前言
熟悉Linux网络或者存储编程的开发人员,对于libaio [1] (Linux-native asynchronous I/O) 应该并不太陌生。Libaio提供了一套不同于POSIX接口的异步I/O接口,其目的是更加高效的利用I/O设备。在最近几年的过程中,有很多Linux 开发人员试图去优化libaio相关的实现,但是收效甚微。于是Jens [2] 开发了一套新的异步编程接口io_uring [3] ,主要是为了替代libaio,目前主要应用在存储的场景中。相比使用libaio,在存储中使用io_uring,那么应用的性能有了显著的提升。比如说用FIO程序,采用不同的存储引擎libaio和io_uring测试同样的NVMe SSD(见[4]),io_uring的效果要好不少。为此也有一些文章宣称,在某些场景下使用io_uring + Kernel NVMe的驱动,效果甚至要比使用SPDK 用户态NVMe 驱动更好。当然在SPDK 项目中,用户也进行如下的对比,使用FIO + SPDK bdev 测试同样的NVMe 盘,可以采用以下的三种bdev进行性能比较: (1) 基于SPDK中用户态NVMe驱动的bdev; (2) 基于SPDK中libaio实现的bdev;(3) 基于SPDK中io_uring实现的bdev。然后可以自行比较一下哪种方式性能最好。
在这篇文章中,我们主要是把io_uring使用在网络中。为了使得大家更清晰的了解,我们将在本文中介绍如下内容:
-
SPDK socket API的现状
-
SPDK中怎么高效利用kernel TCP/IP 栈
-
io_uring目前存在的一些问题
-
在SPDK 中怎么使能io_uring
SPDK socket API 现状
在SPDK的代码库,我们有一个socket API 位于(lib/sock)目录下,这个SPDK socket API主要用于封装各个不同的TCP/IP的socket实现,包括基于内核TCP/IP的socket, 以及用户态的socket实现。图1给出了目前代码中实现的一些情况, SPDK 20.04 版本以及主分支上有三种sock封装, POSIX(module/sock/posix), uring(module/sock/uring), vpp (module/sock/vpp) 。其中POSIX库主要是使用了POSIX的接口去操纵kernel的TCP/IP 栈,uring主要是采用io_uring的接口去使用kernel TCP/IP的栈,VPP 的socket主要是整合了VPP的用户态TCP/IP 栈。从图1中我们可以看到,目前我们主要推荐POSIX的实现。因为uring socket的实现需要环境的支持,比如对Linux kernel版本的要求。目前Linux kernel对于io_uring的支持还在开发过程中,所以在SPDK 中基于io_uring的socket实现,需要不断地完善和更新。但是不可否认,使用io_uring来高效地使用kernel TCP/IP 栈是未来的发展趋势。
对于SPDK中VPP的整合,目前的状况是在SPDK中的集成,将会在20.07停止,20.10中把VPP的sock实现从SPDK 中删除。其主要原因是基于VPP的sock实现并没有体现出相应的性能优势,具体的声明可以参考 [5] 。至于Seastar在SPDK 的集成工作,目前也处于停滞的阶段, 具体patch请见[6]。现在SPDK socket API工作的重点在怎么高效利用kernel的TCP/IP栈实现。
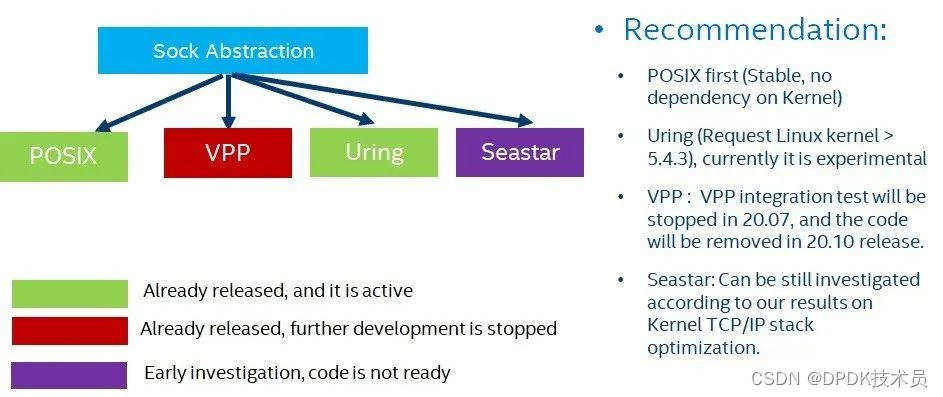
图1 SPDK 代码库中的SOCK封装
高效使用kernel TCP/IP 栈
SPDK 的编程框架的总体思想是异步(asynchronous),数据通路无锁化(lock free data path),以及基于用户态的存储协议栈。虽然kernel TCP/IP 栈在内核中的实现并不是无锁的,但是应用程序可以尽可能高效地利用kernel TCP/IP 栈。为了配合SPDK的编程框架,我们采用了以下的方法在用户态高效利用kernel TCP/IP栈,可以分为以下两类,针对单socket以及针对多socket。
针对单socket的优化
1. 采用非阻塞的I/O。 对于一个SOCKET File Descriptor(简称为SOCK_FD)。我们需要通过系统调用设置相应的属性O_NONBLOCK。这个主要是因为在发生调用的时候,诸如read或者write。我们不希望调用者阻塞在那里。因为根据SPDK的framework,我们还有其他任务去做(参考SPDK 编程framework这篇文章[7])。如果采用阻塞的I/O将会影响到后续其他任务的调度。当然采用非阻塞I/O,就必须要处理可能存在的部分读或者写的问题(partial read/write)。举个例子如图2 所示,用户发起了一个writev操作,vector里面有三个元素,长度分别是4096, 8192,8192,总长度是16384。那么可能返回结果是,第一个元素的写全部完成,第二个完成了一半,第三个什么都没完成。很显然我们需要处理这样的情况,要么让用户自己处理,要么在SPDK 库里面需要处理。
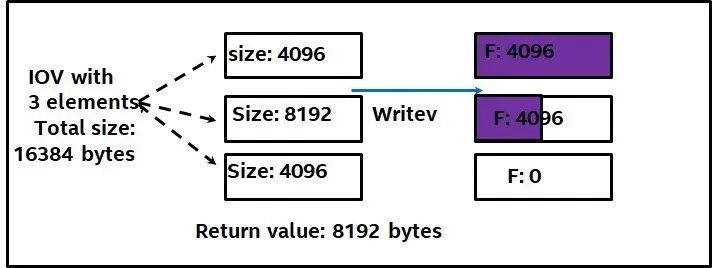
图2 部分写问题
2.减少系统调用。我们知道使用内核TCP/IP栈使用网络读写,需要利用系统调用。频繁的系统调用会产生大量的上下文切换(进程和内核之间)。为此有必要减少系统调用。
-
对读系统调用的优化。对于读的系统调用,我们可以采用以下的策略。比如在用户态开辟一片较大的缓存,然后尽可能一次性读取大量数据,如图3 所示。这里我们可以看到在用户态分配了一个大的临时buffer,然后采用read或者readv进行操作,然后把读到的内容分配拷贝到用户自己逻辑的Buffer1,Buffer2或者Buffer3中。这里读者不仅要问,为什么不能直接利用Buffer1-3 直接构建一个vector数组,进行readv读写。这个问题在于, 并不是在任何时候,我们都能明确知道要进行读的地址。举个例子,比如在NVMe-oF TCP的parse过程中,我们可以把PDU的header配置一个buffer,PDU所涉及到的数据采用另外一个buffer。但是并不是每个PDU 都有带有数据。所以我们不能保证在进行读的时候,知道所有buffer的地址。这么看来不能减少数据的拷贝。显然用这样的方法,我们可以减少读操作的系统调用,但是增加了新的代价,即数据拷贝。为此我们必须做到平衡,意思是在减少系统调用的时候,尽可能采用一些其他硬件卸载数据拷贝的代价。比如在Intel平台上我们可以使用CBDMA(Crystal beach DMA)或者DSA (Data Streaming Accelerator) 去进行copy操作,用于减轻cpu的工作。
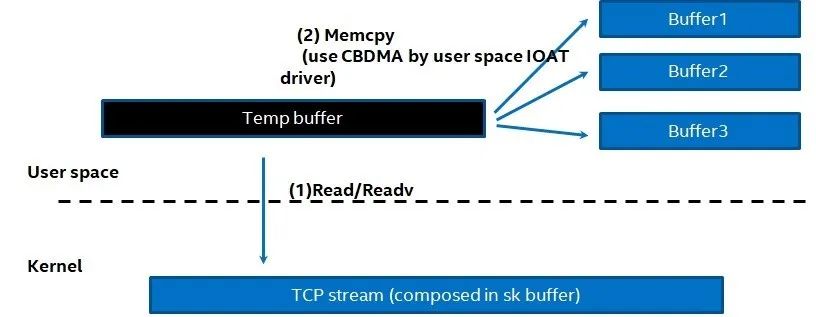
图3 采用大buffer减少读系统调用
-
合并写操作减少系统调用。对于写的操作,为了减少系统调用,我们可以把多个writev操作合并成一个writev操作。其主要思路就是构建一个新的vector数组,把多个writev各自的vector数据的信息放入。这样可以减少写的系统调用。
3. 采用MESSAGE ZERO copY。 在网络编程中,写数据可以采用zero copy。这个特性在Linux 4.1. 4以后支持。比如在SPDK POSIX sock的实现中,我们对于写的IO, 在target 那端,采用了Message zero copy。这个需要调用setsockopt系统调用对SOCK_FD进行设置(使用这个key:SO_ZEROcopY)。然后在对socket进行写的时候,我们不在使用writev,而是采用sendmsg, 然后采用MSG_ZEROcopY 对应的flag。这样的好处是我们可以避免I/O copy。那么Linux网络内核栈会Pin住用户提供的内存,而不是将其复制到内核中的发送缓冲区。当然Pin住这些内存,需要有额外的代价。另外采用MSG_ZEROcopY 后,会产生一些额外的事件, 即target端Message control path上的错误事件: MSG_ERRQUEUE。我们需要进行相应的处理。因为在POSIX实现中,我们也使用了异步的写接口,为此必须等到那个写操作已经完成了,然后调用相应的callback函数。
目前1 和2相应的实现已经存在于SPDK的POSIX和uring的socket实现中, 3的实现主要在POSIX中。
针对多socket的优化
除了针对单socket的优化,SPDK socket实现中采用了以下的机制,来保证更高效的运行;
1. 采用唯一的SPDK thread 管理一个socket 的生命周期。在SPDK 中,对于每个连接(可以对应到相应的socket)I/O 读写处理,我们都使用唯一的SPDK thread。这意味着,我们尽可能避免了多个cpu 在竞争处理同一个连接。为了做到这一点,当我们的Socket Listener得到一个新的连接的时候,我们就可以利用算法把这个connection的处理调度到一个特定的SPDK thread之上处理。
2. 基于组的高效异步I/O 处理。一个SPDK thread可以管理多个连接,为了更高效地处理每个I/O上发生的读写事件。当然用户调用SPDK 基于组的polling的时候(函数是spdk_sock_group_poll) 我们采取了如下策略:
-
一次性侦测组中所有socket的POLLIN 事件。 比如在POSIX SOCK实现中,我们采用epoll的机制。在每一轮中,一次性调用epoll_wait去侦测组中哪些socket有读的事件。这样相比用read或者readv去单独侦测哪个socket有读时间要好很多。举个极端的例子,如果一个组中有100个连接,如果只有一个连接有读的事件。那么采用epoll的方式,我们只用了两个系统调用,epoll_wait以及read。但是不采用epoll,我们需要100个系统调用,即对每个连接调用read或者readv。
-
减少整个组的"写操作"的系统调用。正常来讲,如果每一个socket都要调用"写操作",那么一个组有N个连接,就需要有N个写系统调用。为了更好的解决这个问题,我们引入了uring(当然采用libaio也可以),如图4所示。我们可以看到在每一轮中,我们可以一次性对所有组中所有socket上的写请求,进行提交。如果组中有N个连接,在每一轮我们可以减少N-1次系统调用。当然异步的写,还会引起每个socket上部分写的问题(类似图2描述的那样)。这个问题在SPDK POSIX以及uring的实现中,均已经解决。我们主要的思路是,在下一轮可以重建IO vector,然后进行在下一轮重新提交。当然我们在下一轮的写请求提交中,不仅仅是提交上一轮中每个socket未完成的写I/O,我们也会在合并在上一轮和这一轮中新产生的I/O。为此这个设计是非常高效的。
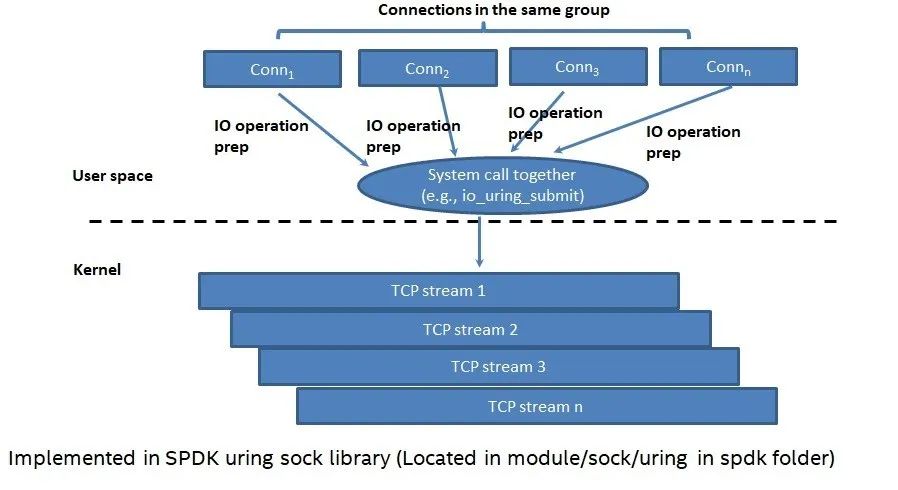
图4 采用异步组提交的方式减少"写系统"调用
io_uring目前使用的一些问题
SPDK uring的实现完全基于io_uring,目前在满足版本需求的Linux kernel上可以正常工作。当然在SPDK uring的整个开发过程中,我们也碰到了一些问题,有些问题liburing库相关的问题,有些问题是Linux kernel中io_uring实现局限。我们把这些问题反馈给io_uring的开发者Jens,得到了非常正面的反馈,也得到了相应的支持。目前角度看来,尚且存在以下的一些问题, 诸如:
-
Fixed buffer 支持。io_uring可以注册固定的缓存,使得Linux内核可以Pin住这次内存,用于提高效率。但是目前io_uring 的固定缓存的支持比较有限。比如目前支持的是:io_uring_prep_write_fixed 以及io_uring_prep_read_fixed。但是并没有支持io_uring_prep_writev_fixed以及io_uring_prep_readv_fixed。对于sendmsg以及recvmsg中的message填充的IOV似乎也没有支持fixed 的buffer。这个无疑是一个缺陷。目前这个特性的改进,估计会出现在以后的版本中。
-
Control message的异步处理。目前io_uring中 io_uring_prep_sendmsg以及io_uring_prep_recvmsg对于数据通道相关的message,均可以支持异步处理。但是对于control message不能支持异步。比如在SPDK POSIX实现中的Message zero copy, 我们并不可以采用异步的recvmsg进行检查。
-
IORING_SETUP_IOPOLL对于网络设备的支持。 目前创建uring的时候,这个选项仅仅可以作用于O_DIRECT模式打开的文件或者设备,才可以让用户选择在用户态自己进行轮询。显而易见,网络的描述符并不满足这个特性。
SPDK 中使能io_uring
-
升级Linux 内核,至少满足内核版本大于5.4.3. 当然越高版本的内核对于io_uring的支持越好,比如Linux kernel 版本5.7-rc1以上的特性应该丰富,诸如支持IORING_FEAT_FAST_POLL 。
-
下载和安装liburing的库:
https://github.com/axboe/liburing
-
编译SPDK, 打开如下开关:./configure --with-uring 。如果liburing没有安装在系统指定的目录,需要自己指定。这样编译出的SPDK 可执行文件,会优先使用SPDK的uring socket实现,而不是POSIX。比如启动SPDK NVMe-oF tcp target, 就会采用SPDK uring 的socket实现。
总结
本文介绍了SPDK 项目中socket实现的一些现状,以及在SPDK 中我们是怎样高效利用内核的TCP/IP 栈,并在POSIX以及uring的socket 模块中实现。在我们的后续开发过程中,我们会继续不断地完善SPDK uring socket的实现。
原文链接:https://mp.weixin.qq.com/s/ewP-jZ6ydgGvV1pchn2T6g
学习更多dpdk视频
DPDK 学习资料、教学视频和学习路线图 :https://space.bilibili.com/1600631218
Dpdk/网络协议栈/ vpp /OvS/DDos/NFV/虚拟化/高性能专家 上课地址: https://ke.qq.com/course/5066203?flowToken=1043799
DPDK开发学习资料、教学视频和学习路线图分享有需要的可以自行添加学习交流q 君羊909332607备注(XMG) 获取





