目录
一、为什么要使用假设性检验?
假设检验是一个工具,能够穿越复杂的现象,得到一个靠谱的结论。
比如去医院检查身体,医生会先假设这个人没有病,然后通过一系列检查,看看能不能找到患者的症状。
二、假设检验基础原理与使用条件
1、概率分布是假设检验的基础:对于很多复杂的随机事件,需要把随机事件的概率分布图拿出来,并根据在图中位置确定P值的大小。只有这样,才能和显著性水平比较,才能判断H0能不能被推翻。假设检验是基于概率的反证法,而要用概率的反证法,就要用到概率分布。
2、假设检验的原理:是如果能够证明一个结论发生的概率特别小,我们就可以推翻这个结论,接受和它相反的结论,这个推论的过程就叫“假设检验”。
3、适用条件:
1)独立性:各观察值间相互独立,不能相互影响
2)正态性:理论上要求样本取自正态总体
3)方差齐性:两样本所对应的总体方差相等
三、怎么使用?
3.1 假设检验的步骤
1、H0(零假设)和H1(备择假设)
这是一对假设,只要互相对立就行,一般情况H0是会被拒绝的假设。
2、计算P值
就是在H0这个假设下,当前现象以及更加极端现象出现的概率。如果P值特别大,我们就不能推翻H0这个假设,更不能去相信H1;而如果P值特别小,就可以认为H0几乎不可能发生,转而去相信H1。
p值得计算中,有单侧和双侧两种
双侧检验:不知道样本所在总体和假定总体的相应指标谁高谁低。得到拒绝结论更困难,因此相应的结果也更稳妥。
单侧检验:在专业上可知所在总体的相应指标不可能更高/更低于假定总体值。
3、确认显著性水平
就是是否推翻H0的边界,一般使用5%,即只要P值小于5%,就推翻H0,相信H1;如果P值大于5%,就没有办法推翻H0。
3.2 常见的统计量
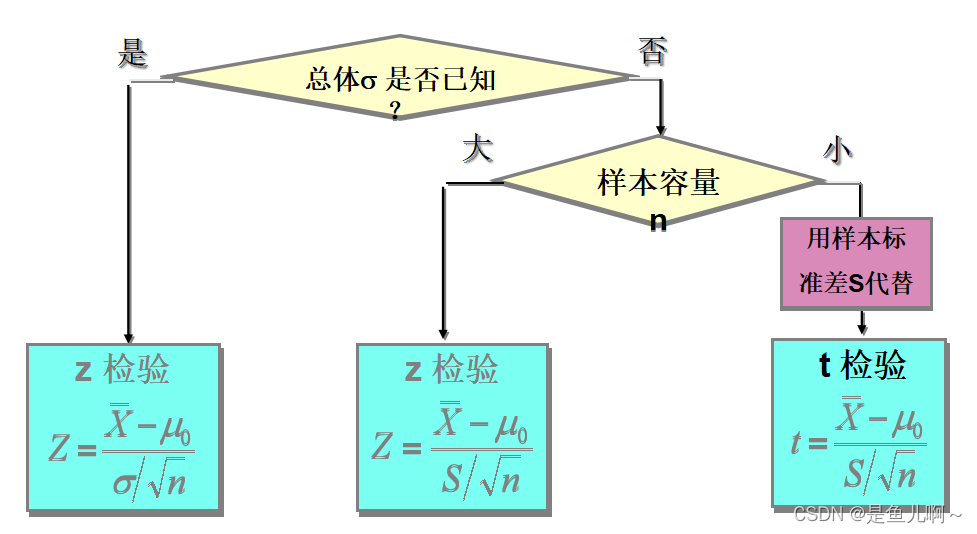
1、z统计量:

2、t 统计量

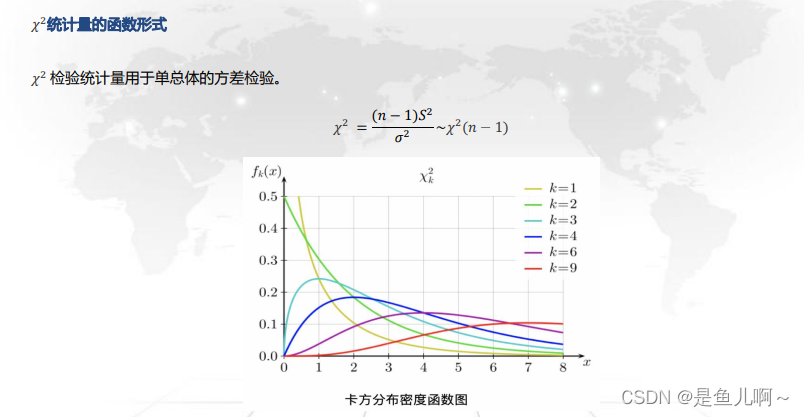
3、卡方统计量
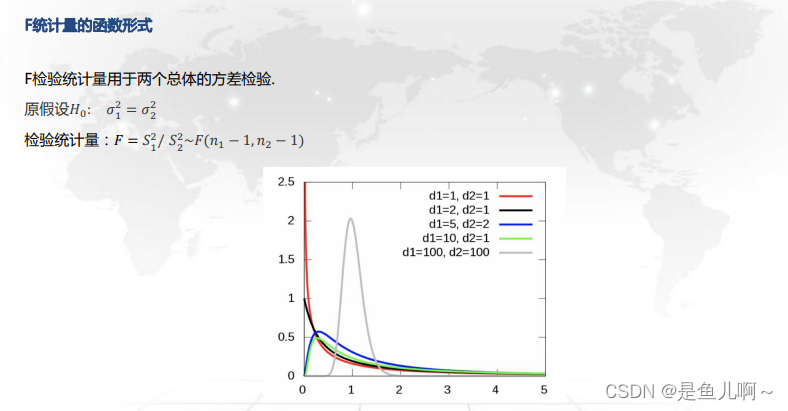
4、F统计量
四、假设检验中存在的两类错误&需要注意的问题
3.1 假设检验中的两类错误
第二类错误:和第一类错误相反,指没有成功拒绝不成立的原假设。
在假设检验中,如何平衡两类错误。在假设检验的过程中,通常会预先设定犯第一类错误的上限,也就是定义显著性水平 ,1-
被称为置信度
一般设定为5%。在显著性水平固定的情况下,认为设定,需要减少第二类错误
发生的概率,1-
对应与规避第二类错误的概率,用power表示,也称为检验效能,power 的大小可以通过增加样本量来提高,通常需要power达到80%或者更好的水平。
3.2 假设检验中需要注意的问题
1、忽略小概率事件,假设检验要用个别推导全部,就一定会忽略一些极端的小概率情况,但是小概率事件,不代表一定不会发生。
2、系统性偏差。因为P值可以影响我们最终的结论,而选择不同的样本就会得到不同的P值。只要不断改变样本,就能不断改变P值,最终总能找到一个非常小的P值,也就能推翻原假设,得到一个自己想要的结论。【例子:著名的邮件骗局】
3、显著性水平设置不好会导致错误。显著性水平是约定俗称的,不同的领域,需要选择不同的标准。
4、用错分布导致错误结论。
六、案例(t检验)
6.1 单样本t检验
实例:ccss项目基期的信心数据被设定为100,但这是全部城市的平均水平,请考察基期时广州信心指数均值是否和基准值有差异。
可以使用的方式:scipy、statsmodels 。
6.1.1 scipy 方法实现
import pandas as pd
ccss = pd.read_excel("CCSS_sample.xlsx", sheet_name = 'CCSS')数据样式:
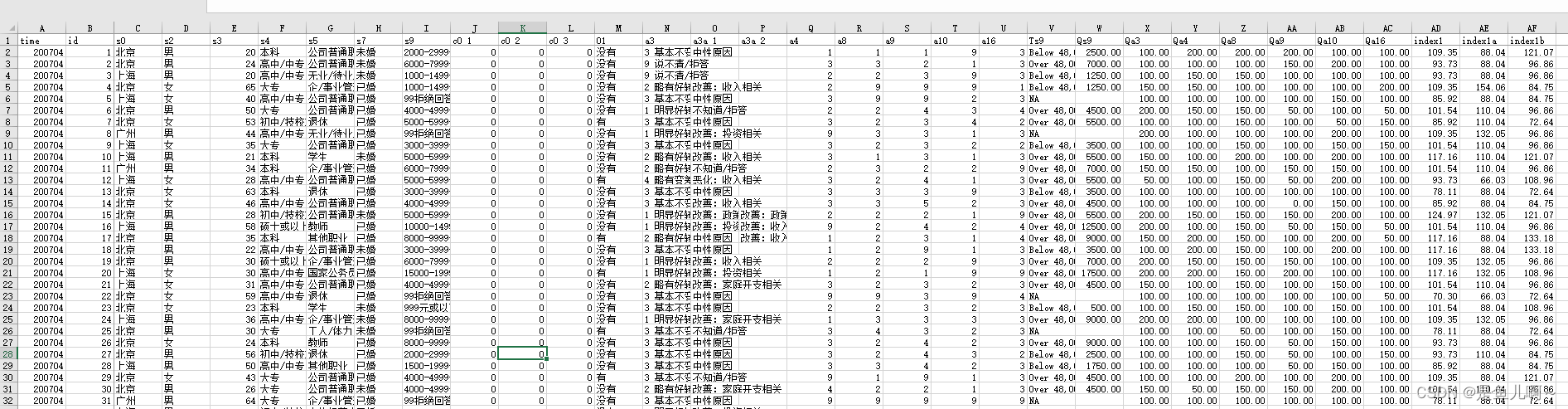
使用scipy.stat包可以实现各种常见的检验方法,但并未配备详细选项,例如不能指定检验的单双侧。
#scipy 中相关参数
scipy.stats.ttest_1samp(
a:类list格式的样本数值
popmean:H0所对应的总体均数
)ccss.query("s0 == '广州' & time == '2022704'") #数据查询
ccss.query("s0 == '广州' & time == '2022704'").index1.describe #数据描述
ccss.query("s0 == '广州' & time == '2022704'").index1.hist #数据直方图
直方图用于展示数据的形态,以上图形大致符合正态分布。
# t检验
from scipy import stats as ss #导入对应的包
ss.ttest_1samp(ccss.query("s0 == '广州' & time == '200704'").index1, 100) #t检验
#输出结果 Ttest_1sampResult(statistic=-1.3625667518512996, pvalue=0.17611075148299993)
#statistic:统计量值,pvalue:p值 6.1.2 statsmodels 方法实现
该方法中数据为DescrStatsW,DescrStatsW类中的confint_mean可以计算可信区间,ttest_mean则可直接实现单样本t检验。
# statsmodels中tconfint_mean相关参数
#计算均值的可信区间
DescrStatsW.tconfint_mean(
alpha = 0.05 #显著性水平
alternative = 'two-sided' #选择是双侧检验还是还是单侧检验
)
#进行单样本t检验
DescrStatsW.ttest_mean(
value = 0 #H0所对应的总体均数
alternative = 'two-sided' | 'larger' | 'smaller'
)# 使用得第二种方法 statsmodels 这种方法可以计算可信区间,也可以实现单样本的t检验
from statsmodels.stats import weightstats as ws
test_samp_data = ccss.query("s0 == '广州' & time == 200704").index1 #样本数据
des = ws.DescrStatsW(test_samp_data) #使用该检验数据必须是DescrStatsW类
des.tconfint_mean() #计算可信区间,默认95% 对应的参数 alpha = 0.05 alternative = 'two-sided'
#输出结果 (93.03590418536487, 101.29354984884586)
des.ttest_mean(100) #默认是双侧
#输出结果 (-1.3625667518512996, 0.17611075148299993, 99.0) 分别为t值、p值、自由度
des.ttest_mean(100,'smaller') #单侧检验
#输出结果 (-1.3625667518512996, 0.08805537574149996, 99.0) t值和双侧检验相同,p值是双侧检验的一半
6.2 两样本t检验
案例:研究不同婚姻状况的信心指数均值可能存在差异。
两样本的t检验需要检验样本的方差齐性检验。
同样可以使用scipy和statsmodels两种方式 。
6.2.1 scipy 方法实现
#进行两样本t检验
scipy.stats.ttest_ind(
a,b:类数据格式的两组数值
equal_var = true #两组方差是否齐同,方差不齐时给出welch's t检验结果
nan_policy = propagate #缺失值的处理方式
propagate #返回nan
raise #是否抛出错误
omit #忽略nan
)方差齐性检验
#常用的方差齐性检验
scipy.stats.bartlett() #bartlett 方差齐性检验
scipy.stats.levene() #levene 方差齐性检验,该结果针对非正泰总体稳健,相对更加常用
#案例中使用
ss.levene(ccss.index1[ccss.s7 == "未婚"],ccss.index1[ccss.s7 == '已婚'])
#输出结果 LeveneResult(statistic=0.6178737960192996, pvalue=0.43200314605212653)
# H0是两个样本具有一样的方差,p值大于0.05接受原假设 即两个样本方差齐
进行样本t检验
#进行样本t检验
ss.ttest_ind(ccss.index1[ccss.s7 == "未婚"],ccss.index1[ccss.s7 == "已婚"])
#输出结果 Ttest_indResult(statistic=2.405261376009453, pvalue=0.016320721789339597)
#Ho两个样本均值一致不具有差异性 p值小于0.05拒绝原假设,即两个样本均值存在差异
#如果在上面的方差检验中,方差不是齐性的,则需要在t检验中进行参数设置
ss.ttest_ind(ccss.index1[ccss.s7 == '未婚'],ccss.index1[ccss.s7 == '已婚'],equal_var= False)6.2.2 statsmodels 方法实现
statsmodels可以实现t检验的所有功能,但是无法完成方差齐性检验。
statsmodels.stats.weightstats.CompareMeans(d1, d2)
# d1, d2均为DescrStatsW对象,如果只有d1为DescrStatsW对象,也可以使用d1.get_compare(other)直接转换
CompareMeans.ttest_ind(
alternative = 'two-sided' : 'larger' | 'smaller'
usevar='pooled' : 'pooled' or 'unequal',方差是否齐同
value = 0 : H0假设所对应的均数差值
)
#两样本的statsmodels实现
d1 = ws.DescrStatsW(ccss.index1[ccss.s7 == '未婚'])
d2 = ws.DescrStatsW(ccss.index[ccss.s7 == '已婚'])
comp = ws.CompareMeans(d1,d2)
comp.ttest_ind()
#输出结果 (-26.42469575169767, 3.1575849989673495e-120, 1131.0) 统计量 p值 自由度
6.3 配对t检验
案例:为保证数据质量,接受过ccss访问的受访家庭半年内不会在进行访问,单半年后会进行抽样回访。现通过回访采集了88个有效样本,希望比较这些样本的信心值是否发生变化。
进行配对p检验时需要使用相关分析进行相关性检验。
ccss_p = pd.read_excel("CCSS_sample.xlsx", sheet_name = 'CCSS_pair') #导入数据
ccss_p.loc[:, ['index1', 'index1n']].describe()
ss.pearsonr(ccss_p.index1, ccss_p.index1n) #相关性检验
ss.ttest_1samp(ccss_p.index1 - ccss_p.index1n, 0) #检验




