背景
在不同业务的表使用中,如果不注意数据类型,很容易导致取出数据的字段值为0而导致错误判断。
比如在这个业务场景中业务取出字段为0:原因是二级key作为的是另一个map的key而不是一个属性。
错误取法:rgpnewbehavior.accumulatedbehavior["STATIC:Game_90d"].total.pay_order_cnt
正确取法:rgpnewbehavior.accumulatedBehavior['STATIC:Game_30d_v1']['total'].pay_order_cnt
下面正文对Hive的数据类型做一个总结使用。
原子类型
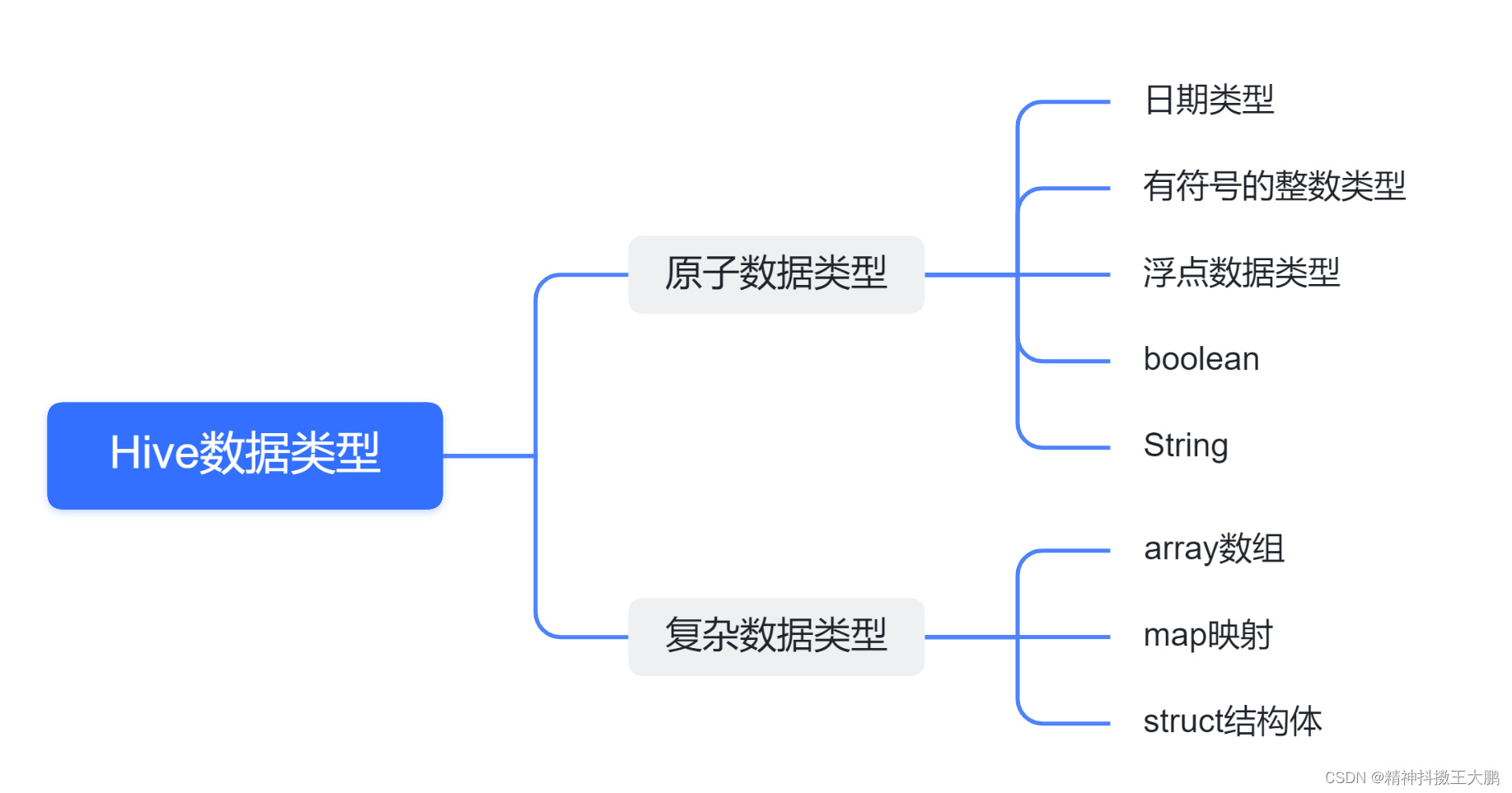
Hive 是用 Java 开发的,除了String 类型,Hive 里的基本数据类型和 java 的基本数据类型(字符、布尔和数值类)是一一对应的。
- 有符号的整数类型:tinyint、SMALLINT、INT 和 BIGINT 分别等价于 Java 的 Byte、Short、 Int和 Long 原子类型,分别为 1 字节、2 字节、4 字节和 8 字节有符号整数;
- 浮点数据类型:FLOAT 和 DOUBLE,对应于 Java 的基本类型 Float 和 Double 类型;
- BOOLEAN 类型:相当于 Java 的基本数据类型 Boolean;
复杂类型
复杂数据类型包括数组(ARRAY)、映射(MAP)和结构体(STRUCT):
- ARRAY:ARRAY 类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问。 比如有一个 ARRAY 类型的变量 fruits,它是由['apple','orange','mango']组成,可以由下标fruits[1]来访问元素orange。hive中经过split拆分后为ARRAY类型;
- MAP:MAP 包含 key->value 键值对,可以通过 key 来访问元素。比如变量userlist是一个 map类型:username:password,需要通过userlist['username']来得到这个用户对应的 password。
- STRUCT:STRUCT 可以包含不同数据类型的元素。这些元素可以通过点语法的方式来得到所需要的元素,比如 user 是一个 STRUCT 类型:15,北京。可以通过 user.address 得到这个用户的地址。
复合数据类型实践
复合数据类型的优势是把多表关系通过一张表就可以实现,拿学生表举个例子:
| CREATE TABLE student( name STRING, -- 爱好有多个,长短不清楚 favors ARRAY<STRING>, -- 课程有多个,每个课程有对应的分数 scores MAP<STRING, FLOAT>, address STRUCT<province:STRING, city:STRING, detail:STRING, zip:INT> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ';' MAP KEYS TERMINATED BY ':' ; | @H_404_132@
在关系型数据库中,如果想表达至少需要三张表来关联定义【若考虑范式,需要更多张表】:学生基本信息表(名字,学生id)、爱好表(学生id,爱好)、成绩表(学生id,课程名,成绩)。
数组array
- 建表
| create table person( name string, -- 指定数组类型 location array<string> ) row format delimited fields terminated by "\t" collection items terminated by ","; | @H_404_132@
- ROW FORMAT DELIMITED 用来指明后面的关键词是列和元素分隔符,列和元素以\t作为分隔;
- COLLECTION ITEMS TERMINATED BY 是元素分隔符,Array 中的各元素以,分隔;
- 通过vim建立一个txt文本
| Plain Text vim array.txt Huangbo beijing,shanghai,tianjin,Hangzhou Xuzheng tianjin,chengdu,wuhan Wangbaoqiang wuhan,shenyang,jilin | @H_404_132@
- 将文本数据映射到hive表
| load data local inpath '/home/data/array.txt' into table person; | @H_404_132@
- 查表
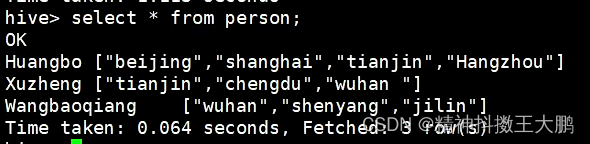
| select * from person; | @H_404_132@
查表查出来的字段为两个,第二个是一个数组。
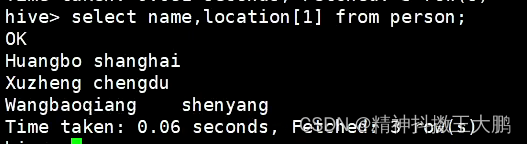
| -- 取数组中对应的值 select name, location[1] from person; | @H_404_132@
映射map
- 建表
| create table score( name string, -- 设置map类型 scores map<string,int> ) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':'; | @H_404_132@
- ROW FORMAT DELIMITED 用来指明后面的关键词是列和元素分隔符,列和元素以\t作为分隔;
- COLLECTION ITEMS TERMINATED BY 是元素分隔符,Array 中的各元素以,分隔;
- MAP KEYS TERMINATED BY 是 Map 中 key 与 value 的分隔符,默认为:;
- 通过vim建立一个txt文本
| Plain Text vim map.txt huangbo yuwen:80,shuxue:89,yingyu:95 xuzheng yuwen:70,shuxue:65,yingyu:81 wangbaoqiang yuwen:75,shuxue:100,yingyu:75 | @H_404_132@
- 将文本数据映射到hive表
| load data local inpath '/home/data/map.txt' into table score; | @H_404_132@
- 查表
| select * from score; | @H_404_132@
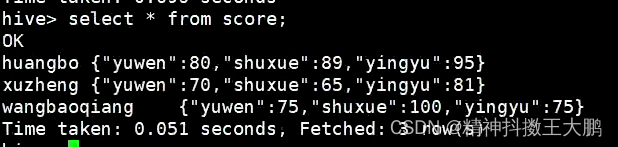
显示两列数据,第二列为map:key和value之间用:,k-v对之间用,作为分隔。
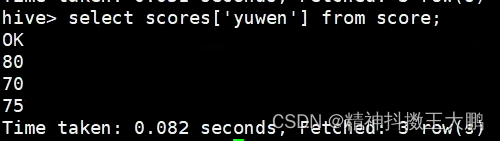
| -- 只拿语文的成绩,用通过[key]来拿value。 | @H_404_132@
struct结构
- 建表
| create table structtable( id int, -- 设置struct类型 course struct<name:string,score:int> ) row format delimited fields terminated by '\t' collection items terminated by ','; | @H_404_132@
- ROW FORMAT DELIMITED 用来指明后面的关键词是列和元素分隔符,列和元素以\t作为分隔;
- COLLECTION ITEMS TERMINATED BY 是元素分隔符,Array 中的各元素以,分隔;
- 通过vim建立一个txt文本
| Plain Text vim structtable.txt 1 english,80 2 math,89 3 chinese,95 | @H_404_132@
- 将文本数据映射到hive表
| load data local inpath '/home/data/structtable.txt' into table structtable; | @H_404_132@
- 查表
| select * from structtable; | @H_404_132@
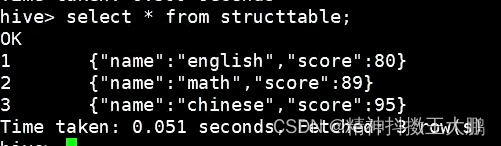
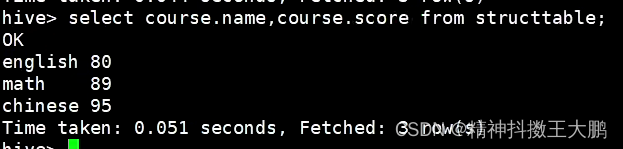
两列,第二列为struct,通过.来获取struct的值。
| select course.name, course.score from structtable; | @H_404_132@