系列文章目录
MysqL集群及高可用-sql线程的优化-并行复制5MysqL集群及高可用
一、MysqL集群-并行复制(sql线程的优化)
半同步优化的是io线程
解决延迟问题
二、MysqL集群-并行复制的配置
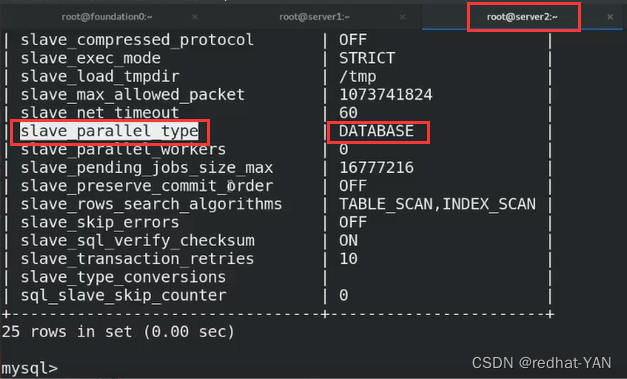
2.1 slave_parallel_type
server2:
进入数据库后
show variables like '%slave%';
DATABASE表示并行的基础是以数据库为基础,一个数据库开启一个线程
但是实际是一个数据库很多的写入,如果按照DATABASE来sql回放发挥不出并行的性能
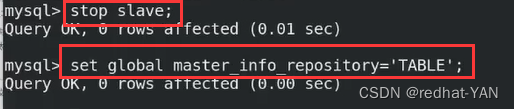
变更slave_parallel_type需要先停掉sql线程 (或者先stop slave;全局环境变量;start slave;)
也可以写到主配置文件/etc/my.cnf重启数据库就可以(生产环境是不能随意重启,测试环境可以)
所以最好是热添加(热生效)set global 临时的
热生效配置后马上写入主配置文件/etc/my.cnf,要不然数据库服务重启后,前面设置的set global就会丢失

2.2 slave_parallel_workers
slave_parallel_workers原先的sql线程会变成为协调线程,重建16个worker,不能设置1,设置1还不如原先的性能(不设置sql的并行复制)
根据实际生产调整具体的worker是多少,官方测试是16
因为一旦走了并行,机制就变化了,通过协调线程来做转发,性能一部分用在了转发上面

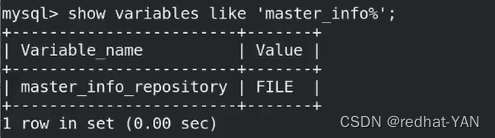
2.3 master_info_repository和relay_log_repository
启动并行复制后,每次复制的时候,主从的信息会保留在数据目录/usr/local/MysqL/data 下面的master.info和relay-log.info
master.info
server3:
读取的文件,读取的号,master主机ip

relay-log.info
server3:

激活并行复制后,文件变更速度比原先快得多,频繁的刷文件,这样的话,性能会下降,配合并行复制mts,官方建议开启两个参数选项
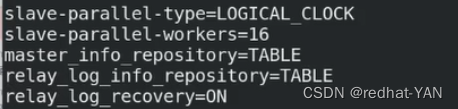
master_info_repository=TABLE
relay_log_repository=TABLE
信息保存方式2种,一种是文件,一种是表(放在数据库中),由数据库系统做刷盘动作,而不是直接写入文件保存,这样开启并行复制的时候性能能提升
server2:

slave状态没问题

master.info 和 relay-log.info 不存在了,变成数据库表了
进入数据库
use MysqL
show tables;
select * from slave_master_info;
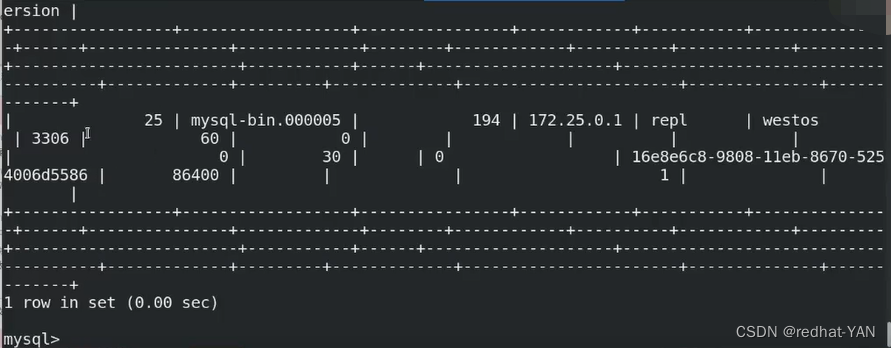
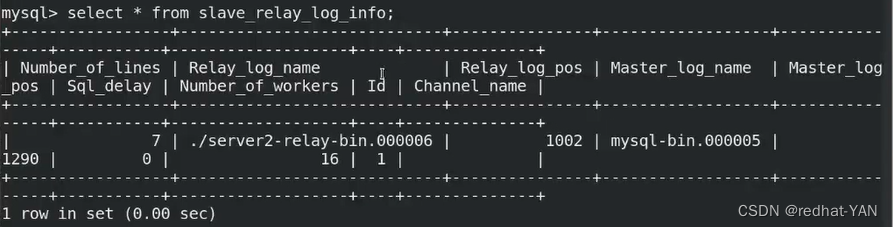
2.4 relay_log_recovery
slave 通过relay_log进行恢复
relay_log_recovery=ON
server2:
由于这个参数是只读,所以只能写到主配置文件中
有些参数不能热生效,必须写入配置文件中

server3:
由于是测试环境,所以直接在server3上的主配置文件/etc/my.cnf上面写上所有参数,重启数据库服务
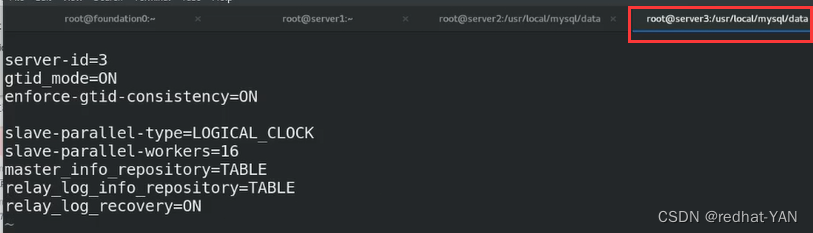
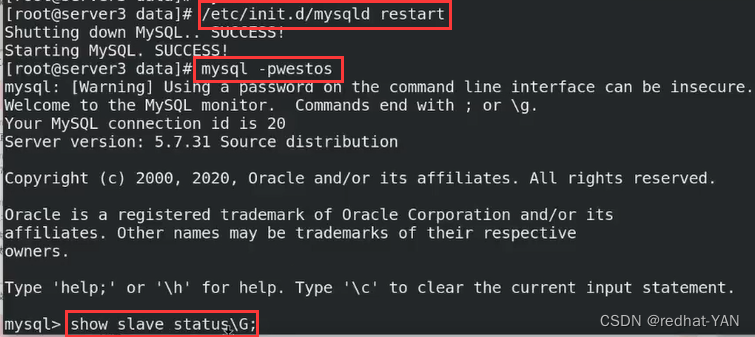


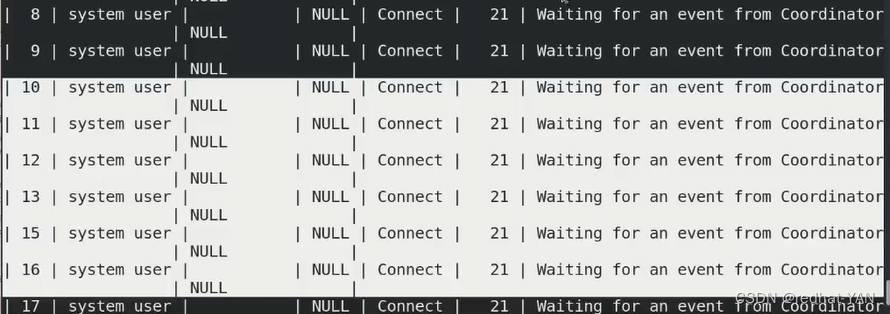
截取部分:
里面16个sql线程
END





