概览
filter:筛选数据
summarize():描述性数据计算
group_by:分组
mutate:计算
arrange():数据框排序
join:数据框关系
本文需要加载的包:
library(dplyr) # 整理工具使用:dplyr
library(ggplot2) # 数据可视化工具
library(nycflights13) # 航班数据集
筛选数据filter
filter相当于excel 中的筛选器。
筛选数据包括:
-
>“大于” -
<“小于” -
>=“大于或等于” -
<=“小于或等于” -
!=“不等于”
在逻辑结构上包括:
-
|“或” -
&“且” -
!"非“
看下面一个例子:
btv_sea_flights_fall <- flights %>%
filter(origin == "JFK", (dest == "BTV" | dest == "SEA"), month >= 10)
View(btv_sea_flights_fall)
描述性数据计算summarize()
summarize()用于各种计算,常见的计算包括:
-
mean(): 平均值 -
sd(): 标准差 -
min()和max():最小值、最大值 -
iqr(): 四分位数 -
sum(): 数字求和 -
n(): 每组中的行数
看下面一个例子:
summary_temp <- weather %>%
summarize(mean = mean(temp, na.rm = TRUE),
std_dev = sd(temp, na.rm = TRUE)) # 使用na.rm 去除空值
summary_temp
输出结果为:
A tibble: 1 × 2
mean std_dev
<dbl> <dbl>
1 55.3 17.8
分组 group_by
分组即把相同的元素归为一组,进行计算。
比如下面的代码表示把月份相同的数据放在一组,然后计算中位数和方差。
summary_monthly_temp <- weather %>%
group_by(month) %>%
summarize(mean = mean(temp, na.rm = TRUE),
std_dev = sd(temp, na.rm = TRUE))
summary_monthly_temp
输出结果为:
# A tibble: 12 × 3
month mean std_dev
<int> <dbl> <dbl>
1 1 35.6 10.2
2 2 34.3 6.98
3 3 39.9 6.25
4 4 51.7 8.79
5 5 61.8 9.68
6 6 72.2 7.55
7 7 80.1 7.12
8 8 74.5 5.19
9 9 67.4 8.47
10 10 60.1 8.85
11 11 45.0 10.4
12 12 38.4 9.98
by_origin <- flights %>%
group_by(origin) %>% # 多个变量分组使用group_by(origin, month)
summarize(count = n())
by_origin
# A tibble: 3 × 2
origin count
<chr> <int>
1 EWR 120835
2 JFK 111279
3 LGA 104662
计算 mutate
用于计算变量之间的加减或者数值转换。
用法如下:
flights <- flights %>%
mutate(gain = dep_delay - arr_delay)
weather <- weather %>%
mutate(temp_in_C = (temp - 32) / 1.8)
数据框排序arrange()
在R中和排序相关的函数包括order()、sort()、rank(),可对向量进行排序。
如下:
> x <- c(10, 45, 2, 8, 12)
> sort(x) # 从小到大排序
[1] 2 8 10 12 45
> x[order(x)] # 从小到大排序
[1] 2 8 10 12 45
> order(x) # 返回每个元素从小到大对应的排序,如10是第三小的元素,返回值为3
[1] 3 4 1 5 2
> rev(sort(x)) # 从大到小排序
[1] 45 12 10 8 2
> rank(x) # 返回值为每个数值对应的排名
[1] 3 5 1 2 4
> rev(x) # 表示向量翻转
[1] 12 8 2 45 10
arrange()可以对数据框进行排序,默认为升序排列,降序使用desc。
freq_dest %>%
arrange(num_flights) # 对变量num_flights升序排列
freq_dest %>%
arrange(desc(num_flights)) # 对num_flights降序排列
也可以对多个数据排列
freq_dest %>%
arrange(变量1, 变量2) #
数据框关系join
包括inner_join、left_join、right_join、full_join。具体用法见github.com
关系如下:
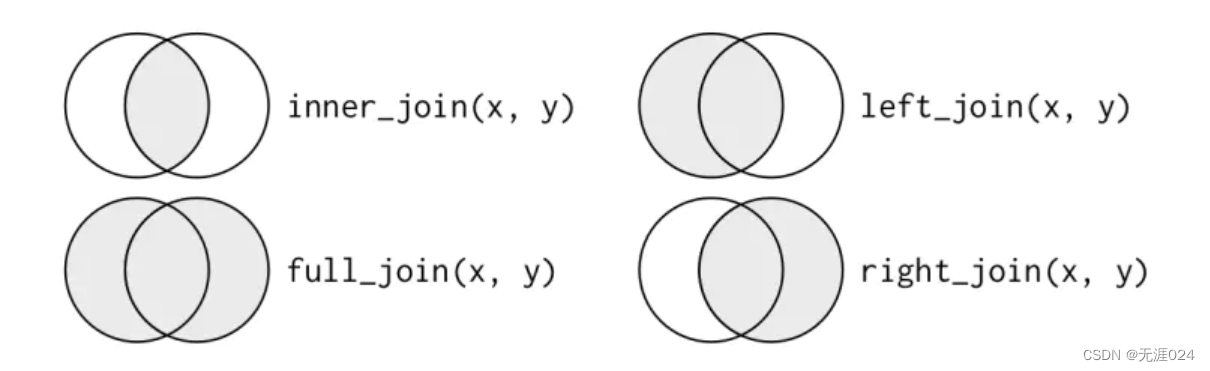
图片来源(https://www.jianshu.com/p/1f4c7bfed3d4)
参考资料
Chapter 3 Data Wrangling | Statistical Inference via Data Science
End.
20220824





