1 数据库发展概述
芯片、操作系统、数据库是现代信息技术领域的三大核心基础。其中,数据库作为数据存取、管理和应用的核心工具,决定了IT运行处理数据的高效性。
自20世纪60年代至今,数据库的发展已相继经历了如下几个阶段:
层次数据库和网状数据库
世界上第一个网状数据库系统是1964年诞生于通用电气公司的IDS(Integrated Data Storage,集成数据存储)。世界上第一个层次数据库系统是1968年诞生于IBM公司的ims(information Management System,信息管理系统)。
关系型数据库
层次和网状数据库虽然解决了数据集中存储、管理和共享的问题,但在数据独立性和抽象级别上仍有较大欠缺。1970年E.F.Codd提出了关系数据模型后,很多关系型数据库应运而生。目前主流的数据库包括Oracle、MysqL、Postgresql、DB2、sql Server等均为关系型数据库。
Nosql数据库
关系型数据库可以很好的处理结构化数据,但对于数据量巨大、数据类型多样化的问题则无法处理。因此衍生出了很多非关系型Nosql数据库。Nosql数据库又包括几种不同的类别,如:
Key-Value存储:如Redis、Memcached等
列存储:如BigTable、HBase等
文档数据库存储:如MongoDB等
图数据库存储:如InfoGrid、GraphDB等
Newsql数据库
Nosql数据库虽然解决了关系型数据库无法处理的场景,但同时又丧失了关系数据库的强一致性、事务支持等特性。因此,结合关系型数据库及Nosql数据库两者优点的数据库便产生了,此类数据库称为Newsql数据库。常见的Newsql有CockroachDB、Greenplum、TiDB、EsgynDB等。
2 国产数据库发展概述
国内数据库的起步较晚,大约是20世纪90年代改革开放以后才开始进入萌芽阶段,那个阶段的数据库研究主要是源自国家的相关研究计划或大学科研需求,缺乏实际的业务场景驱动,因此数据库技术的发展相当缓慢。
自21世纪至今,随着中国经济的迅猛发展,国内数据库行业也有了巨大的改观。虽然Oracle、IBM这些数据库巨头仍然占据着国内数据库领域的绝大部分市场,但国产数据库已经逐步开始了相关的替代工作。
据统计,目前国产数据库厂家已经超过200余家。而在这200多家国产数据库厂商中,排名靠前的有PingCAP的TiDB、华为openGauss、阿里OceanBase、达梦数据库DM、南大通用GBase、人大金仓KingBase、腾讯TDsql、中兴GoldenDB、易鲸捷的EsgynDB等。具体排名情况如下图所示(摘自中国数据库排行 - 墨天轮 (modb.pro))

3 主流数据库介绍
3.1 TiDB
3.1.1 产品简介
TiDB是PingCAP公司基于Google Spanner/F1论文实现的开源分布式关系型数据库,是一款定位HTAP(即同时支持OLTP和OLAP)的数据库。TiDB具备如下核心特性:
sql支持(兼容MysqL)
水平线性扩展
分布式事务
跨数据中心数据强一致性保证
故障自恢复的高可用
3.1.2 产品架构
TiDB的架构如下图所示:

注:以上架构图摘自TiDB 整体架构 | PingCAP Docs
从上图可以发现,TiDB架构中主要包含以下几种角色:
TiDB Server
sql执行层,负责接受客户端连接,执行sql解析并生成分布式执行计划。TiDB Server是无状态的,一般启动多个实例,通过负载均衡组件(如LVS、HAProxy或F5)对外提供统一的接入地址。TiDB Server本身不作数据存储,只是将数据请求转发给TiKV或TiFlash。
PD Server
整个TiDB的元信息管理模块,存储每个TiKV节点的数据分布情况和集群整体拓扑结构。提供TiDB Dashboard管理界面。为分布式事务分配事务ID。不仅存储元信息,还根据TiKV节点实时上报的数据分布状态,下发数据调度命令给具体的TiKV节点。一般至少3个节点,保证高可用。有些类似于Zookeeper的功能。
存储节点
TiKV
TiKV是一个分布式的提供事务的Key-Value存储引擎。存储数据的基本单位是Region,每个Region存储一个Key Range的数据,每个TiKV节点负责多个Region。TiKV的API在KV层面提供分布式事务的原生支持,默认提供SI(快照隔离)隔离级别。TiDB的sql解析完sql后,会将执行计划转换为TiKV API的实际调用。
本质上,TiKV是使用RocksDB+Raft协议实现的。TiKV是把数据保存在RocksDB中,每个TiKV节点都有一个RocksDB。为了满足高可用,使用Raft协议进行数据复制功能(以Region为单位)。

TiFlash
TiFlash是TiKV的列存扩展,在提供良好的隔离性的同时也兼顾强一致性。列存副本通过Raft Learner协议异步复制,但在读取时时通过Raft校对索引配合MVCC的方式获得Snapshot Isolation一致性隔离级别。
3.1.3 产品特点
开源
分布式
HTAP
兼容MysqL
读写分离(写TiKV,读可以从TiFlash及TiKV读)
存算分离
KV存储(TiKV)、列式存储(TiFlash)
乐观锁+悲观锁(3.0.8版本及以后)+MVCC
3.2 openGauss
3.2.1 产品简介
openGauss是一款开源的关系型数据库,内核源自Postgresql。采用客户端/服务器、单进程多线程架构,支持单机和一主多备部署方式,备机只读,支持双机高可用和读扩展。openGauss采用木兰宽松许可证v2发行,提供面向多核架构的极致性能、全链路业务、数据安全、基于AI的调优和高效运维的能力。
3.2.2 产品架构
openGauss的架构如下图所示:

注:以上架构图摘自了解产品 | openGauss
从上图可以发现,openGauss架构中主要包含以下几种角色:
OM
运维管理模块(Operation Manager),提供数据库日常运维、配置管理的管理接口、工具。
客户端驱动
负责接收来自应用的访问请求,并向应用返回执行结果。
openGauss(主备)
负责存储业务数据、执行数据查询以及向客户端返回结果。支持一主多备,建议将主、备实例部署在不同的物理节点。
Storage
服务器的本地存储资源,持久化存储数据。
3.2.3 产品特点
开源
单机+主备
兼容Postgresql
行存+列存
悲观锁+MVCC
3.3 OceanBase
3.3.1 产品简介
OceanBase是阿里完全自研的原生分布式关系型数据库。产品具有云原生、强一致性、高度兼容Oracle/MysqL等特性。OceanBase首创“三地五中心”城市级故障自动无损容灾新标准,具备卓越的水平扩展能力。
3.3.2 产品架构
OceanBase的架构如下图所示:

注:以上架构图摘自OceanBase 海量记录 笔笔算数
从上图可以发现,OceanBase架构中各个节点之间完全对等,每个节点都有自己的sql引擎、事务引擎、存储引擎。OceanBase数据库采用Zone的概念,每个Zone是一个机房内的一组服务器,每个服务器为一个OBServer。每个Zone有一台OBServer会同时运行总控服务(RootService),用于负责整个集群的资源调度、资源分配、数据分布信息管理以及schema管理等操作。整个集群中只存在一个主总控服务,其他的总控服务作为备用服务运行。每一个Zone上包含一个完整的数据副本。
OceanBase基于paxos分布式选举算法来实现高可用,最小粒度可以做到分区级别。数据的一个分区会保存到所有的Zone上,整个系统中该副本的多个分区之间通过paxos协议进行日志同步。每个分区及副本构成一个paxos复制组,其中一个为主分区(leader),其它分区为备分区(Follower)。所有针对副本的写请求都会自动路由到对应的主分区上进行。
OceanBase的存储引擎采用基于LSM-Tree的架构,把基线数据和增量数据分别保存在磁盘和内存中,具备读写分离的特点。对数据的修改都是增量数据,只写内存。读的时候,数据可能在内存里面有新版本,在磁盘中有基线版本,需要把两个版本合并获取一个新的版本。

3.3.3 产品特点
开源+闭源
分布式
HTAP
兼容Oracle/MysqL
读写分离(读磁盘+内存、写内存)
pax行列混存(类似于Spanner)
悲观锁+MVCC
3.4 TDsql
3.4.1 产品简介
TDsql是部署在腾讯云上的一种支持自动水平拆分、Shared nothing架构的分布式数据库。提供两种不同的引擎,均兼容MysqL标准协议:
InnoDB作为存储引擎
采用腾讯云自研的TDstore作为存储引擎
3.4.2 产品架构
TDsql的架构如下图所示:

注:以上架构图摘自一文剖析:腾讯分布式数据库TDsql的金融级能力 - 碳链价值 (ccvalue.cn)
从上图可以发现,TDsql的整体逻辑是用户请求通过负载均衡发到sql引擎,sql引擎作为计算层,将请求发到后端取数据。Zookeeper作为一个协调者,保存元数据信息,如路由信息。因此,整体上,TDsql可以分为三部分:管理模块、计算模块和存储模块。
管理模块
管理模块包括几个关键模块:Zookeeper、Schedule Manager、OSS和监控采集程序、赤兔管理控制台。具体工作流程为:DBA在赤兔管理平台(WEB客户端)进行一个操作(如扩容),操作请求被转移到OSS模块(类似WEB服务器),OSS将请求转发到Zookeeper。Zookeeper根据请求创建一个任务节点,这个任务节点被Schedule Manager捕获到后开始处理任务。处理完成后返回ZK上。ZK上的任务被OSS捕获后去查询任务最后得到一个结果返回给前端。整个过程通过监控采集模块去采集,对整个流程的审计及状态进行获取。
计算模块
计算模块,即sql引擎层。sql引擎获取客户端请求后,首先从ZK上拉取元数据,用于权限校验、读写分离,以及统计信息、协议模拟等相关的操作。sql引擎需要处理分布式事务、维护全局自增字段等工作。
存储模块
存储模块,即数据节点。存储模块一般包括一个或多个SET,SET就是数据库实例。一个SET包含数据库的一个Master节点和N个Slave节点。数据节点上有一个Agent模块,用来完成对所有集群对MysqL的操作,并且上报MysqL状态。Agent的存在是为了无损升级的问题(只升级Agent而不需要升级MysqL)。
3.4.3 产品特点
闭源
分布式
HTAP
兼容MysqL
读写分离
存算分离
行存
悲观锁+MVCC
3.5 GoldenDB
3.5.1 产品简介
GoldenDB是中兴通讯的关系型分布式数据库,主要应用于金融、政企行业,采用无共享架构,提供高可用、高可靠、可扩展的解决方案。
3.5.2 产品架构
Golden的架构如下图所示:

下图为物理架构部署图(考虑HA故障场景下,所有的角色均采用主备部署模式)
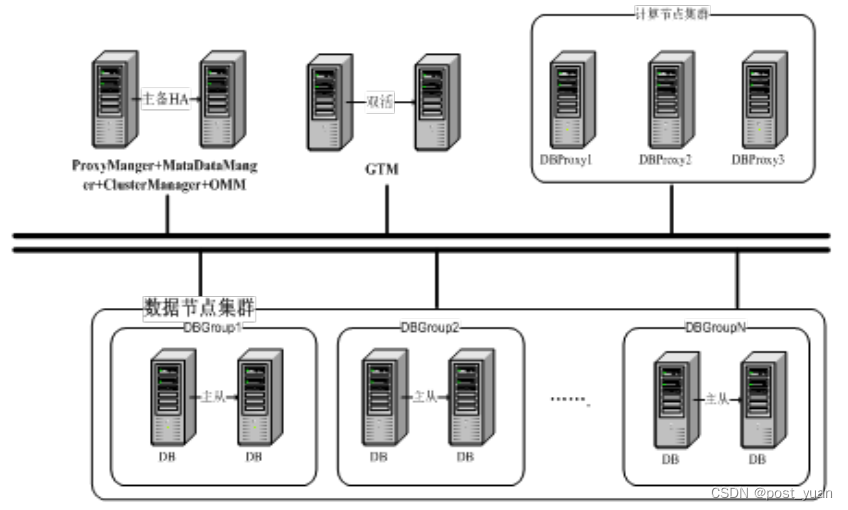
注:以上架构图摘自《GoldenDB分布式数据库技术白皮书》
从上图可以发现,GoldenDB由数据库驱动、计算节点集群、数据节点集群、管理节点和全局事务管理节点5个部分组成。
数据库驱动
GoldenDB支持通用数据库标准协议,包括JDBC、ODBC。
计算节点集群
计算节点集群是核心层,由无状态的计算节点(DBProxy)组成。主要负责接收sql请求生成分布式执行计划。
数据节点集群
数据节点集群由一个或多个安全组(DBGroup)组成,集群中每个表中的数据按照某种策略进行横向分片后存放到对应的安全组中,分片策略包括复制策略、哈希策略、范围策略、列表策略。
管理节点
管理节点负责集群管理流程,不涉及业务访问流程,一般采用两节点主备方式部署。管理节点中包括如下几个子模块:
统一运维管理OMM
GoldenDB分布式数据库产品的统一操作维护入口,可以在OMM上进行用户权限管理、元数据管理、计算节点管理、数据节点管理、DDL执行、节点扩容、备份恢复 、系统安装、统计及告警处理等。
元数据管理器MetaDataServer
存放系统的全量元数据,是整个集群的元数据中心。
计算节点管理ProxyManager
负责管理计算节点集群。
数据节点管理ClusterManager
负责管理数据节点集群。
全局事务管理节点
维护全局事务的全生命周期,提供申请、释放、查询全局事务的能力。
3.5.3 产品特点
闭源
分布式
兼容MysqL
读写分离
存算分离
行存
悲观锁+MVCC
3.6 EsgynDB
3.6.1 产品简介
EsgynDB是易鲸捷捷公司自主研发的基于Key-Value存储格式的分布式数据库,Trafodion是其对应的开源产品。EsgynDB底座是Hadoop分布式文件系统。
3.6.2 产品架构
EsgynDB的架构如下图所示:

注:以上架构图摘自《EsgynDB技术白皮书》
通过以上架构图可以发现,EsgynDB整体架构分为以下三层:
连接层
连接层也是客户端服务层。应用程序通过EsgynDB提供的标准JDBC/ODBC接口把请求发送到EsgynDB数据库计算引擎。
EsgynDB提供的OM数据库管理监控工具可以实现数据库的管理监控,如运行负载监控、用户权限管理、备份恢复、慢SQL查询、告警服务等。
计算引擎
计算引擎即sql层,该层封装了所有管理EsgynDB对象和高效执行sql数据库请求的服务。包括连接管理、sql语句编译和生成执行计划、sql执行、事务管理和工作负载管理等。
数据存储
数据存储即存储层。EsgynDB当前主要使用HBase作为存储引擎。HBase是一款Key-Value的存储引擎。同时,EsgynDB也支持Hive作为存储引擎,包括ORC或Parquet列存储格式。使用HDFS分布式文件系统作为实际的文件存储。
3.6.3 产品特点
开源+闭源
分布式
HTAP
兼容Oracle
KV存储、行式存储、列式存储
HDFS分布式文件系统
乐观锁+悲观锁(QianBase版本)
3.7 PolarDB
3.7.1 产品简介
PolarDB是阿里自研的新一代云原生关系型数据库,使用存算分离架构,利用软硬件结合的优势,提供极致弹性、高性能、海量存储、安全可靠的数据库服务。PolarDB有MysqL版和Postgresql版。PolarDB主要特性在于:
计算与存储分离,共享分布式存储。
计算节点通过分布式文件系统(PolarFileSystem)共享底层的存储(Polarstore)。
一写多读,读写分离。
采用多节点集群架构,集群中有一个主节点(可读可写)和至少一个只读节点。通过内部的代理层(PolarProxy)对外提供服务,代理层可以做安全认证和保护,还可以解析sql,把读操作均衡地分发到多个只读节点,实现自动的读写分离。
3.7.2 产品架构
PolarDB的架构如下图所示:

注:以上架构图摘自产品架构 (aliyun.com)
通过以下架构图显示,PolarDB的实现架构具体以下几个特点:
一写多读
PolarDB采用分布式集群架构,包括一个主节点和最多15个只读节点。主节点处理读写请求,只读节点仅处理读请求。主节点和只读节点采用Active-Active的Failover模式,提供高可用。
计算与存储分离
数据库的计算节点仅存储元数据,将数据文件、Redo Log等存储于远端的的存储节点。计算节点仅需同步Redo Log相关的元数据信息,极大降低主节点和只读节点的复制延迟。当主节点故障时,只读节点可以快速切换为主节点。
高速链路互联
计算节点与存储节点之间采用高速网络互联,并通过RDMA协议进行数据传输,使I/O性能不再成为瓶颈。
共享分布式存储
多个计算节点共享一份数据,而不是每个计算节点存储一份数据。基于全新打造的分布式块存储和文件系统。存储节点的数据采用多副本形式,通过Parallel-Raft协议保证数据一致性。
3.7.3 产品特点
闭源
分布式
兼容MysqL及Postgresql
读写分离
存算分离
分布式共享存储
3.8 AnalyticDB
3.8.1 产品简介
AnalyticDB是阿里自研的云原生数据仓库。用于实现海量数据实时高并发在线分析云计算服务,可以在毫秒级针对千亿级数据进行即时的多维分析透视和业务探索。AnalyticDB支持高吞吐的的数据实时增删改、低延时的实时分析和复杂ETL,兼容上下游生态工具,可用于构建企业级报表系统、数据仓库和数据服务引擎。
3.8.2 产品架构
AnalyticDB的架构如下图所示:

注:以上架构图摘自整体架构 (aliyun.com)
从上述架构图可以发现,AnalyticDB可以分为三层:
接入层
由Multi-Master可线性扩展的协调节点构成,负责协议层接入、sql解析和优化、实时写入Sharding、数据调度和查询调度。
计算引擎
具备分布式MPP和DAG融合执行能力,结合智能优化器,支持高并发和复杂sql混合负载。
存储引擎
基于Raft协议实现的分布式实时强一致高可用存储引擎,通过数据分片和Multi-Raft实现并并发,利用分层存储实现冷热分离,通过行列存储和智能索引达到极极致性能。
3.8.3 产品特点
闭源
分布式
数据仓库
兼容MysqL
存算分离
分层存储
3.9 Greenplum
3.9.1 产品简介
Greenplum是一种大规模并行处理(MPP)数据库,其架构特别针对管理大规模分析型数据仓库以及商业智能工作负载而设计。Greenplum是基于Postgresql开源技术的,本质上是多个Postgresql实例一起工作形成的紧密结合的数据库管理系统。Greenplum与PG的主要区别:
在基于PG查询优化器之外,可以利用GPORCA进行查询优化。
可以使用追加优化(append-optimized,AO)的存储。
可以选用列式存储。
3.9.2 产品架构
Greenplum的架构如下图所示:

注:以上架构图摘自关于Greenplum的架构 | Greenplum Database Docs
Greenplum数据库通过将数据和处理负载分布在多个服务器来存储和处理大量的数据。Greenplum数据库是一个由多个PG数据库组成的阵列,阵列中的数据库工作在一起呈现单一数据库的现象。主要包括Master、Segment及Interconnect三个主要部分。
Master
Master是数据库系统入口,接受连接和SQL查询并把工作分布到Segment实例上。Master是全局系统目录的所在地,全局系统目录是一组包含有关Greenplum数据库系统本身的元数据的系统表。Master不包含任何用户数据,数据只存放于Segment上。Master认证客户端连接、处理sql请求、在Segment之间分布工作负载、协调每个Segment返回的结果并将结果返回给客户端。
为了保证高可用,Master一般配置为主备模式。如下图所示,Standby节点用于当Master节点损坏时提供Master服务,Standby实时与Master节点的Catalog和事务日志保持同步。

Segment
Segment实例是独立的Postgresql数据库,每一个都存储数据的一部分并且执行查询处理的主要部分。当用户通过Master发出一个查询时,每个Segment数据库上都会创建一些进程来处理该查询工作。一台Segment主机通常运行2至8个Segment。
为了保证高可用,数据在Segment中使用镜像保护。每个Segment的数据冗余存放在另一个Segment上,数据实时同步。当Primary Segment失败时,Mirror Segment将自动提供服务。Primary Segment恢复正常后,使用gprecoverseg -F同步数据。

Interconnect
Interconnect是Greenplum架构中的网络层,指的是Segment之间的进程间通信以及通信依赖的网络基础设施。Interconnect采用标准的以太交换网络,出于性能原因,推荐使用万兆网或更快的网络。默认情况下,Interconnect使用带流控制的UDP在网络上发送消息。
3.9.3 产品特点
开源
分布式
OLAP->HTAP(GP新版本对OLTP有更好的支持)
兼容Postgresql
行式存储、列式存储
悲观锁+MVCC
3.10 CockroachDB
3.10.1 产品简介
CockroachDB是一款开源的分布式数据库,具有Nosql对海量数据的存储管理能力,又保持传统数据库ACID和sql等,还支持跨地域、去中心、高并发、多副本强一致和高可用等特性。支持OLTP场景,同时支持轻量OLAP场景。
3.10.2 产品架构
CockroachDB的架构如下图所示:

注:以上架构图摘自TiDB VS CockroachDB - 简书 (jianshu.com)
从上图可以发现,CockroachDB采用去中心化设计,逻辑上分为2层:sql层+分布式KV层。
sql层
由于CRDB节点都是对称的,因此可以向任何节点发送请求,无法哪个节点接收请求都将充当“网关节点”来处理请求。前端通过sql向集群发送请求,但数据最终以键值对的形式写入存储层和从存储层读取。因此,sql层将sql语句转换为KV操作计划,并将其传递给事务层。
存储层
每个CRDB节点至少包含一个store,在节点启动时指定,这是CRDB进程在磁盘上读取和写入其数据的地方。使用RocksDB将数据作为键值对存储在磁盘上,RocksDB作为墨盒API。每个store包含三个RocksDB实例:
一个用于Raft日志
一个用于存储临时分布式sql数据
一个用于节点上的所有其他数据
3.10.3 产品特点
开源
分布式
OLTP
兼容Postgresql
KV存储
乐观锁+MVCC
3.11 YugabyteDB
3.11.1 产品简介
YugabyteDB是一款全球部署的分布式开源数据库,和国内的TiDB和国外的CockroachDB类似,也是受到Spanner论文启发,在很多地方这几款数据库存在不少相似之处。YugabyteDB主打全球分布式的事务数据库,不仅能把节点部署到全球各地,还能完整支持ACID事务。除此以外还有一些独有的特性,比如支持文档数据库接口。
3.11.2 产品架构
YugabyteDB的架构如下图所示:

注:以上架构图摘自layered architecture for queries and storage | YugabyteDB Docs
从上图可以发现,YugabyteDB逻辑上分为2层:sql层+分布式KV层。
查询层
Yugabyte查询层(YQL)是YugabyteDB的上层。应用程序使用客户机驱动程序直接与YQL交互。这一层处理特定API的方面,比如查询/命令编译和运行时(数据类型表示、内置操作等)。构建YQL时考虑到了可扩展性,并允许添加新的API。
目前,YQL支持两种类型的分布式sql API,Ysql及YCQL。
DocDB分布式存储层
DocDB是一个分布式文档存储。它具有以下属性:
强写一致性
具有极强的抗失败能力
自动分片和负载均衡
分区/区域/云感知的数据放置策略
可调读一致性
DocDB中的数据存储在表中。每个表由行组成,每行包含一个键和一个文档。以下是一些要点:
分片
复制
持久化
事务
3.11.3 产品特点
开源
分布式
OLTP
兼容Postgresql
KV存储
乐观锁+MVCC
4 主流数据库对比
以上章节介绍了几种主流的数据库,下面我们使用表格的形式从各个不同的维度对这些产品进行对比
| 特征 | TiDB | openGauss | OceanBase | TDsql | GoldenDB | EsgynDB | PolarDB | AnalyticDB | Greenplum | CockroachDB | YugabyteDB |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 开源 | 是 | 是 | 是 | 否 | 否 | 是(Trafodion) | 否 | 否 | 是 | 是 | 是 |
| 分布式 | 是 | 否 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 |
| 系统架构 | 中心化 | 单机 | 去中心化 | 中心化 | 中心化 | 中心化 | 中心化 | 中心化 | 中心化 | 去中心化 | 去中心化 |
| 定位HTAP | 是 | 否(OLTP) | 是 | 否(OLTP) | 否(OLTP) | 是 | 否(OLTP) | 否(OLAP) | 否(OLAP) | 否(OLTP) | 否(OLTP) |
| 兼容性 | MysqL | Postgresql | MysqL+Oracle | MysqL | MysqL | Oracle | MysqL+ Postgresql | MysqL | Postgresql | Postgresql | Postgresql |
| 读写分离 | 是 | 否 | 是 | 是 | 是 | 否 | 是 | 是 | 否 | 否 | 否 |
| 存算分离 | 是 | 否 | 否 | 是 | 是 | 否 | 是 | 是 | 否 | 否 | 否 |
| 存储引擎 | KV+列式 | 行式+列式 | pax 行列混存 | 行式 | 行式 | KV+行式+列式 | 行式 | 行列混存 | 行式+列式 | KV | KV |
| 提交机制 | 2PC | 1PC | paxos+2PC | 2PC | 1PC+自动回滚补偿 | 2PC | 2PC | 2PC | 2PC | 通过事务表实现 | 通过事务表实现 |
| 并发控制 | 乐观锁+悲观锁+MVCC | 悲观锁+MVCC | 悲观锁+MVCC | 悲观锁+MVCC | 悲观锁+MVCC | 乐观锁+悲观锁 | 悲观锁+MVCC | 悲观锁+MVCC | 悲观锁+MVCC | 乐观锁+MVCC | 乐观锁+MVCC |
| 副本一致性 | Raft | 日志复制 | paxos | 基于binlog同步复制 | 基于binlog同步复制 | HDFS | Parallel Raft | Multi Raft | 基于xlog的同步复制 | Raft | Raft |
5 主流数据库对比总结
- 从是否开源角度,TiDB、openGauss、OceanBase、Greenplum、EsgynDB、CockroachDB、YugabyteDB均具有开源产品。TDsql、GoldenDB、PolarDB、AnalyticDB为非开源产品。
- 从是否分布式角度,只有openGauss是单机/主备部署,其余均为分布式系统。
- 从系统架构角度,OceanBase与CockroachDB、YugabyteDB类似,都是“去中心化”架构,即所有节点都是对等的。其余几款产品都是中心化架构。
- 从是否定位HTAP角度,只有TiDB、OceanBase、EsgynDB是原生定位HTAP的产品,其余产品在OLTP和OLAP都有侧重。其中AnalyticDB和Greenplum是主打OLAP,而openGauss、TDsql、GoldenDB、PolarDB和CockroachDB、YugabyteDB是主打OLTP。
- 从兼容性角度,兼容MysqL的有TiDB、OceanBase、TDsql、GoldenDB、PolarDB、AnalyticDB。兼容Postgresql的有openGauss、Greenplum、CockroachDB、PolarDB、YugabyteDB。兼容Oracle的有OceanBase、EsgynDB。
- 从读写分离角度,TiDB、OceanBase、TDsql、GoldenDB、PolarDB、AnalyticDB均支持读和写分离。openGuass、EsgynDB、Greenplum、CockroachDB、YugabyteDB暂不支持读写分离。
- 从存算分离角度,TiDB、TDsql、GoldenDB、PolarDB、AnalyticDB为存算分离。
- 从存储引擎角度,支持KV存储的有TiDB、EsgynDB、CockroachDB、YugabyteDB。支持列存的有TiDB、openGauss、EsgynDB、Greenplum。使用行列混存的有OceanBase、AnalyticDB。支持行存的有openGauss、TDsql、GoldenDB、PolarDB、Greenplum。
- 从提交机制角度,openGauss为单机数据库所以是1PC,分布式数据库几乎都是2PC。其中OceanBase额外增加了paxos算法。而CockroachDB、YugabyteDB则号称是使用“事务表”来实现的。
- 从并发控制角度,大多数产品都是基于悲观锁+MVCC。其中,TiDB和EsgynDB还支持了乐观锁。
- 从副本一致性角度,使用Raft复制的有TiDB、PolarDB、AnalyticDB、CockroachDB、YugabyteDB。使用paxos复制的有OceanBase。openGauss、TDsql、GoldenDB、Greenplum均是使用日志复制的方式,只不过openGauss和Greenplum是基于PG的日志复制,而TDsql和GoldenDB是基于MysqL的binlog复制。EsgynDB比较特殊,是采用HDFS自身的多副本机制实现。





