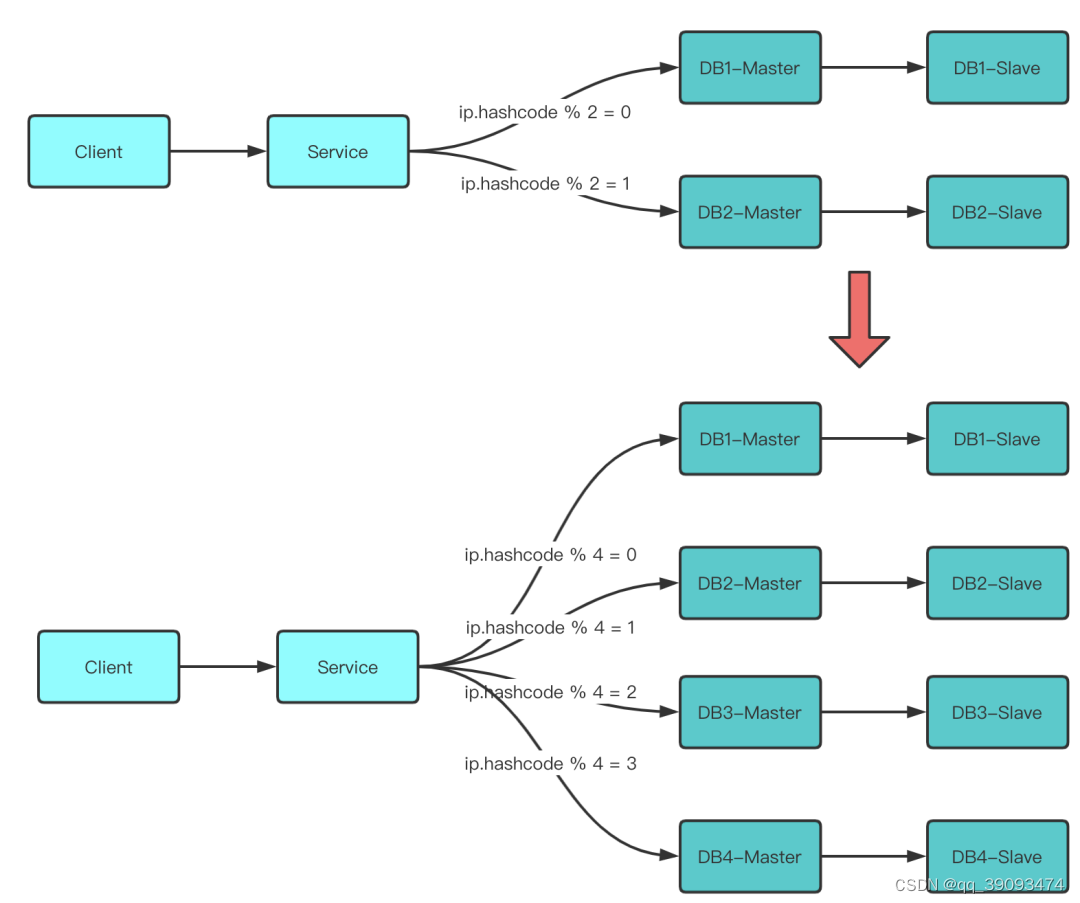
目标:打算将原来到两个数据库扩容到4个。
3.3.1 第一步:修改配置
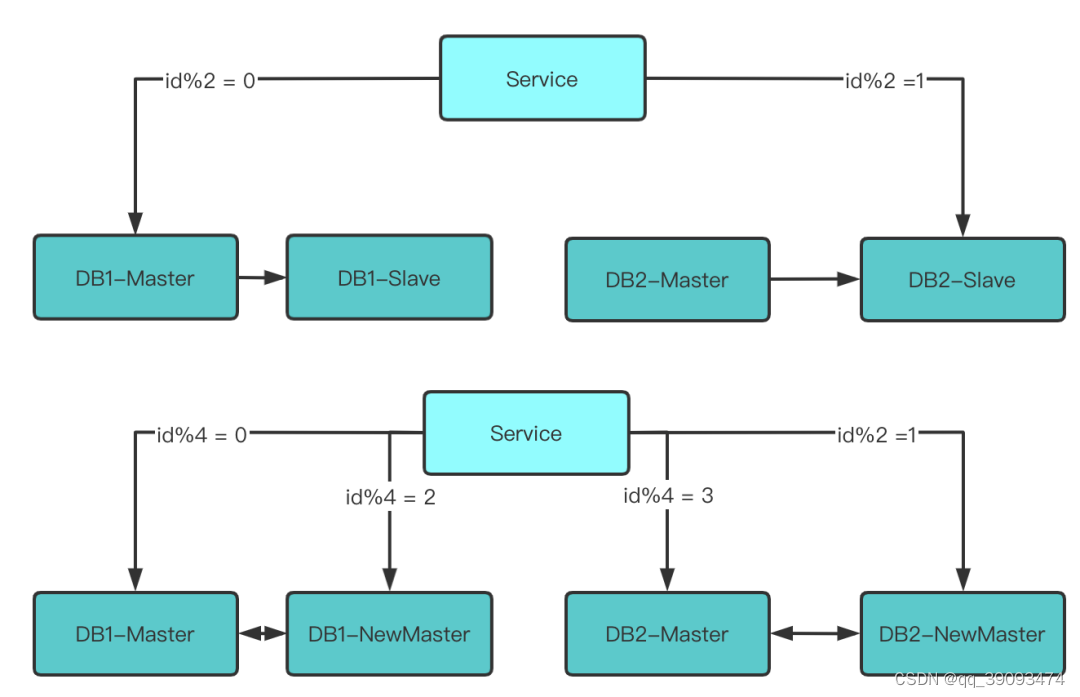
- 修改配置信息,注意旧库跟新库之间的映射关系,确保扩容后数据可以正确路由到服务器。
-
Id % 2 = 0的库变为了id % 4 = 0或id % 4 = 2 -
Id % 2 = 1的库变为了id % 4 = 1或id % 4 = 3
-
3.3.2 reload配置
服务层reload配置,可以重启服务,也可以CLoud那样配置中心发送信号来实现重读配置文件。
至此,数据库的2 --> 4 扩容完成,原来是2个数据库实例提供服务,现在变为4个数据库实例提供服务。
3.3.3 第三步:收缩数据
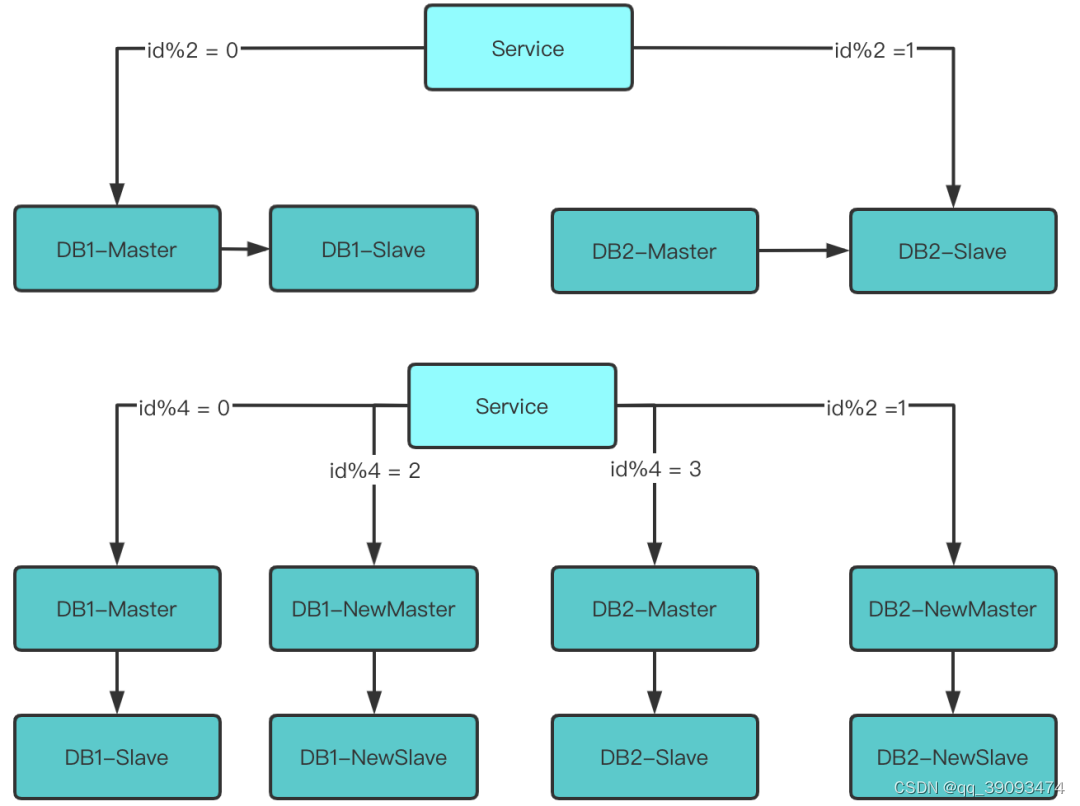
此时 id % 4 = 0 跟 id % 4 = 2 的两个DB 还在同步数据。id % 4 = 1 跟 id % 4= 3 的两个DB还在同步数据。需做一些收尾操作。





