目录
distantly Supervised Named Entity Recognition using Positive-Unlabeled Learning
前言
使用无标注数据和命名实体识别字典:执行该任务的自然做法是使用字典扫描查询文本,并将与字典条目列表匹配的术语视为实体。
对于标注中出现的错误,一个直观的解决方案是使用字典标记的数据进一步执行监督或半监督学习。
文章贡献
(1)新的PU learning算法
(2)AdaSampling 算法,丰富字典。
Risk定义——基础部分
Risk Minimization
风险最小化:给定损失函数l和分类器f的基础上,计算risk值为:
Y的标签空间是{0,1},f(x)表示一个分类器。
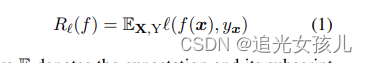
使用经验损失R^估计损失:
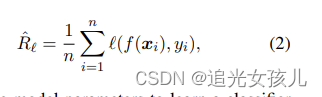
通过损失函数最小化,更新模型参数。即argmin(R^)
Unbiased Positive-Unlabeled learning
风险计算可以使用:
π_n表示negative,π_p表示positive的比率。
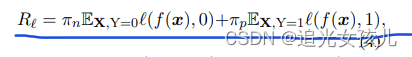
进一步,根据概率公式:P(x)=P(y=1)*P(x|y=1)+P(y=0)*P(x|y=0)
将上式,negative部分,用all data的分布表示出来。
公式转化过程:
R ℓ = π n E X , Y = 0 ℓ ( f ( x ) , 0 ) + π p E X , Y = 1 ℓ ( f ( x ) , 1 ) , R_{\ell}=\pi_{n} \mathbb{E}_{\mathbf{X}, Y=0} \ell(f(\boldsymbol{x}), 0)+\pi_{p} \mathbb{E}_{\mathbf{X}, \mathrm{Y}=1} \ell(f(\boldsymbol{x}), 1), Rℓ=πnEX,Y=0ℓ(f(x),0)+πpEX,Y=1ℓ(f(x),1),
Π p = P ( Y = 1 ) \Pi_{p}=P(Y=1) Πp=P(Y=1)
Π n = P ( Y = 0 ) \Pi_{n}=P(Y=0) Πn=P(Y=0)
π n E X , Y = 0 ℓ ( f ( x ) , 0 ) = E X ℓ ( f ( x ) , 0 ) − π p E X , Y = 1 ℓ ( f ( x ) , 0 ) \begin{aligned} \pi_{n} \mathbb{E}_{\mathbf{X}, Y=0} \ell(f(\boldsymbol{x}), 0) &=\mathbb{E}_{\mathbf{X}} \ell(f(\boldsymbol{x}), 0) \\ &-\pi_{p} \mathbb{E}_{\mathbf{X}, \mathrm{Y}=1} \ell(f(\boldsymbol{x}), 0) \end{aligned} πnEX,Y=0ℓ(f(x),0)=EXℓ(f(x),0)−πpEX,Y=1ℓ(f(x),0)
计算推导,在计算期望时,
R ℓ = π p E X , Y = 1 ℓ ( f ( x ) , 1 ) + E X ℓ ( f ( x ) , 0 ) − π p E X , Y = 1 ℓ ( f ( x ) , 0 ) \begin{aligned} R_{\ell}=\pi_{p} \mathbb{E}_{\mathbf{X}, \mathrm{Y}=1} \ell(f(\boldsymbol{x}), 1)+\mathbb{E}_{\mathbf{X}} \ell(f(\boldsymbol{x}), 0) \\ &-\pi_{p} \mathbb{E}_{\mathbf{X}, \mathrm{Y}=1} \ell(f(\boldsymbol{x}), 0) \end{aligned} Rℓ=πpEX,Y=1ℓ(f(x),1)+EXℓ(f(x),0)−πpEX,Y=1ℓ(f(x),0)
继续推导为:
R ^ ℓ = 1 n u ∑ i = 1 n u ℓ ( f ( x i u ) , 0 ) + π p n p ∑ i = 1 n p ( ℓ ( f ( x i p ) , 1 ) − ℓ ( f ( x i p ) , 0 ) ) \begin{aligned} \hat{R}_{\ell} &=\frac{1}{n_{u}} \sum_{i=1}^{n_{u}} \ell\left(f\left(\boldsymbol{x}_{i}^{u}\right), 0\right)+\\ \frac{\pi_{p}}{n_{p}} \sum_{i=1}^{n_{p}}\left(\ell\left(f\left(\boldsymbol{x}_{i}^{p}\right), 1\right)-\ell\left(f\left(\boldsymbol{x}_{i}^{p}\right), 0\right)\right) \end{aligned} R^ℓnpπpi=1∑np(ℓ(f(xip),1)−ℓ(f(xip),0))=nu1i=1∑nuℓ(f(xiu),0)+
PU learning的一致性
PU learning中,不仅要保证risk计算的无偏性还需要保证计算的一致性。
作者在这一块给出了一些证明公式。
最终的Risk计算公式为:

基于词典的伪标注
为了获得 D+,我们使用最大匹配算法 (Liu et al., 1994; Xue, 2003) 用 De 进行数据标注。这是一个贪婪的搜索例程(greedy search),遍历一个句子,试图从句子中的给定点开始,找到与字典中的条目匹配的最长字符串。该算法的一般过程总结在算法。 1. 在我们的实验中,我们直观地设置了上下文大小 k = 4

Build PU Learning Classifier
Word Representation: character-level representation(one-layer-convolution network)+word-level representation(Stanford’s glove word)+human designed features(allCaps、upperInitial、小写、mixedCaps、无信息-noinfo,类似于大小写特征)
之后将concat的特征,通过LSTM得到hidden state,特征表示为:
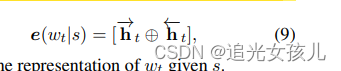
loss定义:
f(w|s)=sigmoid(w*e(w|s)+b)
risk计算:
l(f(w|s),y)=|y-f(w|s)|
训练过程中的经验损失定义为:
考虑到样本分布的不均衡性,作者在计算loss时,增加了weight项,将损失函数重新定义为:
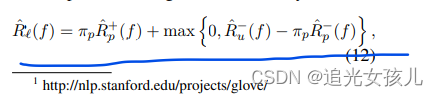
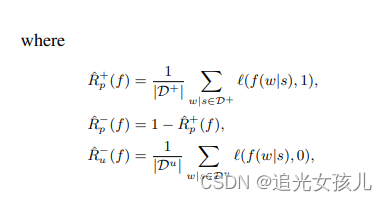

Label Inference.
每个token可能被多个classifier预测为不同的type,选择highest prediction probability作为最终的type。
Adapted PU Learning for NER
对于一个预测的实体,如果它出现了 k 次,并且它在未标记数据集中的所有出现都被预测为实体,我们将在下一次迭代中将其添加到实体字典中
实验部分
• 我们提出的使用简单字典的方法的一般性能;
• 未标记数据大小的影响;
• 字典质量的影响,例如大小、数据标注精度和召回率;
• 以及 πp 估计的影响





