目录
1.逻辑回归
公式:
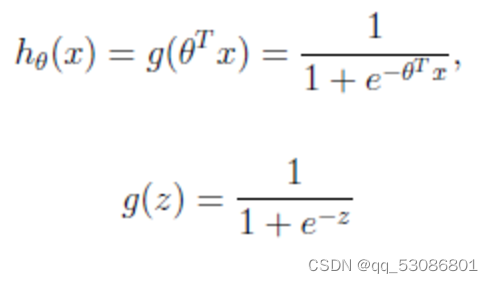
g(z)为sigmoid函数
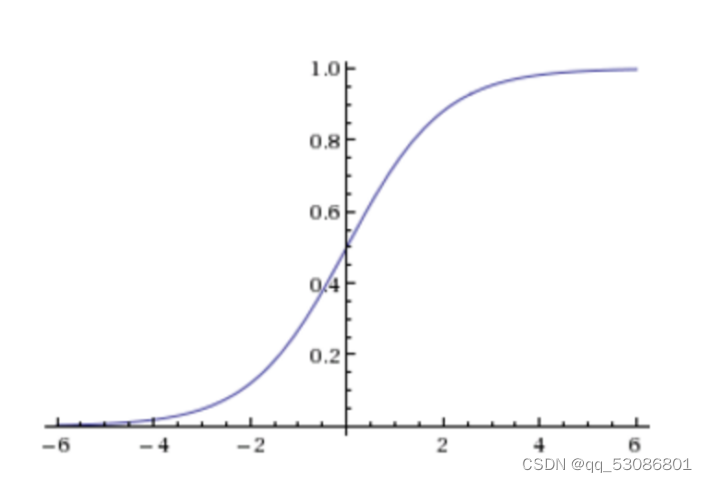
sigmoid函数
1.1逻辑回归的损失函数
与线性回归原理相同,但由于是分类问题,损失函数不一样,只能通过梯度下降求解
对数似然损失函数:
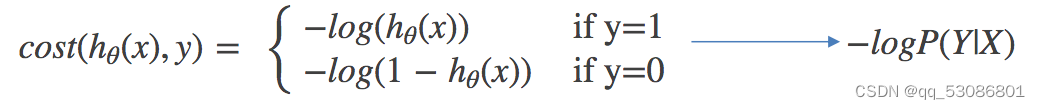
完整的损失函数:
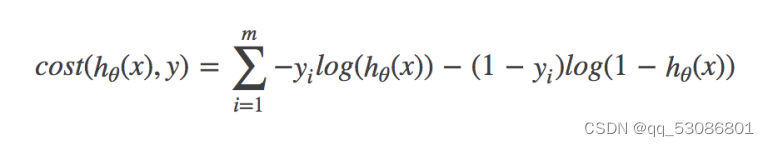
cost损失的值越小,那么预测的类别准确度更高
1.2sklearn逻辑回归API
sklearn.linear_model.LogisticRegression
sklearn.linear_model.LogisticRegression(penalty=‘l2’, C = 1.0)
Logistic回归分类器
coef_:回归系数
2.非监督学习–聚类算法(k-means)
2.1k-means步骤
1、随机设置K个特征空间内的点作为初始的聚类中心
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
2.2k-means API
sklearn.cluster.KMeans
sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
k-means聚类
n_clusters:开始的聚类中心数量
init:初始化方法,默认为’k-means ++’
labels_:默认标记的类型,可以和真实值比较(不是值比较)
2.3Kmeans性能评估指标
轮廓系数:
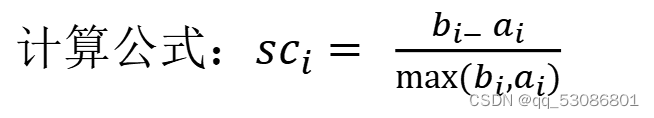
注:对于每个点i 为已聚类数据中的样本 ,bi 为i 到其它族群的所有样本的平均
距离,ai 为i 到本身簇的距离平均值
最终计算出所有的样本点的轮廓系数平均值
如果sc_i 小于0,说明a_i 的平均距离大于最近的其他簇。聚类效果不好
如果sc_i 越大,说明a_i 的平均距离小于最近的其他簇。聚类效果好
轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优
2.4Kmeans性能评估指标API
sklearn.metrics.silhouette_score
sklearn.metrics.silhouette_score(X, labels)
计算所有样本的平均轮廓系数
X:特征值
labels:被聚类标记的目标值
3.模型保存和加载
保存:
joblib.dump(模型名,‘test.pkl’)
加载:
estimator=joblib.load(‘test.pkl’)





