前言
本次主要搬运2023年字节实习面试情况
文章目录
问题总结
进程和线程有什么区别?
多线程有什么好处?
chrome架构是多线程还是单线程?

答:多线程。采用多进程可以使浏览器具备更好的容错性,提供安全性和沙盒性。因为操作系统可以提供方法限制每个进程拥有的能力,所以浏览器可以让某些进程只能具备特定的功能,例如Chrome的Tab限制了对系统文件的读写能力,但是多进程的浏览器有一个缺点,就是进程的内存占用相对更多,但是Chrome为了节省内存,会限制被启动的进程数,当进程数到达界限后,会将访问同一个网站的tab都放在一个进程里运行。
Chrome浏览器有哪些进程呢?
- 浏览器进程(browser Process),这个是浏览器的主进程,主要负责包括地址栏、前进后退按钮、处理网络访问、文件访问等。
- 渲染进程(Renderer Process),控制显示网站的选项卡内的所有内容。
- 插件进程(Plugin Process),控制网站使用的所有插件。
- GPU(GPU Process),与其他进程隔离处理GPU任务,由于GPU处理来自多个应用程序的请求并将它们绘制在同一表面上,因此将其分为不同的过程。
- 网络进程(NetWork Process),负责页面的网络资源加载,之前是放在浏览器进程中的一个线程运行,现在独立出来。
Chrome浏览器为什么是多进程而不是多线程?
多进程有四点好处。
- chromium项目创建初期,webkit不属于谷歌。他们对苹果的东西不信任,而且各种页面渲染时候的崩溃也很大。那时候webkit在chromium里的地位就是个小小第三方库。所以需要把渲染放到另外个进程防止崩溃了影响主进程。
- 同样的,webkit那时候很多内存泄露。多进程能很大程度避免。一个进程关了,所有内存就回收了。当时谷歌还写文章鄙视了下那些说多进程占用内存多的人。
- 多进程安全性更好。如果blink被发现什么提权漏洞,例如写一段js就能控制整个chromium进程做任何事情,显然多进程可以把损失限制在渲染线程。渲染线程拿不到主进程的各种私密信息,例如别的域名下的密码
- 另外有个点大家没说的地方就是,webkit内部很多全局变量。如果要做到一个页面一个线程,理论上很难搞。谷歌其实考虑过想搞一个单进程多线程模式,后来发现不好搞就放弃了。。这个模式在移动平台还是有优势的。以前的手机性能和内存还很差。多进程很消耗内存。chromium刚移植到安卓上时,还是30几版本。性能和稳定性远不如webkit单进程。那时候安卓版chromium就是单进程模式。
你了解浏览器缓存吗?
强缓存和协商缓存两个有什么区别?
强缓存是通过设置请求头的expires和cache-control,想服务器请求会先看缓存,如果强缓存没有,就走协商缓存,如果协商缓存有,就返回304,如果没有,服务器返回新的资源
强缓存需要向后台请求吗?
强缓存如果没有命中的话,就会走到协商缓存,如果命中的话,就直接从缓存返回资源。强缓存表示在缓存期间不需要请求
js、css这些静态资源存储在哪里?
答:这些静态资源存储在LocalStorage中。
如果想要做搜索引擎优化,那么css可以用LS(LocalStorage)的本地缓存优化吗?
答:不可以。div+css结构清晰,很容易被搜索引擎搜索到,适合SEO优化,降低网页大小,让网页体积变得更小。如果要做SEO,那么CSS必然不能进行LS(localstorage)的本地缓存优化。原因很简单:要进行SEO,必须直接输出完整HTML,因此必须让样式在头部以link标签加载。如果先输出HTML,后用js从本地缓存读取样式再插入,在样式重置过程中会出现严重的阻塞和闪烁问题。
LS使用?
PC上应用价值不大:
- 兼容性不太好,不支持LS的浏览器比例仍然很大
- 网络速度快,协商缓存响应快,LS读取+eval很多时候会比不上304
- 通常需要SEO,导致css不能缓存,仅缓存js使得整个缓存方案意义进一步减小
- 浏览器本地缓存足够可靠持久
- 跨页面间共享缓存即便有浪费也差别不大
移动端webapp值得一试:
- 兼容性好
- 网速慢,LS读取+eval大多数情况下快于304
- webapp不需要SEO,css也可以缓存,再通过js加载
- 浏览器缓存经常会被清理,LS被清理的几率低一些
你知道堆栈有什么区别吗?
- 申请方式
栈:由系统自动分配。例如在声明函数的一个局部变量int b,系统自动在栈中为b开辟空间。
堆:需要程序员自己申请,并指明大小,在C中用malloc函数;在C++中用new运算符。 - 申请后系统的响应
栈:只要栈的剩余空间大于所申请的空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:操作系统有一个记录空间内存地址的链表,当系统收到程序的申请时,会遍历链表,寻找第一个空间大于所申请空间的堆节点,然后将节点从内存空闲节点链表中删除,并将该节点的空间分配给程序。对于大多数操作系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的对节点的大小不一定正好等于申请的大小,系统会自动地将多余的那部分重新放入到链表中。 - 申请大小的限制
栈:在Windows下,栈是向低地址拓展的数据结构,是一块连续的内存的区域。站定地址和栈的大小是系统预先规定好的,如果申请的内存空间超过栈的剩余空间,将提示栈溢出。
堆:堆是向高地址拓展的内存结构,是不连续的内存区域。是系统用链表存储空闲内存地址的,不连续。 - 申请效率的比较
栈:由系统自动分配,速度较快。但程序员无法控制。
堆:由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来方便。
拓展:在Windows操作系统中,最好的方式使用VirtualAlloc分配内存。不是在堆,不是在栈,而是在内存空间中保留一块内存,虽然用起来不方便,但是速度快,也很灵活。 - 堆和栈的存储内容
栈:在函数调用时,第一个进栈的是主函数的中的下一条指令(函数调用的下一个可执行语句)的地址,然后是函数的各个参数。在C编译器中,参数是由右往左入栈的,然后是函数的局部变量。静态变量不入栈。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容由程序员安排。
数据结构方面的堆和栈与上边叙述不同。这里的堆是指优先队列的一种数据结构,第一个元素有最高的优先权;栈实际就是满足先进后出的性质的数学或数据结构。
总结:
(1)heap是堆,stack是栈;
(2)stack的空间由操作系统自动分配/释放,heap上的空间手动分配/释放;
(3)stack空间有限,heap是很大的自由内存区;
(4)C中的malloc函数分配的内存空间即在堆上,C++中对应的是new操作符。
程序在编译对变量和函数分配内存都在栈上进行,且内存运行过程中函数调用时参数的传递在栈上进行。
js的基础类型,引用类型
值类型(基本类型):字符串(String)、数字(Number)、布尔(Boolean)、空(Null)、未定义(Undefined)、Symbol。
引用数据类型(对象类型):对象(Object)、数组(Array)、函数(Function),还有两个特殊的对象:正则(RegExp)和日期(Date)。
基础类型存在堆还是栈?
栈的特点:大小固定、顺序存储、先进后出
堆的特点:大小动态变化、随机存
- 原始数据类型
undefined、Boolean、Number、String、BigInt、Symbol
储存位置:栈
传值方式:按值传递
原始数据类型复制时,系统会为新的变量在栈中创建一块新的内存区域存放复制的值 - 引用数据类型
null、Object、Function
储存位置:数据储存在堆中,栈中只会储存指向堆的一个指针地址(指针放到栈中,内容放到堆中)
传值方式:按引用传递
引用数据类型复制时,系统只会在栈中复制同一个指针地址,多个变量其实指向的是同一个指针地址
特别的,null代表一个空对象指针
原型链了解吗?
常用的数组方法、for和forEach的区别?
for和forEach的区别:
- for循环可以使用break跳出循环,但forEach不能。
- for循环可以控制循环起点(i初始化的数字决定循环的起点),forEach只能默认从索引0开始。
- for循环过程中支持修改索引(修改 i),但forEach做不到(底层控制index自增,我们无法左右它)。
怎么退出for循环?
JS跳出循环的三种方法(break, return, continue)
跳出循环的三种方法
那这3个可以在forEach中用吗?
forEach专门用来循环数组,可以直接取到元素,同时也可以取到index值,存在局限性,不能continue跳过或者break终止循环,没有返回值,不能return终止foreach循环 :运用抛出异常(try catch)可以终止foreach循环 。
在forEach中,不能使用continue 和break ,可以使用return 或return false 跳出循环,效果与for 中continue 一样。
问了数组的其他操作方式,重点问了reduce,参数;concat修改数组还是返回新数组;push有没有返回值,返回的是什么?数组去重,怎么判断不重复的值等
关于Promise
其他异步编程的方式?
回调函数、事件监听、发布订阅模式、promise、generator+yield、async+await
promise比setTimeout 的优势?
promise比setTimeout快,promise产生的是js引擎的微任务,setTimeout产生的是宏任务。在事件循环的过程中,作业队列(存储promise回调函数)比任务队列(存储setTimeout回调)优先级高
js为什么是单线程?
假设有两个线程同时操作一个DOM 元素,线程1 要求浏览器删除DOM,而线程2 却要求修改DOM 样式,这时浏览器就无法决定采用哪个线程的操作。 当然,我们可以为浏览器引入“锁”的机制来解决这些冲突,但这会大大提高复杂性,所以JavaScript 从诞生开始就选择了单线程执行。
关于css
css的盒模型?
什么是盒模型:盒模型又称框模型(Box Model),包含了元素内容(content)、内边距(padding)、边框(border)、外边距(margin)几个要素。如图:
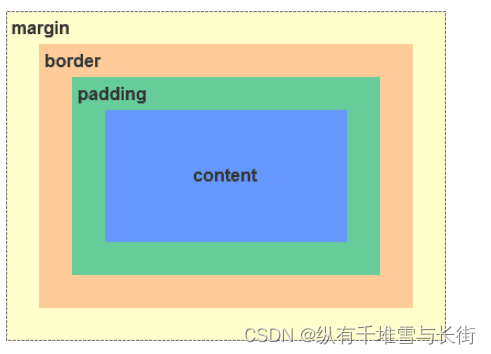
由于IE盒模型的怪异模式,IE模型和标准模型的内容计算方式不同。
IE模型和标准模型唯一的区别是内容计算方式的不同,如下图所示:
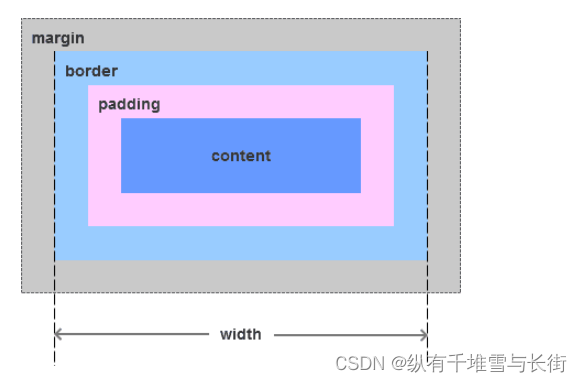
IE模型元素宽度width=content+padding,高度计算相同。

标准模型元素宽度width=content,高度计算相同。
详情见:CSS盒模型完整介绍
伪类和伪元素的区别?
伪类: 用来选择那些不能够被普通选择器选择的文档之外的元素,比如:hover
伪类用于当已有元素处于的某个状态时,为其添加对应的样式,这个状态是根据用户行为而动态变化的。
比如,当用户悬停在指定的元素时,我们可以通过:hover 来描述这个元素的状态。
虽然它和普通的 css 类相似,可以为已有的元素添加样式,但是它只有处于 dom树无法描述的状态下才能为元素添加样式,所以将其称为伪类
常见伪类::link,:visited,:hover,:active,:focus,:not(),:first-child,:last-child,:nth-child,:nth-last-child,:only-child,:target,:checked,:empty,:valid
伪元素:
伪元素用于创建一些不在文档树中的元素,并为其添加样式。比如说,我们可以通过:before 来在一个元素前增加一些文本,并为这些文本添加样式。虽然用户可以看到这些文本,但是这些文本实际上不在文档树中
伪元素前面是两个冒号,E::first-line 伪元素。会创造出不存在的新元素,由于 css 对单冒号的伪元素也支持,单双冒号都支持,但实际上现在css3 已经明确规定了伪类单冒号,伪元素双冒号的规则,用于区分它们
::before/:before在被选元素前插入内容::after/:after 在被元素后插入内容,其用法和特性与:before相似::placeholder 匹配占位符的文本,只有元素设置了placeholder 属性时,该伪元素才能生效
对于伪元素 :before和 :after 而言,属性 content 是必须设置的,它的值可以为字符串,也可以有其它形式,比如指向一张图片的 URL
- 伪类和伪元素都是用来表示文档树以外的"元素"。
- 伪类和伪元素分别用单冒号:和双冒号::来表示。
- 伪类和伪元素的区别,最关键的点在于如果没有伪元素(或伪类),是否需要添加元素才能达到目的,如果是则是伪元素,反之则是伪类。
css的position?
答:position 属性的五个值:
- static
- relative
- fixed
- absolute
- sticky
CSS Position
哪个定位脱离文档流?
position的值为absolute、fixed的元素脱离文档流,static、relative没有脱离文档流
absolute相对于谁定位?
absolute:定位是相对于离元素最近的设置了绝对或相对定位的父元素决定的,如果没有父元素设置绝对或相对定位,则元素相对于根元素即html元素定位。 设置了absolute的元素脱了了文档流,元素在没有设置宽度的情况下,宽度由元素里面的内容决定。
Vue
关于Webpack?
vue的computed和watcher的区别?
相同点:他们两者都是观察页面数据变化的。
不同点:computed只有当依赖的数据变化时才会计算, 当数据没有变化时, 它会读取缓存数据。 watch每次都需要执行函数。watch更适用于数据变化时的异步操作。
Vue中的watch与computed区别理解
vue的组件通信的方式?
(1)props、 $ emit
父组件通过props向子组件传值,子组件通过$ emit自定义事件向父组件传值
(2)$ emit、$ on
组件之间,不仅限父子组件
通过 var Event = new Vue(); 做为事件的总线,Event.$ emit(事件名,数据)、Event.$on(事件名,data=>{})
3)vuex
vuex实现单向数据流,【vueComponent】 通过 $store.disaptch(‘事件名’,data)触发【Actions】,然后通过 $store.commit() 触发【mutation】,最后更新【state】
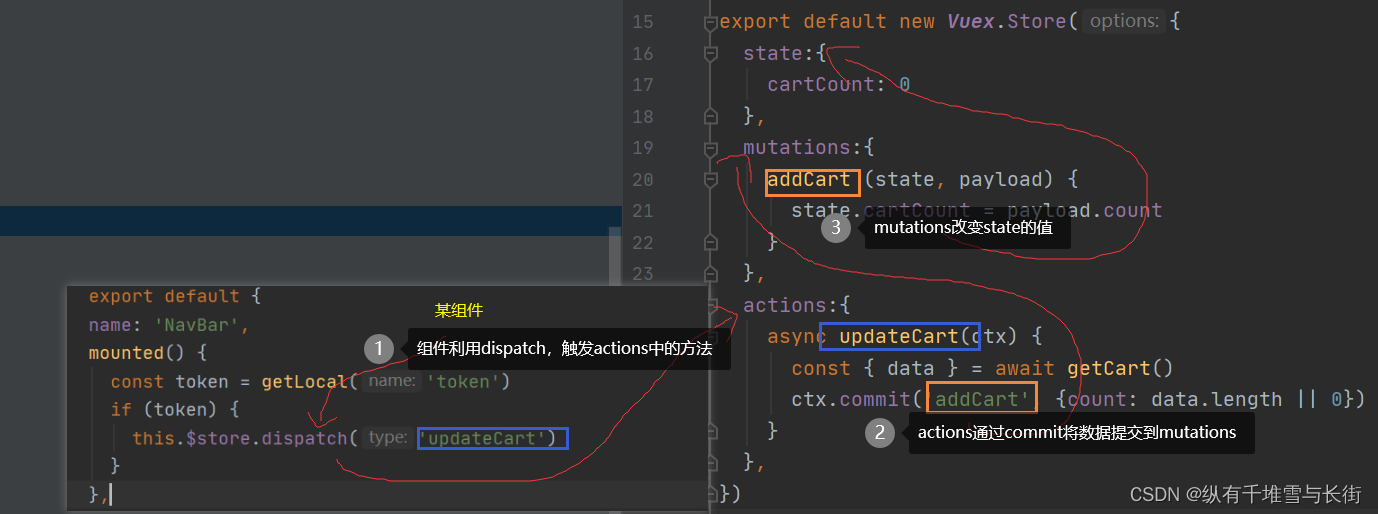
4) $ attrs、 $listeners
$ attrs 会包含父组件中没有被props的所有属性,通过v-bind=" $ attrs"
可以传入内部组件,$ listeners 会包含父组件中所有v-on的事件,通过v-on=" $ listeners"可以传入内部组件
(5)provide、inject
祖先组件通过provide提供一个变量,然后子孙组件通过inject注入变量并使用
(6) $ parent、$ children、ref
ref用在DOM上,引用指向的就是DOM元素,ref用在子组件上,引用指向的就是组件实例
//父组件
<template>
<div>
<child-two ref="child"></child-two>
</div>
<script>
mounted() {
//第一种方法,通过ref获取子组件的属性
let test = this.$refs.child;
console.log(test.title)
//第二种方法,通过$children获取子组件属性
console.log(this.$children[0].title)
},
// 父组件方法
say() {
console.log('我是父组件的方法!!')
}
</script>
//子组件
<div>
<span>ChildTwo</span>
</div>
<script>
data() {
return {
title: 'ChildTwo'
}
},
mounted() {
// 子组件调用父组件的方法
let test = this.$parent;
test.say();
}
}
</script>
举一个发布订阅模式最简单的例子?
vue的双向绑定原理
如果你用发布订阅模式,你会怎么写父子组件的通信?
答:一个中间者,发布者,接受者,子组件订阅信息,父组件发布(老师,父组件触发事件,子组件监听这个事件)
【补充】父组件做为被观察者,子组件作为观察者,子组件订阅父组件的消息,当父组件数据变化时,通知子组件更新
keep-alive有什么好处?
keep-alive是vue2.0加入的一个特性, 能缓存某个组件,或者某个路由。它的好处:





