趴说
基于深度引导学习的快速多曝光图像融合
输入图像经过全卷积网络进行权值预测,将权重图经过引导滤波进行上采样,最后加权融合。
摘要
针对任意空间分辨率和曝光次数的静态图像序列,提出了一种快速多曝光图像融合(MEF)方法,即MEF- net。首先将低分辨率的输入序列输入到一个完全卷积网络中进行权值映射预测,然后使用引导滤波器对权重图进行上采样,最后的图像通过加权融合计算得到。与传统的MEF方法不同,MEF- net通过优化感知校准的MEF结构相似度(MEF- ssim)指数在训练序列数据库上以完全分辨率进行端到端训练。
介绍
我本文目标是为静态场景开发一种具有三个理想属性的MEF方法:
1、灵活性:可接受任意空间分辨率和曝光次数的输入序列。
2、高速度:便于高分辨率的实时移动应用程序。
3、高质量:在广泛的内容和亮度变化范围内产生高质量的融合图像
1、灵活性
为了实现灵活性,我们利用了一个完全卷积的网络[15],它接受任意大小的输入,并产生相应大小的输出(称为密集预测),该网络由不同的曝光图像共享,使其能够处理任意数量的曝光。
2、高速度
为了获得速度,我们遵循下采样-execute-上采样方案,并向网络提供低分辨率的输入序列。网络学习生成Eq.(1)中的低分辨率权值映射,并使用引导滤波器[18]联合上采样,最终进行加权融合。通过这样做,我们利用了权重图的平滑特性,并利用输入序列作为指导[19]。由于高分辨率序列中存在丰富的高频信息并且缺乏适当的引导,因此很难直接对融合图像进行上采样。
3、高质量
为了达到质量要求,我们将可微引导滤波器与前面的网络[19]集成,并针对大量训练序列上受试者校准的MEF结构相似性指数[9]对整个模型进行端到端优化。
提出的方法
1、 网络结构
本文描述了一种灵活、快速、高质量的MEF方法——MEF- net。MEF-Net由双线性下采样器、CAN、引导滤波器和加权融合模块组成。结构如图1所示。
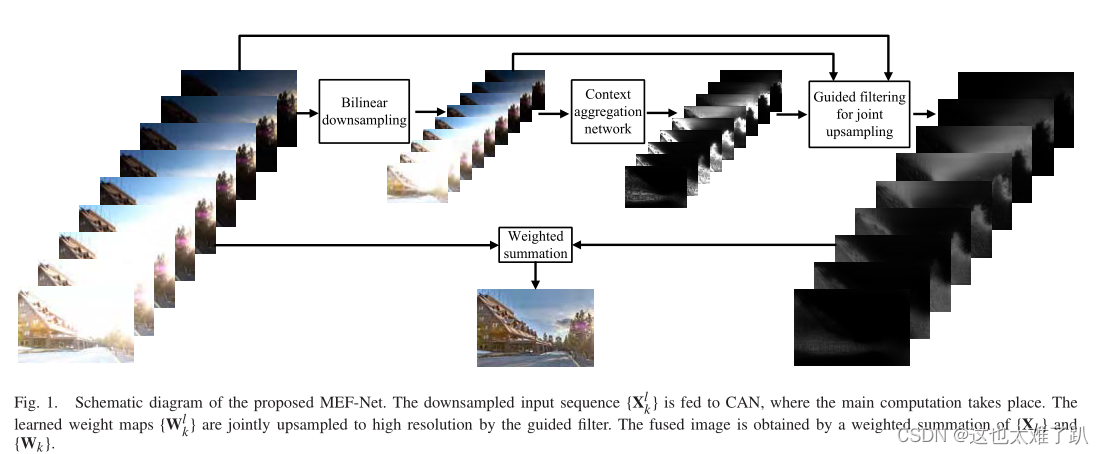
首先输入序列{ X k X_k Xk}下采样,向CAN提供低分辨率版本{ X k l X^l_k Xkl}来预测低分辨率权重图{ W k l W^l_k Wkl}。把{ W k l W^l_k Wkl},{ X k l X^l_k Xkl}和{ X k X_k Xk}作为输入,通过引导滤波器得到高分辨率权重图{ W k W_k Wk},该操作在计算机视觉[37]中也称为联合上采样。最后,我们使用Eq.(1)计算融合图像Y。MEF-Net是端到端可训练的,目标函数MEF-SSIM[9]在高分辨率下评估。
Y = ∑ k + 1 k W k ⨀ X k ( 1 ) Y=\sum^k_{k+1}{W_k}\bigodot{X_k}~~~~~~~~~~~~~(1) Y=k+1∑kWk⨀Xk (1)
2、用于低分辨率权重图预测的 CAN
MEF-Net的核心模块是一个卷积网络,它将低分辨率的输入序列{Xl k}转换为相应的权值图{Wl k}。网络必须允许任意空间大小和曝光数的{Xlk},并产生相应大小和数量的{Wlk}。为此,我们使用完全卷积网络来处理所有的曝光(即不同曝光的图像共享相同的权重生成网络),这可以通过batch维度分配{Xl k}来高效实现。
在众多可供选择的网络[15]、[38]中,我们选择了由Chen等人[14]和Wu等人[19]所倡导的CAN[34]来逼近图像处理算子。CAN的主要优点是它在不牺牲空间分辨率的前提下具有较大的接收场。它在更深层次上逐渐聚合上下文信息,完成全局图像统计的计算,从而更好地进行图像建模。表I指定了我们的CAN配置。
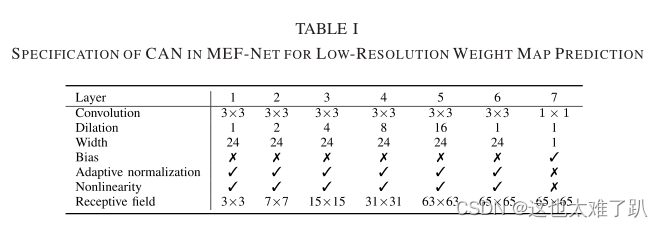
它有7个卷积层,它们的响应与输入具有相同的分辨率。与[14]类似,我们在卷积后立即进行自适应归一化。
A
N
(
Z
)
=
λ
n
Z
+
λ
n
′
I
N
(
Z
)
(
2
)
AN(Z)=\lambda_{n} Z +\lambda^\prime_nIN(Z)~~~~~~~~~~~~~(2)
AN(Z)=λnZ+λn′IN(Z) (2)
其中
λ
n
\lambda_n
λn
λ
n
′
\lambda^\prime_n
λn′∈R为可学习标量权值,Z为中间表示,IN(·)为实例归一化算子[39]。我们在这里选择不使用批归一化[40],因为批大小(即暴露次数)通常很小,这可能会在训练时由于批统计估计不准确而带来问题。此外,为了更好地保存
X
k
l
X^l_k
Xkl[20]的局部结构信息,我们采用LReLU作为点向非线性
L
R
E
L
U
(
Z
)
=
m
a
x
(
λ
r
Z
,
Z
)
(
3
)
LRELU(Z)=max(\lambda_rZ,Z) (3)
LRELU(Z)=max(λrZ,Z)(3)其中
λ
r
\lambda_r
λr> 0为训练时的固定参数。输出层使用1 × 1卷积产生
W
k
l
W^l_k
Wkl,没有自适应归一化和非线性.
3、 高分辨率权重图的引导滤波器
引导滤波器的关键假设是导引I和滤波输出Q之间的局部线性模型。
Q
(
i
)
=
a
ω
I
(
i
)
+
b
ω
∀
i
∈
ω
(
4
)
Q(i)=a_\omega I(i)+b_\omega~~~~~\forall i \in \omega ~~~(4)
Q(i)=aωI(i)+bω ∀i∈ω (4)其中,i是引导的索引,
ω
\omega
ω是半径为
r
r
r的窗口,
a
ω
a_\omega
aω,
b
ω
b_\omega
bω是假设在
ω
ω
ω中恒定的线性系数,可以通过最小化重建误差来计算
l
(
a
ω
,
b
ω
)
=
∑
i
∈
ω
(
(
a
ω
I
(
i
)
)
+
b
ω
−
P
(
i
)
)
2
+
λ
a
a
ω
2
(
5
)
l(a_ω,b_ω)=\sum _{i\in ω}((a_ωI(i))+b_ω-P(i))^2+\lambda_aa^2_ω ~~~~~~(5)
l(aω,bω)=i∈ω∑((aωI(i))+bω−P(i))2+λaaω2 (5)其中 P 是滤波输入,而
λ
a
λ_a
λa是惩罚大
a
ω
a_ω
aω的正则化参数[18]。在MEF-Net环境下,将低分辨率的
W
k
l
W^l_k
Wkl和
X
k
l
X^l_k
Xkl作为输入和引导滤波器的引导,分别得到
A
k
l
A^l_k
Akl和
B
k
l
B^l_k
Bkl。 我们替换了 Alk 和 Blk 上的平均滤波器,并将它们双线性上采样得到高分辨率 Ak 和 Bk。高分辨率权重图 Wk 的计算公式为
W
k
=
A
k
⨀
X
k
+
B
k
(
6
)
W_k=A_k \bigodot X_k+B_k~~~~~~~~~~~~~~(6)
Wk=Ak⨀Xk+Bk (6) 为了在训练过程中稳定梯度,并获得一致的结果,我们取{Wk}的绝对值,然后进行归一化。
W
k
(
i
)
=
∣
W
k
(
i
)
∣
∑
k
k
=
1
∣
W
k
(
i
)
∣
^
(
7
)
\hat{W_k(i)=\frac{|W_k(i)|}{\sum ^k_k=1|W_k(i)|}}~~~~~~~~~~~~(7)
Wk(i)=∑kk=1∣Wk(i)∣∣Wk(i)∣^ (7)
图2展示了学习到的源序列“Corridor”的权值映射{
W
k
W_k
Wk},其中
W
k
^
\hat {W_k}
Wk^中较亮的像素表示
X
k
X_k
Xk中对应的像素对融合图像
Y
Y
Y的贡献更多。学习到的
W
k
^
\hat {W_k}
Wk^具有几个理想的属性。首先,
W
k
^
\hat {W_k}
Wk^是平滑的:从尖锐区域到平坦区域的平缓过渡。其次,
W
k
^
\hat {W_k}
Wk^偏好对比度高、曝光良好的区域,这两个区域显著影响
Y
Y
Y的感知质量。最后,
W
k
^
\hat {W_k}
Wk^反映了
X
k
X_k
Xk的全局结构,有利于大规模细节保存。因此,融合后的图像看起来很自然,没有丢失细节和伪影。

4、MEF-SSIM作为目标函数
在本节中,我们详细介绍了MEF-SSIM索引[9]作为MEF-Net的目标函数。具体来说,MEF-SSIM将一个图像补丁xk分解为三个概念上独立的组件
X
k
=
∣
∣
X
k
−
μ
X
k
∣
∣
⋅
X
k
−
μ
X
k
∣
∣
X
k
−
μ
X
k
∣
∣
+
μ
X
k
=
∣
∣
X
ˇ
k
∣
∣
⋅
X
ˇ
k
∣
∣
X
ˇ
k
∣
∣
=
c
k
⋅
s
k
+
l
k
\begin{align} X_k & = ||X_k-\mu_{X_k}||\cdot\frac{X_k-\mu_{X_k}}{||X_k-\mu_{X_k}||}+\mu_{X_k} \\ &= ||\check X_k||\cdot \frac{\check X_k}{||\check X_k||}\\ & = c_k \cdot s_k+l_k \end{align}
Xk=∣∣Xk−μXk∣∣⋅∣∣Xk−μXk∣∣Xk−μXk+μXk=∣∣Xˇk∣∣⋅∣∣Xˇk∣∣Xˇk=ck⋅sk+lk
其中,
∣
∣
⋅
∣
∣
||\cdot||
∣∣⋅∣∣代表2范数,
c
k
c_k
ck,
s
k
s_k
sk,
l
k
l_k
lk分别表示强度,对比度和结构。
融合后图像块的期望强度由下式子得到:
l
^
=
∑
k
=
1
k
ω
l
(
μ
k
,
l
k
)
l
k
∑
k
=
1
k
ω
l
(
μ
k
,
l
k
)
(
8
)
\hat{l}=\frac{{\sum^k_{k=1} \omega_l(\mu_k,l_k)l_k}}{{\sum^k_{k=1}\omega_l(\mu_k,l_k)}}~~~~~~~~~~~~~(8)
l^=∑k=1kωl(μk,lk)∑k=1kωl(μk,lk)lk (8)
其中,
ω
l
\omega_l
ωl是
X
k
X_k
Xk的全球平均强度
μ
k
μ_k
μk和局部平均强度
l
k
l_k
lk的权函数,
ω
l
(
⋅
)
\omega _l(\cdot)
ωl(⋅)由二维高斯剖面指定。
w
l
(
μ
k
,
l
k
)
=
e
x
p
(
−
(
μ
k
−
τ
)
2
2
σ
g
2
−
(
l
k
−
τ
)
2
2
σ
l
2
)
(
9
)
w_l(\mu _k,l_k)=exp(-{\frac{(\mu_k-\tau)^2}{2\sigma^2_g}}-{\frac{(l_k-\tau)^2}{2\sigma^2_l}})~~~~~~~~~~~~~~~~~(9)
wl(μk,lk)=exp(−2σg2(μk−τ)2−2σl2(lk−τ)2) (9)
其中,
σ
g
\sigma_g
σg和
σ
l
\sigma_l
σl为两个光度差,分别设置为0.2和0.5。
τ
\tau
τ= 128表示8位序列的中强度值。期望的对比度由
x
k
{x_k}
xk中的最高对比度决定。
c
^
=
m
a
x
c
k
1
≤
k
≤
K
(
10
)
\hat{c}=max {c_k}~~~~~~~_{1≤k≤K}~~~~~~~~~~(10)
c^=maxck 1≤k≤K (10)期望的结构是通过加权求和来计算的。
s
^
=
s
ˉ
∣
∣
s
ˉ
∣
∣
,
~~~~~~~~~~~~~~~~~~~~~\hat{s}=\frac{\bar{s}}{||\bar{s}||},~~~~~
s^=∣∣sˉ∣∣sˉ, where
s
ˉ
=
∑
k
=
1
k
ω
s
(
x
ˇ
k
)
s
k
∑
k
=
1
k
ω
s
(
x
ˇ
k
)
(
11
)
\bar{s}=\frac{\sum^k_{k=1}\omega_s(\check{x}_k)s_k}{\sum^k_{k=1}\omega_s(\check{x}_k)}~~~~~~~~~~~(11)
sˉ=∑k=1kωs(xˇk)∑k=1kωs(xˇk)sk (11)
其中,
w
s
(
⋅
)
=
∣
∣
⋅
∣
∣
∞
w_s(\cdot)=||\cdot||_\infty
ws(⋅)=∣∣⋅∣∣∞是
l
∞
l_\infty
l∞范数权重和。
一旦确定
l
^
\hat{l}
l^,
c
^
\hat{c}
c^和
s
^
\hat{s}
s^,我们对分解过程进行反求,得到所需的融合块。
x
^
=
c
^
⋅
s
^
+
l
^
(
12
)
\hat{x}=\hat{c} \cdot \hat{s}+\hat{l}~~~~~~~~~~(12)
x^=c^⋅s^+l^ (12)
MEF-SSIM的构造遵循SSIM索引[43]的定义:
S
(
x
k
,
y
)
=
(
2
μ
x
^
+
μ
y
+
C
1
)
(
2
σ
x
^
y
+
C
2
)
(
μ
x
^
2
+
μ
y
2
+
C
1
)
(
σ
x
^
2
+
σ
y
2
+
C
2
)
(
13
)
S({x_k},y)=\frac{(2\mu_{\hat{x}}+\mu_y+C1)(2\sigma_{{\hat{x}y}}+C2)}{(\mu^2_{\hat{x}}+\mu^2_y+C1)(\sigma^2_{\hat{x}}+\sigma^2_y+C2)}~~~~~~~~~~~~(13)
S(xk,y)=(μx^2+μy2+C1)(σx^2+σy2+C2)(2μx^+μy+C1)(2σx^y+C2) (13)
其中
μ
x
^
\mu_{\hat{x}}
μx^ 和
μ
y
μ_y
μy 表示所需patch和给定融合patch的平均强度。
σ
x
^
\sigma_{\hat{x}}
σx^,
σ
y
\sigma _y
σy
σ
x
^
y
\sigma_{\hat {x}y}
σx^y分别表示
x
^
\hat{x}
x^和
y
y
y的局部方差及其协方差。C1和C2是两个小的常数,防止不稳定。对局部的S值进行平均,得到融合图像的整体质量度量如下。
M
E
F
−
S
S
I
M
(
X
K
,
Y
)
=
1
M
∑
i
=
1
M
S
(
R
i
X
k
,
R
i
Y
)
(
14
)
MEF-SSIM({X_K},Y)=\frac{1}{M}\sum^M_{i=1}S({R_iX_k},R_iY)~~~~~~~~(14)
MEF−SSIM(XK,Y)=M1i=1∑MS(RiXk,RiY) (14)
其中
R
i
R_i
Ri为从图像中提取第i个patch的矩阵,MEF-SSIM评分范围为0 ~ 1,数值越大,视觉质量越好。
普通版MEF- ssim[9]剔除了强度比较,Prabhakar等人[6]采用它来驱动MEF的卷积网络学习。在我们的实验中,我们发现在没有强度信息的情况下优化MEF-SSIM是不稳定的,导致融合后的图像外观相对苍白(如图6)。改进版MEF-SSIM[8]增加了Eq.(13)中的强度比较,直接处理颜色序列。然而,在某些情况下,它可能会产生过度饱和的颜色。为了获得更保守、伪影较少的融合图像,我们选择按照[6]中建议的方法分别处理色度分量。具体来说,我们采用Y 'CbCr格式,只在
X
k
{X_k}
Xk和
Y
Y
Y的亮度分量上评估MEF-SSIM,换句话说,MEF-Net中的CAN被优化以融合亮度分量。对于Cb色度分量,我们采用[6]中建议的简单加权求和。
b
^
=
∑
K
=
1
K
ω
c
(
b
k
)
b
k
∑
K
=
1
K
ω
c
(
b
k
)
(
15
)
\hat{b}=\frac{\sum^K_{K=1}\omega_c(b_k)b_k}{\sum^K_{K=1}\omega_c(b_k)}~~~~~~~~~~~~~~~(15)
b^=∑K=1Kωc(bk)∑K=1Kωc(bk)bk (15)
其中
b
k
b_k
bk为第k次曝光时Cb色度值,
ω
c
(
b
k
)
=
∣
∣
b
k
−
τ
∣
∣
1
\omega_c(b_k)=||b_k-\tau||_1
ωc(bk)=∣∣bk−τ∣∣1为1范数权重函数。Cr色度成分可以以相同的方式融合。最后,我们将融合的图像从ycbcr转换回RGB。
训练
我们为MEF-Net收集了一个大规模数据集。最初,我们收集了1000多个暴露序列,主要来自五个来源[6]、[20]-[23]。我们首先消除包含可见物体运动的序列。对于相机运动,我们保留那些已经通过现有的图像配准算法[44]成功对齐的序列。经过筛选,总共保留了690个静态序列,跨越了大量的HDR内容,包括室内与室外、人物与静物、白景与夜景。一些代表性序列如图3所示。空间分辨率在0.2到2000万像素之间,而曝光次数在3到9次之间。我们在600个序列上训练MEF-Net,并留下剩下的90个序列进行测试。
在训练过程中,我们只在最细尺度上应用MEF-SSIM,以减少GPU的内存消耗。MEF-SSIM的参数继承自[8]、[9]。我们将曝光序列的大小分别调整为128s和512s作为MEF-Net的低分辨率和高分辨率输入,其中128s意味着短尺寸被调整为128,同时保持长宽比。LReLU的参数 λ r \lambda_r λr固定在0.2,将导引滤波器的半径r设为1,正则化参数 λ a λ_a λa设为 1 0 − 4 10^{−4} 10−4。 λ a λ_a λa是MEFNet中的一个关键参数。培训使用Adam求解器[45],学习速率为 1 0 − 4 10^{−4} 10−4。Adam的其他参数默认设置。batch大小等于当前序列中曝光的数量。当达到最大epoch=100时,学习停止。我们试图在大于512s[19]的各种高分辨率序列上进一步训练MEF-Net,但这并没有产生明显的改善。最后,我们在测试过程中评估MEF-Net的全分辨率





