一、Docker原理
1、Docker简介
我们知道进程是Linux操作系统执行任务的最小单元,一个时间同步服务是一个进程,一个Java服务是一个进程,一个Nginx服务是一个主进程+若干工作进程,总之,把一个系统比作一个办公室,进程就是一个个打工人:

正常情况下,一个进程是能感知到其他进程的存在的,正如一个打工人放眼望去,办公室里还坐着一群其他打工人。进程的唯一标识是进程ID,用数字1、2、3……表示,好比打工人的工牌号,大家都各不一样。
而容器技术首先要解决的就是进程的隔离,即一个进程在运行的时候看不到其他进程。如何让一个打工人在工作时看不到其他打工人呢?方法是给这个打工人带一个VR眼镜,于是他看到的不是一个真实的办公室,而是一个虚拟的办公室。在这个虚拟办公室中,只有他一个打工人,没有别人。在Linux系统中,对一个进程进行隔离,主要是通过Namespace和Cgroup两大机制实现的。一个被隔离的进程,操作系统也会正常分配进程ID,比如12345,但是隔离进程自己看到的ID总是1,好比打工人的工牌是12345,但他自己通过VR眼镜看到的工牌号却是1,感觉自己是1号员工似的:

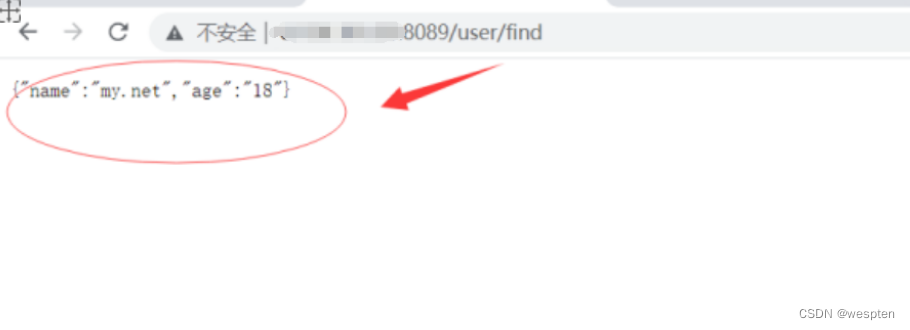
我们通过一个简单的Python程序就可以验证一下隔离进程的特点。我们编写一个简单的HTTP服务程序,针对URL为/、/ps、/ls分别返回自身进程ID、所有进程ID和磁盘根目录列表。如果我们正常启动某个Python程序,在浏览器中,可以看到进程ID为10297:

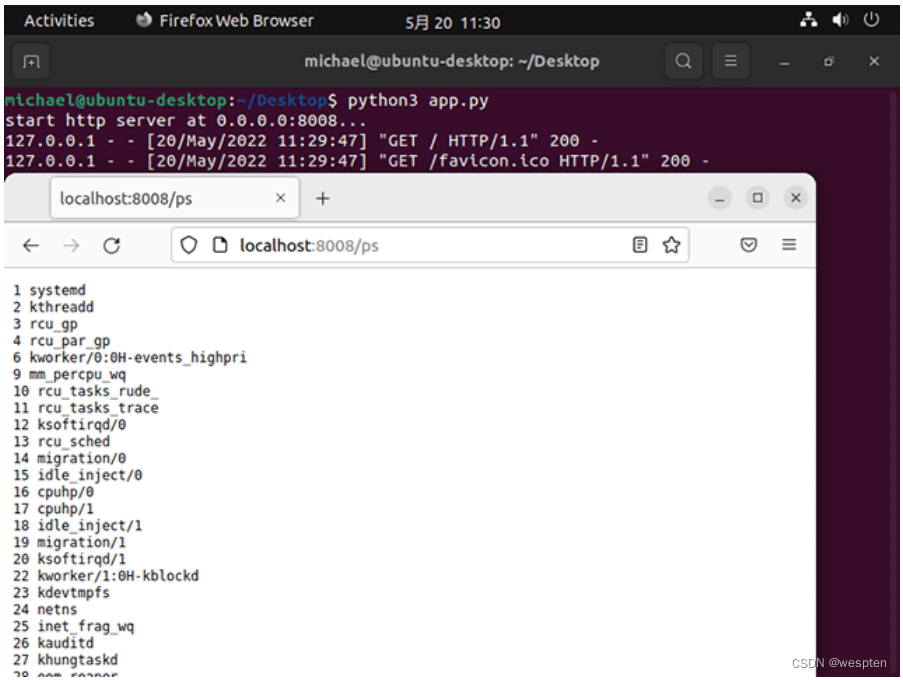
用/ps查看所有进程,可以看到1号进程是systemd,还有很多其他进程:
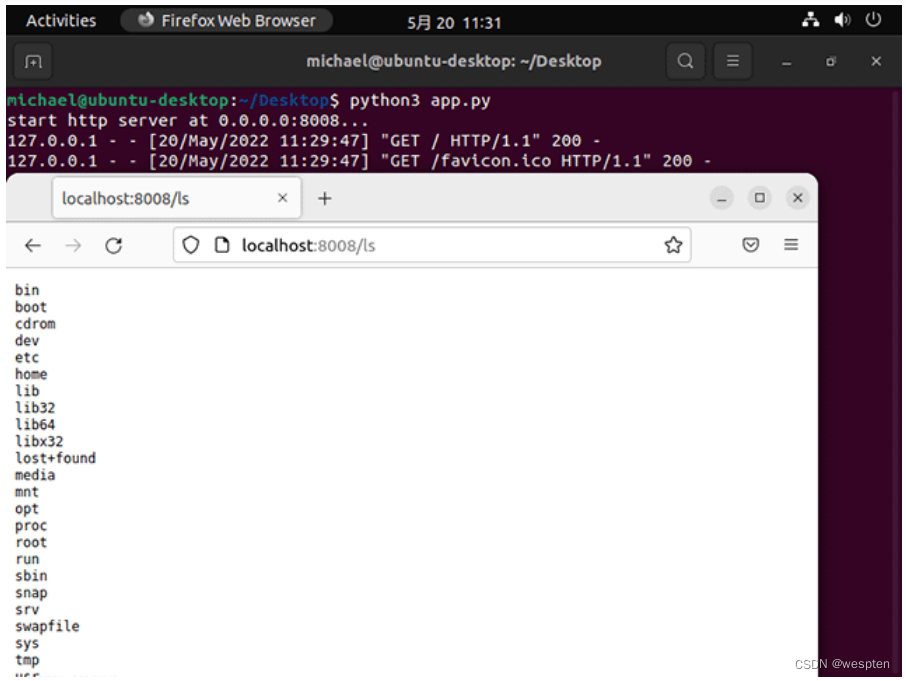
用/ls查看磁盘根目录,与当前系统根目录一致:
现在,我们制作一个Docker镜像,然后以Docker模式启动这个Python服务程序,再看看进程ID:
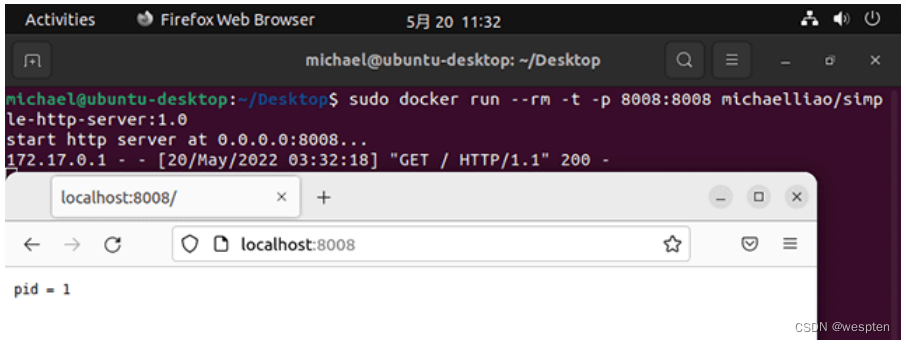
从进程自己的视角看,它看到的进程ID总是1,并且,用/ps看不到其他进程,只能看到自己:
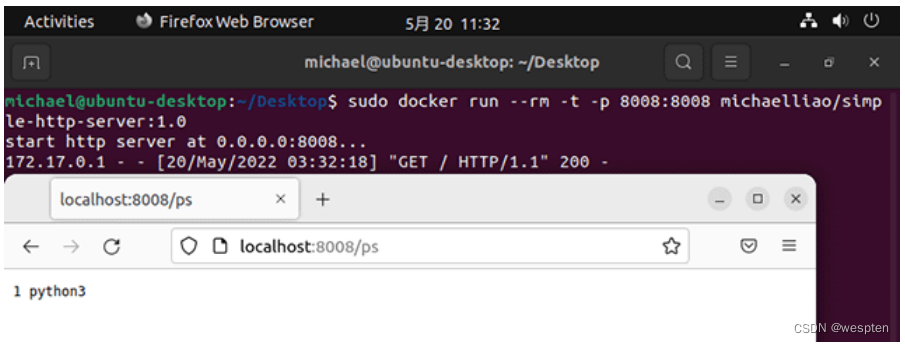
再用/ls看一下磁盘,看到的也不是系统的根目录,而是Docker给挂载的一个虚拟的文件系统:
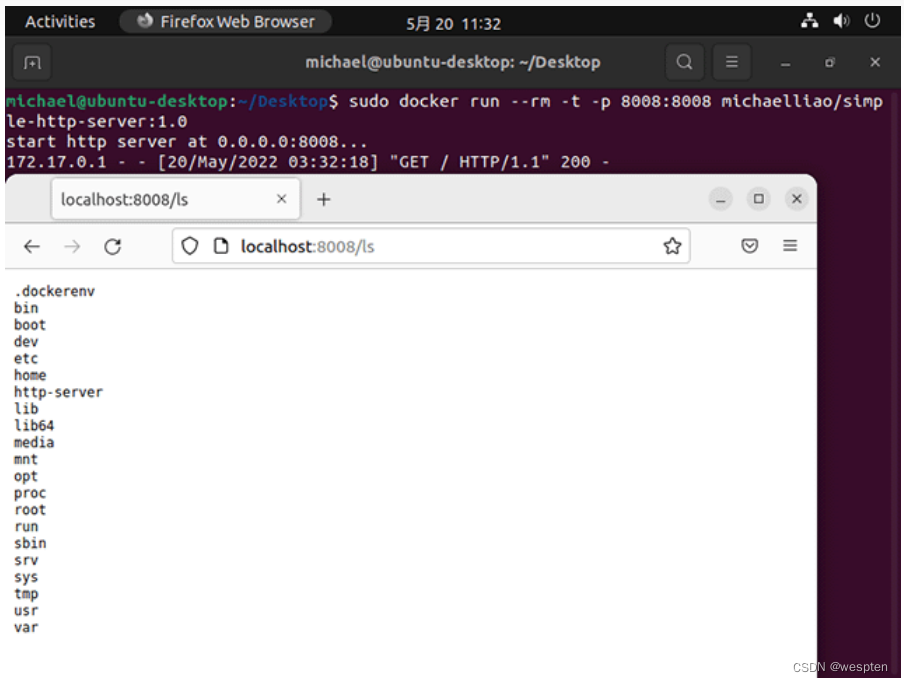
但其实从操作系统看,这个Docker进程和其他进程一样,也有一个唯一的进程ID为10475:
所以我们可以得出结论:
一个容器进程本质上是一个运行在沙盒中的隔离进程,由Linux系统本身负责隔离,Docker只是提供了一系列工具,帮助我们设置好隔离环境后,启动这个进程。
第一种隔离就是进程之间看不到彼此,这是由Linux的Cgroup机制实现的。进程隔离的结果就是以隔离方式启动的进程看到的自身进程ID总是1,且看不到系统的其他进程。
第二种隔离就是隔离系统真实的文件系统。
Docker利用Linux的mount机制,给每个隔离进程挂载了一个虚拟的文件系统,使得一个隔离进程只能访问这个虚拟的文件系统,无法看到系统真实的文件系统。至于这个虚拟的文件系统应该长什么样,这就是制作Docker镜像要考虑的问题。比如我们的Python程序要正常运行,需要一个python3解释器,需要把用到的第三方库如psutil引入进来,这些复杂的工作被简化为一个Dockerfile,再由Docker把这些运行时的依赖打包,就形成了Docker镜像。我们可以把一个Docker镜像看作一个zip包,每启动一个进程,Docker都会自动解压zip包,把它变成一个虚拟的文件系统。
第三种隔离就是网络协议栈的隔离,这个最不容易理解。
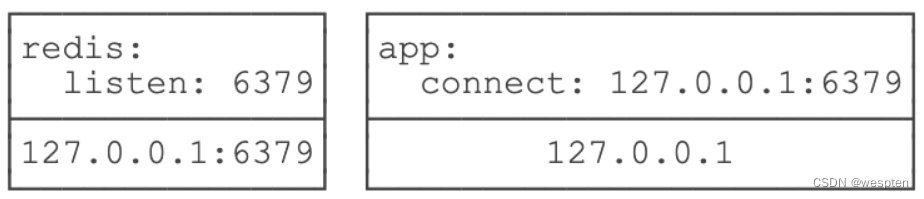
我们举个例子:在Docker中运行docker run redis:latest,然后在宿主机上写个程序连接127.0.0.1:6379,是无法连接到Redis的,因为Redis虽然监听127.0.0.1:6379这个端口,但Linux可以为进程隔离网络,Docker默认启动的Redis进程拥有自己的网络名字空间,与宿主机不同:
要让宿主机访问到Redis,可以用-p 6379:6379把Redis进程的端口号映射到宿主机,从而在宿主机上访问Redis:
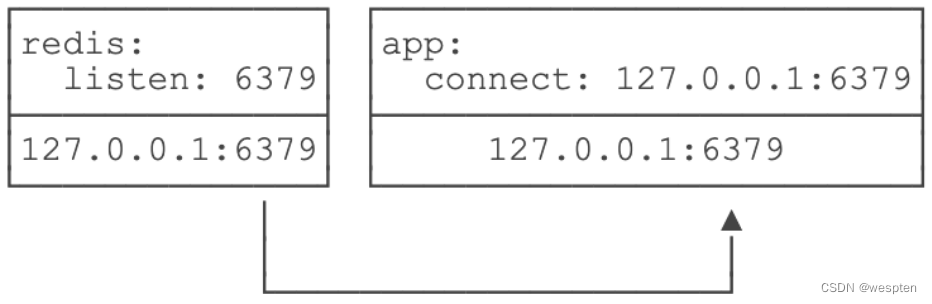
因此,在Linux的网络名字空间隔离下,Redis进程和宿主机进程看到的IP地址127.0.0.1表面上一样,但实际上是不同的网络接口。
我们再看一个更复杂的例子。如果我们要运行ZooKeeper和Kafka,先启动ZooKeeper:
docker run -p 2181:2181 zookeeper:latest再启动Kafka,发现Kafka是无法连接ZooKeeper的,原因是,Kafka试图连接的127.0.0.1:2181在它自己的网络接口上并不存在:
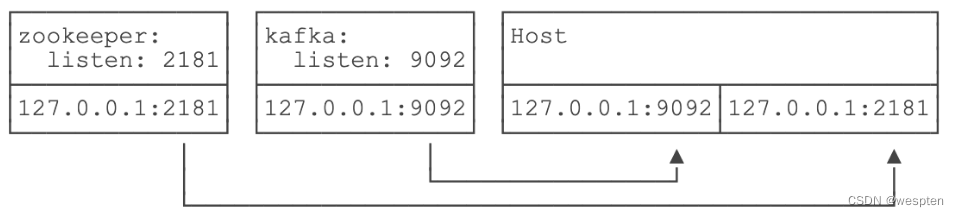
必须连接到ZooKeeper的IP:2181或者宿主机的IP:2181。直接指定IP并不是一个好的方式,我们应该利用Docker Compose,把ZooKeeper和Kafka运行在同一个网络名字空间里,并通过zookeeper:2181来访问ZooKeeper端口,让Docker自动把zookeeper名字解析为动态分配的IP地址。
docker-compose.yml参考配置如下:
---
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.0.1
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.0.1
container_name: broker
ports:
# To learn about configuring Kafka for access across networks see
# https://www.confluent.io/blog/kafka-client-cannot-connect-to-broker-on-aws-on-docker-etc/
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_broKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_Security_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092,PLAINTEXT_INTERNAL://broker:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1运行此命令以正确顺序启动所有服务:
docker-compose up -d运行此命令以创建一个新 topic, 我们将在其中写入和读取一些测试消息:
docker exec broker \
kafka-topics --bootstrap-server broker:9092 \
--create \
--topic quickstart您可以使用 kafka-console-producer 命令行工具将消息写入topic,运行此命令等待您的输入:
docker exec --interactive --tty broker \
kafka-console-producer --bootstrap-server broker:9092 \
--topic quickstart输入几行文本,每一行都是一条新消息:
this is my first kafka message
Hello World!
this is my third kafka message. I’m on a roll :-D完成后,按 Ctrl-D 返回命令提示符。
现在我们已经向主题写入了消息,我们将读回这些消息。运行此命令以启动 kafka-console-consumer,--from-beginning参数意味着将从主题的开头读取消息:
docker exec --interactive --tty broker \
kafka-console-consumer --bootstrap-server broker:9092 \
--topic quickstart \
--from-beginning和以前一样,这对于在命令行上进行试验很有用,但实际上,您将在应用程序代码中使用 Consumer API,或使用 Kafka Connect 从 Kafka 读取数据以推送到其他系统。
这是我的第一个卡夫卡消息
你好世界!
这是我的第三条卡夫卡信息。我很高兴:-D让上一步中的 kafka-console-consumer 命令继续运行。如果您已经关闭它,只需重新运行它。现在打开一个新的终端窗口并再次运行 kafka-console-producer:
docker exec --interactive --tty broker \
kafka-console-producer --bootstrap-server broker:9092 \
--topic quickstart输入更多消息并注意它们是如何几乎立即在消费者终端中显示的,按 Ctrl-D 退出生产者,按 Ctrl-C 停止消费者。
完成后,您可以关闭 Kafka 代理。请注意,这样做会破坏您编写的主题中的所有消息。从包含docker-compose.yml先前创建的文件的目录中,运行此命令以按正确顺序停止所有服务:
docker-compose down2、Docker与虚拟机有何区别
很多人将Docker理解为Docker实现了类似于虚拟化的技术,容器被称为轻量级的虚拟化技术,实际上是不准确的。Docker 不是轻量级的虚拟机,确切地说,容器是一种对进程进行隔离的运行环境。
Docker其实是一个Client-Server结构的系统,Docker守护进程运行在主机上, 然后通过Socket连接从客户端访问Docker守护进程。
Docker守护进程从客户端接受命令,并按照命令管理运行在主机上的容器。一个Docker 容器,是一个运行时环境,可以简单理解为进程运行的集装箱。
Docker和虚拟机主要的区别有一下几点:
1. 虚拟化技术依赖的是物理cpu和内存,是硬件级别的,需要的是Guest OS;而Docker是构建在操作系统层面的,利用的是宿主机操作系统的内核,所以Docker同样可以运行在虚拟机上。
2. 虚拟机中的系统就是我们常说的操作系统镜像,比较复杂;而Docker比较轻量级,有着比虚拟机更少的抽象层,我们可以使用Docker部署一个独立的Redis,就像类似于在虚拟机当中安装一个Redis应用,但是我们用Docker部署的应用是完全隔离的。
3. 在传统的虚拟化技术是通过快照来保存的;而Docker引用了类似于源码的管理机制,将容器的快照历史版本一一记录下来,切换成本之低。
4. 传统的虚拟化技术在构建系统的时候非常复杂;而Docker可以通过一个简单的Dockerfile文件来构建整个容器,更重要的是Dockerfile可以手动编写,这样应用开发人员可以通过发布Dockerfile来定义应用的环境和依赖,这样对于持续交付非常有利。

VM(VMware)在宿主机器、宿主机器操作系统的基础上创建虚拟层、虚拟化的操作系统、虚拟化的仓库,然后再安装应用;Container(Docker容器),在宿主机器、宿主机器操作系统上创建Docker引擎,在引擎的基础上再安装应用。
所以说,新建一个容器的时候,docker不需要像虚拟机一样重新加载一个操作系统,避免引导。Docker是利用宿主机的操作系统,省略了这个复杂的过程,妙极!
虚拟机是加载Guest OS ,这是分钟级别的。
与传统VM特性对比:
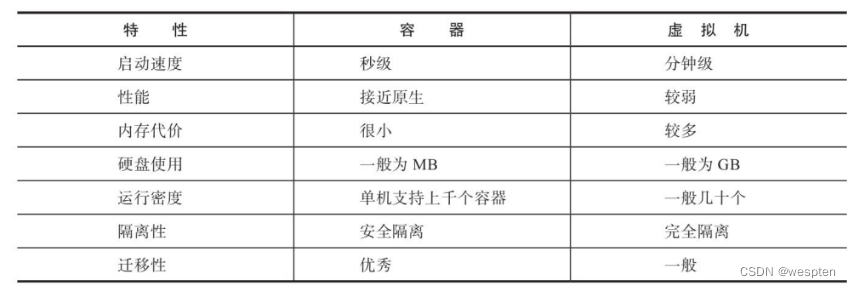
作为一种轻量级的虚拟化方式,Docker在运行应用上跟传统的虚拟机方式相比具有显著优势:
- Docker 容器很快,启动和停止可以在秒级实现,这相比传统的虚拟机方式要快得多。
- Docker 容器对系统资源需求很少,一台主机上可以同时运行数千个Docker容器。
- Docker 通过类似Git的操作来方便用户获取、分发和更新应用镜像,指令简明,学习成本较低。
- Docker 通过Dockerfile配置文件来支持灵活的自动化创建和部署机制,提高工作效率。
- Docker 容器除了运行其中的应用之外,基本不消耗额外的系统资源,保证应用性能的同时,尽量减小系统开销。
- Docker 利用Linux系统上的多种防护机制实现了严格可靠的隔离。从1.3版本开始,Docker引入了安全选项和镜像签名机制,极大地提高了使用Docker的安全性。
3、Docker核心概念
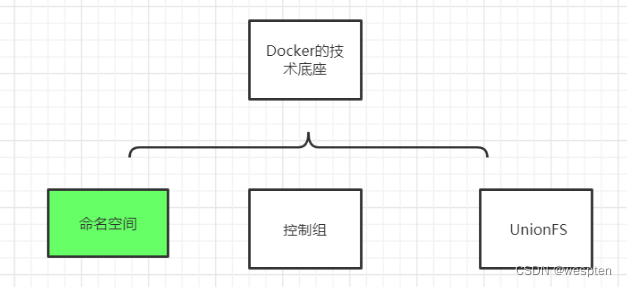
Linux 命名空间、控制组和 UnionFS 三大技术支撑了目前 Docker 的实现,也是 Docker 能够出现的最重要原因。
① Docker namespace
Linux 内核2.4.19中开始陆续引用了namespace概念。目的是将某个特定的全局系统资源(global system resource)通过抽象方法使得namespace中的进程看起来拥有它们自己的隔离的全局系统资源实例,命名空间是Linux内核强大的特性。
命名空间容器隔离的基础,保证A容器看不到B容器。每个容器都有自己的命名空间,运行在其中的应用都是在独立操作系统中运行一样。命名空间保证了容器之间彼此互不影响。
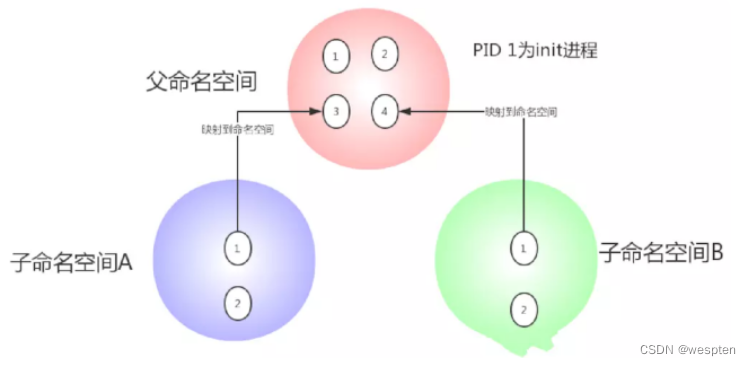
6个命名空间:User,Mnt,Network,UTS,IPC,Pid。
② Docker CGroups
Cgroups 是 Control Group 的缩写,控制组,cgroups容器资源统计和隔离。Docker容器使用Linux namespace来隔离其运行环境,使得容器中的进程看起来就像在一个独立的环境中运行。但是光有运行环境隔离还不够,因为这些进程还是可以不受限制地使用系统资源,比如网络、磁盘、cpu以及内存等。
Cgroups是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu, Memory, IO等)的机制。最初由Google的工程师提出,后来被整合进Linux内核。Cgroups也是LXC为实现虚拟化所使用的资源管理手段,可以说没有Cgroups就没有LXC,也就没有Docker。
Cgroups最初的目标是为资源管理提供的一个统一的框架,既整合现有的cpuset等子系统,也为未来开发新的子系统提供接口。现在的Cgroups适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization)。
Cgroups提供以下功能:
a)限制进程组可以使用的资源数量(Resource limiting )。比如:Memory子系统可以为进程组设定一个Memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)。
b)进程组的优先级控制(Prioritization)。比如:可以使用cpu子系统为某个进程组分配特定cpushare。
c)进程组隔离(Isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
d)记录进程组使用的资源数量(Accounting)。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间
e)进程组控制(Control)。比如:使用freezer子系统可以将进程组挂起和恢复。
主要用到的cgroups子系统:cpu,blkio,device,freezer,memory。
实际上 Docker 是使用了很多 Linux 的隔离功能,让容器看起来像一个轻量级虚拟机在独立运行,容器的本质是被限制了的 Namespaces,cgroup,具有逻辑上独立文件系统,网络的一个进程。
③ Docker UnionFS
没有操作系统,怎么运行程序?
可以在Docker中创建一个centos的镜像文件,这样就能将centos系统集成到Docker中,运行的应用就都是centos的应用。
Image 是 Docker 部署的基本单位,一个 Image 包含了我们的程序文件,以及这个程序依赖的资源的环境。Docker Image 对外是以一个文件的形式展示的(更准确的说是一个 mount 点)。
UnionFS顾名思义,可以把文件系统上多个目录(文件系统)内容联合挂载到同一个目录(挂载点)下,而目录的物理位置是分开的。
要理解unionFS,我们首先需要先了解bootfs和rootfs1.boot file system (bootfs) 包含操作系统boot loader和kernel。用户不会修改这个文件系统,一旦启动成功后,整个Linux内核加载进内存,之后bootfs会被卸载掉,从而释放内存。同样的内核版本不同Linux发行版,其bootfs都是一直的2.root file system (rootfs) 包含典型的目录结构(/dev/,/proc,/bin,/etc,/lib,/usr,/tmp)Linux系统在启动时,rootfs首先会被挂载为只读模式,然后在启动完成后被修改为读写模式,随后它们就可以被修改了。
假设Dockerfile内容如下:
FROM ubuntu:14.04
ADD run.sh /
VOLUME /data
CMD ["./run.sh"]
联合文件系统对应的层次结构如下图所示:
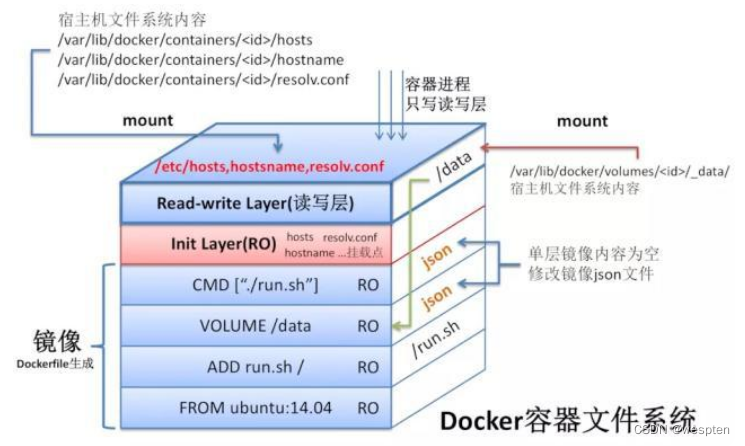
图中的顶上两层,是Docker为Docker容器新建的内容,而这两层属于容器范畴。这两层分别为Docker容器的初始层(init Layer)与可读写层(Read-write Layer)。
初始层:大多是初始化容器环境时,与容器相关的环境信息,如容器主机名,主机host信息以及域名服务文件等。
读写层: Docker容器内的进程只对可读可写层拥有写权限,其它层进程而言都是只读的(Read-Only)。关于VOLUME以及容器的host、hostname、resolv.conf文件都会挂载到这里。
1. FROM ubuntu:14.04 设置基础镜像,此时会使用Ubuntu:14.04作为基础镜像;
2. ADD run.sh / 将Dockerfile所在目录下的run.sh加至镜像的根目录,此时新一层的镜像只有一项内容,即根目录下的run.sh;
3. VOLUME /data 设置镜像存储,此VOLUME在容器内部的路径为/data。此时并未在新一层的镜像中添加任何文件,但是更新了镜像的json文件,以便通过此镜像启动容器时获取这方面的信息;
4. CMD [“./run.sh”] 设置镜像的默认执行入口,此命令同样不会在新建镜像中添加任何文件,仅仅在上一层镜像json文件的基础上更新新的镜像的json文件;
4、Namespaces命名空间
在Linux系统中,Namespace是在内核级别以一种抽象的形式来封装系统资源,通过将系统资源放在不同的Namespace中,来实现资源隔离的目的。不同的Namespace程序,可以享有一份独立的系统资源。
命名空间(namespaces)是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。在日常使用 Linux 或者 macOS 时,我们并没有运行多个完全分离的服务器的需要,但是如果我们在服务器上启动了多个服务,这些服务其实会相互影响的,每一个服务都能看到其他服务的进程,也可以访问宿主机器上的任意文件,这是很多时候我们都不愿意看到的,我们更希望运行在同一台机器上的不同服务能做到完全隔离,就像运行在多台不同的机器上一样。
Linux 的命名空间机制提供了以下七种不同的命名空间,包括 :
- CLONE_NEWCGROUP
- CLONE_NEWIPC
- CLONE_NEWNET
- CLONE_NEWNS
- CLONE_NEWPID
- CLONE_NEWUSER
- CLONE_NEWUTS
通过这七个选项, 我们能在创建新的进程时, 设置新进程应该在哪些资源上与宿主机器进行隔离。
具体如下:
| Namespace | Flag | Page | Isolates |
|---|---|---|---|
| Cgroup | CLONE_NEWCGROUP | cgroup_namespaces | Cgroup root directory |
| IPC | CLONE_NEWIPC | ipc_namespaces | System V IPC,POSIX message queues 隔离进程间通信 |
| Network | CLONE_NEWNET | network_namespaces | Network devices,stacks, ports, etc. 隔离网络资源 |
| Mount | CLONE_NEWNS | mount_namespaces | Mount points 隔离文件系统挂载点 |
| PID | CLONE_NEWPID | pid_namespaces | Process IDs 隔离进程的ID |
| Time | CLONE_NEWTIME | time_namespaces | Boot and monotonic clocks |
| User | CLONE_NEWUSER | user_namespaces | User and group IDs 隔离用户和用户组的ID |
| UTS | CLONE_NEWUTS | uts_namespaces | Hostname and NIS domain name 隔离主机名和域名信息 |
这里提出一个问题,在宿主机上启动两个容器,在这两个容器内都各有一个 PID=1的进程,众所周知,Linux 里 PID 是唯一的,既然 Docker 不是跑在宿主机上的两个虚拟机,那么它是如何实现在宿主机上运行两个相同 PID 的进程呢?
这里就用到了 Linux Namespaces,它其实是 Linux 创建新进程时的一个可选参数,在 Linux 系统中创建进程的系统调用是 clone()方法。
int clone(int (*fn) (void *),void *child stack,
int flags, void *arg, . . .
/* pid_ t *ptid, void *newtls, pid_ t *ctid */ ) ;
通过调用这个方法,这个进程会获得一个独立的进程空间,它的 pid 是1,并且看不到宿主机上的其他进程,这也就是在容器内执行 PS 命令的结果。
不仅仅是 PID,当你启动启动容器之后,Docker 会为这个容器创建一系列其他 namespaces。
这些 namespaces 提供了不同层面的隔离。容器的运行受到各个层面 namespace 的限制。
Docker Engine 使用了以下 Linux 的隔离技术:
The pid namespace: 管理 PID 命名空间 (PID: Process ID);
The net namespace: 管理网络命名空间 (NET: Networking);
The ipc namespace: 管理进程间通信命名空间 (IPC: InterProcess Communication);
The mnt namespace: 管理文件系统挂载点命名空间 (MNT: Mount);
The uts namespace: Unix 时间系统隔离 (UTS: Unix Timesharing System);
通过这些技术,运行时的容器得以看到一个和宿主机上其他容器隔离的环境。
1)进程隔离
进程是 Linux 以及现在操作系统中非常重要的概念,它表示一个正在执行的程序,也是在现代分时系统中的一个任务单元。
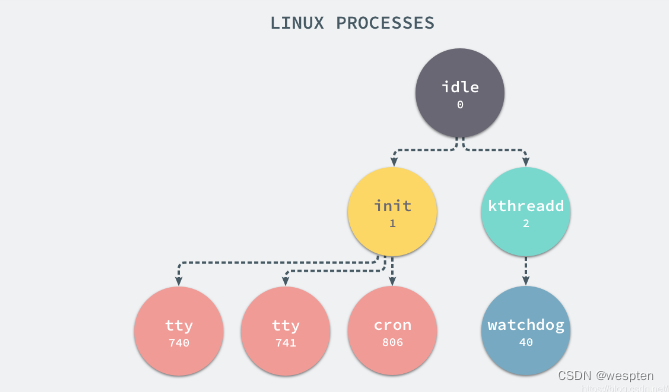
在每一个 *nix 的操作系统上,我们都能够通过 ps 命令打印出当前操作系统中正在执行的进程,比如在 Ubuntu 上,使用该命令就能得到以下的结果:
|$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Apr08 ? 00:00:09 /sbin/init
root 2 0 0 Apr08 ? 00:00:00 [kthreadd]
root 3 2 0 Apr08 ? 00:00:05 [ksoftirqd/0]
root 5 2 0 Apr08 ? 00:00:00 [kworker/0:0H]
root 7 2 0 Apr08 ? 00:07:10 [rcu_sched]
root 39 2 0 Apr08 ? 00:00:00 [migration/0]
root 40 2 0 Apr08 ? 00:01:54 [watchdog/0]
当前机器上有很多的进程正在执行,在上述进程中有两个非常特殊,一个是 pid 为 1 的 /sbin/init 进程,另一个是 pid 为 2 的 kthreadd 进程,这两个进程都是被 Linux 中的上帝进程 idle 创建出来的,其中前者负责执行内核的一部分初始化工作和系统配置,也会创建一些类似 getty 的注册进程,而后者负责管理和调度其他的内核进程。
如果我们在当前的 Linux 操作系统下运行一个新的 Docker 容器,并通过 exec 进入其内部的 bash 并打印其中的全部进程,我们会得到以下的结果:
UID PID PPID C STIME TTY TIME CMD
root 29407 1 0 Nov16 ? 00:08:38 /usr/bin/dockerd --raw-logs
root 1554 29407 0 Nov19 ? 00:03:28 docker-containerd -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --metrics-interval=0 --start-timeout 2m --state-dir /var/run/docker/libcontainerd/containerd --shim docker-containerd-shim --runtime docker-runc
root 5006 1554 0 08:38 ? 00:00:00 docker-containerd-shim b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79 /var/run/docker/libcontainerd/b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79 docker-runc在新的容器内部执行 ps 命令打印出了非常干净的进程列表,只有包含当前 ps -ef 在内的三个进程,在宿主机器上的几十个进程都已经消失不见了。
当前的 Docker 容器成功将容器内的进程与宿主机器中的进程隔离,如果我们在宿主机器上打印当前的全部进程时,会得到下面三条与 Docker 相关的结果。
在当前的宿主机器上,可能就存在由上述的不同进程构成的进程树:
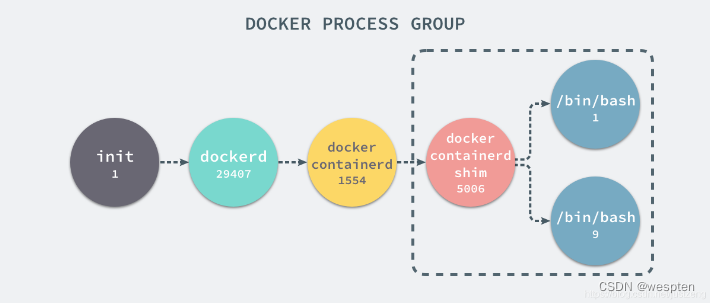
这就是在使用 clone(2) 创建新进程时传入 CLONE_NEWPID 实现的,也就是使用 Linux 的命名空间实现进程的隔离,Docker 容器内部的任意进程都对宿主机器的进程一无所知。
containerRouter.postContaineRSStart
└── daemon.ContainerStart
└── daemon.createSpec
└── setNamespaces
└── setNamespace
Docker 的容器就是使用上述技术实现与宿主机器的进程隔离,当我们每次运行 docker run 或者 docker start 时,都会在下面的方法中创建一个用于设置进程间隔离的 Spec:
func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) {
s := oci.DefaultSpec()
// ...
if err := setNamespaces(daemon, &s, c); err != nil {
return nil, fmt.Errorf("linux spec namespaces: %v", err)
}
return &s, nil
}
在 setNamespaces 方法中不仅会设置进程相关的命名空间,还会设置与用户、网络、IPC 以及 UTS 相关的命名空间:
func setNamespaces(daemon *Daemon, s *specs.Spec, c *container.Container) error {
// user
// network
// ipc
// uts
// pid
if c.HostConfig.PidMode.IsContainer() {
ns := specs.LinuxNamespace{Type: "pid"}
pc, err := daemon.getPidContainer(c)
if err != nil {
return err
}
ns.Path = fmt.Sprintf("/proc/%d/ns/pid", pc.State.GetPID())
setNamespace(s, ns)
} else if c.HostConfig.PidMode.IsHost() {
oci.RemoveNamespace(s, specs.LinuxNamespaceType("pid"))
} else {
ns := specs.LinuxNamespace{Type: "pid"}
setNamespace(s, ns)
}
return nil
}
所有命名空间相关的设置 Spec 最后都会作为 Create 函数的入参在创建新的容器时进行设置:
daemon.containerd.Create(context.Background(), container.ID, spec, createOptions)所有与命名空间的相关的设置都是在上述的两个函数中完成的,Docker 通过命名空间成功完成了与宿主机进程和网络的隔。
2)网络隔离
如果 Docker 的容器通过 Linux 的命名空间完成了与宿主机进程的网络隔离,但是却有没有办法通过宿主机的网络与整个互联网相连,就会产生很多限制。
所以 Docker 虽然可以通过命名空间创建一个隔离的网络环境,但是 Docker 中的服务仍然需要与外界相连才能发挥作用。
每一个使用 docker run 启动的容器其实都具有单独的网络命名空间,Docker 为我们提供了四种不同的网络模式,Host、Container、None 和 Bridge 模式。
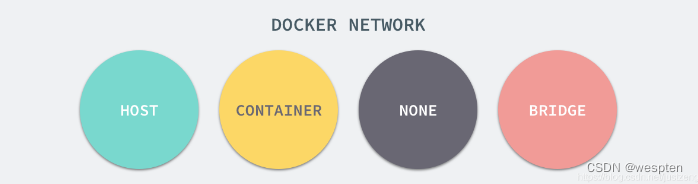
在这一部分,我们将介绍 Docker 默认的网络设置模式:网桥模式。
在这种模式下,除了分配隔离的网络命名空间之外,Docker 还会为所有的容器设置 IP 地址。
当 Docker 服务器在主机上启动之后会创建新的虚拟网桥 docker0,随后在该主机上启动的全部服务在默认情况下都与该网桥相连。
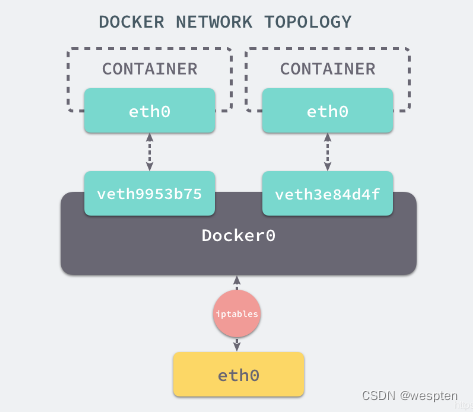
在默认情况下,每一个容器在创建时都会创建一对虚拟网卡,两个虚拟网卡组成了数据的通道,其中一个会放在创建的容器中,会加入到名为 docker0 网桥中。
我们可以使用如下的命令来查看当前网桥的接口:
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242a6654980 no veth3e84d4f
veth9953b75docker0会为每一个容器分配一个新的 IP 地址并将 docker0 的 IP 地址设置为默认的网关。
网桥 docker0 通过 iptables 中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。
$ iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
Chain DOCKER (2 references)
target prot opt source destination
RETURN all -- anywhere anywhere
我们在当前的机器上使用 docker run -d -p 6379:6379 redis 命令启动了一个新的 Redis 容器,在这之后我们再查看当前 iptables 的 NAT 配置就会看到在 DOCKER 的链中出现了一条新的规则:
DNAT tcp -- anywhere anywhere tcp dpt:6379 to:192.168.0.4:6379上述规则会将从任意源发送到当前机器 6379 端口的 TCP 包转发到 192.168.0.4:6379 所在的地址上。
这个地址其实也是 Docker 为 Redis 服务分配的 IP 地址,如果我们在当前机器上直接 ping 这个 IP 地址就会发现它是可以访问到的:
$ ping 192.168.0.4
PING 192.168.0.4 (192.168.0.4) 56(84) bytes of data.
64 bytes from 192.168.0.4: icmp_seq=1 ttl=64 time=0.069 ms
64 bytes from 192.168.0.4: icmp_seq=2 ttl=64 time=0.043 ms
^C
--- 192.168.0.4 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.043/0.056/0.069/0.013 ms从上述的一系列现象,我们就可以推测出 Docker 是如何将容器的内部的端口暴露出来并对数据包进行转发的了;当有 Docker 的容器需要将服务暴露给宿主机器,就会为容器分配一个 IP 地址,同时向 iptables 中追加一条新的规则。
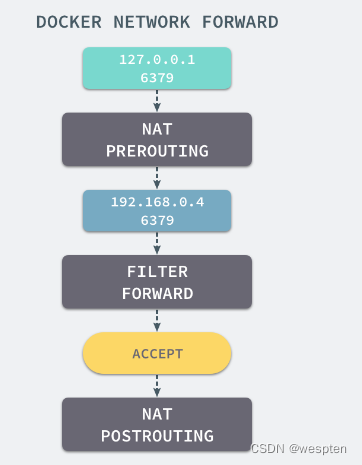
当我们使用 redis-cli 在宿主机器的命令行中访问 127.0.0.1:6379 的地址时,经过 iptables 的 NAT PREROUTING 将 ip 地址定向到了 192.168.0.4,重定向过的数据包就可以通过 iptables 中的 FILTER 配置,最终在 NAT POSTROUTING 阶段将 ip 地址伪装成 127.0.0.1,到这里虽然从外面看起来我们请求的是 127.0.0.1:6379,但是实际上请求的已经是 Docker 容器暴露出的端口了。
$ redis-cli -h 127.0.0.1 -p 6379 ping
PONGDocker 通过 Linux 的命名空间实现了网络的隔离,又通过 iptables 进行数据包转发,让 Docker 容器能够优雅地为宿主机器或者其他容器提供服务。
3)Libnetwork
整个网络部分的功能都是通过 Docker 拆分出来的 libnetwork 实现的,它提供了一个连接不同容器的实现,同时也能够为应用给出一个能够提供一致的编程接口和网络层抽象的容器网络模型。
The goal of libnetwork is to deliver a robust Container Network Model that provides a consistent programming interface and the required network abstractions for applications.
libnetwork 中最重要的概念,容器网络模型由以下的几个主要组件组成,分别是 SandBox、Endpoint 和 Network:
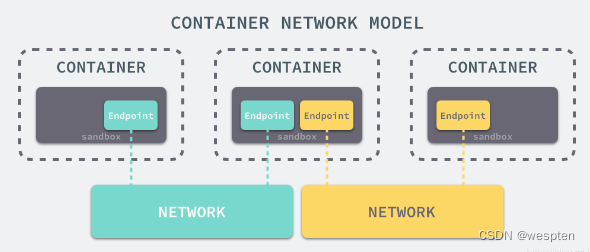
在容器网络模型中,每一个容器内部都包含一个 SandBox,其中存储着当前容器的网络栈配置,包括容器的接口、路由表和 DNS 设置,Linux 使用网络命名空间实现这个 SandBox,每一个 SandBox 中都可能会有一个或多个 Endpoint,在 Linux 上就是一个虚拟的网卡 veth,SandBox 通过 Endpoint 加入到对应的网络中,这里的网络可能就是我们在上面提到的 Linux 网桥或者 VLAN。
4)挂载点
在这里不得不简单介绍一下 chroot(change root),在 Linux 系统中,系统默认的目录就都是以 / 也就是根目录开头的,chroot 的使用能够改变当前的系统根目录结构,通过改变当前系统的根目录,我们能够限制用户的权利,在新的根目录下并不能够访问旧系统根目录的结构个文件,也就建立了一个与原系统完全隔离的目录结构。
虽然我们已经通过 Linux 的命名空间解决了进程和网络隔离的问题,在 Docker 进程中我们已经没有办法访问宿主机器上的其他进程并且限制了网络的访问,但是 Docker 容器中的进程仍然能够访问或者修改宿主机器上的其他目录,这是我们不希望看到的。
在新的进程中创建隔离的挂载点命名空间需要在 clone 函数中传入 CLONE_NEWNS,这样子进程就能得到父进程挂载点的拷贝,如果不传入这个参数子进程对文件系统的读写都会同步回父进程以及整个主机的文件系统。
如果一个容器需要启动,那么它一定需要提供一个根文件系统(rootfs),容器需要使用这个文件系统来创建一个新的进程,所有二进制的执行都必须在这个根文件系统中。
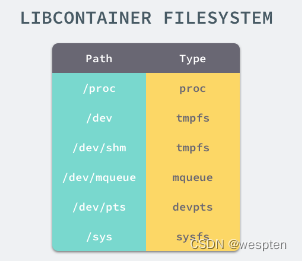
想要正常启动一个容器就需要在 rootfs 中挂载以上的几个特定的目录,除了上述的几个目录需要挂载之外我们还需要建立一些符号链接保证系统 IO 不会出现问题。
为了保证当前的容器进程没有办法访问宿主机器上其他目录,我们在这里还需要通过 libcotainer 提供的 pivor_root 或者 chroot 函数改变进程能够访问个文件目录的根节点。
// pivor_root
put_old = mkdir(...);
pivot_root(rootfs, put_old);
chdir("/");
unmount(put_old, MS_DETACH);
rmdir(put_old);
// chroot
mount(rootfs, "/", NULL, MS_MOVE, NULL);
chroot(".");
chdir("/");到这里我们就将容器需要的目录挂载到了容器中,同时也禁止当前的容器进程访问宿主机器上的其他目录,保证了不同文件系统的隔离。
linux namespace API:
所讨论的namespace实现针对的均是Linux内核3.8及其以后的版本。
namespace的API包括clone()、setns()以及unshare(),还有/proc下的部分文件。为了确定隔离的到底是哪种namespace,在使用这些API时,通常需要指定以下六个常数的一个或多个,通过|(位或)操作来实现。你可能已经在上面的表格中注意到,这六个参数分别是CLONE_NEWIPC、CLONE_NEWNS、CLONE_NEWNET、CLONE_NEWPID、CLONE_NEWUSER和CLONE_NEWUTS。
① 通过clone()创建新进程的同时创建namespace
使用clone()来创建一个独立namespace的进程是最常见做法,它的调用方式如下。
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);clone()实际上是传统UNIX系统调用fork()的一种更通用的实现方式,它可以通过flags来控制使用多少功能。一共有二十多种CLONE_*的flag(标志位)参数用来控制clone进程的方方面面(如是否与父进程共享虚拟内存等等),下面外面逐一讲解clone函数传入的参数。
② 查看/proc/[pid]/ns文件
从3.8版本的内核开始,用户就可以在/proc/[pid]/ns文件下看到指向不同namespace号的文件,效果如下所示,形如[4026531839]者即为namespace号。
$ ls -l /proc/$$/ns <<-- 0="" 1="" 8="" $$="" 表示应用的pid="" total="" lrwxrwxrwx.="" mtk="" jan="" 04:12="" ipc="" -=""> ipc:[4026531839]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 net -> net:[4026531956]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 pid -> pid:[4026531836]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 user->user:[4026531837]
lrwxrwxrwx. 1 mtk mtk 0 Jan 8 04:12 uts -> uts:[4026531838]
如果两个进程指向的namespace编号相同,就说明他们在同一个namespace下,否则则在不同namespace里面。/proc/[pid]/ns的另外一个作用是,一旦文件被打开,只要打开的文件描述符(fd)存在,那么就算PID所属的所有进程都已经结束,创建的namespace就会一直存在。那如何打开文件描述符呢?把/proc/[pid]/ns目录挂载起来就可以达到这个效果,命令如下。
# touch ~/uts
# mount --bind /proc/27514/ns/uts ~/uts
如果你看到的内容与本文所描述的不符,那么说明你使用的内核在3.8版本以前。该目录下存在的只有ipc、net和uts,并且以硬链接存在。
③ 通过setns()加入一个已经存在的namespace
上文刚提到,在进程都结束的情况下,也可以通过挂载的形式把namespace保留下来,保留namespace的目的自然是为以后有进程加入做准备。通过setns()系统调用,你的进程从原先的namespace加入我们准备好的新namespace,使用方法如下:
int setns(int fd, int nstype);-
参数fd表示我们要加入的namespace的文件描述符。上文已经提到,它是一个指向/proc/[pid]/ns目录的文件描述符,可以通过直接打开该目录下的链接或者打开一个挂载了该目录下链接的文件得到。
-
参数nstype让调用者可以去检查fd指向的namespace类型是否符合我们实际的要求。如果填0表示不检查。
为了把我们创建的namespace利用起来,我们需要引入execve()系列函数,这个函数可以执行用户命令,最常用的就是调用/bin/bash并接受参数,运行起一个shell,用法如下:
fd = open(argv[1], O_RDONLY); /* 获取namespace文件描述符 */
setns(fd, 0); /* 加入新的namespace */
execvp(argv[2], &argv[2]); /* 执行程序 */假设编译后的程序名称为setns:
# ./setns ~/uts /bin/bash # ~/uts 是绑定的/proc/27514/ns/uts至此,你就可以在新的命名空间中执行shell命令了,在下文中会多次使用这种方式来演示隔离的效果。
④ 通过unshare()在原先进程上进行namespace隔离
最后要提的系统调用是unshare(),它跟clone()很像,不同的是,unshare()运行在原先的进程上,不需要启动一个新进程,使用方法如下:
int unshare(int flags);调用unshare()的主要作用就是不启动一个新进程就可以起到隔离的效果,相当于跳出原先的namespace进行操作。这样,你就可以在原进程进行一些需要隔离的操作。Linux中自带的unshare命令,就是通过unshare()系统调用实现的,有兴趣的读者可以在网上搜索一下这个命令的作用。
5、CGroups物理资源限制分组
我们通过 Linux 的命名空间为新创建的进程隔离了文件系统、网络并与宿主机器之间的进程相互隔离,但是命名空间并不能够为我们提供物理资源上的隔离,比如 cpu 或者内存,如果在同一台机器上运行了多个对彼此以及宿主机器一无所知的『容器』,这些容器却共同占用了宿主机器的物理资源。
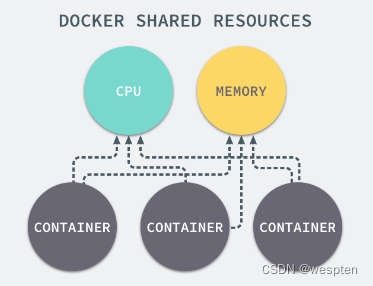
如果其中的某一个容器正在执行 cpu 密集型的任务,那么就会影响其他容器中任务的性能与执行效率,导致多个容器相互影响并且抢占资源。如何对多个容器的资源使用进行限制就成了解决进程虚拟资源隔离之后的主要问题,而 Control Groups(简称 CGroups)就是能够隔离宿主机器上的物理资源,例如 cpu、内存、磁盘 I/O 和网络带宽。
每一个 CGroup 都是一组被相同的标准和参数限制的进程,不同的 CGroup 之间是有层级关系的,也就是说它们之间可以从父类继承一些用于限制资源使用的标准和参数。
Linux 的 CGroup 能够为一组进程分配资源,也就是我们在上面提到的 cpu、内存、网络带宽等资源,通过对资源的分配。
Linux 使用文件系统来实现 CGroup,我们可以直接使用下面的命令查看当前的 CGroup 中有哪些子系统:
$ lssubsys -m
cpuset /sys/fs/cgroup/cpuset
cpu /sys/fs/cgroup/cpu
cpuacct /sys/fs/cgroup/cpuacct
memory /sys/fs/cgroup/memory
devices /sys/fs/cgroup/devices
freezer /sys/fs/cgroup/freezer
blkio /sys/fs/cgroup/blkio
perf_event /sys/fs/cgroup/perf_event
hugetlb /sys/fs/cgroup/hugetlb大多数 Linux 的发行版都有着非常相似的子系统,而之所以将上面的 cpuset、cpu 等东西称作子系统,是因为它们能够为对应的控制组分配资源并限制资源的使用。
如果我们想要创建一个新的 cgroup 只需要在想要分配或者限制资源的子系统下面创建一个新的文件夹,然后这个文件夹下就会自动出现很多的内容,如果你在 Linux 上安装了 Docker,你就会发现所有子系统的目录下都有一个名为 Docker 的文件夹:
$ ls cpu
cgroup.clone_children
...
cpu.stat
docker
notify_on_release
release_agent
tasks
$ ls cpu/docker/
9c3057f1291b53fd54a3d12023d2644efe6a7db6ddf330436ae73ac92d401cf1
cgroup.clone_children
...
cpu.stat
notify_on_release
release_agent
tasks9c3057xxx 其实就是我们运行的一个 Docker 容器,启动这个容器时,Docker 会为这个容器创建一个与容器标识符相同的 CGroup,在当前的主机上 CGroup 就会有以下的层级关系:
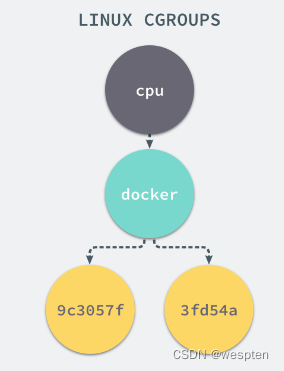
每一个 CGroup 下面都有一个 tasks 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统,cpu.cfs_quota_us 文件中的内容能够对 cpu 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 cpu 占用率不能超过 50%。
如果系统管理员想要控制 Docker 某个容器的资源使用率就可以在 docker 这个父控制组下面找到对应的子控制组并且改变它们对应文件的内容,当然我们也可以直接在程序运行时就使用参数,让 Docker 进程去改变相应文件中的内容。
当我们使用 Docker 关闭掉正在运行的容器时,Docker 的子控制组对应的文件夹也会被 Docker 进程移除,Docker 在使用 CGroup 时其实也只是做了一些创建文件夹改变文件内容的文件操作,不过 CGroup 的使用也确实解决了我们限制子容器资源占用的问题,系统管理员能够为多个容器合理的分配资源并且不会出现多个容器互相抢占资源的问题。
6、Docker存储驱动
写时复制 (CoW):所有驱动都用到的技术————写时复制,Cow全称copy-on-write,表示只是在需要写时才去复制,这个是针对已有文件的修改场景。比如基于一个image启动多个Container,如果每个Container都去分配一个image一样的文件系统,那么将会占用大量的磁盘空间。而CoW技术可以让所有的容器共享image的文件系统,所有数据都从image中读取,只有当要对文件进行写操作时,才从image里把要写的文件复制到自己的文件系统进行修改。所以无论有多少个容器共享一个image,所做的写操作都是对从image中复制到自己的文件系统的副本上进行,并不会修改image的源文件,且多个容器操作同一个文件,会在每个容器的文件系统里生成一个副本,每个容器修改的都是自己的副本,互相隔离,互不影响。使用CoW可以有效的提高磁盘的利用率。
用时分配 (allocate-on-demand):写是分配是用在原本没有这个文件的场景,只有在要新写入一个文件时才分配空间,这样可以提高存储资源的利用率。比如启动一个容器,并不会因为这个容器分配一些磁盘空间,而是当有新文件写入时,才按需分配新空间。
Docker最开始采用AUFS作为文件系统,也得益于AUFS分层的概念,实现了多个Container可以共享一个image。但是由于AUFS未并入Linux内核,且只支持Ubuntu,考虑到兼容性问题,在Docker 0.7 版本中引入了存储驱动,目前,Docker支持AUFS、Btrfs、Devicemapper、OverlayFS、ZFS五种存储驱动。
① AUFS
AUFS (Advanced UnionFS)其实就是 UnionFS 的升级版,它能够提供更优秀的性能和效率,是文件级的存储驱动。
AUFS 作为先进联合文件系统,它能够将不同文件夹中的层联合(Union)到了同一个文件夹中,这些文件夹在 AUFS 中称作分支,整个『联合』的过程被称为联合挂载(Union Mount)。
AUFS能透明覆盖一或多个现有文件系统的层状文件系统,把多层合并成文件系统的单层表示。简单来说就是支持将不同目录挂载到同一个虚拟文件下的文件系统。这种文件系统可以一层一层地叠加修改文件。
无论底下有多少层都是只读的,只有最上层的文件系统是可写的。当需要修改一个文件时,AUFS创建该文件的一个副本,使用CoW将文件从只读层复制到可写层进行修改,结果也保存在科协层。在Docker中,只读层就是image,可写层就是Container。
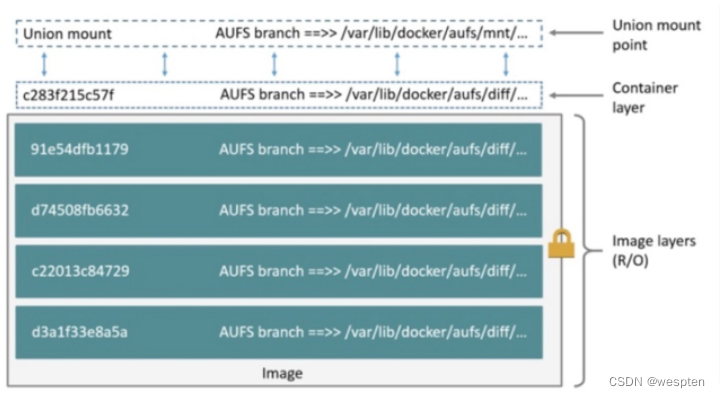
最好是有一个真实的例子来帮助我们理解。
首先,我们建立 company 和 home 两个目录,并且分别为他们创造两个文件:
# tree .
.
|-- company
| |-- code
| `-- meeting
`-- home
|-- eat
`-- sleep
然后我们将通过 mount 命令把 company 和 home 两个目录「联合」起来,建立一个 AUFS 的文件系统,并挂载到当前目录下的 mnt 目录下:
# mkdir mnt
# ll
total 20
drwxr-xr-x 5 root root 4096 Oct 25 16:10 ./
drwxr-xr-x 5 root root 4096 Oct 25 16:06 ../
drwxr-xr-x 4 root root 4096 Oct 25 16:06 company/
drwxr-xr-x 4 root root 4096 Oct 25 16:05 home/
drwxr-xr-x 2 root root 4096 Oct 25 16:10 mnt/
# mount -t aufs -o dirs=./home:./company none ./mnt
# ll
total 20
drwxr-xr-x 5 root root 4096 Oct 25 16:10 ./
drwxr-xr-x 5 root root 4096 Oct 25 16:06 ../
drwxr-xr-x 4 root root 4096 Oct 25 16:06 company/
drwxr-xr-x 6 root root 4096 Oct 25 16:10 home/
drwxr-xr-x 8 root root 4096 Oct 25 16:10 mnt/
root@rds-k8s-18-svr0:~/xuran/aufs# tree ./mnt/
./mnt/
|-- code
|-- eat
|-- meeting
`-- sleep
4 directories, 0 files
通过 ./mnt 目录结构的输出结果,可以看到原来两个目录下的内容都被合并到了一个 mnt 的目录下。
默认情况下,如果我们不对「联合」的目录指定权限,内核将根据从左至右的顺序将第一个目录指定为可读可写的,其余的都为只读。那么,当我们向只读的目录做一些写入操作的话,会发生什么呢?
# echo apple > ./mnt/code
# cat company/code
# cat home/code
apple通过对上面代码段的观察,我们可以看出,当写入操作发生在 company/code 文件时, 对应的修改并没有反映到原始的目录中。
而是在 home 目录下又创建了一个名为 code 的文件,并将 apple 写入了进去。
看起来很奇怪的现象,其实这正是 Union File System 的厉害之处:
Union File System 联合了多个不同的目录,并且把他们挂载到一个统一的目录上。
在这些「联合」的子目录中, 有一部分是可读可写的,但是有一部分只是可读的。当你对可读的目录内容做出修改的时候,其结果只会保存到可写的目录下,不会影响只读的目录。
比如,我们可以把我们的服务的源代码目录和一个存放代码修改记录的目录「联合」起来构成一个 AUFS。前者设置只读权限,后者设置读写权限。
那么,一切对源代码目录下文件的修改都只会影响那个存放修改的目录,不会污染原始的代码。
在 AUFS 中还有一个特殊的概念需要提及一下:
branch – 就是各个要被union起来的目录。
Stack 结构 - AUFS 它会根据branch 被 Union 的顺序形成一个 Stack 的结构,从下至上,最上面的目录是可读写的,其余都是可读的。如果按照我们刚刚执行 aufs 挂载的命令来说,最左侧的目录就对应 Stack 最顶层的 branch。
所以:下面的命令中,最为左侧的为 home,而不是 company:
mount -t aufs -o dirs=./home:./company none ./mnt
什么是 Docker 镜像分层机制?
首先,让我们来看下 Docker Image 中的 Layer 的概念:
Docker Image 是有一个层级结构的,最底层的 Layer 为 BaseImage(一般为一个操作系统的 ISO 镜像),然后顺序执行每一条指令,生成的 Layer 按照入栈的顺序逐渐累加,最终形成一个 Image。
直观的角度来说,是这个图所示:
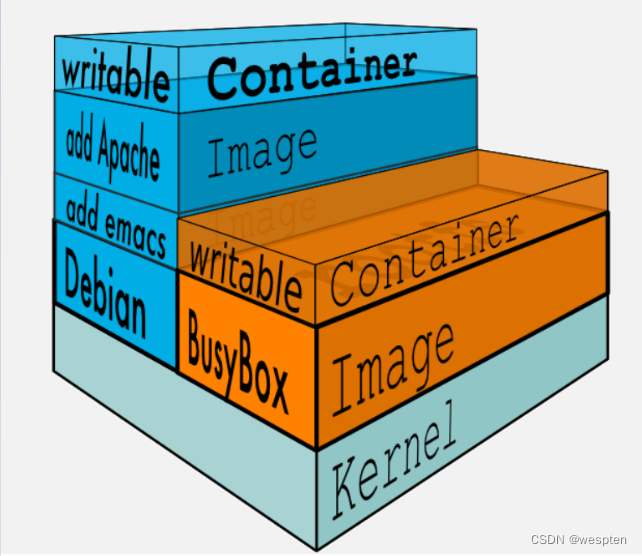
每一次都是一个被联合的目录,从目录的角度来说,大致如下图所示:
Docker Image 如何而来呢?
简单来说,一个 Image 是通过一个 DockerFile 定义的,然后使用 docker build 命令构建它。
DockerFile 中的每一条命令的执行结果都会成为 Image 中的一个 Layer。
这里,我们通过 Build 一个镜像,来观察 Image 的分层机制。
Dockerfile:
# Use an official Python runtime as a parent image
FROM python:2.7-slim
# Set the working directory to /app
workdir /app
# copy the current directory contents into the container at /app
copY . /app
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Make port 80 available to the world outside this container
EXPOSE 80
# Define environment variable
ENV NAME World
# Run app.py when the container launches
CMD ["python", "app.py"]
构建结果:
root@rds-k8s-18-svr0:~/xuran/exampleimage# docker build -t hello ./
Sending build context to Docker daemon 5.12 kB
Step 1/7 : FROM python:2.7-slim
---> 804b0a01ea83
Step 2/7 : workdir /app
---> Using cache
---> 6d93c5b91703
Step 3/7 : copY . /app
---> Using cache
---> feddc82d321b
Step 4/7 : RUN pip install --trusted-host pypi.python.org -r requirements.txt
---> Using cache
---> 94695df5e14d
Step 5/7 : EXPOSE 81
---> Using cache
---> 43c392d51dff
Step 6/7 : ENV NAME World
---> Using cache
---> 78c9a60237c8
Step 7/7 : CMD python app.py
---> Using cache
---> a5ccd4e1b15d
Successfully built a5ccd4e1b15d
通过构建结果可以看出,构建的过程就是执行 Dockerfile 文件中我们写入的命令。构建一共进行了7个步骤,每个步骤进行完都会生成一个随机的 ID,来标识这一 layer 中的内容。 最后一行的 a5ccd4e1b15d 为镜像的 ID。由于我贴上来的构建过程已经是构建了第二次的结果了,所以可以看出,对于没有任何修改的内容,Docker 会复用之前的结果。
如果 DockerFile 中的内容没有变动,那么相应的镜像在 build 的时候会复用之前的 layer,以便提升构建效率。并且,即使文件内容有修改,那也只会重新 build 修改的 layer,其他未修改的也仍然会复用。
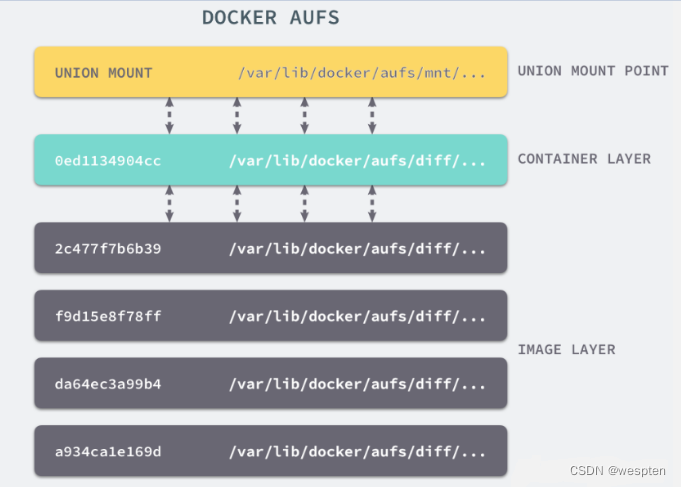
通过了解了 Docker Image 的分层机制,我们多多少少能够感觉到,Layer 和 Image 的关系与 AUFS 中的联合目录和挂载点的关系比较相似。
而 Docker 也正是通过 AUFS 来管理 Images 的。
② OverlayFS
OverlayFS是一种和AUFS很类似的文件系统,与AUFS相比,OverlayFS有以下特性; 1) 更简单地设计; 2) 从Linux 3.18开始,就加入了Linux内核主线; 3) 速度更快 因此,OverlayFS在Docker社区关注提高很快,被很多人认为是AUFS的继承者。Docker的overlay存储驱动利用了很多OverlayFS特性来构建和管理镜像与容器的磁盘结构 从Docker1.12起,Docker也支持overlay2存储驱动,相比于overlay来说,overlay2在inode优化上更加高效,但overlay2驱动只兼容Linux kernel4.0以上的版本。
注意: 自从OverlayFS加入kernel主线后,它的kernel模块中的名称就从overlayfs改为overlay了。
OverlayFS使用两个目录,把一个目录置放于另一个智商,并且对外提供单个统一的视角。这两个目录通常被称作层,这个分层的技术被称作union mount。术语上,下层的目录叫做lowerdir,上层的叫做upperdir。对外展示的统一视图称作merged。
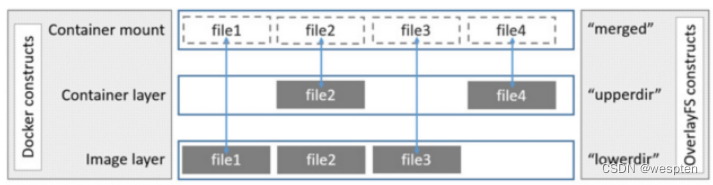
镜像层和容器层是如何处理相同文件的:容器层(upperdir)的文件是显性的,会隐藏镜像层(lowerdir)相同文件的存在,并在容器映射(merged)显示出统一视图。
overlay驱动只能工作在两层之上,也就是说多层镜像不能用多层OverlayFS实现。替代的,每个镜像层在/var/lib/docker/overlay中用自己的目录来实现,使用硬链接这种有效利用空间的方法,来引用底层分享的数据。
注意: Docker1.10之后,镜像层ID和/var/lib/docker中的目录名不再一一对应。
创建一个容器,overlay驱动联合镜像层和一个新目录给容器,镜像顶层中的overlay是只读lowerdir,容器的新目录是可写的upperdir。
OverlayFS (overlay2)镜像分层与共享:overlay驱动只工作在一个lower OverlayFS层之上,因此需要硬链接来实现多层镜像,但overlay2驱动原生地支持多层lower OverlayFS镜像(最多128层)。因此overlay2驱动在合层相关的命令(如build何commit)中提供了更好的性能,与overlay驱动对比,减少了inode消耗
容器overlay读写:有三种场景,容器会通过overlay只读访问文件 容器层不存在的文件 如果容器只读打开一个文件,但该容器不在容器层(upperdir),就要从镜像层(lowerdir)中读取。这会引起很小的性能消耗 只存在于容器层的文件 如果容器只读权限打开一个文件,并且容器只存在于容器层(upperdir)而不是镜像层(lowerdir),那么直接从镜像层读取文件,无额外的性能损耗 文件同时存在于容器层和镜像层 那么会读取容器层的文件,因为容器层(upperdir)隐层了镜像层(lowerdir)的同名文件,因此,也没有额外的性能损耗。
有以下场景容器修改文件 第一次写一个文件,容器第一次写一个已经存在的文件,容器层不存在这个文件。overlay/overlay2驱动执行copy-up操作,将文件从镜像层拷贝到容器层。然后容器修改容器层新拷贝的文件:
1. copy-up 操作只发生在第一次写文件时,后续的对同一个文件的鞋操作都是直接针对拷贝到容器层的文件;
2. OverlayFS只工作在两层中。这比AUFS要在多层镜像中查找时性能要好;
删除文件和目录删除文件时,容器会在镜像层创建一个whiteout文件,而镜像层的文件并没有删除,但是whiteout文件会隐藏它。容器中删除一个目录,容器层会创建一个不透明目录,这和whiteout文件隐藏镜像层的文件类似。
重命名目录只有在源文件和目的路径都在顶层容器层时,才允许执行rename操作,否则返回EXDEV。因此,应用需要能够处理EXDEV,并且回滚操作,执行替代的”拷贝和删除”策略。
在Docker中配置overlay2 存储驱动为了给Docker配置overlay存储驱动,你的Docker host必须在Linux kernel3.18版本之上,并且加载了overlay内核驱动。对于overlay2驱动,kernel版本必须在4.0或以上。OverlayFS可以运行在大多数Linux文件系统之上。
注意: 在开始配置之前,如果你已经在使用Docker daemon,并且有一些想保留的镜像,请将他们push到镜像仓库中。
我这里使用centos7.6内核4.18演示:
1.停止Docker
[root@i4t ~]# systemctl stop docker
2.检查kernel版本,确定overlay的内核模块是否加载
[root@i4t ~]# uname -r
4.18.9-1.el7.elrepo.x86_64
[root@i4t ~]# lsmod |grep overlay
overlay 901120
#如果没有过滤出overlay模块,说明驱动没有加载,使用下面方法进行加载
[root@i4t ~]# modprobe overlay
3.使用verlay2存储来启动docker
#配置方法有2种
(1)在Docker的启动配置文件中添加--storage-driver=overlay2的标志到DOCKER_OPTS中,这样可以持久化配置
(2)或者将配置持久化到配置文件/etc/docker/daemon.json中
"storage-driver":"overlay2"
接下来可以检查Docker是否使用overlay2作为存储引擎:

③ Devicemapper
Device mapper是Linux内核2.6.9后支持的,提供的一种从逻辑设备到物理设备的映射框架机制,在该机制下,用户可以很方便的根据自己需要制定实现存储资源的管理策略。AUFS和OverlayFS都是文件级存储,而Devicemapper是块级存储,所有的操作都是直接对块进行操作,而不是文件。
Devicemapper驱动会先在块设备上创建一个资源池,然后在资源池上创建一个带有文件系统的基本设备,所有镜像都是这个基本设备的快照,而容器则是镜像的快照。所以在容器看到文件系统是资源池上基本设备的文件系统的快照,并不是为容器分配空间。当要写入一个新文件时妹子容器的镜像内为其分配新的块并写入数据,这个叫做用时分配,上面也介绍了。当要修改已有文件时,再使用CoW为容器快照分配块空间,将要修改的数据复制到容器快照中的新快里再进行修改。
Devicemapper驱动默认会创建一个100G的文件包含镜像和容器,每个容器被限制在10G大小的卷内,可以自己配置调整。

④ Btrfs
Btrfs被称为下一代写时复制的文件系统,并入Linux内核,也是文件级存储,但可以像Devicemapper一直被操作底层设备。Btrfs把文件系统的一部分配置为一个完整的子文件系统,称之为subvolume。
采用subvolume,一个大的文件系统可以被划分多个子文件系统,这些子文件系统共享底层的设备空间,在需要磁盘空间时便从底层设备中分配,比如Btrfs支持动态添加设备。用户在系统中新增加硬盘后,可以使用Btrfs的命令将该设备添加到文件系统中。Btrfs把一个大的文件系统当成一个资源池,配置成多个完整的子文件系统,还可以往资源池里加新的子文件系统,而基础镜像则是子文件系统的快照,每个子镜像和容器都有自己的快照,这些快照都是subvolume的快照。
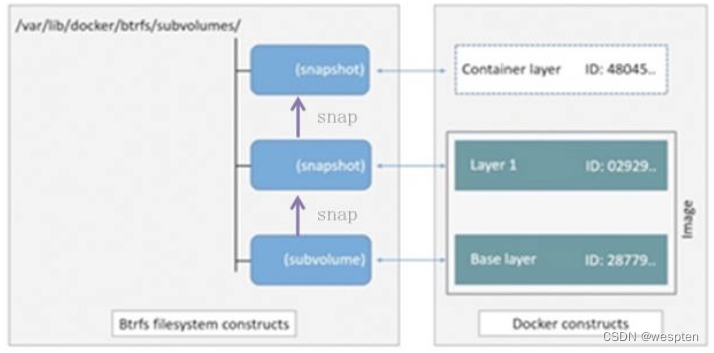
当写入一个新文件时,在容器的快照里为其分配了一个新的数据块,文件写在这个空间里,叫做用时分配。而当修改已有文件时,使用CoW复制分配一个新的原始数据和快照,在这个新分配的空间变更数据,等结束后再进行相关的数据结构指引到新子文件系统和快照,原来的原始数据和快照没有指针指示,被覆盖。
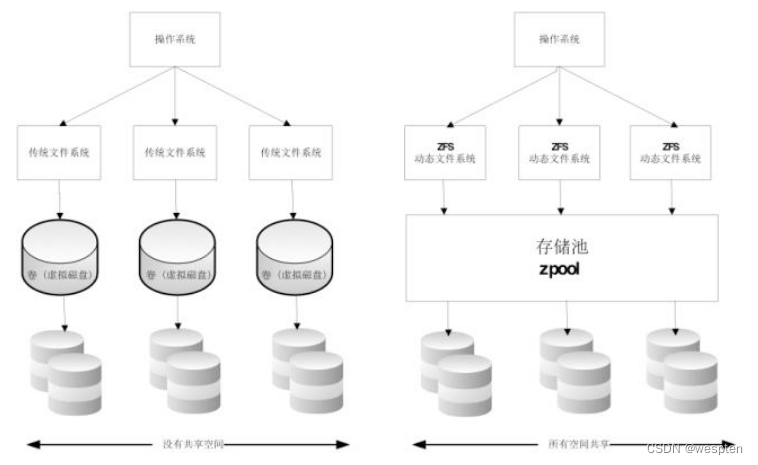
⑤ ZFS
ZFS文件系统是一个革命性的全新的文件系统,它从根本上改变了文件系统的管理方式,ZFS完全抛弃了”卷管理”,不再创建虚拟的卷,而是把所有设备集中到一个存储池中来进行管理,用”存储池”的概念来管理物理存储空间。过去,文件系统都是构建在物理设备之上的,并为数据提供冗余,”卷管理”的概念提供了一个单设备的映像。
而ZFS创建在虚拟的,被称为”zpools”的存储池上。每个存储池由若干虚拟设备(virtual devices,vdevs)组成。这些虚拟设备可以是原始磁盘,也可以是一个RAID的镜像设备,或者是非标准RAID等级的多磁盘组。这样zpool上的文件系统可以使用这些虚拟设备的总存储容量。
在Docker中使用ZFS,首先从zpool里分配一个ZFS文件系统给镜像的基础层,而其它镜像层则是这个ZFS文件系统快照的克隆,快照只是只读的,而克隆是可写的,当容器启动时则在镜像的最顶层生成一个可写成:
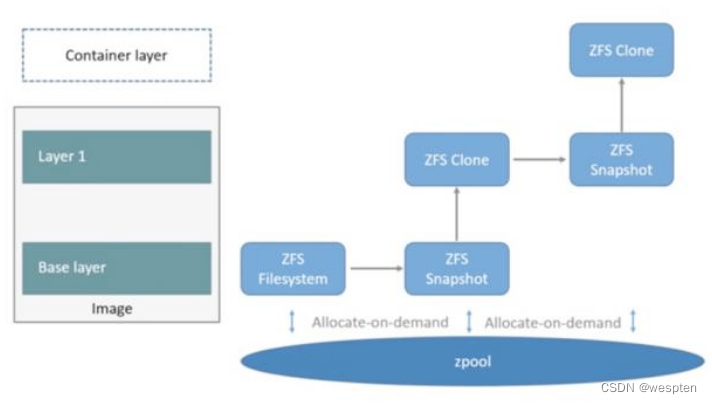
当要写一个新文件时,使用按需分配,一个新的数据块从zpool里生成,新的数据写入这个块,而这个新的空间存储于容器(ZFS的克隆)里。当要修改一个已存在的文件时,使用写时复制,分配一个新空间并把原始数据复制到新空间完成修改。
存储驱动的对比及适应场景:
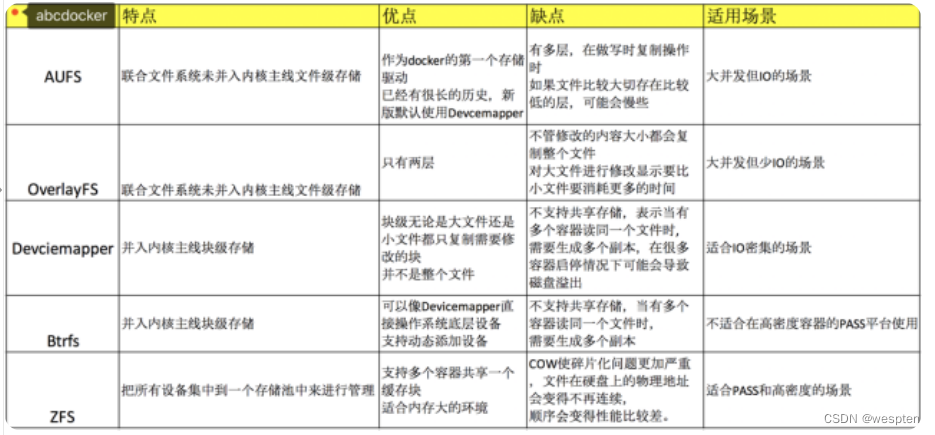
一般来说,overlay2驱动更快一些,几乎肯定比AUFS和devicemapper更快,在某些情况下,可能比Btrfs也快。在使用overlay2存储驱动时,需要注意以下几点:
1. Page Caching 页缓存 OverlayFS支持页缓存,也就是说如果多个容器访问同一个文件,可以共享一个或多个页缓存选项。这使得overlay2驱动高效地利用了内存,是Pass平台或者高密度场景很好的选择;
2. copy_up 和AUFS一样,在容器第一次修改文件时,OverlayFS都需要执行copy_up操作,这会给操作带来一些延迟————尤其这个拷贝很大的文件时,不过一旦文件已经执行了这个向上拷贝的操作后,所有后续对这个文件的操作都只针对这份容器层的拷贝而已;
3. Inode limits 使用overlay存储驱动可能导致过多的inode消耗,尤其是Docker host上镜像和容器的数目增长时。大量的镜像或者很多容器启停,会迅速消耗该Docker host的inode。但是overlay2 存储驱动不存在这个问题;
针对overlay2小结:overlay2存储驱动已经成为了Docker首选存储驱动,并且性能优于AUFS和devicemapper。不过,也带来了一些与其他文件系统不兼容性,如对open和rename操作的支持,另外,overlay和overlay2相比,overlay2支持了多层镜像,优化了inode的使用。
7、原理总结
Dockers=LXC+AUFS
- LXC负责资源管理
- AUFS负责镜像管理
Docker约等于LXC+AUFS(之前只支持ubuntu时)(Docker0.9.0版本开始引入libcontainer,可以视作LXC的替代品),其中LXC负责资源管理,AUFS负责镜像管理。
LXC包括cgroup,namespace,chroot等组件,并通过cgroup资源管理:
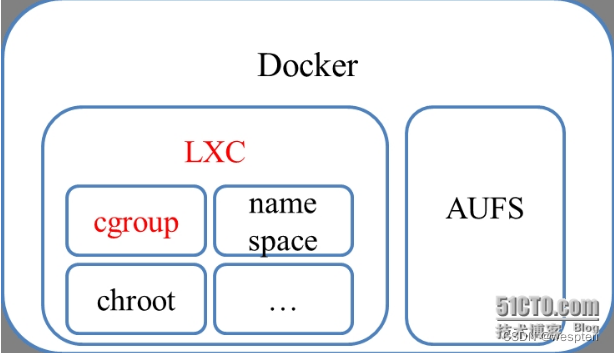
所以只从资源管理这条线来看的话,Docker、LXC、Cgroup三者的关系是:Cgroup在最底层落实资源管理,LXC在cgroup上封装了一层,Docker又在LXC封装了一层,关系图如图所示。因此,要想玩转Docker,有必要了解负责资源管理的CGroup和LXC。
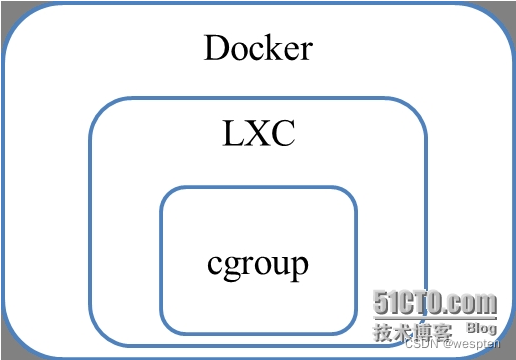
Cgroup其实就是linux提供的一种限制,记录,隔离进程组所使用的物理资源管理机制;也就是说,Cgroup是LXC为实现虚拟化所使用资源管理手段,我们可以这样说,底层没有cgroup支持,也就没有lxc,更别说docker的存在了,这需要我们掌握和理解三者之间的关系。
我们在把重心转移到LXC这个相当于中间件上,上述我们提到LXC是建立在cgroup基础上的,我们可以粗略的认为LXC=Cgroup+namespace+Chroot+veth+用户控制脚本。LXC利用内核的新特性(cgroup)来提供用户空间的对象,用来保证资源的隔离和对应用系统资源的限制。
① Cgroup基本概念与术语
任务(task):
在Cgroups中,任务就是系统的一个进程。
控制族群(control group):
控制族群就是一组按照某种标准划分的进程,控制族群通常按照应用划分,即与某应用相关的一组进程,被划分为一个进程组,即控制族群(control group)。Cgroups中的资源控制都是以控制族群为单位实现。
一个进程可以加入到某个控制族群,也可以从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用Cgroups以控制族群为单位分配的资源,同时受到Cgroups以控制族群为单位设定的限制。
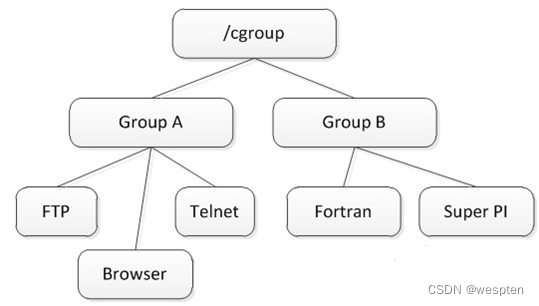
层级(hierarchy):
控制族群可以组织成hierarchical的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。
控制族群树的示意图如图所示:
子系统(subsystem):
一个子系统就是一个资源控制器,比如cpu子系统就是控制cpu时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
② Cgroup子系统介绍
a) blkio -- 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB等等)。
b) cpu -- 这个子系统使用调度程序提供对cpu 的 Cgroup 任务访问。
c) cpuacct -- 这个子系统自动生成Cgroup中任务所使用的 cpu 报告。
d) cpuset-- 这个子系统为 Cgroup中的任务分配独立cpu(在多核系统)和内存节点。
e) devices -- 这个子系统可允许或者拒绝Cgroup中的任务访问设备。
f) freezer -- 这个子系统挂起或者恢复Cgroup中的任务。
g) memory -- 这个子系统设定Cgroup中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。
h) net_cls -- 这个子系统使用等级识别符(classid)标记网络数据包,可允许Linux 流量控制程序(tc)识别从具体cgroup 中生成的数据包。
i) ns -- 名称空间子系统。
Cgroup具有不同的挂载方法——“多挂载点”和“单挂载点”。子系统“多挂载点”挂载就是指不同子系统的文件挂载在不同的目录下,每个子系统各有一个挂载点,目录结构如图所示:

Cgroup对应服务cgconfig默认使用的就是“多挂载点”的方法。“单挂载点”则是指所有子系统的文件都挂载在同一个目录下,所有子系统都统一挂载在一个挂载点,目录结构如图所示:
③ Cgroup安装配置
1) Cgroup安装
安装Cgroups需要libcap-devel和libcgroup两个相关的包,CentOS上可以通过yum的方式下载安装,具体的命令为:
yum install gcc, libcap-devel,libcgroup, bridge-utils2) Cgroup挂载配置
Cgroup对应服务名称为cgconfig,cgconfig默认采用“多挂载点”挂载。经过实际测试,发现在CentOS环境中应采用“单挂载点”进行挂载,因此应当卸载原有cgroup文件系统,并禁用cgconfig:
cgclear或者sudo service cgconfig stop # 停止cgconfig,卸载cgroup目录
sudo chkconfig cgconfig off # 禁用cgconfig服务,避免其开机启动然后采用“单挂载点”方式重新挂载cgroup,可以直接手动挂载,这样仅当次挂载成功:
mount -t cgroup none /cgroup然后编辑/etc/fstab/,输入下列内容。这样每次开机后都会自动挂载:
none /cgroup cgroup defaults 0 03)常用的Cgroup相关命令和配置文件
service cgconfig status|start|stop|restart #查看已存在子系统
lssubsys –am #查看已存在子系统
cgclear # 清除所有挂载点内部文件,相当于service cgconfig stop
cgconfigparser -l /etc/cgconfig.conf #重新挂载
Cgroup默认挂载点(CentOS):/cgroup
cgconfig配置文件:/etc/cgconfig.conf4)libcgroup Man Page简介
man 1 cgclassify -- cgclassify命令是用来将运行的任务移动到一个或者多个cgroup。
man 1 cgclear -- cgclear 命令是用来删除层级中的所有cgroup。
man 5 cgconfig.conf -- 在cgconfig.conf文件中定义cgroup。
man 8 cgconfigparser -- cgconfigparser命令解析cgconfig.conf文件和并挂载层级。
man 1 cgcreate -- cgcreate在层级中创建新cgroup。
man 1 cgdelete -- cgdelete命令删除指定的cgroup。
man 1 cgexec -- cgexec命令在指定的cgroup中运行任务。
man 1 cgget -- cgget命令显示cgroup参数。
man 5 cgred.conf -- cgred.conf是cgred服务的配置文件。
man 5 cgrules.conf -- cgrules.conf 包含用来决定何时任务术语某些 cgroup的规则。
man 8 cgrulesengd -- cgrulesengd 在 cgroup 中发布任务。
man 1 cgset -- cgset 命令为 cgroup 设定参数。
man 1 lscgroup -- lscgroup 命令列出层级中的 cgroup。
man 1 lssubsys -- lssubsys 命令列出包含指定子系统的层级。④ Linux Container(LXC)
LinuxContainer容器可以提供轻量级的虚拟化,以便隔离进程和资源,而且不需要提供指令解释机制以及全虚拟化的其他复杂性。容器有效地将由单个操作系统管理的资源划分到孤立的组中,以更好地在孤立的组之间平衡有冲突的资源使用需求。
LXC建立在CGroup基础上,我们可以粗略的认为LXC = Cgroup+ namespace + Chroot + veth +用户态控制脚本。LXC利用内核的新特性(CGroup)来提供用户空间的对象,用来保证资源的隔离和对于应用或者系统的资源控制。
根据LXC官网(Linux Containers)的描述,LXC具有以下特性:
Current LXC uses the following kernel features to contain processes:
Kernel namespaces (ipc, uts, mount, pid, network and user)
Apparmor and SELinux profiles
Seccomp policies
Chroots (using pivot_root)
Kernel capabilities
Control groups (cgroups)1)LXC的优势
与虚拟化相比,它的优势在于:
a)不需要指令级模拟;
b)不需要即时(Just-in-time)编译;
c)容器可以在cpu核心的本地运行指令,而不需要任何专门的解释机制;
d)避免了准虚拟化和系统调用替换中的复杂性;
总结来说,就是LXC更加轻量级,具有更小的性能开销、更快的相应时间。
2)LXC安装
从sourceforge.net/projects/lxc/files/lxc下载lxc源码,解压后进入目录,执行以下命令:
./configure
make
sudo make install3)LXC常用命令
lxc-version # 用于显示系统LXC的版本号
lxc-checkconfig # 查看内核是否支持LXC
lxc-create -n name -f config
# 注:1.采用lxc-create创建的容器,在停止运行后,不会被销毁,要采用lxc-destroy命令才能销毁
# 2.容器命令空间是全局的,系统中不允许存在重名的容器,如果-n 后面跟一个已经存在的容器名,创建会失败
lxc-start -n name -f config cmd #用于在容器中执行给定命令
lxc-execute -n name -f config cmd #用于在一个容器执行应用程序
# 备注:lxc-start只启动一个进程,即cmd;lxc-execute 启动两个进程,lxc-init和cmd
lxc-kill -n name #给SIGNUM信号
lxc-stop -n name # 停止lxc容器内所有进程
lxc-destroy -n name # 销毁容器
lxc-cgroup -n name subsys value #用于获取或调整与cgroup相关的参数,例如 lxc-cgroup -n name cpuset.cpus “0,3” ,控制资源
lxc-info # 用户获取一个容器的状态
lxc-monitor # 监控一个容器状态的变换,当一个容器的状态变化时,此命令会在屏幕上打印出容器的状态
lxc-ls # 列出当前系统所有的容器
lxc-ps # 列出特定容器中运行的进程4)资源控制
Cores
lxc.cgroup.cpuset.cpus=1,2,3
cpu share
lxc.cgroup.cpu.shares=1024 # default
Memory usage (!Debian)
lxc.cgroup.memory.limit_in_bytes = 256M
lxc.cgroup.memory.memsw.limit_in_bytes = 1G
disk (blkio)
disk space – standard LVM, quota...
echo 100 > /cgroup/disk1/blkio.weight # XXX < 1000 !
echo "3:0 1048576" >/cgroup/disk1/blkio.throttle.read_bps_device
lxc.cgroup.blkio.weight = 1005)配置文件样例
lxc.utsname = host_name
lxc.tty = 1
lxc.network.type = veth
lxc.network.flags = u
lxc.network.link = br0
lxc.network.ipv4 = 192.168.120.105/16
lxc.network.name = eth0
#lxc.mount = ./fstab
#lxc.rootfs = /rootfs
lxc.cgroup.cpuset.cpus = 0
lxc.cgroup.cpu.shares = 80使用中的一些小问题:
lxc-ls #列出所有lxc,但是在centos下时常不好用。备注:lxc-create之后,lxc-ls才能看到。但是只lxc-create,而不execute,则并未实际启动congtainer,相应cgroup并未实际挂载。
lxc-ps # 列出指定container内的所有进程。备注:lxc-ps –n name或者lxc-ps –n name -- -ef二、Docker架构与生命周期
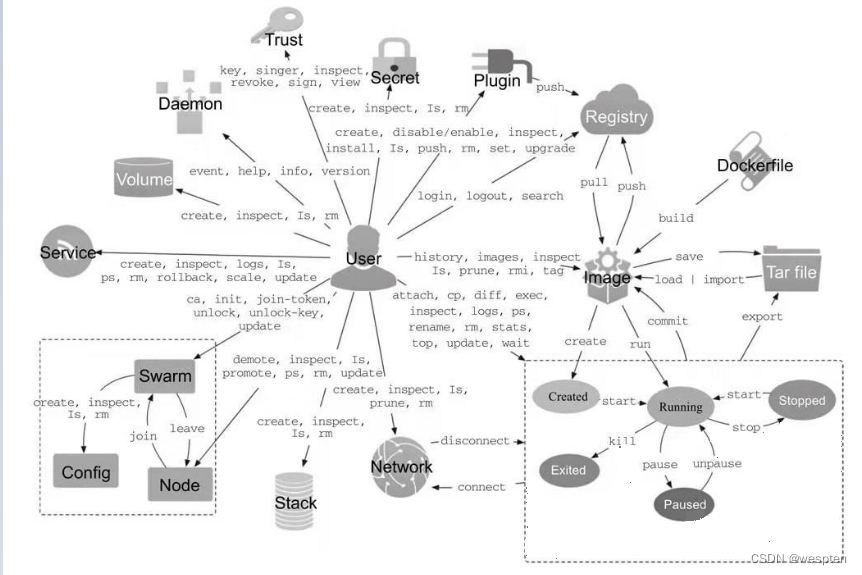
1、Docker架构
Docker Engine是一个C/S架构的应用程序,主要包含下面几个组件:
1. 常驻后台进程Dockerd;
2. 一个用来和Dockerd交互的REST API Server;
3. 命令行CLI接口,通过和REST API进行交互;
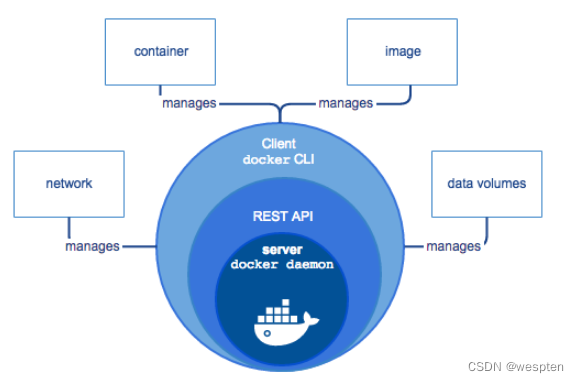
Docker包含三个基本概念:
1. 镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。
2. 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等,且容器之间是彼此互相隔离、互不可见的。镜像自身是只读的。容器从镜像启动的时候,会在镜像的最上层创建一个可写层。
3. 仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。同一类的镜像会存放在一个仓库中,并使用 tag 来进行区分。其中最大的公开仓库是官方的 Docker Hub,其次国内云服务供应商(如腾讯云、阿里云等)也提供了公开的仓库,国内用户的话最好访问它们。
Docker 容器通过 Docker 镜像来创建。
| 概念 | 说明 |
|---|---|
| Docker 镜像(Images) | Docker 镜像是用于创建 Docker 容器的模板,比如 Ubuntu 系统。 |
| Docker 容器(Container) | 容器是独立运行的一个或一组应用,是镜像运行时的实体。 |
| Docker 客户端(Client) | Docker 客户端通过命令行或者其他工具使用 Docker SDK (https://docs.docker.com/develop/sdk/) 与 Docker 的守护进程通信。 |
| Docker 主机(Host) | 一个物理或者虚拟的机器用于执行 Docker 守护进程和容器。 |
| Docker Registry | Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hub(https://hub.docker.com) 提供了庞大的镜像集合供使用。一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。 ———————————————— 版权声明:本文为CSDN博主「架构师-尼恩」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/crazymakercircle/article/details/121134690 |
Docker使用了C/S体系架构,使用远程API来管理和创建Docker容器。Docker客户端与Docker守护进程通信,Docker守护进程负责构建,运行和分发Docker容器。Docker客户端和守护进程可以在同一个系统上运行,也可以将Docker客户端连接到远程Docker守护进程。Docker客户端和守护进程使用REST API通过UNIX套接字或网络接口进行通信。
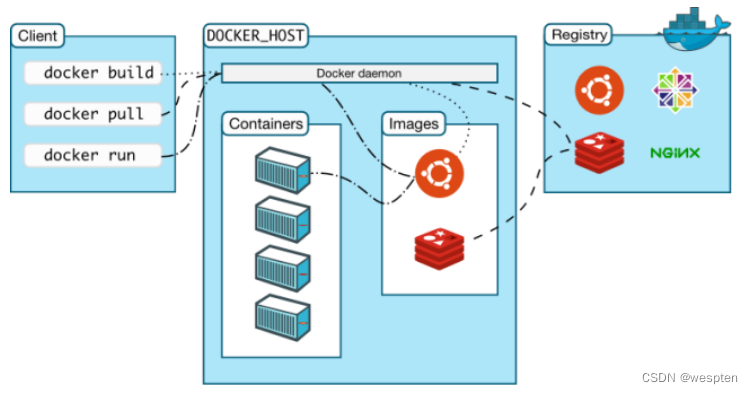
Docker damon DockerD用来监听Docker API的请求和管理Docker对象,比如镜像、容器、网络和Volume Docker Client docker client是我们和Docker进行交互的最主要的方式方法,比如可以通过docker run来运行一个容器,然后我们的这个client会把命令发送给上面的DockerDocker Registry 用来存储Docker镜像的仓库,Docker Hub是Docker官方提供的一个公共仓库,而且Docker默认也是从Docker Hub上查找镜像的,当然你也可以很方便的运行一个私有仓库。
当我们使用docker pull或者docker run命令时,就会从我们配置的Docker镜像仓库中去拉取镜像,使用docker push命令时,会将我们构建的镜像推送到对应的镜像仓库中 Images 镜像,镜像是一个制度模板,带有Docker容器的说明,一般来说的,镜像会基于另外的一些基础镜像上面安装一个Nginx服务器,这样就可以构建一个属于我们自己的镜像了 Containers 容器,容器是一个镜像的可运行的实例,可以使用Docker REST API或者CLI来操作容器,容器的实质是进程,但与直接在宿主执行的实例进程不同,容器进程属于自己的独立的命名空间。
因此容器可以拥有自己的root文件系统、自己的网络配置、自己的进程空间、甚至自己的用户ID。容器内的经常是运行在一个隔离的环境里,使用起来,就好像在一个独立于宿主的系统下操作一样,这种特性使得容器封装的应用比直接在宿主运行更加安全 。
2、Docker生命周期
生命周期是指容器所处的状态 ,容器其实本质是Host宿主机的进程,操作系统对于进程的管理是基于进程的状态切换的,进程从创建到销毁可能经过的路径图可以称之为“生命周期”。
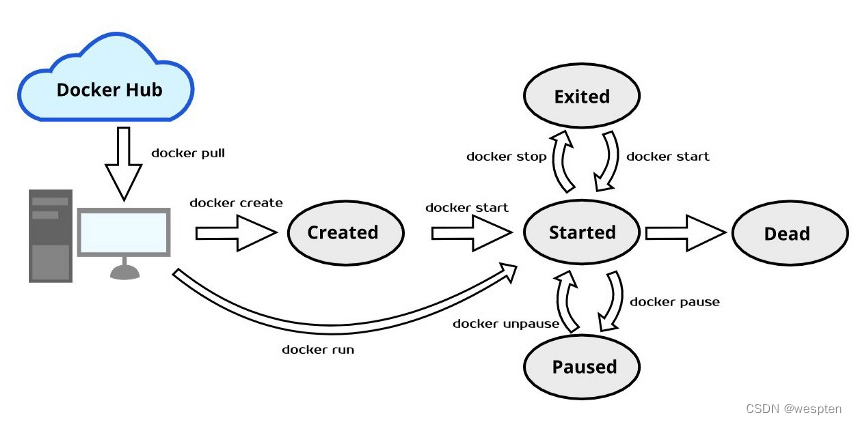
容器的五种状态:
1. created:初建状态
2. running:运行状态
3. stopped:停止状态
4. paused: 暂停状态
5. deleted: 删除状态
容器在执行某种命令后进入的过度状态:
docker create : 创建容器后,不立即启动运行,容器进入初建状态;
docker run : 创建容器,并立即启动运行,进入运行状态;
docker start : 容器转为运行状态;
docker stop : 容器将转入停止状态;
docker kill : 容器在故障(死机)时,执行 kill(断电),容器转入停止状态,这种操作容易丢失数据,
除非必要,否则不建议使用;
docker restart : 重启容器,容器转入运行状态;
docker pause : 容器进入暂停状态;
docker unpause : 取消暂停状态,容器进入运行状态;
docker rm : 删除容器,容器转入删除状态(如果没有保存相应的数据库,则状态不可见);完整生命周期图如下:
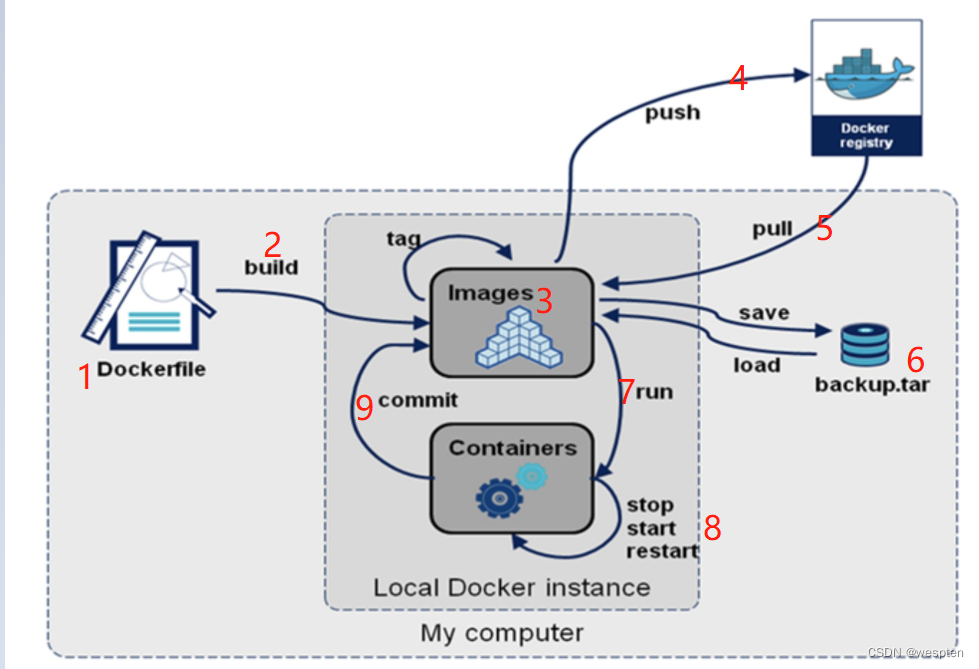
下面详细解释一下各个过程:
1. Dockerfile:一个用于构建docker image的脚本(这个我们暂时还不会用到);Dockerfile其实就是一个脚本文件,作用是自定义一个docker镜像。回想一下上一节讲的Nginx镜像,我们是从仓库里面pull拉取下来的,也就是说Nginx镜像是官方提供好的,我们可以直接拿来用的;但是如果我们想在本地自定义的构建一个镜像呢?就得需要使用Dockerfile自己去写了;
2. 通过build命令(docker build)可以构建dockerfile生成镜像image;我们生成的的镜像文件被images所管理;
3. 在images中,我们可以通过docker images命令来查看有哪些镜像文件。images是存储在机器本地的;但是在本地存着就没办法跟别人交互;
4. 如果想让本地的镜像文件和别人进行交互,就得通过网络并利用docker push命令传输到镜像仓库(Docker registry)中;镜像仓库类型有公开仓库(docker hub)和私有仓库(自行搭建);
5. 我们还可以从镜像仓库中获取我们想要的镜像,即docker pull;例如我们前面上一节讲到的从镜像仓库中获取Nginx镜像:docker pull Nginx就是一个例子;
6. 除了利用push和pull实现在网络中管理镜像,我们还可以利用save和load实现在本地管理镜像;docker save可以用于导出镜像为一个压缩文件;docker load可以用于导入镜像;这两个操作的作用主要是用于我们在公司工作过程中,和同事之间传递、分享镜像文件;
7. 利用run命令(docker run),我们可以将镜像运行出一个具体的容器(containers),这个过程我们在上一节也利用Nginx演示过了;
8. 在容器(containers)内部,我们可以利用stop、start、restart等命令对容器进行操作了;docker stop +容器id/名字:停止容器;docker start +容器id/名字:启动容器;docker restart +容器id/名字:重启容器;
9. 最后,commit的作用:当我们再容器中,进行新增或者修改等操作,定制安装了一些软件,并想要提交该容器生成一个镜像时,就要用到commit了(命令为docker commit +容器id);
[root@localhost ~]# docker commit
"docker commit" requires at least 1 and at most 2 arguments.
See 'docker commit --help'.
Usage: docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
Create a new image from a container's changes举个例子:
我们获取了一个centos镜像,且是最小化安装的,连vim都没有,我们先(docker run centos)运行这个容器,运行这个容器时,我们是可以进入到容器内的,假设我们在容器内安装了一个vim,此时我们利用docker commit 容器id提交该容器,提交后生成的镜像就是携带了vim 的centos系统了;以后我们再次docker run此镜像生成的容器,就是携带vim的容器了。
三、Docker安装与容器操作命令
Docker Engine 是 docker 容器和核心组件,官方提供了社区版本(Community Edition, CE)和企业版本(Enterprise Edition,EE)。官方还提供了除引擎之外的其他服务:Docker Hub、Docker Cloud等。
- Docker引擎: 包括支持在桌面系统或云平台安装Docker, 以及为企业提供简单安全弹性的容器集群编排和管理;
- dockerhub: 官网提供的云托管服务, 可以提供公有或私有的镜像仓库;
- DockerCloud: 官网提供的容器云服务, 可以完成容器的部署与管理, 可以完整地支持容器化项目, 还有CI、 CD功能。
1、Docker安装
注:本系列都是使用 CentOS7,运行 Docker。
1. 安装 yum 源
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo2. 安装 docker 社区版
sudo yum install docker-ce docker-ce-cli containerd.io3. 启动 docker 服务
sudo systemctl start docker4. 验证
docker run hello-world执行成功会输出 Hello from docker!
2、删除 docker
删除 docker 的命令为:
sudo yum remove docker-ce删除 docker 后,它对应的配置信息和镜像、卷等文件不会删除,可以使用以下命令清除:
sudo rm -rf /var/lib/docker注:其他系统上的安装方式这里就不详细说明了,详情请参考官方:Docker Documentation | Docker Documentation
3、配置 docker 服务
为了避免每次使用Docker命令时都需要切换到特权身份, 可以将当前用户加入安装中自动创建的docker用户组, 代码如下:
sudo usermod -aG docker USER_NAMEDocker 服务启动时实际上是调用了 dockerd 命令, 支持多种启动参数。因此, 用户可以直接通过执行dockerd 命令来启动Docker服务, 如下面的命令启动Docker服务, 开启Debug模式, 并监听在本地的2376端口:
dockerd -D -H tcp://127.0.0.1:2376这些选项可以写入/etc/docker/路径下的daemon.json文件中, 由dockerd 服务启动时读取:
{
"debug": true,
"hosts": ["tcp://127.0.0.1:2376"]
}当然, 操作系统也对Docker服务进行了封装, 以使用Upstart 来管理启动服务的 Ubuntu 系统为例, Docker服务的默认配置文件为/etc/default/docker, 可以通过修改其中的DOCKER_OPTS来修改服务启动的参数, 例如让Docker服务开启网络2375端口的监听:
DOCKER_OPTS="$DOCKER_OPTS -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock"设置overlay2为默认存储驱动,并配置加速器:
mkdir -p /etc/docker/
cat >/etc/docker/daemon.json <<EOF
{
"exec-opts":["native.cgroupdriver=systemd"],
"registry-mirrors":["https://hjvrgh7a.mirror.aliyuncs.com"],
"log-driver":"json-file",
"log-opts":{
"max-size":"100m"
},
"insecure-registries":["harbor.i4t.com"],
"storage-driver":"overlay2"
}
EOF这里配置当时镜像加速器,添加我们harbor仓库,可以不进行配置,但是建议配置。默认docker hub需要https协议,使用上面配置不需要配置https。
修改之后, 来重启Docker服务,并设置docker开机启动:
sudo systemctl enable --Now docker手动设置docker命令补全:
yum install -y epel-release bash-completion && cp /usr/share/bash-completion/completions/docker /etc/bash_completion.d/对于CentOS、 RedHat等系统, 服务通过systemd来管理, 配置文件路径为 /etc/systemd/system/docker.service.d/docker.conf 。 更新配置后需要通过 systemctl 命令来管理Docker服务:
sudo systemctl daemon-reload
sudo systemctl start docker.service此外, 如果服务工作不正常, 可以通过查看Docker服务的日志信息来确定问题, 例如在RedHat系统上日志文件可能为/var/log/messages, 在Ubuntu或CentOS系统上可以执行命令journalctl-u docker.service。每次重启Docker服务后, 可以通过查看Docker信息(docker info 命令) , 确保服务已经正常运行。
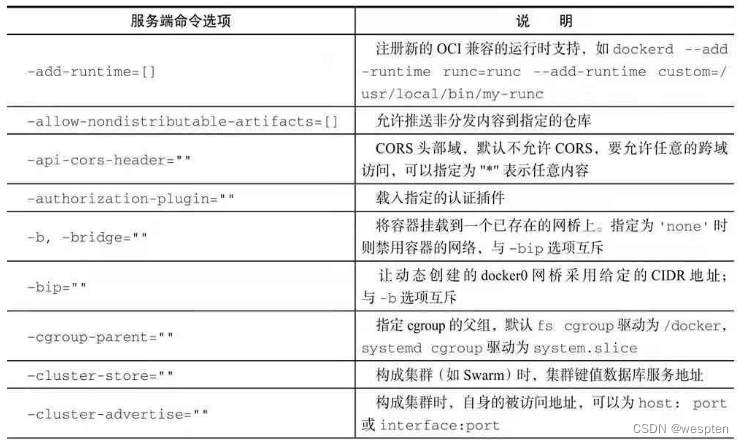
dockerd启动服务端主进程支持的命令选项如下:


4、容器操作命令
docker 的容器是镜像的一个运行实例。docker 镜像是只读文件,而容器则带有运行时的可读写层,而且容器中的应用进程处于运行状态。接下来我们就来学习 docker 容器的具体操作。
1)创建容器
创建容器相关的命令有 create、start、run、wait 和 logs。
使用命令 docker [container] create 新建一个容器:
# docker create -it ubuntu:latest
63197c11dc16e893dc8bb032ebf92419032cc40d6dcb6f750a16e9e308d52584
# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
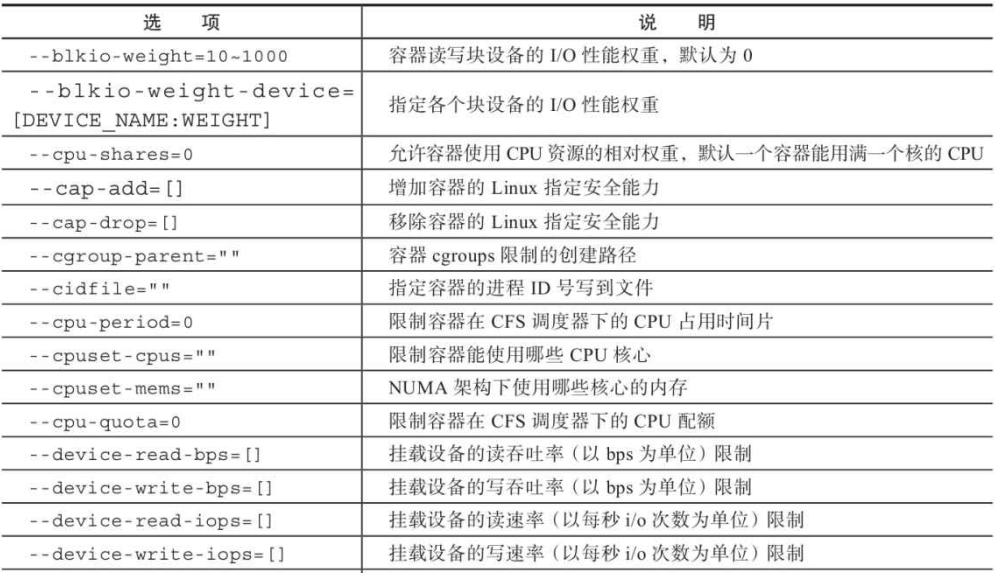
63197c11dc16 ubuntu:latest "/bin/bash" 5 seconds ago Created hardcore_ramandocker create命令对应的参数有很多,create 命令与容器运行模式相关的选项,下面列出对应的选项:

create命令与容器环境和配置相关的选项:

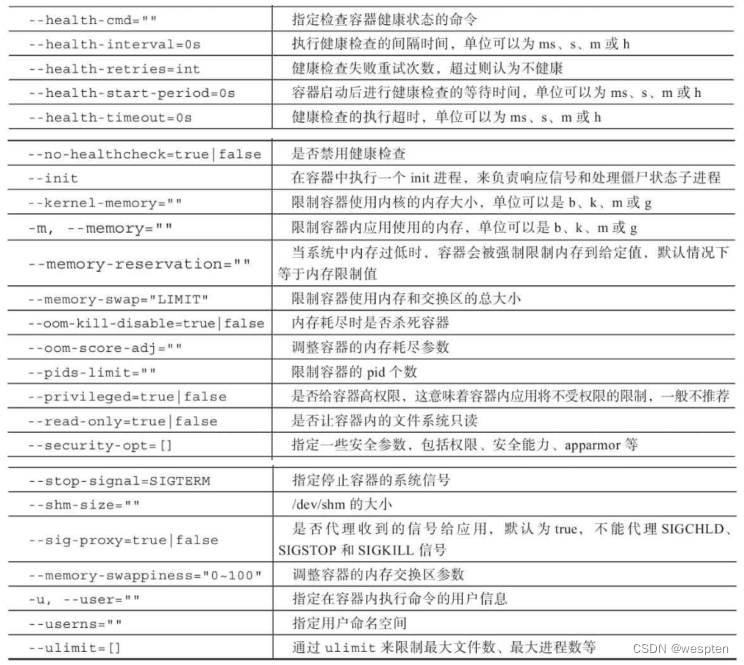
create 命令与容器资源限制和安全保护相关的选项:
以及:
2)启动容器
使用该命令新建的容器处于停止状态,使用命令 docker [container] start启动容器,通过 docker [container] ps查看运行中的容器:
# docker start 63197c11dc16e893dc8bb032ebf92419032cc40d6dcb6f750a16e9e308d52584
63197c11dc16e893dc8bb032ebf92419032cc40d6dcb6f750a16e9e308d52584
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
63197c11dc16 ubuntu:latest "/bin/bash" About a minute ago Up 3 seconds hardcore_raman我们还可以将新建和启动容器合起来,命令 docker [container] run 就是两个命令的组合:
# docker run ubuntu /bin/echo "Hello World"
Hello World
# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5982bad8cf83 ubuntu "/bin/echo 'Hello Wo…" 7 seconds ago Exited (0) 6 seconds ago exciting_lalandedocker run参数
docker run 启动容器,可以指定参数设置容器启动策略,如下:
- -d 容器会在后台运行并不会把输出(STDOUT)打印到宿主机上;
- -t 让docker分配一个伪终端并绑定到容器的标准输入上;
- -i 让容器的标准输入保持打开;
- -p 映射本地端口和容器端口,格式为-p ip:hostPort:containerPort或者-p hostPort:containerPort;
- -P 大写的P,使用 -P 标记时,Docker 会随机映射一个 49000~49900 的端口到内部容器开放的网络端口;
- --rm 在容器执行完毕后将其删除,默认只能删除已停止的容器,如果想要删除正在运行中容器,可增加-f参数;
- --name xxx 执行容器的name;
注意,容器是否会长久运行,是和docker run指定的命令有关,和 -d 参数无关。
使用 run 命令实际上在后台包含了以下过程:
- 检查本地是否存在指定的镜像, 不存在就从公有仓库下载;
- 利用镜像创建一个容器, 并启动该容器;
- 分配一个文件系统给容器, 并在只读的镜像层外面挂载一层可读写层;
- 从宿主主机配置的网桥接口中桥接一个虚拟接口到容器中去;
- 从网桥的地址池配置一个IP地址给容器;
- 执行用户指定的应用程序;
- 执行完毕后容器被自动终止。
注:运行结束后容器就会停止。
还可以在创建时启动一个 bash 终端,这样就能和容器交互了:
# docker run -it ubuntu bash
root@264cf6ed894e:/# - -t:选项让Docker分配一个伪终端(pseudo-tty) 并绑定到容器的标准输入上。
- -i:则让容器的标准输入保持打开。
容器支持的重启策略包括 always、unless-stopped 和 on-Failed:
always 策略是一种简单的方式。除非容器被明确停止,比如通过 docker container stop 命令,否则该策略会一直尝试重启处于停止状态的容器。一种简单的证明方式是启动一个新的交互式容器,并在命令后面指定 --restart always 策略,同时在命令中指定运行 Shell 进程。
当容器启动的时候,会登录到该 Shell,退出 Shell 时会杀死容器中 PID 为 1 的进程,并且杀死这个容器。但是因为指定了 --restart always 策略,所以容器会自动重启。如果运行 docker container ls 命令,就会看到容器的启动时间小于创建时间。
$ docker container run --name neversaydie -it --restart always alpine sh
//等待几秒后输入exit
/# exit
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS
0901afb84439 alpine "sh" 35 seconds ago Up 1 second容器于 35s 前被创建,但却在 1s 前才启动。这是因为在容器中输入退出命令的时候,容器被杀死,然后 Docker 又重新启动了该容器。
--restart always 策略有一个很有意思的特性,当 daemon 重启的时候,停止的容器也会被重启。
例如,新创建一个容器并指定 --restart always 策略,然后通过 docker container stop命令停止该容器,现在容器处于 Stopped (Exited) 状态。但是,如果重启 Docker daemon,当 daemon 启动完时,该容器也会重新启动。
always 和 unless-stopped 的最大区别,就是那些指定了 --restart unless-stopped 并处于 Stopped (Exited) 状态的容器,不会在 Docker daemon 重启的时候被重启。
下面创建两个新容器,其中“always”容器指定 --restart always 策略,另一个“unless- stopped”容器指定了 --restart unless-stopped 策略:
$ docker container run -d --name always \
--restart always \
alpine sleep 1d
$ docker container run -d --name unless-stopped \
--restart unless-stopped \
alpine sleep 1d
$ docker container ls
CONTAINER ID IMAGE COMMAND STATUS NAMES
3142bd91ecc4 alpine "sleep 1d" Up 2 secs unless-stopped
4f1b431ac729 alpine "sleep 1d" Up 17 secs always两个容器均通过 docker container stop 命令停止,接着重启 Docker。结果“always”容器会重启,但是“unless-stopped”容器不会。
$ docker container stop always unless-stopped
$ docker container ls -a
CONTAINER ID IMAGE STATUS NAMES
3142bd91ecc4 alpine Exited (137) 3 seconds ago unless-stopped
4f1b431ac729 alpine Exited (137) 3 seconds ago always
$ systemlctl restart docker
$ docker container ls -a
CONTAINER CREATED STATUS NAMES
314..cc4 2 minutes ago Exited (137) 2 minutes ago unless-stopped
4f1..729 2 minutes ago Up 9 seconds always注意到“always”容器(启动时指定了 --restart always 策略)已经重启了,但是“unless-stopped”容器(启动时指定了 --restart unless-stopped 策略)并没有重启。
on-failure 策略会在退出容器并且返回值不是 0 的时候,重启容器。就算容器处于 stopped 状态,在 Docker daemon 重启的时候,容器也会被重启。
如果使用 Docker Compose 或者 Docker Stack,可以在 service 对象中配置重启策略,例如:
version: "3.5"
services:
myservice:
<Snip>
restart_policy:
condition: always | unless-stopped | on-failure3)退出容器
用户可以按 Ctrl+d 或输入 exit 命令来退出容器,也可以使用命令 docker container wait CONTAINER[CONTAINER...] 命令来等待容器退出, 并打印退出返回结果。
root@264cf6ed894e:/# exit
exit- 125: Docker daemon执行出错, 例如指定了不支持的Docker命令参数;
- 126: 所指定命令无法执行, 例如权限出错;
- 127: 容器内命令无法找到。
4)后台运行
docker container run -it 创建一个容器并进入交互式模式:
➜ ~ docker container run -it busyBox sh
/ #
/ #
/ # ls
bin dev etc home proc root sys tmp usr var
/ # ps
PID USER TIME COMMAND
1 root 0:00 sh
8 root 0:00 ps
/ # exitdocker container exec -it 在一个已经运行的容器里执行一个额外的command:
➜ ~ docker container run -d Nginx
33d2ee50cfc46b5ee0b290f6ad75d724551be50217f691e68d15722328f11ef6
➜ ~
➜ ~ docker container exec -it 33d sh
#
#
# ls
bin boot dev docker-entrypoint.d docker-entrypoint.sh etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
#
# exit
➜ ~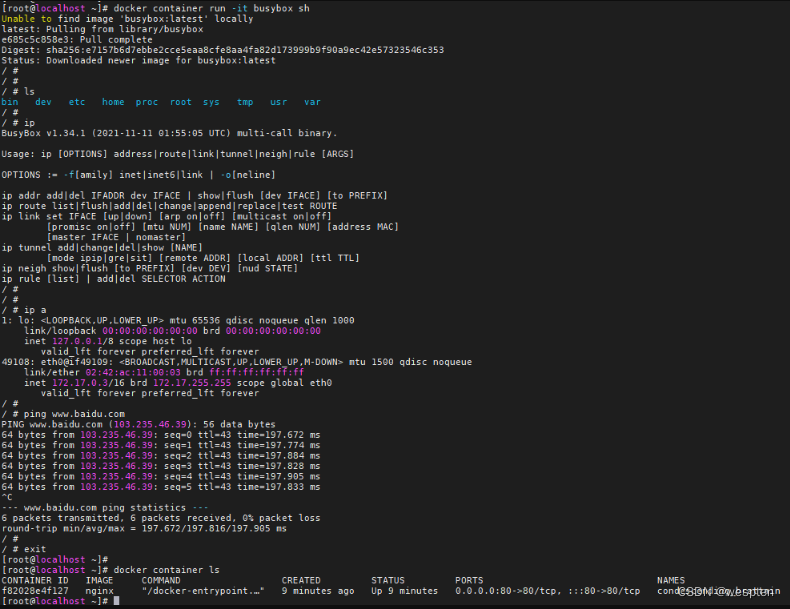
如果需要让容器在后台以守护态(Daemonized) 形式运行,可以通过 -d 参数实现:
# docker run -itd ubuntu /bin/bash -c "while true; do echo hello world; sleep 1; done"
5352f3e531b2f451ec6b484a6d35d1fd064438fa3d3404691b80b98bbc6e7801它会返回一个唯一的id值,使用 docker ps 或 docker container ls 来查看容器信息:
# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5352f3e531b2 ubuntu "/bin/bash -c 'while…" 2 minutes ago Up 2 minutes lucid_albattani5)查看容器输出
刚才通过 -d 让容器以后台方式运行,我们没有看到它的输出信息,可以使用命令docker [container] logs命令查看,该命令包含以下选项:
- -details: 打印详细信息;
- -f, -follow: 持续实时实时查看日志;
- -since string: 输出从某个时间开始的日志;
- -tail string: 输出最近的若干日志;
- -t, -timestamps:显示时间戳信息;·-until string: 输出某个时间之前的日志。
# docker logs 5352f3e531b2
hello world注:创建容器后会返回一个唯一的id,但一般我们截取字符前面的一部分,保证能认到这个容器就可以了。
6)暂停容器
使用命令docker [container] pause CONTAINER[CONTAINER...]来暂停一个运行中的容器。
# docker run --name test --rm -itd ubuntu bash
c1a52ffc5f662b2e60bcd98fe81157754cb251b22a624e8a6a32785905d5b93e
# docker pause c1a52ffc5
c1a52ffc5
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c1a52ffc5f66 ubuntu "bash" 16 seconds ago Up 16 seconds (Paused) test出于 paused 状态的容器就可以使用 docker [container] unpause CONTAINER[CONTAINER...] 命令来恢复了。
7)停止容器
容器正在运行 /bin/bash 应用。当使用 docker container rm <container> -f来销毁运行中的容器时,不会发出任何告警。毫无征兆地被销毁,会令容器和应用猝不及防,来不及“处理后事”。
但是,docker container stop 命令就有礼貌多了,该命令给容器内进程发送将要停止的警告信息,给进程机会来有序处理停止前要做的事情。一旦 docker stop 命令返回后,就可以使用 docker container rm 命令删除容器了。
docker container stop 命令向容器内的 PID 1 进程发送了 SIGTERM 这样的信号,会为进程预留一个清理并优雅停止的机会。如果 10s 内进程没有终止,那么就会收到 SIGKILL 信号,进程起码有 10s 的时间来“解决”自己。
使用命令docker [container] stop [-t|--time[=10]] [CONTAINER...] 停止容器:
# docker stop 5352f3e531b2
5352f3e531b2现在使用命令 docker container prune 会删除所有处于停止状态的容器。
除了 stop 外,使用命令docker [container] kill或在交互模式下通过命令exit或Ctrl+d都可以停止容器。属于停止状态的容器,可以使用命令 docker [container] start 来启动,或者是命令 docker [container] restart 来先停止再启动。
8)进入容器
容器运行过程中,常常需要进入容器中执行操作场景,可使用如下命令进入容器:
attach:使用命令docker attach containerId/names进入容器,但是使用 attach 命令有时候并不方便。当多个窗口同时 attach 到同一个容器的时候,所有窗口都会同步显示,当某个窗口因命令阻塞时,其他窗口也无法执行操作了。注意,进入容器后,如果使用exit退出容器,那么容器也会停止运行,可以使用命令Ctrl+P+Q来退出但不关闭容器。

命令行的输入会直接传到docker容器里面,比如Linux系统中运行容器时输入ctrl+c便会停止容器运行,不推荐使用attach模式。
nsenter:nsenter 启动一个新的shell进程(默认是/bin/bash),同时会把这个新进程切换到和目标(target)进程相同的命名空间,这样就相当于进入了容器内部,nsenter 要正常工作需要有 root 权限。
exec:使用exec命令更加便捷,docker exec -it 775c7c9ee1e1 /bin/bash ,很方便的进入容器。
当容器在后台运行时,使用 docker [container] exec 命令可以进入容器中,支持的参数有:
- -d, --detach: 在容器中后台执行命令;
- --detach-keys="": 指定将容器切回后台的按键;
- -e, --env=[]: 指定环境变量列表;
- -i, --interactive=true|false: 打开标准输入接受用户输入命令, 默认值为false;
- --privileged=true|false: 是否给执行命令以权限, 默认值为false;
- -t, --tty=true|false: 分配伪终端, 默认值为false;
- -u, --user="": 执行命令的用户名或ID。
# docker exec -it 5352f3e531b2 /bin/bash9)删除容器
删除容器则是使用命令 docker [container] rm,命令的格式为 docker [container] rm [-f|--force] [-l|--link] [-v|--volumes] CONTAINER [CONTAINER...],支持以下选项:
- -f, --force=false: 是否强制终止并删除一个运行中的容器;
- -l, --link=false: 删除容器的连接, 但保留容器;
- -v, --volumes=false: 删除容器挂载的数据卷
# docker rm -f 5352f3e531b2
5352f3e531b2使用 docker rm 命令只能删除处于停止状态或退出状态的容器,并不能删除还在运行状态中的容器。但是使用选项 -f 可以删除,Docker会先发送SIGKILL信号给容器, 终止其中的应用, 之后强制删除。
10)导出容器
有时我们需要将运行中的容器在不同的机器上拷贝,docker 则实现了容器的导入和导出功能。
导出使用命令为 docker [container] export,命令格式为 docker [container] export [-o|--output[=""]] CONTAINER:
# docker export -o ubuntu.tar 6f71e82ba8b1
[root@CentOS1 ~]# ls
anaconda-ks.cfg dockerfile ubuntu.tar导出后的容器就可以直接复制到其他机器上导入运行了。
11)导入容器
使用命令 docker [container] import 则可以导入容器,格式为 docker import [-c|--change[=[]]] [-m|--message[=MESSAGE]] file|URL|-[REPOSITORY[:TAG]]:
# docker import ubuntu.tar test/ubuntu:v1.0
sha256:6ccd40df1a76c15233708df3446fb97621f05826b2f0e4780aac29f5afaf76a7
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
test/ubuntu v1.0 6ccd40df1a76 7 seconds ago 69.9MB可以使用docker load命令来导入镜像存储文件到本地镜像库, 也可以使用docker[container]import命令来导入一个容器快照到本地镜像库。
这两者的区别在于: 容器快照文件将丢弃所有的历史记录和元数据信息(即仅保存容器当时的快照状态) ,而镜像存储文件将保存完整记录, 体积更大。 此外, 从容器快照文件导入时可以重新指定标签等元数据信息。
12)查看容器
查看容器有 inspect、ls、top 和 stats 子命令。
使用命令 docker container inspect [OPTIONS] CONTAINER [CONTAINER...] 查看容器详情:
# docker inspect 6f71e82ba8b129e54dd315d79ef4
[
{
"Id": "6f71e82ba8b129e54dd315d79ef4ec49fc3b26cd60102adcebe8b8a39c05dd3f",
"Created": "2019-08-21T13:22:23.432469852Z",
"Path": "/bin/bash"
...
}
]该命令会以 json 格式返回包括容器Id、 创建时间、 路径、 状态、 镜像、 配置等在内的各项信息。
可以使用 docker container ls 命令来观察当前系统正在运行的容器列表:
$ docker container ls
CNTNR ID IMAGE COMMAND CREATED STATUS NAMES
302...74 ubuntu:latest /bin/bash 6 mins Up 6mins sick_montalcini使用命令 docker [container] top [OPTIONS] CONTAINER [CONTAINER...] 查看容器内进程:
# docker container top 6f71e82b
UID PID PPID C STIME TTY TIME CMD
root 16395 16376 0 08:12 pts/0 00:00:00 /bin/bash这个命令类似于Linux系统中的 top 命令, 会打印出容器内的进程信息, 包括PID、 用户、 时间、 命令等:

使用命令 docker[container] stats [OPTIONS] [CONTAINER...] 查看容器统计信息。
- -a, -all: 输出所有容器统计信息, 默认仅在运行中;
- --format string: 格式化输出信息;
- --no-stream: 不持续输出, 默认会自动更新持续实时结果;
- --no-trunc: 不截断输出信息;
13)其他命令
除此之外,docker 容器还支持其他类型的命令,如 cp、diff、port 和 update 子命令。
① cp
该命令支持在容器和主机之间复制文件。命令格式为 docker [container] cp [OPTIONS] CONTAINER: SRC_PATH DEST_PATH|-,支持的选项:
- -a, -archive: 打包模式, 复制文件会带有原始的uid/gid信息;
- -L, -follow-link: 跟随软连接。 当原路径为软连接时, 默认只复制链接信息, 使用该选项会复制链接到的内容。
docker container cp /etc/passwd 6f71e82ba8b1:/tmp/② diff
diff 查看容器内文件系统的变更,格式为 docker[container]diff CONTAINER :
# docker container diff 6f71e82ba8b1
C /tmp
A /tmp/passwd因为上面将文件复制到容器中,所以看到容器的文件系统发生了变化,C 为 改变,A 为追加。
③ port
port 用来查看容器的端口映射情况,命令格式为 docker container port CONTAINER [PRIVATE_PORT [/PROTO]]:
# docker container port 07a4e1582bd1
3306/tcp -> 0.0.0.0:3306④ update
update 可以更新容器运行时配置,命令格式为 docker [container] update [OPTIONS] CONTAINER [CONTAINER...],支持选项有:
- --blkio-weight uint16: 更新块IO限制, 10~1000, 默认值为0, 代表着无限制;
- --cpu-period int: 限制cpu调度器CFS(Completely Fair Scheduler) 使用时间, 单位为微秒, 最小1000;
- --cpu-quota int: 限制cpu调度器CFS配额, 单位为微秒, 最小1000;
- --cpu-rt-period int: 限制cpu调度器的实时周期, 单位为微秒;
- --cpu-rt-runtime int: 限制cpu调度器的实时运行时, 单位为微秒;
- -c, -cpu-shares int: 限制cpu使用份额;
- --cpus decimal: 限制cpu个数;
- --cpuset-cpus string: 允许使用的cpu核, 如0-3, 0, 1;
- --cpuset-mems string: 允许使用的内存块, 如0-3, 0, 1;
- --kernel-memory bytes: 限制使用的内核内存;
- -m, -memory bytes: 限制使用的内存;
- --memory-reservation bytes: 内存软限制;
- --memory-swap bytes: 内存加上缓存区的限制, -1表示为对缓冲区无限制;
- --restart string: 容器退出后的重启策略
比如限制 docker 容器的内存和cpu:
# docker container update -m 1g --memory-swap 1g --cpus 1 6f71e82ba8b1
6f71e82ba8b1四、Docker镜像与仓库管理
1、获取镜像
docker 获取镜像使用的命令为:docker [image] pull NAME[: TAG]。
例如我们获取一个 Ubuntu18.04 系统的基础镜像,就可以使用命令:
docker pull ubuntu:18.04如果不指定版本,默认就拉取最新的版本 ubuntu:latest:
docker pull ubuntu从Quay上拉取镜像:
$ docker pull quay.io/bitnami/ubuntu
Using default tag: latest
latest: Pulling from bitnami/Nginx
2e6370f1e2d3: Pull complete
2d464c695e97: Pull complete
83eb3b1671f4: Pull complete
364c139450f9: Pull complete一般来说,镜像的 latest 表示该镜像内容为最新,出于稳定性考虑,不要在生产中使用最新版本的,最好拉取是带上版本号。
使用docker pull命令下载中会获取并输出镜像的各层信息。 当不同的镜像包括相同的层时, 本地仅存储了层的文份内容, 减少了存储空间。
如果我们要从指定的仓库中拉取,可以通过补全镜像的路径实现,例如从网易上拉取 ubuntu18.04,命令如下:
docker pull hub.c.163.com/public/ubuntu:18.04一般在国内,拉取官方的镜像速度,所以我们可以改成默认从国内云服务供应商的仓库上拉取,比如阿里云的。
# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"]
}下载了镜像后,我们就可以使用它了:
# docker run -it ubuntu:18.04 bash
root@fe3ce439f6dc:/# echo "Hello World"
Hello World
root@fe3ce439f6dc:/# exit2、查看镜像
查看镜像主要使用 docker 的 ls、tag、inspect子命令:
1)images 子命令
使用 images 列出所有镜像:
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu 18.04 a2a15febcdf3 5 days ago 64.2MB
redis latest f7302e4ab3a8 5 days ago 98.2MB我们来说明下输出的信息:
- REPOSITORY:来自于哪个仓库, 比如ubuntu表示ubuntu系列的基础镜像;
- TAG:镜像的标签信息, 比如18.04、 latest表示不同的版本信息。 标签只是标记, 并不能标识镜像内容;
- IMAGE ID:镜像的ID(唯⼀标识镜像) , 如果两个镜像的ID相同, 说明它们实际上指向了同一个镜像, 只是具有不同标签名称而已;
- CREATED:创建时间, 说明镜像最后的更新时间;
- SIZE:镜像大小, 优秀的镜像往往体积都较小。
images命令主要支持如下选项:
- -a, --all=true|false: 列出所有(包括临时文件) 镜像文件, 默认为否;
- --digests=true|false: 列出镜像的数字摘要值, 默认为否;
- -f, --filter=[]: 过滤列出的镜像, 如dangling=true只显出没有被使用的镜像; 也可指定带有特定标注的镜像等;
- --format="TEMPLATE": 控制输出格式, 如.ID代表ID信息, .Repository代表仓库信息等;
- --no-trunc=true|false: 对输出结果中太长的部分是否进行截断, 如镜像的ID信息, 默认为是;
- -q, --quiet=true|false: 仅输出ID信息, 默认为否。
$ docker image inspect 94b72494607b
[
{
"Id": "sha256:94b72494607b406caa2e2c0f3d79d6c49fd4d65fd56688ec0171a1f2b356bb2d",
"RepoTags": [
"quay.io/bitnami/Nginx:latest"
],
"RepoDigests": [
"quay.io/bitnami/Nginx@sha256:0caf2be99c1f13a6a5c5c7c38c1e472b413ca62160d3be2cfd0d30d62af7d8f5"
],
"Parent": "",
"Comment": "",
"Created": "2021-11-23T02:18:43.577193295Z",
"Container": "e51d3aaafbf51cd81b13cf1d8ac5f3a733b3ab1e9086f13030d27a9a5f14c503",
"ContainerConfig": {
"Hostname": "e51d3aaafbf5",
"Domainname": "",
"User": "1001",
"AttachStdin": false,
"AttachStdout": false,
"AttachStderr": false,
"ExposedPorts": {
"8080/tcp": {},
"8443/tcp": {}
},
"Tty": false,
"OpenStdin": false,
"StdinOnce": false,
"Env": [
"PATH=/opt/bitnami/common/bin:/opt/bitnami/Nginx/sbin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"HOME=/",
"OS_ARCH=amd64",
"OS_FLAVOUR=debian-10",
"OS_NAME=linux",
"BITNAMI_APP_NAME=Nginx",
"BITNAMI_IMAGE_VERSION=1.21.4-debian-10-r19",
"Nginx_ENABLE_CUSTOM_PORTS=no",
"Nginx_HTTPS_PORT_NUMBER=",
"Nginx_HTTP_PORT_NUMBER="
],
...其中, 还支持对输出结果进行控制的选项, 如-f.--filter=[]、 --notrunc=true|false、 -q、 --quiet=true|false等
2)tag 子命令
[root@CentOS1 ~]# docker tag ubuntu:18.04 myubuntu:18.04
[root@CentOS1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
myubuntu 18.04 a2a15febcdf3 5 days ago 64.2MB
ubuntu 18.04 a2a15febcdf3 5 days ago 64.2MB如果细节看的话会发现 ubuntu 和 myubuntu 的 IMAGE ID 是一样的,因为 tag 子命令其实是给原来的镜像添加了别名,内部指向同一个文件,所以删除其中的某一个,只是删除一个链接而已,实际的镜像文件依然存在。
3)inspect 子命令
使用 inspect 子命令来查看镜像的详细信息:docker [image] inspect:
docker inspect ubuntu返回 JSON 格式的消息,如果只要其中一项内容,可以使用 -f 指定:
docker inspect -f {{".Architecture"}} ubuntu4)history 子命令
使用 history 子命令查看镜像的历史命令:
[root@localhost ~]# docker history insaneloafer/hello:1.0
Or
[root@localhost ~]# docker image history insaneloafer/hello:1.0
IMAGE CREATED CREATED BY SIZE COMMENT
e3a733c6921a 24 hours ago /bin/sh -c #(nop) CMD ["python3" "/hello.py… 0B
<missing> 24 hours ago /bin/sh -c #(nop) ADD file:d739451e741e82c2f… 22B
<missing> 24 hours ago /bin/sh -c apt-get update && DEBIAN_FRON… 127MB
<missing> 7 weeks ago /bin/sh -c #(nop) CMD ["bash"] 0B
<missing> 7 weeks ago /bin/sh -c #(nop) ADD file:3a18768000089a105… 80MB3、搜寻镜像
使用 search 子命令可以在仓库中搜寻我们需要的镜像,语法为 docker search [option] keyword,支持的命令选项主要包括:
- -f, --filter filter: 过滤输出内容;
- --format string: 格式化输出内容;
- --limit int: 限制输出结果个数, 默认为25个;
- --no-trunc: 不截断输出结果。
例如我们搜寻名为 Nginx 的镜像:
docker search --limit=4 --filter=starts=4 Nginx4、删除镜像
删除镜像使用 docker rmi 或者 docker images rm,语法为 docker rmi IMAGE[IMAGE...],其中IMAGE可以为标签或ID。支持选项包括:
docker rmi myubuntu:latest当该镜像存在容器时,不能删除镜像,但可以加上 -f 选项强制删除,同时也删除容器。当一个镜像有多个 tag 时,docker rmi 只是删除该镜像的标签,不会影响到镜像文件。
正在运行的container和停止掉但是没有删除的container,不能删除其image:

5、清理镜像
使用Docker一段时间后, 系统中可能会遗留一些临时的镜像文件, 以及一些没有被使用的镜像, 可以通过docker image prune命令来进行清理。支持选项包括:
# docker image prune -f
Total reclaimed space: 0B6、创建镜像
创建 docker 镜像的方法有三种:基于已有镜像的容器创建、 基于本地模板导入、 基于Dockerfile创建。
1)基于已有镜像的容器创建
使用命令 docker [container] commit 命令,语法为 docker [container] commit [OPTIONS] CONTAINER [REPOSITORY[: TAG]]。主要选项包括:
- -a, --author="": 作者信息;
- -c, --change=[]: 提交的时候执行Dockerfile指令, 包括CMD|ENTRYPOINT|ENV|EXPOSE|LABEL|ONBUILD|USER|VOLUME|workdir等;
- -m, --message="": 提交消息;
- -p, --pause=true: 提交时暂停容器运行。
下面我们尝试下:首先启动一个镜像,在镜像中做一些修改,之后用修改过的容器创建镜像。
# docker run -it ubuntu:latest bash
root@a93ecdb26b77:/# echo "hello world" > test
root@a93ecdb26b77:/# exit
exit
# docker commit -m "Added test" -a "xingyys" a93ecdb26b77 test
sha256:5f538a96c081d2f64356cd64eb38f7cc0b6987bb07ba283032796c8c7dc2cf2f2)基于本地模板导入
用户也可以直接从一个操作系统模板文件导入一个镜像, 主要使用docker [container] import 命令。
命令格式为 docker [image] import [OPTIONS] file | URL | - [REPOSITORY[: TAG]]:
cat ubuntu-18.04-x86_64-minimal.tar.gz | docker import - ubuntu:18.043)基于Dockerfile创建
基于Dockerfile创建是最常见的方式。 Dockerfile是一个文本文件,利用 docker 的指令能快速制作一个镜像。
下面给出一个简单的实例,基于基于debian: stretch-slim镜像安装Python 3环境, 构成一个新的python:3镜像。创建一个 dockerfile 文件,写入:
FROM debian:stretch-slim
LABEL version="1.0" maintainer="docker user <docker_user@github>"
RUN apt-get update && \
apt-get install -y python3 && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*使用docker[image]build命令创建, 编译成功后本地将多出一个python:3镜像:
docker [image] build -t python:3 .7、导出和载入镜像
docker 还提供了镜像的导出和载入。
使用命令 docker [image] save 导出镜像:
docker save -o ubuntu.tar ubuntu导出后的文件就可以复制到其他机器上载入了,对应的载入命令为 docker [image] load :
docker load -i ubuntu.tar或者是:
docker load < ubuntu.tar完整案例:
[root@localhost ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/bitnami/Nginx latest 94b72494607b 9 hours ago 90.5MB
busyBox latest 69593048aa3a 5 months ago 1.24MB
localhost:5002/busyBox v1.0 69593048aa3a 5 months ago 1.24MB
Nginx 1.20.0 7ab27dbbfbdf 6 months ago 133MB
[root@localhost ~]#
[root@localhost ~]# docker image save Nginx:1.20.0 -o Nginx.image
[root@localhost ~]#
[root@localhost ~]# ls
agent.jar Desktop Documents initial-setup-ks.cfg Music Nginx.image Public test_db-master Videos
anaconda-ks.cfg D:\JenkinsNode Downloads jenkins MysqL Pictures Templates test.txt
[root@localhost ~]#
[root@localhost ~]# docker image rm 7ab
Untagged: Nginx:1.20.0
Untagged: Nginx@sha256:ea4560b87ff03479670d15df426f7d02e30cb6340dcd3004cdfc048d6a1d54b4
Deleted: sha256:7ab27dbbfbdf4031f0603a4b597cc43031ff883b54f9329f0309c80952dda6f5
Deleted: sha256:5b2a9404d052ae4205f6139190fd4b0921ddeff17bf2aaf4ee97f79e1a8242fe
Deleted: sha256:03ebf76f0cbf5fd32ca010bb589c2139ce7e44c050fe3de2d77addf4cfd25866
Deleted: sha256:0191669d087dce47072254a93fe55cbedd687f27d3798e2260f846e8f8f5729a
Deleted: sha256:17651c6a0ba04d31da14ac6a86d8fb3f600883f9e155558e8aad0b94aa6540a2
Deleted: sha256:5a673ff4c07a1b606f2ad1fc53697c99c45b0675734ca945e3bb2bd80f43feb8
Deleted: sha256:02c055ef67f5904019f43a41ea5f099996d8e7633749b6e606c400526b2c4b33
[root@localhost ~]#
[root@localhost ~]# docker image load -i Nginx.image
02c055ef67f5: Loading layer [==================================================>] 72.53MB/72.53MB
1839f9962bd8: Loading layer [==================================================>] 64.8MB/64.8MB
a2f4f809e04e: Loading layer [==================================================>] 3.072kB/3.072kB
9b63e6289fbe: Loading layer [==================================================>] 4.096kB/4.096kB
f7141923aaa3: Loading layer [==================================================>] 3.584kB/3.584kB
272bc57d3405: Loading layer [==================================================>] 7.168kB/7.168kB
Loaded image: Nginx:1.20.0
[root@localhost ~]#
[root@localhost ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/bitnami/Nginx latest 94b72494607b 9 hours ago 90.5MB
busyBox latest 69593048aa3a 5 months ago 1.24MB
localhost:5002/busyBox v1.0 69593048aa3a 5 months ago 1.24MB
Nginx 1.20.0 7ab27dbbfbdf 6 months ago 133MB8、上传镜像
push命令可以让我们将本地的镜像上传到仓库中。默认上传到Docker Hub官方仓库(需要登录)。
格式为: docker [image] push NAME[: TAG]|[REGISTRY_HOST[:REGISTRY_PORT]/]NAME[: TAG] 。
用户在Docker Hub网站注册后可以上传自制的镜像。例如, 用户user上传本地的test: latest镜像, 可以先添加新的标签 user/test: latest, 然后用 docker [image] push命令上传镜像:
# docker tag test:latest user/test:latest
# docker push user/test:latest
The push refers to a repository [docker.io/user/test]
Sending image list
Please login prior to push: Username: Password: Email:第一次上传时, 会提示输入登录信息或进行注册, 之后登录信息会记录到本地~/.docker目录下。
9、公共仓库
仓库(Responsitory)是集中存放镜像的地方,又分公共仓库和私有仓库。有时候容易把仓库与注册服务器(Registry) 混淆。 实际上注册服务器是存放仓库的具体服务器, 一个注册服务器上可以有多个仓库, 而每个仓库下都可以有多个镜像。
Docker Hub 是 docker 官方提供的最大的公共镜像仓库,地址为:Docker Hub
可以使用命令 docker login 来注册和登陆。
使用命令 docker search [IMAGE] 来搜索镜像:
# docker search centos
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
centos The official build of CentOS. 5520 [OK]
ansible/centos7-ansible Ansible on Centos7 122 [OK]
jdeathe/centos-ssh CentOS-6 6.10 x86_64 / CentOS-7 7.6.1810 x86… 111 [OK]上面显示的镜像分为两类:
- 一种是类似于centos这样的基础镜像, 也称为根镜像。 这些镜像是由Docker公司创建、 验证、 支持、 提供, 这样的镜像往往使用单个单词作为名字;
- 另一种类型的镜像, 例如ansible/centos7-ansible镜像, 是由Docker用户ansible创建并维护的, 带有用户名称为前缀, 表明是某用户下的某仓库。 可以通过用户名称前缀“user_name/镜像名”来指定使用某个用户提供的镜像。
使用命令 docker pull [IMAGE] 拉取镜像:
# docker pull centos10、第三方公共镜像
在国内也又一些的公有仓库,我们可以通过配置,让下载镜像的地址指向国内的源。这里选择阿里云,操作步骤如下:
1. 登陆阿里云,点击右上角的“管理中心”,点击进入后,点击“镜像加速器”,得到加速的地址。
2. 配置文件:
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://xxxxxx.mirror.aliyuncs.com"]
}3. 重启 docker
# systemctl restart docker11、搭建本地私有仓库
除了以上的公共仓库之外,在需要的时候我们也可以搭建私有的仓库。
安装 docker 后,可以通过官方提供的 registy 镜像来搭建本地私有仓库:
1. 下载镜像:
# docker pull registry 2. 启动镜像:
# docker run -d -p 5000:5000 registry 默认情况下, 仓库会被创建在容器的/var/lib/registry目录下。 可以通过-v参数来将镜像文件存放在本地的指定路径。
3. 管理仓库
通过 docker push命令来上传文件,将镜像上传本地的仓库前需要对镜像作一个特别的tag:
# docker tag cenntos 192.168.127.128:5000/centos
# docker push 172.7.15.113:5000/centos 把标记的镜像给推送到私有仓库,但此时并不会成功,并报错:
Get https://172.7.15.113:5000/v2/: http: server gave HTTP response to HTTPS client# vi /etc/docker/daemon.json
{
"insecure-registries":["192.168.127.128:5000"]
}重启服务,启动仓库容器:
# systemctl restart docker
# docker run container_id现在可以上传镜像了:
# docker push 192.168.127.128:5000/centos 查看上传的镜像:
# curl 192.168.127.128:5000/v2/_catalog 下载镜像:
# docker pull 192.168.127.128:5000/centos注:在客户端中从本地下载镜像需要修改docker的配置文件 /etc/docker/daemon.json。
五、Docker数据卷与文件存储管理
一般容器中管理数据主要有两种方式:
- 数据卷(Data Volumes):容器内数据直接映射到本地主机环境。
- 数据卷容器(Data Volume Containers):使用特定容器维护数据卷。
数据卷(Data Volumes)是一个可供容器使用的特殊目录,它将主机操作系统目录直接映射进容器,类似于Linux中的mount行为。如果直接挂载一个文件到容器,使用文件编辑工具,包括vi或者sed --in-place的时候,可能会造成文件inode的改变。从Docker 1.1.0起,这会导致报错误信息。所以推荐的方式是直接挂载文件所在的目录到容器内。
数据卷是被设计用来持久化数据的,它的生命周期独立于容器,Docker不会在容器被删除后自动删除数据卷,并且也不存在垃圾回收这样的机制来处理没有任何容器引用的数据卷。
1、数据卷
首先我们先来介绍下什么是数据卷:数据卷(Data Volume)是一个可供容器使用的特殊目录,是将主机操作系统目录直接映射进容器,类似于Linux的mount命令。
数据卷可以提供很多很用的特性:
- 数据卷可以在容器之间共享和重用, 容器间传递数据将变得高效与方便;
- 对数据卷内数据的修改会立马生效,无论是容器内操作还是本地操作;
- 对数据卷的更新不会影响镜像, 解耦开应用和数据;
- 卷会一直存在, 直到没有容器使用, 可以安全地卸载它;
1)创建数据卷
使用命令 docker volume create:
# docker volume create -d local test
test
# docker volume list
DRIVER VOLUME NAME
local 9145a9036e96655189d81bd59c16181b1287de6c324cae08d4b5df32778926ff
local ac107675a30b3be115772d545130ddf1ba5fd27bfcb62f93a2a533ad4403b616
local d2760077757c8b9ef48f37a94032ed0f68a847e1fe0a6c84c16bcaba146fe25f
local test默认 volumes 的存放目录为 /var/lib/docker/volumes。
docker volume 支持以下的子命令:
2)绑定数据卷
除了使用 volume 子命令来创建管理数据卷外,还可以使用--mount标记来将数据卷挂载到容器里,正在创建容器是指定本地的任意目录挂载到容器作为数据卷,这也称为绑定数据卷。
在使用 docker [container] run 命令的时候,可以使用选项 --mount 来使用数据卷,它支持三种形式的数据卷:
- volume: 普通数据卷, 映射到主机/var/lib/docker/volumes路径下,格式:
type=bind,source=/path/on/host,destination=/path/in/container - bind: 绑定数据卷, 映射到主机指定路径下,格式:
type=volume,source=my-volume,destination=/path/in/container,volume-label="color=red",volume-label="shape=round" - tmpfs: 临时数据卷, 只存在于内存中,格式 :
type=tmpfs,tmpfs-size=512M,destination=/path/in/container
它们通用的选项有:
- src, source:源路径
- dst, destination, target:目标路径
- ro, readonly:true or false (default),是否只读
# mkdir /webapp
# docker run -d -P --name web --mount type=bind,source=/webapp,destination=/opt/webapp ubuntu
242a073a4f65aa3814c68147b7e3c5706834ac5a13b19d98d0b5c6ff5afa9c70该命令等同于 -v 格式的命令,所以上述的命令等价于:
# docker run -d -P --name web -v /webapp:/opt/webapp ubuntu如果使用的Docker有容器在运行,这里可能会不止一个。但是如果不添加-v参数,当容器停止或者删除时,volume同时也会被删除。
如果要只读挂载就成这样:
# docker run -d -P --name web -v /webapp:/opt/webapp:ro ubuntu本地目录的路径必须是绝对路径, 容器内路径可以为相对路径。 如果目录不存在, Docker会自动创建。
可以使用inspect命令查看指定数据卷的信息:
$ docker volume inspect MysqL-volume
[
{
"CreatedAt":"2019-08-10T05:18:55+08:00",
"Driver":"local",
"Labels":{},
"Mountpoint":"/var/lib/docker/volumes/MysqL-volume/_data",
"Name":"MysqL-volume",
"Options":{},
"Scope":"local"
}
]3)演示
使用MysqL镜像,创建一个名为abcdocker的容器,并加载MysqL-volume数据卷到容器的/var/lib/MysqL目录(因为这个目录就是MysqL默认的存储目录)。
docker run -d --name abcdocker -v MysqL-volume:/var/lib/MysqL -e MysqL_ALLOW_EMPTY_PASSWORD=true MysqL:5.7参数说明:
run 启动并创建容器
-d 后台运行
--name 设置名词
-v 挂载数据卷
-e 设置命令(因为MysqL默认需要设置密码,使用这个变量是可以不设置密码的)
MysqL:5.7为MysqL的镜像版本为我本地并没有下载MysqL的镜像,所以在运行容器的时候会自动帮我们拉取镜像:
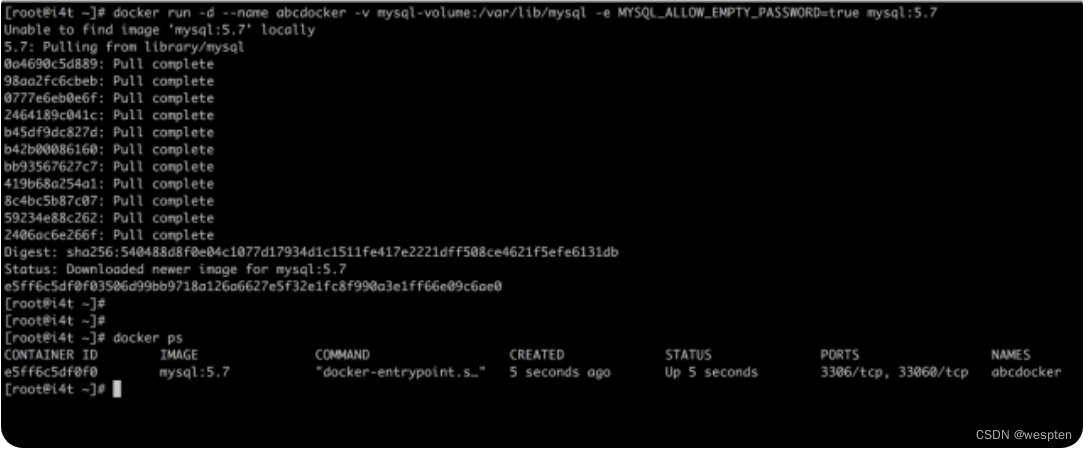
我们可以通过inspect查看web容器的详细信息:
$ docker inspect abcdocker
...省略号...
"Mounts":[
{
"Type":"volume",
"Name":"MysqL-volume",
"Source":"/var/lib/docker/volumes/MysqL-volume/_data",
"Destination":"/var/lib/MysqL",
"Driver":"local",
"Mode":"z",
"RW":true,
"Propagation":""
}
],
...省略号...从配置中我们可以看到我们容器挂载了一个名词为MysqL-volume的存储卷,并且挂载到/var/lib/MysqL目录下。
接下来我们可以进入到容器查看:
docker exec-it abcdocker /bin/bash登陆MysqL创建并创建一个数据库名称为abcdocker数据库。
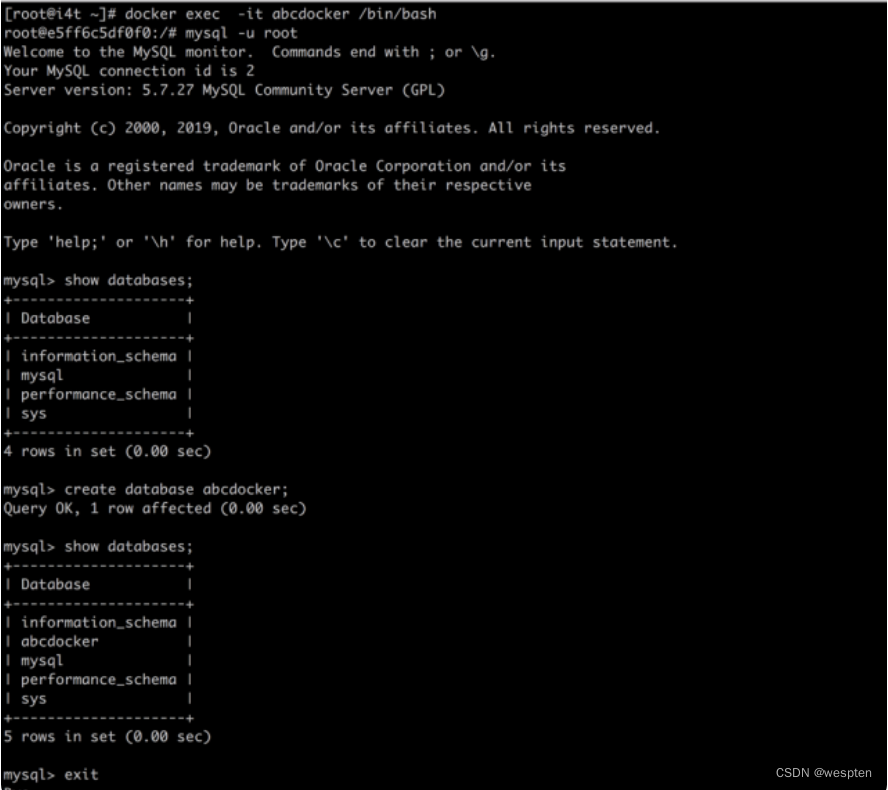
接下来我们可以将容器删除,并从新创建一个,查看是否有为abcdocker:
#删除abcdocker的数据库容器
$ docker rm -f abcdocker
#并创建一个新的
$ docker run -d --name abcdocker -v MysqL-volume:/var/lib/MysqL -e MysqL_ALLOW_EMPTY_PASSWORD=true MysqL:5.7
#查看是否有abcdocker数据库
MysqL> show databases;
+--------------------+
|Database|
+--------------------+
| information_schema |
| abcdocker |
| MysqL |
| performance_schema |
| sys |
+--------------------+
5 rows inset(0.00 sec)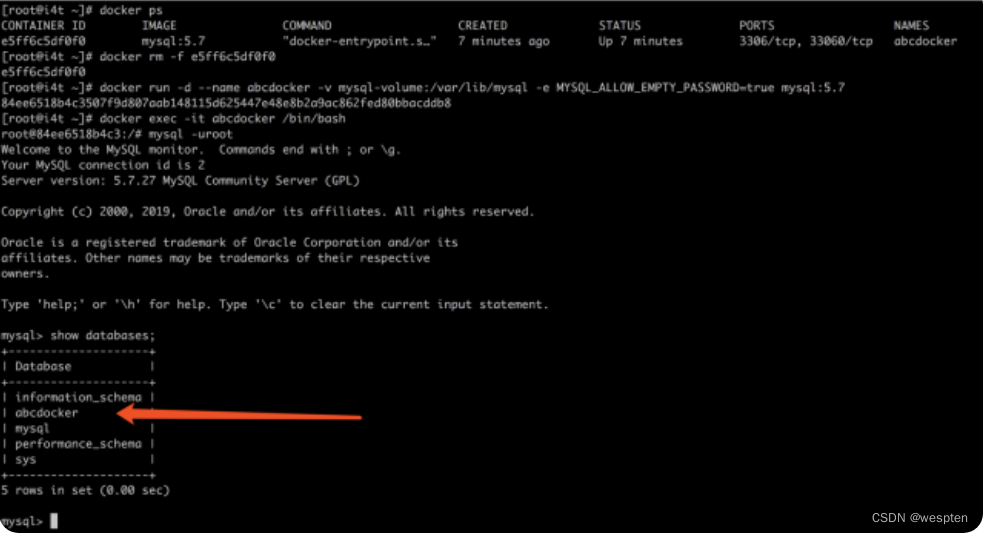
如果需要删除在删除容器同时移除数据卷。可以在删除容器时使用docker rm -v命令。无主的数据卷可能会占用很多空间:
#删除数据卷名称为MysqL-volume命令如下
docker volume rm MysqL-volume
#删除所有数据卷(请谨慎操作)
docker volume prune挂载主机目录Docker持久化存储除了有逻辑卷还有一个是挂载目录:
#挂载一个主机目录作为数据卷,可以使用--mount或者使用-v 指定目录(-v也可以指定数据卷) -p参数为端口映射后面会说
[root@i4t ~]# docker run -d --name abcdocker-Nginx -p 80:80-v /data:/data Nginx
630f0d194583b5e3b547572c018bae1ac78f9341364a2c9eebf4ba898c9bf23e
[root@i4t ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
630f0d194583 Nginx "Nginx -g 'daemon of…"3 seconds ago Up2 seconds 0.0.0.0:80->80/tcp abcdocker-Nginx
[root@i4t ~]# docker exec-it abcdocker-Nginx /bin/bash
root@630f0d194583:/# cd /data/
root@630f0d194583:/data# ls
root@630f0d194583:/data# echo "i4t.com" >abcdocker.txt
root@630f0d194583:/data# exit
exit
[root@i4t ~]# cat /data/abcdocker.txt
i4t.com上面的测试我们是将宿主机的/data目录挂载到容器的/data目录,本地目录的路径必须是绝对路径,如果使用-v参数本地目录不存在Docker会自动创建一个文件夹。这样宿主机和Docker的/data目录数据就同步,相当于NFS挂载。
查看数据卷的具体信息,可以在宿主机使用inspect查看容器信息:
$ docker inspect abcdocker-Nginx
...省略号...
"Mounts":[
{
"Type":"bind",
"Source":"/data",
"Destination":"/data",
"Mode":"",
"RW":true,
"Propagation":"rprivate"
}
],
...省略号...2、数据卷容器
数据卷容器本身也是一个容器,它能为不同的容器提供数据卷,关键命令在于 docker run 的 --volumes-from 选项。
首先创建一个数据卷容器 dbdata,并创建一个数据卷挂载到 /dbdata:
# docker run -itd -v /dbdata --name dbdata ubuntu然后其他容器使用 --volumes-from 来挂载 dbdata 容器中的数据卷:
# docker run -itd --volumes-from dbdata --name db1 ubuntu
# docker run -itd --volumes-from dbdata --name db2 ubuntu此时,容器 db1 和 容器 db2 都挂载同一个数据卷。
选项 --volumes-from 也支持从多个容器挂载多个数据卷:
# docker run -itd --name db3 --volumes-from db1 --volumes-from 8b41042720 ubuntu使用--volumes-from参数所挂载数据卷的容器自己并不需要保持在运用状态。如果删除了挂载的容器(包括dbdata、 db1和db2) , 数据卷并不会被自动删除。 如果要删除一个数据卷, 必须在删除最后一个还挂载着它的容器时显式使用docker rm-v命令来指定同时删除关联的容器。
3、利用数据卷容器来迁移数据
可以利用数据卷对其中的数据卷进行备份和恢复,从而实现数据迁移。
1)备份
使用以下的命令来备份dbdata数据卷容器内的数据卷:
# docker run --volumes-from dbdata -v $(pwd):/backup --name worker --rm ubuntu tar -cvf /backup/backup.tar.gz /dbdata相对复杂点,具体的步骤就是先创建一个 worker 容器,将本地目录挂载进去,使用 --volumes-from 挂载 dbdata 容器的数据卷。容器启动后使用 命令 tar -cvf /backup/backup.tar /dbdata 备份数据到挂载的目录下。选项 --rm 能保证容器执行完命令后自动删除。
2)恢复
如果要恢复到容器,下面的命令:
# docker run -it --volumes-from dbdata -v $(pwd):/backup --name recover --rm ubuntu tar -xvf /backup/backup.tar -C /dbdata4、多个机器之间的容器共享数据
sshfs的driver可以让docker使用不在同一台机器上的文件系统做volume。
官方参考链接 https://docs.docker.com/storage/volumes/#share-data-among-machines
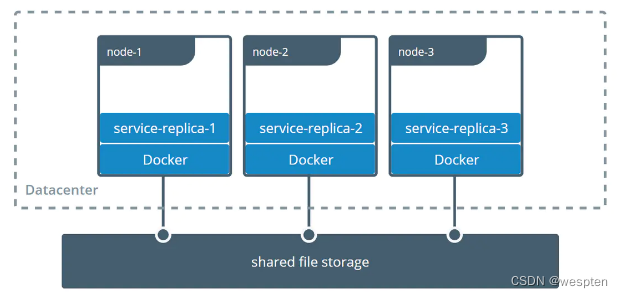
Docker的volume支持多种driver,默认创建的volume driver都是local。
$ docker volume inspect vscode
[
{
"CreatedAt": "2021-06-23T21:33:57Z",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/vscode/_data",
"Name": "vscode",
"Options": null,
"Scope": "local"
}
]准备三台Linux机器,之间可以通过SSH相互通信:

安装plugin:
在其中两台机器上安装一个plugin vieux/sshfs。
[vagrant@docker-host1 ~]$ docker plugin install --grant-all-permissions vieux/sshfs
latest: Pulling from vieux/sshfs
Digest: sha256:1d3c3e42c12138da5ef7873b97f7f32cf99fb6edde75fa4f0bcf9ed277855811
52d435ada6a4: Complete
Installed plugin vieux/sshfs[vagrant@docker-host2 ~]$ docker plugin install --grant-all-permissions vieux/sshfs
latest: Pulling from vieux/sshfs
Digest: sha256:1d3c3e42c12138da5ef7873b97f7f32cf99fb6edde75fa4f0bcf9ed277855811
52d435ada6a4: Complete
Installed plugin vieux/sshfs创建volume:
[vagrant@docker-host1 ~]$ docker volume create --driver vieux/sshfs \
-o sshcmd=vagrant@192.168.200.12:/home/vagrant \
-o password=vagrant \
sshvolume查看:
[vagrant@docker-host1 ~]$ docker volume ls
DRIVER VOLUME NAME
vieux/sshfs:latest sshvolume
[vagrant@docker-host1 ~]$ docker volume inspect sshvolume
[
{
"CreatedAt": "0001-01-01T00:00:00Z",
"Driver": "vieux/sshfs:latest",
"Labels": {},
"Mountpoint": "/mnt/volumes/f59e848643f73d73a21b881486d55b33",
"Name": "sshvolume",
"Options": {
"password": "vagrant",
"sshcmd": "vagrant@192.168.200.12:/home/vagrant"
},
"Scope": "local"
}
]创建容器挂载Volume:
创建容器,挂载sshvolume到/app目录,然后进入容器的shell,在/app目录创建一个test.txt文件。
[vagrant@docker-host1 ~]$ docker run -it -v sshvolume:/app busyBox sh
Unable to find image 'busyBox:latest' locally
latest: Pulling from library/busyBox
b71f96345d44: Pull complete
Digest: sha256:930490f97e5b921535c153e0e7110d251134cc4b72bbb8133c6a5065cc68580d
Status: Downloaded newer image for busyBox:latest
/ #
/ # ls
app bin dev etc home proc root sys tmp usr var
/ # cd /app
/app # ls
/app # echo "this is ssh volume"> test.txt
/app # ls
test.txt
/app # more test.txt
this is ssh volume
/app #
/app #这个文件我们可以在docker-host3上看到:
[vagrant@docker-host3 ~]$ pwd
/home/vagrant
[vagrant@docker-host3 ~]$ ls
test.txt
[vagrant@docker-host3 ~]$ more test.txt
this is ssh volume六、Docker网络管理
1、Docker 网络类型
在 docker 1.7版本中,官方就开始将 docker 网络部分的代码抽出并单独创建独立的网络库,那就是 libnetwork。之后,在 docker 1.9版本中,有推出一套 docker network 命令来管理主机的网络。
docker 官方整合了网络驱动并使之标准化,并使用 CNM(Container Network Model)来定义构建容器虚拟化网络的模型,提供了可以用于开发多种网咯驱动的标准化接口和组件。
libnetwork 中使用 CNM 来完成网络功能的提供,CNM中主要有 sandBox(沙盒)、endpoint(端点)和 network(网络)三种组件。
同时内置六种类型驱动:
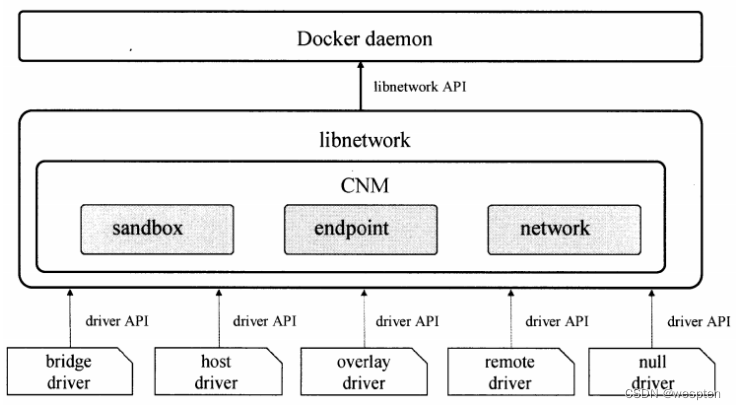
CNM 的三个核心组件:
- 沙盒:一个沙盒包含了一个容器网络栈的信息。沙盒可以对容器的接口、路由和 DNS 设置等进行管理。沙盒的实现可以是 Linux network namespace、FreeBSD Jail 或者类似的机制。一个沙盒可以有多个端点和多个网络。
- 端点:一个端点可以加入一个沙盒和一个网络。端点的实现可以是veth pair、Open vSwitch 内部端口或者相似的设备。一个端点只可以属于一个网络并且只属于一个沙盒。
- 网络:一个网络是一组可以直接相互连通的端点。网络的实现可以是 Linux bridge、VLAN 等。一个网络可以包含多个端点。
libnetwork 内置的六种驱动:
- bridge 驱动:bridge 是 Docker 默认设置,使用这个驱动的时候,libnetwork 将创建出来的 docker 容器连接到 docker 网桥上(Docker0)。bridge 模式一般情况下已经可以满足容器最基本的使用需求。但由于与外部通信使用 NAT,增加了通信的复杂性,不适合在复杂场景下使用。
- host 驱动:使用 host 驱动,libnetwork 容器和宿主机共用同一个 network namespace,使用宿主机的网卡、IP和端口等信息(其他资源是隔离的)。host 模式很好地解决了容器与外界通信地地址转换问题,可以直接使用宿主机地IP进行通信,不存在虚拟化网路带来地性能损耗。但也降低了和主机之间网络层地隔离性,引起网络资源地竞争与冲突。一般私用与容器集群规模不大地场景。
- overlay 驱动:overlay 驱动采用IETF标准地 VXLAN 方式,并且是 VXLAN 中被普遍认为最适合大规模地云计算虚拟化环境地 SDN controller 模式。使用时,需要一个额外地配置存储服务,如 Consul,etcd,ZooKeeper。在启动 docker daemon 时还要额外添加参数来指定所有使用地配置存储服务地址。
- remote 驱动:remote 驱动提供可插件化地方式,调用用户自行实现地网络驱动插件。用户只要根据 libnetwork 提供地协议标准,实现其所要求地各个接口并向 docker daemon 注册。
- null 驱动:null 驱动提供了 network namespace 和自带地 loopback 网卡,如果用户不进行特定地配置就无法使用 docker 网络。它给用户最大地自由度来自定义容器地网络环境。
- macvlan 驱动:macvlan 驱动和其他驱动相比是最新的一种驱动。它本身是 linxu kernel的模块,本质上是一种网卡虚拟化技术。其功能是允许在同一个物理网卡上虚拟出多个网卡,通过不同的MAC地址在数据链路层进行网络数据的转发,一块网卡上配置多个 MAC 地址(即多个 interface)
mavlan 驱动地注意事项:
- 由于IP地址耗尽或“VLAN传播”,很容易无意中损坏您的网络,在这种情况下,您的网络中存在大量不合适的MAC地址。
- 您的网络设备需要能够处理“混杂模式”,其中一个物理接口可以分配多个MAC地址。
- 如果您的应用程序可以使用桥接器(在单个Docker主机上)或覆盖层(跨多个Docker主机进行通信),那么从长远来看,这些解决方案可能会更好。
而 docker 默认 bridge 驱动的网络环境拓扑图如下:
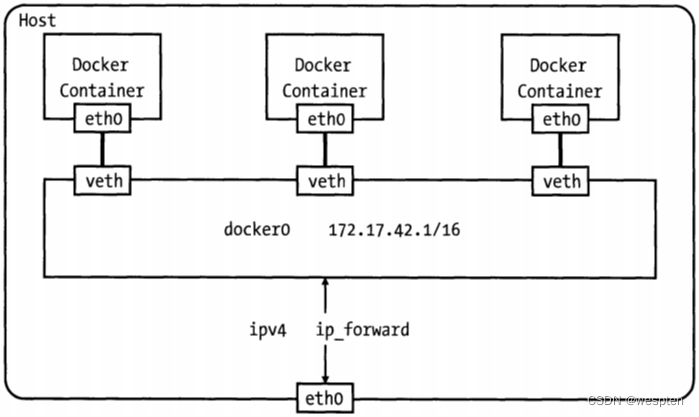
Docker四种网络模式:
-
Bridge:当Docker进程启动时,会在主机上创建一个名为Docker0的虚拟网桥,此主机上启动的Docker容器默认会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机相似,这样主机上的所有容器就通过交换机连在了一个二层网络中。从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器内部网卡),另一端在放在主机中,以vethxxx这样类似的名称命名,并将这个网络设备加入到docker0网桥中。可以使用brctl show命令查看。如果有多个容器之间需要互相通信,推荐使用Docker Compose或者使用k8s编排工具。
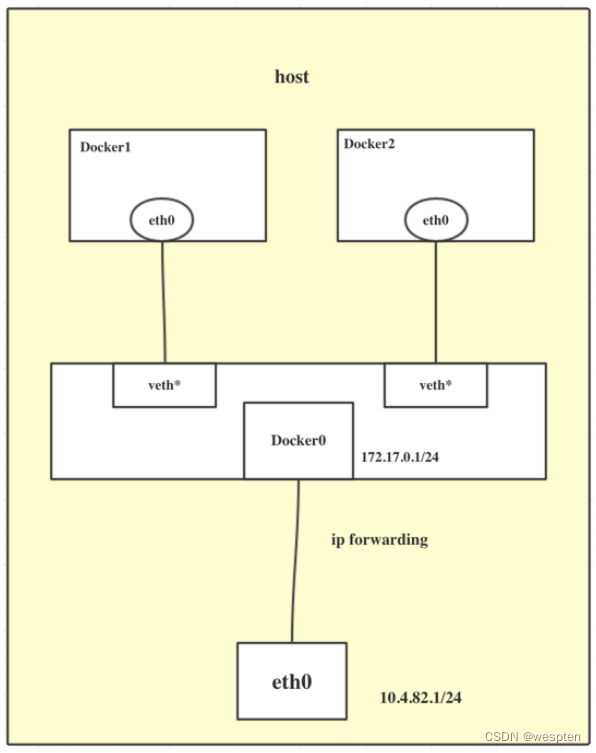
- Host如果启动容器的时候使用host模式,那么这个容器将不会获取一个独立的Network Namespace,而是和宿主机共用一个Network Namespace(这里和我们平常使用的虚拟机的仅主机模式相似)。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。但是,容器的其他方便,如文件系统、系统进程等还是和宿主机隔离的。
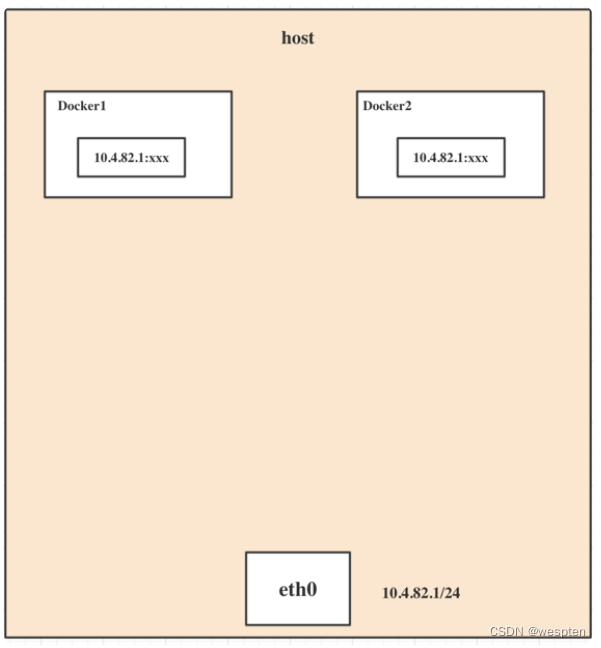
- Container这个模式指定新创建的容器和已经存在的容器共享一个Network Namespace,而不是和宿主机共享。新创建的容器也不会自己创建网卡,IP等。而是和一个指定的容器共享IP、端口范围等。同样,两个容器除了网络方面,其他的还都是属于隔离。两个容器的进程可以通过宿主机的lo网卡设备进行通信。
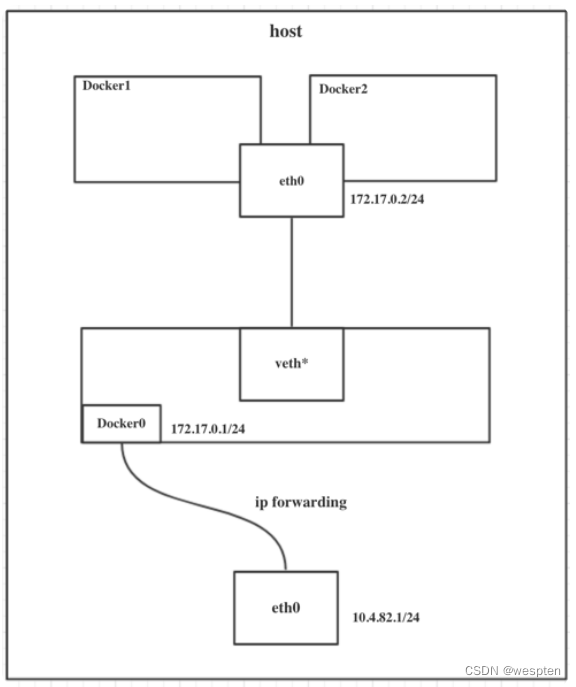
- None使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。
以上几种网络模式配置只需要在docker run的时候使用--net参数就可以指定,默认情况下是使用Bridge模式,也是常见的模式。
① 配置一个host仅主机模式
容器与宿主机共享同一网络,从下面的例子可以发现,容器Box1和宿主机使用的网络完全一致。
[root@localhost zhangtao]# docker container run -d --rm --name Box1 --network host busyBox /bin/sh -c "while true; do sleep 3600; done"
3512823b7fba88c082f30966b91b3070bfa6d10f117a766aae4d1df82f78fe4a
[root@localhost zhangtao]#
[root@localhost zhangtao]# docker container exec -it Box1 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <broADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq qlen 1000
link/ether 00:50:56:9c:d9:7d brd ff:ff:ff:ff:ff:ff
inet 10.66.253.123/20 brd 10.66.255.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet6 fe80::f683:a97e:c58:1cfb/64 scope link tentative dadFailed noprefixroute
valid_lft forever preferred_lft forever
inet6 fe80::7b70:f10a:c37a:83b/64 scope link tentative dadFailed noprefixroute
valid_lft forever preferred_lft forever
inet6 fe80::40c6:68e2:7711:779a/64 scope link tentative dadFailed noprefixroute
valid_lft forever preferred_lft forever
3: br-75f6bbe6b8e4: <NO-CARRIER,broADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue
link/ether 02:42:74:98:0b:4d brd ff:ff:ff:ff:ff:ff
inet 172.30.10.1/24 brd 172.30.10.255 scope global br-75f6bbe6b8e4
valid_lft forever preferred_lft forever
4: docker0: <NO-CARRIER,broADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue
link/ether 02:42:96:11:5d:92 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
5: br-a73727a1bbe7: <NO-CARRIER,broADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue
link/ether 02:42:bf:d4:73:dd brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 brd 172.18.255.255 scope global br-a73727a1bbe7
valid_lft forever preferred_lft forever
[root@localhost zhangtao]#
[root@localhost zhangtao]#
[root@localhost zhangtao]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNowN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens192: <broADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:9c:d9:7d brd ff:ff:ff:ff:ff:ff
inet 10.66.253.123/20 brd 10.66.255.255 scope global noprefixroute ens192
valid_lft forever preferred_lft forever
inet6 fe80::f683:a97e:c58:1cfb/64 scope link tentative noprefixroute dadFailed
valid_lft forever preferred_lft forever
inet6 fe80::7b70:f10a:c37a:83b/64 scope link tentative noprefixroute dadFailed
valid_lft forever preferred_lft forever
inet6 fe80::40c6:68e2:7711:779a/64 scope link tentative noprefixroute dadFailed
valid_lft forever preferred_lft forever
3: br-75f6bbe6b8e4: <NO-CARRIER,broADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:74:98:0b:4d brd ff:ff:ff:ff:ff:ff
inet 172.30.10.1/24 brd 172.30.10.255 scope global br-75f6bbe6b8e4
valid_lft forever preferred_lft forever
4: docker0: <NO-CARRIER,broADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:96:11:5d:92 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
5: br-a73727a1bbe7: <NO-CARRIER,broADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:bf:d4:73:dd brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 brd 172.18.255.255 scope global br-a73727a1bbe7
valid_lft forever preferred_lft forever如果使用像Nginx的容器,将其网络改为host的话,就不能创建多个Nginx容器。因为第一个使用host的Nginx容器已经将宿主机的80端口所占用,其他容器就不能再次监听宿主机的80端口了。
创建两个Nginx容器,都使用host网络,会发现web5这个容器已经退出了:
[root@localhost]# docker container run -d --name web4 --network host Nginx
a24800911cff61c283e629ec50f56b377b18e8199fda91bce535328401433aba
[root@localhost]#
[root@localhost]# docker container run -d --name web5 --network host Nginx
15ab3a57acd09e6cd8f2a7d9b7be6aced157a25baf90d2ca3440d3146e66b5b0
[root@localhost]# docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
15ab3a57acd0 Nginx "/docker-entrypoint.…" About a minute ago Exited (1) About a minute ago web5
a24800911cff Nginx "/docker-entrypoint.…" 2 minutes ago Up 2 minutes web4
ecdc2d9e4a77 Nginx "/docker-entrypoint.…" 6 minutes ago Up 6 minutes 80/tcp web3
81a03dcd558d Nginx "/docker-entrypoint.…" 6 minutes ago Up 6 minutes 80/tcp web2
85f19091f188 Nginx "/docker-entrypoint.…" 6 minutes ago Up 6 minutes 80/tcp web1
f82028e4f127 Nginx "/docker-entrypoint.…" 3 weeks ago Exited (255) 23 minutes ago 0.0.0.0:80->80/tcp, :::80->80/tcp condescending_brattain查看web5的日志就会发现,宿主机的80端已经被占用,不能再创建web5容器:
[root@localhost]# docker logs -f web5
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/Nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/Nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2021/12/13 12:29:51 [emerg] 1#1: bind() to 0.0.0.0:80 Failed (98: Address already in use)
Nginx: [emerg] bind() to 0.0.0.0:80 Failed (98: Address already in use)
2021/12/13 12:29:51 [emerg] 1#1: bind() to [::]:80 Failed (98: Address already in use)
Nginx: [emerg] bind() to [::]:80 Failed (98: Address already in use)
2021/12/13 12:29:51 [notice] 1#1: try again to bind() after 500ms
2021/12/13 12:29:51 [emerg] 1#1: bind() to 0.0.0.0:80 Failed (98: Address already in use)
Nginx: [emerg] bind() to 0.0.0.0:80 Failed (98: Address already in use)
2021/12/13 12:29:51 [emerg] 1#1: bind() to [::]:80 Failed (98: Address already in use)
Nginx: [emerg] bind() to [::]:80 Failed (98: Address already in use)
2021/12/13 12:29:51 [notice] 1#1: try again to bind() after 500ms
2021/12/13 12:29:51 [emerg] 1#1: bind() to 0.0.0.0:80 Failed (98: Address already in use)
Nginx: [emerg] bind() to 0.0.0.0:80 Failed (98: Address already in use)
2021/12/13 12:29:51 [emerg] 1#1: bind() to [::]:80 Failed (98: Address already in use)
Nginx: [emerg] bind() to [::]:80 Failed (98: Address already in use)
2021/12/13 12:29:51 [notice] 1#1: try again to bind() after 500ms
2021/12/13 12:29:51 [emerg] 1#1: bind() to 0.0.0.0:80 Failed (98: Address already in use)
Nginx: [emerg] bind() to 0.0.0.0:80 Failed (98: Address already in use)
2021/12/13 12:29:51 [emerg] 1#1: bind() to [::]:80 Failed (98: Address already in use)
Nginx: [emerg] bind() to [::]:80 Failed (98: Address already in use)
2021/12/13 12:29:51 [notice] 1#1: try again to bind() after 500ms
2021/12/13 12:29:51 [emerg] 1#1: bind() to 0.0.0.0:80 Failed (98: Address already in use)
Nginx: [emerg] bind() to 0.0.0.0:80 Failed (98: Address already in use)
2021/12/13 12:29:51 [emerg] 1#1: bind() to [::]:80 Failed (98: Address already in use)
Nginx: [emerg] bind() to [::]:80 Failed (98: Address already in use)
2021/12/13 12:29:51 [notice] 1#1: try again to bind() after 500ms
2021/12/13 12:29:51 [emerg] 1#1: still Could not bind()
Nginx: [emerg] still Could not bind()host网络的好处:
-
能够减少性能损耗,比如使用bridge网络,会经过NAT、端口转发等过程,而使用host不需要。
② Bridge模式容器间通信
创建两个容器:
$ docker container run -d --rm --name Box1 busyBox /bin/sh -c "while true; do sleep 3600; done"
$ docker container run -d --rm --name Box2 busyBox /bin/sh -c "while true; do sleep 3600; done"
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4f3303c84e53 busyBox "/bin/sh -c 'while t…" 49 minutes ago Up 49 minutes Box2
03494b034694 busyBox "/bin/sh -c 'while t…" 49 minutes ago Up 49 minutes Box1容器间通信:
两个容器都连接到了一个叫 docker0 的Linux bridge上。
$ docker network ls
NETWORK ID NAME DRIVER ScopE
1847e179a316 bridge bridge local
a647a4ad0b4f host host local
fbd81b56c009 none null local
$ docker network inspect bridge
[
{
"Name": "bridge",
"Id": "1847e179a316ee5219c951c2c21cf2c787d431d1ffb3ef621b8f0d1edd197b24",
"Created": "2021-07-01T15:28:09.265408946Z",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"subnet": "172.17.0.0/16",
"Gateway": "172.17.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"03494b034694982fa085cc4052b6c7b8b9c046f9d5f85f30e3a9e716fad20741": {
"Name": "Box1",
"EndpointID": "072160448becebb7c9c333dce9bbdf7601a92b1d3e7a5820b8b35976cf4fd6ff",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
},
"4f3303c84e5391ea37db664fd08683b01decdadae636aaa1bfd7bb9669cbd8de": {
"Name": "Box2",
"EndpointID": "4cf0f635d4273066acd3075ec775e6fa405034f94b88c1bcacdaae847612f2c5",
"MacAddress": "02:42:ac:11:00:03",
"IPv4Address": "172.17.0.3/16",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
]brctl 使用前需要安装, 对于CentOS, 可以通过 sudo yum install -y bridge-utils 安装;对于Ubuntu, 可以通过sudo apt-get install -y bridge-utils。
$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242759468cf no veth8c9bb82
vethd8f9afb③ none网络
使用none网络无法进行内网和外网通信,只有一个本地的回环地址。
[root@localhost zhangtao]# docker network ls
NETWORK ID NAME DRIVER ScopE
bbd37a39580b bridge bridge local
02c908cdee7e host host local
d8c32d294a1b none null local

使用场景:被第三方程序使用,比如容器编排就希望docker创建一个没有网络的容器,至于网络部分就由容器编排来负责。
2、Docker network 网络管理
docker network 子命令用于 docker 中网络的操作,它主要包含以下命令:
- create: 创建一个网络;
- connect: 将容器接入到网络;
- disconnect: 把容器从网络上断开;
- inspect: 查看网络的详细信息。
- ls: 列出所有的网络;
- prune: 清理所有未使用的网络资源;
- rm: 删除一个网络。
1. 创建网络
创建网络使用命令 docker network create [OPTIONS] NETWORK,支持参数包括:
- --attachable[=false]: 支持自动容器挂载;
- --aux-address=map[]: 辅助的IP地址;
- --config-from="": 从某个网络复制配置数据;·-config-only[=false]: 启用仅可配置模式;
- -d,--driver="bridge": 网络驱动类型, 如br--ingress[=false]: 创建一个Swarm可路由idge或overlay;
- --gateway=[]: 网关地址;
- --ingress[=false]: 创建一个Swarm可路由的网状网络用于负载均衡, 可将对某个服务的请求自动转发给一个合适的副本;
- --internal[=false]: 内部模式, 禁用外部对所创建网络的访问;
- --ip-range=[]: 指定分配IP地址范围;
- --ipam-driver="default": IP地址管理的插件类型;
- --ipam-opt=map[]: IP地址管理插件的选项;
- --ipv6[=false]: 支持IPv6地址;
- --label value: 为网络添加元标签信息;
- -o,--opt=map[]: 网络驱动所支持的选项;
- --scope="": 指定网络范围;
- --subnet=[]: 网络地址段, CIDR格式, 如172.17.0.0/16。
# docker network create nettest
e128e4369a3366a246c0204c5e6d9a05922a7429988ee224025932e2aa1ab1ae2. 列出网络
命令 docker network ls [OPTIONS] 用来列出 docker 的所有网络,支持的选项有:
- -f,--filter="": 指定输出过滤器, 如driver=bridge;
- --format="": 给定一个golang模板字符串, 对输出结果进行格式化;
- --no-trunc[=false]: 不截断地输出内容;
- -q,--quiet[=false]: 安静模式, 只打印网络的ID;
# docker network ls
NETWORK ID NAME DRIVER ScopE
e08e2741bb1a bridge bridge local
1e7a510c218d docker_gwbridge bridge local
ff8cf4a7552a host host local
sr8ng3ogxxa8 ingress overlay swarm
e128e4369a33 nettest bridge local
8514568883d2 none null localdocker daemon 启动时,默认有 null,host 和 bridge 三种类型的驱动。
linux 上会创建一个名为 docker0 的网卡,对应 docker 中的 bridge 驱动,另外,ingress 是 overlay 驱动,使用命令 docker swarm 创建集群时就会生成该驱动。
3. 接入网络
docker network connect [OPTIONS] NETWOKR CONTAINER 命令将一个容器连接到一个已存在的网络上,同一个网络上的容器可以互通,容器和网络为多对多关系。也可以在 docker run 命令时指定 -net 参数指定容器连接的网络。
支持的参数为:
- --alias=[]: 为容器添加一个别名, 此别名仅在所添加网络上可见;
- --ip="": 指定IP地址, 需要注意不能跟已接入的容器地址冲突;
- --ip6="": 指定IPv6地址;
- --link value: 添加链接到另外一个容器;
- --link-local-ip=[]: 为容器添加一个链接地址。
# docker run -itd --name node1 --network nettest busyBox sh
a9ec9af4fac7074031d3f23068600c1a8151771611aa57914ab77df67f5914cd
# docker run -itd --name node2 busyBox sh
# docker network connect nettest node2
# docker exec -it node2 sh
# ping node1
PING node1 (172.19.0.2): 56 data bytes
64 bytes from 172.19.0.2: seq=0 ttl=64 time=0.120 ms4. 断开网络
与 connect 对应的命令时 docker network disconnect [OPTIONS] NETWORK CONTAINER,支持参数包括 -f, -force: 强制把容器从网络上移除。
# docker network disconnect nettest node25. 查看网络信息
docker network inspect [OPTIONS] NETWORK [NETWORK...] 命令用于查看某个网络的具体信息(JSON格式),包括接人的容器、 网络配置信息等。
- -f,--format="": 给定一个Golang模板字符串, 对输出结果进行格式化, 如只查看地址配置可以用 -f'{{.IPAM.Config}}';
- -v,--verbose[=false]: 输出调试信息。
6. 清理所有网络
docker network prune [OPTIONS] [flags] 命令用于清理已经没有容器使用的网络。
- --filter="": 指定选择过滤器;
- -f,--force: 强制清理资源。
7. 删除网络
docker network rm NETWORK [NETWORK...] 命令用于删除指定的网络, 当网络上没有容器连接上时, 才会成功删除。
8. docker网络创建案例
-d:指定driver为bridge:
[root@localhost ~]# docker network create -d bridge mybridge
a0bc67bd61e96496569fe5cb99cf3541a94fb5344ab78744d017ce68b08e56de
[root@localhost ~]#
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER ScopE
c4b678a93972 bridge bridge local
d0763579887a host host local
a0bc67bd61e9 mybridge bridge local
6a03d63270a6 none null local
[root@localhost ~]#
[root@localhost ~]# docker network inspect a0b
[
{
"Name": "mybridge",
"Id": "a0bc67bd61e96496569fe5cb99cf3541a94fb5344ab78744d017ce68b08e56de",
"Created": "2021-12-12T15:39:11.777904385+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]- 可看到新创建的bridge子网为172.18.0.0/16
使用自定义bridge,创建container时使用--network [network_name] 来指定网络:
[root@localhost ~]# docker container run -d --name Box3 --network mybridge busyBox /bin/sh -c "while true; do sleep 3600; done"
d4d224ad1847593352e11877e2264797129c3205d13aae42c227c50fea6b903a
[root@localhost ~]#
[root@localhost ~]# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d4d224ad1847 busyBox "/bin/sh -c 'while t…" 11 seconds ago Up 10 seconds Box3
a99bb30012ad busyBox "/bin/sh -c 'while t…" 19 hours ago Up 19 hours Box2
80c4a01d050e busyBox "/bin/sh -c 'while t…" 19 hours ago Up 19 hours Box1使用docker container inspect Box3查看容器信息,发现网络使用的是自定义的bridge:
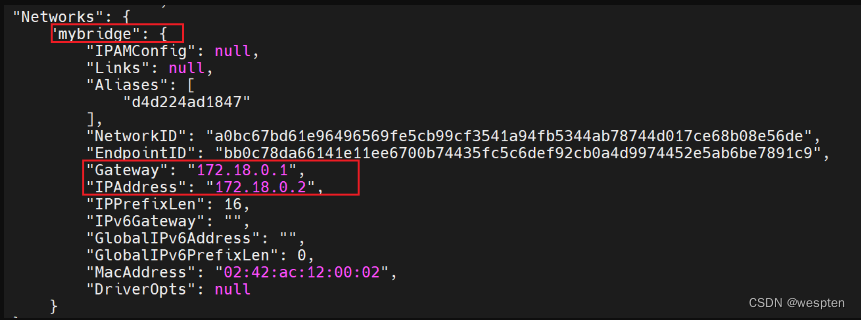
使用docker network inspect mybridge 查看自定义的bridge信息,发现container下有Box3:

使用docker network connect bridge Box3 来使容器Box3连接默认的bridge网络,连接完成后docker container inspect Box3 来查看Box3的信息,发现Box3同时连接了自定义的mybridge和默认的bridge。
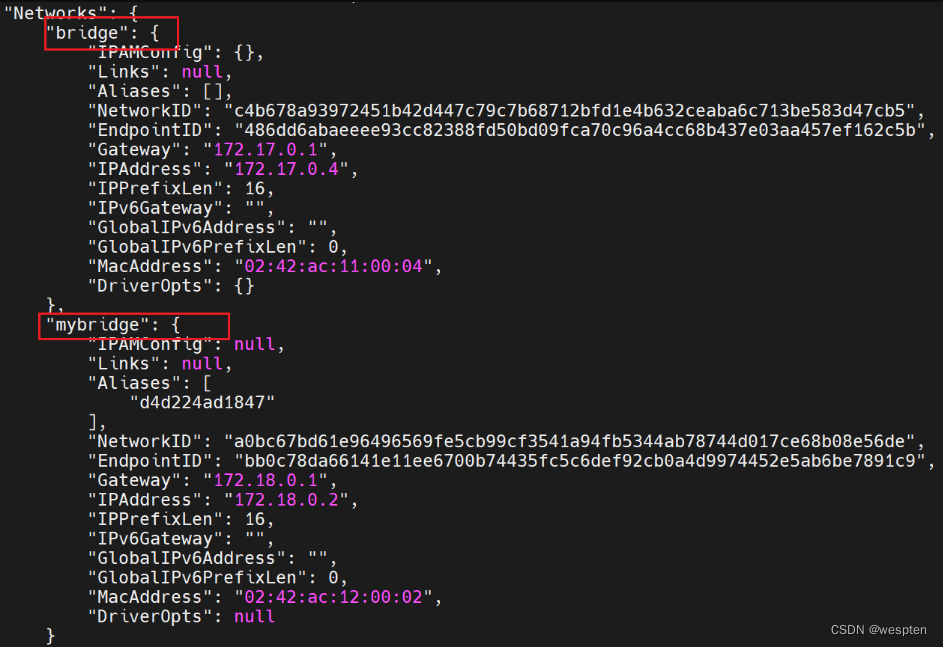
进入到容器中docker container exec -it Box3 sh查看ip信息ip a,也能查看到此容器连接了172.18.0.2/16以及172.17.0.4/16两个接口:
[root@localhost ~]# docker container exec -it Box3 sh
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
29: eth0@if30: <broADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth0
valid_lft forever preferred_lft forever
31: eth1@if32: <broADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.4/16 brd 172.17.255.255 scope global eth1
valid_lft forever preferred_lft forever使用docker network inspect bridge也能查看到container中多了Box3这个容器:
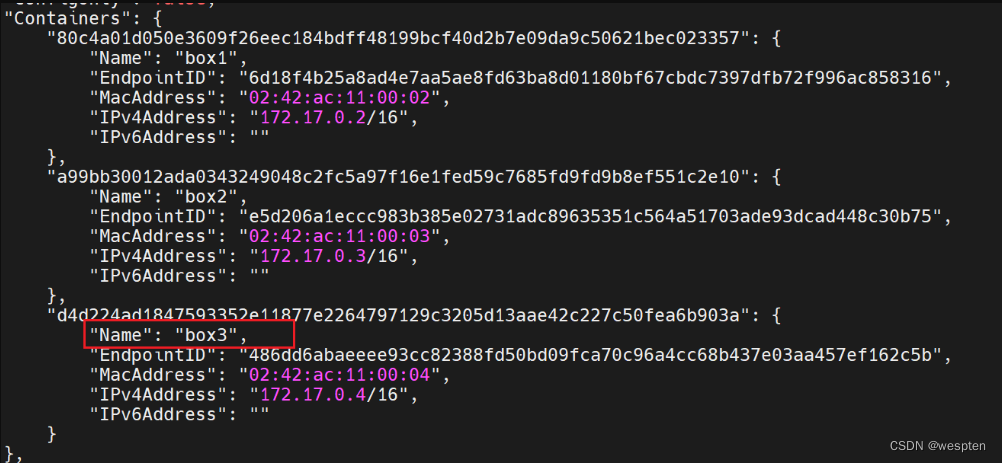
关闭网络连接:
docker network disconnect [network_name] [container_name]自定义的mybridge提供了类似DNS的功能,可以通过容器名称查询其ip地址。但是默认的bridge不提供类似的DNS的功能:
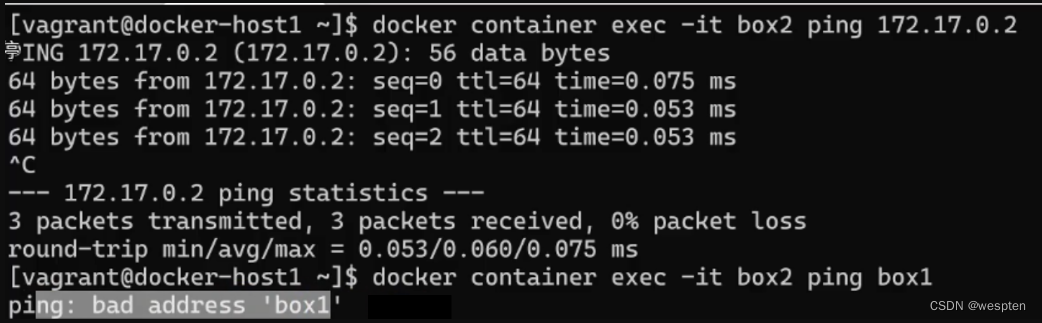
docker network其他参数:
[root@localhost ~]# docker network create --help
Usage: docker network create [OPTIONS] NETWORK
Create a network
Options:
--attachable Enable manual container attachment
--aux-address map Auxiliary IPv4 or IPv6 addresses used by Network driver (default map[])
--config-from string The network from which to copy the configuration
--config-only Create a configuration only network
-d, --driver string Driver to manage the Network (default "bridge")
--gateway strings IPv4 or IPv6 Gateway for the master subnet
--ingress Create swarm routing-mesh network
--internal Restrict external access to the network
--ip-range strings Allocate container ip from a sub-range
--ipam-driver string IP Address Management Driver (default "default")
--ipam-opt map Set IPAM driver specific options (default map[])
--ipv6 Enable IPv6 networking
--label list Set Metadata on a network
-o, --opt map Set driver specific options (default map[])
--scope string Control the network's scope
--subnet strings subnet in CIDR format that represents a network segment指定网关和子网:
[root@localhost ~]# docker network create -d bridge --gateway 172.200.0.1 --subnet 172.200.0.0/16 demo-bridge
18294d3e66dd7004ff956f8f1243ffcaf2d29940f3e024dfcd70c41814cc1b01
[root@localhost ~]#
[root@localhost ~]# docker network inspect demo-bridge
[
{
"Name": "demo-bridge",
"Id": "18294d3e66dd7004ff956f8f1243ffcaf2d29940f3e024dfcd70c41814cc1b01",
"Created": "2021-12-12T16:19:44.154286168+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"subnet": "172.200.0.0/16",
"Gateway": "172.200.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {},
"Options": {},
"Labels": {}
}
]3、Docker 网络高级应用
docker 网络高级应用就涉及到 Linux network namespace,Namespace(命名空间)技术是一种隔离技术,常用的Namespace有 user namespace, process namespace, network namespace等
在Docker容器中,不同的容器通过Network namespace进行了隔离,也就是不同的容器有各自的IP地址,路由表等,互不影响。
ip 是 linux 系统下强大的网络配置工具,我们可以使用 ip 命令来配置管理 network namespace。
1. 网络命名空间 network namespace
brtcl 命令需要安装,如果是Ubuntu的系统,可以通过 apt-get install bridge-utils 安装;如果是Centos系统,可以通过 sudo yum install bridge-utils 来安装。
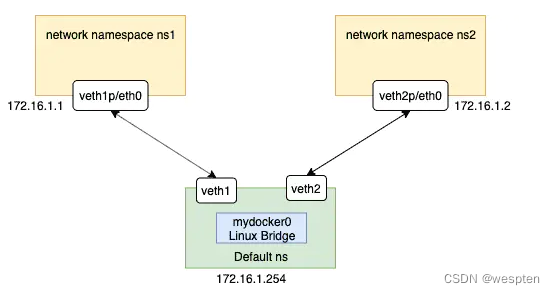
创建 bridge:
[vagrant@docker-host1 ~]$ sudo brctl addbr mydocker0
[vagrant@docker-host1 ~]$ brctl show
bridge name bridge id STP enabled interfaces
mydocker0 8000.000000000000 no
[vagrant@docker-host1 ~]$准备一个shell脚本,脚本名字叫 add-ns-to-br.sh:
#!/bin/bash
bridge=$1
namespace=$2
addr=$3
vethA=veth-$namespace
vethB=eth00
sudo ip netns add $namespace
sudo ip link add $vethA type veth peer name $vethB
sudo ip link set $vethB netns $namespace
sudo ip netns exec $namespace ip addr add $addr dev $vethB
sudo ip netns exec $namespace ip link set $vethB up
sudo ip link set $vethA up
sudo brctl addif $bridge $vethA脚本执行:
[vagrant@docker-host1 ~]$ sh add-ns-to-br.sh mydocker0 ns1 172.16.1.1/16
[vagrant@docker-host1 ~]$ sh add-ns-to-br.sh mydocker0 ns2 172.16.1.2/16把mydocker0这个bridge up起来:
[vagrant@docker-host1 ~]$ sudo ip link set dev mydocker0 up验证:
[vagrant@docker-host1 ~]$ sudo ip netns exec ns1 bash
[root@docker-host1 vagrant]# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: eth00@if6: <broADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether f2:59:19:34:73:70 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.16.1.1/16 scope global eth00
valid_lft forever preferred_lft forever
inet6 fe80::f059:19ff:fe34:7370/64 scope link
valid_lft forever preferred_lft forever
[root@docker-host1 vagrant]# ping 172.16.1.2
PING 172.16.1.2 (172.16.1.2) 56(84) bytes of data.
64 bytes from 172.16.1.2: icmp_seq=1 ttl=64 time=0.029 ms
64 bytes from 172.16.1.2: icmp_seq=2 ttl=64 time=0.080 ms
^C
--- 172.16.1.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 0.029/0.054/0.080/0.026 ms
[root@docker-host1 vagrant]#对外通信:
NAT with Linux and iptables - Tutorial (Introduction)
2. 使用 ip netns 命令操作 network namespace
ip netns 命令用来操作 network namespace,创建一个 network namespace:
# ip netns add nstest列出系统中所有的 network namespace:
# ip netns list
nstest# ip netns delete nstest在一个 network namespace 中执行命令:
# ip netns exec nstest ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:003. 使用ip命令为network namespace配置网卡
使用 ip netns add 命令创建一个 network namespace 后,就生成一个独立的网络空间,它默认只有一个 lo 设备,这样我们可以根据需求添加网卡、配置IP、设置路由规则等。
之前创建的 lo 设备,现在来启动它:
# ip netns exec nstest ip link set dev lo up在主机上创建两张虚拟网卡 veth-a 和 veth-b:
ip link add veth-a type veth peer name veth-b将 veth-b 设备添加到 nstest 这个 network namespace 中,veth-a 留在主机中:
# ip link set veth-b netns nstest现在 nstest 中就存在两块网卡 lo 和 veth-b 了:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNowN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
24: veth-b@if25: <broADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 32:fe:32:98:1f:15 brd ff:ff:ff:ff:ff:ff link-netnsid 0然后为网卡分配IP并启动网卡:
# ip addr add 10.0.0.1/24 dev veth-a
# ip link set dev veth-a ip
# ip link set dev veth-a up在 nstest 中配置 veth-a 并启动:
# ip netns exec nstest ip addr add 10.0.0.2/24 dev veth-b
# ip netns exec nstest ip link set dev veth-b up
# ip netns exec nstest ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNowN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
24: veth-b@if25: <broADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 32:fe:32:98:1f:15 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.0.2/24 scope global veth-b
valid_lft forever preferred_lft forever
inet6 fe80::30fe:32ff:fe98:1f15/64 scope link
valid_lft forever preferred_lft forever给两张网卡配置了 IP 后,就在各自的 network namespace 中生成一条路由,使用命令 ip route 命令可以查看:
# ip route
...
10.0.0.0/24 dev veth-a proto kernel scope link src 10.0.0.1
# ip netns exec nstest ip route
10.0.0.0/24 dev veth-b proto kernel scope link src 10.0.0.2 4. 将两个network namespace连接起来
我们再扩展之前的配置,利用 veth pair 设备连接两个 network namespace,结构如下图:
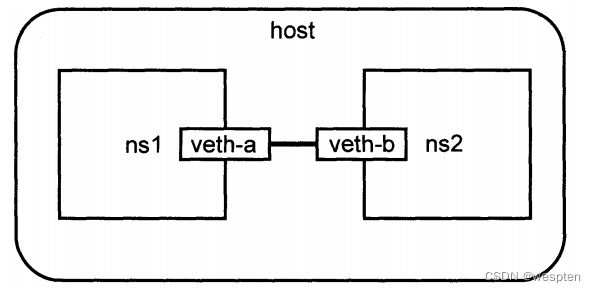
# 创建两个 network namespace
# ip netns add ns1
# ip netns add ns2
# 创建 veth pair 设备 veth-a,veth-b
# ip link add veth-a type veth peer name veth-b
# 将网卡放在两个 network namespace 中
# ip link set veth-a netns ns1
# ip link set veth-b netns ns2
# 启动网卡
# ip netns exec ns1 ip link set dev veth-a up
# ip netns exec ns2 ip link set dev veth-b up
# 分配ip
# ip netns exec ns1 ip addr add 10.0.0.1/24 dev veth-a
# ip netns exec ns2 ip addr add 10.0.0.2/24 dev veth-b
# ip netns exec ns1 ping 10.0.0.2
PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
64 bytes from 10.0.0.2: icmp_seq=1 ttl=64 time=0.155 ms5. 使用 ip 命令配置 docker 容器网络
ip 命令不能直接管理到 docker 容器所在的网络,但经过相应的处理可以达到我们的目的。使用 ip netns list 查看到的 network namespace 保存在目录 /var/run/netns 下,使用 docker 创建的容器的同时也会创建一个 network namespace。
# docker run -itd --name test1 centos /bin/bash
# docker inspect test1 --format "{{.State.Pid}}"
14404
# 查询到 docker 容器对应的 pid 之后,我们就可以使用 pid 查看对应的 network namespace
# ll /proc/14404/ns/net
lrwxrwxrwx 1 root root 0 Sep 8 23:02 /proc/14404/ns/net -> net:[4026532749]每个 network namespace 中的进程有不同的 net:[] 号码分配,这些号码代表不同的 network namespace,拥有相同 net:[] 号码的进程属于同一个 network namespace。只要将 docker 创建的 network namespace 的文件链接到 /var/run/netns 目录下,就可以使用 ip netns 命令进行操作了。
# mkdir -p /var/run/netns
# ln -s /proc/14404/ns/net /var/run/netns/test1
# ip netns list
test1 (id: 4)
ns2 (id: 3)
ns1 (id: 2)
# ip netns exec test1 ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNowN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
25: eth0@if26: <broADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever在没有特权模式下(--privileged)下不能直接在容器内部操作网络,所以这种方法是比较好的一个方法了,同时 linux 还有一个命令,能更简便的操作 docker 网络 nsenter。
# nsenter --target 14404 --mount --uts --ipc --net --pid4、pipework原理解析
除了 docker 本身的网络模型外,我们可以自定义 docker 网络,比如将 docker 容器网络配置到本地主机网络中,这样就可以将容器当作应用的节点使用,实现容器与容器,容器与主机的通信了。
# 启动一个名为 test1 的 docker 容器
# docker run -itd --name test1 --net=none ubuntu /bin/bash
# 创建一个供容器连接的网桥 br0
# brctl addbr br0
# ip link set br0 up
# 将主机 ens33 桥接到 br0 上,并把 ens33 的 ip 配置在 br0 上。
# ip addr add 192.168.10.100/24 dev br0; \
ip addr del 192.168.10.10/24 dev ens33; \
brctl addif br0 ens33; \
ip route del default; \
ip route add default via 192.168.10.254 dev br0
# pid=$(docker inspect --format '{{ .State.Pid }}' test1)
# mkdir -p /var/run/netns
# ln -s /proc/$pid/ns/net /var/run/netns/$pid
# ip link add veth-a type veth peer name veth-b
# brctl addif br0 veth-a
# ip link set veth-a up
# ip link set veth-b netns $pid
# ip netns exec $pid ip link set dev veth-b name ens33
# ip netns exec $pid ip link set ens33 up
# ip netns exec $pid ip addr add 192.168.10.101/24 dev ens33
# ip netns exec $pid ip route add default via 192.168.10.254
以上的命令封装成 shell 脚本的话就是工具 pipework 了。
1)配置Linux网桥连接容器并配置容器IP地址,先下载 pipework:
# git clone https://github.com/jpetazzo/pipework
# 如果没有 git 命令,可以使用 docker 来实现
# docker run -it --rm -v ./pipework:/gitdata alpine/git clone https://github.com/jpetazzo/pipework /gitdata/
# cp ~/pipework/pipework /usr/local/sbin/使用命令完成之前的操作:
pipework br0 test1 192.168.10.102/24@192.168.10.2这行命令执行的操作如下:
- 查看主机使用存在br0的网桥,不存在就创建;
- 向test1中加入一块名为eth1的网卡,并配置IP地址为192.168.10.102/24;
- 若test1中已经有默认路由,则删掉,把192.168.10.102设为默认路由的网关;
- 将test1容器连接到之前创建的网桥br0上。
2)使用macvlan设备将容器连接到本地网络
macvlan设备是从网卡上虚拟出的一块新网卡,它和主网卡分别有不同的MAC地址,可以配置独立的IP地址。使用pipework配置macvlan命令如下:
# pipework ens33 test1 192.168.10.104/24@192.168.10.2操作过程如下:
- 从主机的ens33上创建一块macvlan设备,将macvlan设备放入到test1中并命名为eth1;
- 为test1中新添加的网卡设备配置IP地址为192.168.10.104/24;
- 若test1中已经有默认路由,则删掉,把192.168.10.2设为默认路由的网关
也可以使用ip命令创建macvlan设备:
# 用命令在ens33上创建macvlan设备
# ip link add link ens33 dev ens33m mtu 1500 type macvlan mode bridge
# 将创建的macvlan设备放入Docker容器中,并重命名为eth1
# ip link set ens33m netns $NSPID
# ip netns exec $NSPID ip link set ens33m name eth1从ens33上创建出的macvlan设备放在test1后,test1容器就可以和本地网络中的其他主机通信了。但是,如果在test1所在的主机上却不能访问test1,因为进出macvlan设备的流量被主网卡ens33隔离了,主机不能通过ens33访问macvlan。要解决这个问题,需要在ens33在再创建一个macvlan设备,将ens33的IP地址转移到这个macvlan设备上。
# ip addr del 192.168.10.10/24 dev ens33; \
> ip link add link ens33 dev ens33m type macvlan mode bridge; \
> ip link set ens33m up; \
> ip addr add 192.168.10.10/24 dev ens33m; \
> route add default gw 192.168.10.23)使用DHCP获取容器IP
pipework ens33 test1 dhcpDHCP服务除了要求主机环境存在DHCP服务器外,Docker主机上还必须安装有DHCP客户端(udhcp,dhclient,dhcpcd)。
4)使用Open vSwitch
Open vSwitch 是一个开源的虚拟交换机,相比于 Linux Bridge,Open vSwitch 支持 VLAN,Qos 等功能,同时还提供对 OpenFlow 协议的支持,可以很好的于SDN(软件定义网络)体系融合。因此,利用 Open vSwitch 能很好的扩展 docker 网络。
pipework 目前也只支持 Open vSwitch 的简单功能:
# pipework ovsbr0 test1 192.168.20.100/245)设置网卡MAC地址
pipework 除了支持给网卡配置IP外,还可以指定网卡的MAC地址。具体用法是再IP参数后面再加一个MAC地址的参数:
# pipework br0 test1 dhcp fa:de:b0:99:52:1c5、端口映射实现容器对外通信
docker的容器除了能连接网络外,在许多时候,我们需要让多个容器来协同完成任务。为了应对这样的需求,docker 提供了两种机制:
容器启动时,如果不指定对应的参数,容器外部是无法访问容器内部的。要让外部能访问内部的话,在容器启动时利用选项 -p | -P 可以实现端口的映射。
# docker run -d -P training/webapp python app.py
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7a91ece91213 training/webapp "python app.py" 8 seconds ago Up 6 seconds 0.0.0.0:32768->5000/tcp eloquent_fermat
# docker logs -f web //查看应用的信息 指定 -P 随机分配主机的32768端口映射到容器的5000端口,访问主机的32768输出如下:
# curl http://127.0.0.1:32768
Hello World!利用选项 -p | -P 能实现不同的映射类型。
1. 指定端口映射:-p HostPort:ContainerPort:
# docker run -d -p 5000:5000 training/webapp python app.py 2. 多个端口映射,多次使用 -p 实现:
# docker run -d -p 5001:5000 -p 3000:80 training/webapp python app.py 3. 映射到指定地址的指定端口 -p IP:HostPort:ContainerPort:
# docker run -d -p 127.0.0.1:5000:5000 training/webapp python app.py4. 映射到指定地址的任意端口 -p IP::ContainerPort:
# docker run -d -p 127.0.0.1::5000 training/webapp python app.py这样我们就可以通过访问 127.0.0.1:5001 来访问容器的 5000 端口。
5. 映射到指定的协议 tcp 或 udp -p IP::ContainerPort/protocol,指定udp端口:
# docker run -d -p 127.0.0.1:5000:5000/udp training/webapp python app.py6. 查看docker容器的映射端口可以使用inspect命令,同时docker port 命令可以让我们更快捷地查看端口的绑定情况。:
# docker port f061c03d
5000/udp -> 127.0.0.1:50007. Bridge模式端口映射
查看路由:
$ ip route
default via 10.0.2.2 dev eth0 proto dhcp metric 100
10.0.2.0/24 dev eth0 proto kernel scope link src 10.0.2.15 metric 100
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.200.0/24 dev eth1 proto kernel scope link src 192.168.200.10 metric 101iptable 转发规则:
$ sudo iptables --list -t nat
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere !loopback/8 ADDRTYPE match dst-type LOCAL
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.17.0.0/16 anywhere
Chain DOCKER (2 references)
target prot opt source destination
RETURN all -- anywhere anywhere创建容器:
$ docker container run -d --rm --name web -p 8080:80 Nginx
$ docker container inspect --format '{{.NetworkSettings.IPAddress}}' web
$ docker container run -d --rm --name client busyBox /bin/sh -c "while true; do sleep 3600; done"
$ docker container inspect --format '{{.NetworkSettings.IPAddress}}' client
$ docker container exec -it client wget http://172.17.0.2查看iptables的端口转发规则:
[vagrant@docker-host1 ~]$ sudo iptables -t nat -nvxL
Chain PREROUTING (policy ACCEPT 10 packets, 1961 bytes)
pkts bytes target prot opt in out source destination
1 52 DOCKER all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
Chain INPUT (policy ACCEPT 9 packets, 1901 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 2 packets, 120 bytes)
pkts bytes target prot opt in out source destination
0 0 DOCKER all -- * * 0.0.0.0/0 !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
Chain POSTROUTING (policy ACCEPT 4 packets, 232 bytes)
pkts bytes target prot opt in out source destination
3 202 MASQUERADE all -- * !docker0 172.17.0.0/16 0.0.0.0/0
0 0 MASQUERADE tcp -- * * 172.17.0.2 172.17.0.2 tcp dpt:80
Chain DOCKER (2 references)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- docker0 * 0.0.0.0/0 0.0.0.0/0
1 52 DNAT tcp -- !docker0 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:8080 to:172.17.0.2:80docker中使用-p <外网端口>:<内网端口>来实现端口转发,如:docker container run -d --rm --name web -p 8080:80 Nginx,将web容器将Nginx的80端口映射为宿主机的8080端口,此过程中实际是在iptables中生效。
查看iptables(iptables -t nat -nvxL | grep -A 5 'Chain DOCKER')信息发现,iptables增加了DNAT(Destination NAT)规则,此规则将宿主机的8080转发为172.17.0.4即容器Nginx的80端口。

6、容器互联
容器的连接系统是除了端口映射外另一种可以与容器中应用进行交互的方式,它会在源和接收容器之间创建一个隧道,接收容器可以看到源容器指定的信息。
同一台宿主机上的多个docker容器之间如果想进行通信,可以通过使用容器的ip地址来通信,也可以通过宿主机的ip加上容器暴露出的端口来通信,前者会导致ip址址的硬编码,不方便迁移,并且容器重启后ip地址会改变,除非使用固定的ip,后都的通信方式比较单一,只能依靠监听在暴露出的端口的进程来进来有限通信。
通信docker的link机制可以通过一个name来和另一个容器通信,link机制方便了容器去发现其它的容器并且可以安全的传递一些连接信息给其它的容器。
1)使用连接系统容器互联
端口映射并不是唯一把 docker 连接到另一个容器的方法,docker 有一个连接系统允许将多个容器连接在一起,共享连接信息。docker 连接会创建一个父子关系,其中父容器可以看到子容器的信息。
当我们创建一个容器的时候,docker 会自动对它进行命名。另外,我们也可以使用 --name 标识来命名容器,例如:
runoob@runoob:~$ docker run -d -P --name runoob training/webapp python app.py
43780a6eabaaf14e590b6e849235c75f3012995403f97749775e38436db9a441我们可以使用 docker ps 命令来查看容器名称:
runoob@runoob:~$ docker ps -l
CONTAINER ID IMAGE COMMAND ... PORTS NAMES
43780a6eabaa training/webapp "python app.py" ... 0.0.0.0:32769->5000/tcp runoob下面先创建一个新的 Docker 网络:
$ docker network create -d bridge test-net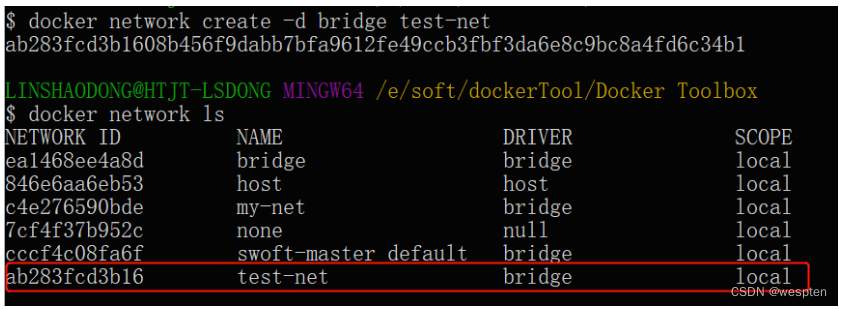
参数说明:
-d:参数指定 Docker 网络类型,有 bridge、overlay,其中 overlay 网络类型用于 Swarm mode。
运行一个容器并连接到新建的 test-net 网络:
$ docker run -itd --name test1 --network test-net ubuntu /bin/bash打开新的终端,再运行一个容器并加入到 test-net 网络:
$ docker run -itd --name test2 --network test-net ubuntu /bin/bash
通过 ping 来证明 test1 容器和 test2 容器建立了互联关系。
如果 test1、test2 容器内中无 ping 命令,则在容器内执行以下命令安装 ping(即学即用:可以在一个容器里安装好,提交容器到镜像,在以新的镜像重新运行以上俩个容器)。
apt-get update
apt install iputils-ping在 test1 容器输入以下命令:

同理在 test2 容器也会成功连接到:
这样,test1 容器和 test2 容器建立了互联关系,如果你有多个容器之间需要互相连接,推荐使用 Docker Compose。
2)使用--link参数可以让容器间建立安全的连接进行交互
容器的互联(linking) 是一种让多个容器中的应用进行快速交互的方式。 它会在源和接收容器之间创建连接关系, 接收容器可以通过容器名快速访问到源容器, 故不用指定具体的IP地址。
连接系统依据容器的名称来执行,所以在启动容器的时候需要使用 --name 选项指定容器名称,虽然容器启动时会被随机分配一个名称,但互联是指定名称还是必要的。
# docker run -d -p 127.0.0.1:5000:5000 --name web training/webapp python app.py注:docker 名唯一。执行docker run时,如果加上--rm参数,容器在终止后悔立即被删除,但是不能与-d参数一同使用。
docker run -it --rm ubuntu:17.10 cat /etc/resolv.conf容器互联使用选项 --link name:alias,前者是容器名,后者是自定义的别名。
连接系统根据容器的名称执行,所以需要自定义一个较为简单容易区分的容器名。自定义命名使用--name参数,例如我们创建一个数据库容器 db ,再创建一个web应用容器 web 连接 db:
# docker run -d --name db training/postgres
# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
73fd1af29108 training/postgres "su postgres -c '/us…" 5 seconds ago Up 4 seconds 5432/tcp db# docker run -d -P --name web --link db:db training/webapp python app.py
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7e983b169dd5 training/webapp "python app.py" 6 seconds ago Up 4 seconds 0.0.0.0:32769->5000/tcp web
73fd1af29108 training/postgres "su postgres -c '/us…" About a minute ago Up About a minute 5432/tcp db这样一来,web容器就和db容器建立互联关系了。
docker相当于在两个互联的容器之间创建了一个虚机通道, 而且不用映射它们的端口到宿主主机上。 在启动db容器的时候并没有使用 -p 和 -P 标记, 从而避免了暴露数据库服务端口到外部网络上。
3)docker两种公开连接信息方式
- 更新环境变量;
- 更新 /etc/hosts 文件。
重新启动容器查看它互联的环境变量:
# docker run -it -P --name web2 --link db:db --rm training/webapp env
TERM=xterm
DB_PORT=tcp://172.17.0.3:5432
DB_PORT_5432_TCP=tcp://172.17.0.3:5432
DB_PORT_5432_TCP_ADDR=172.17.0.3
DB_PORT_5432_TCP_PORT=5432
DB_PORT_5432_TCP_PROTO=tcp
DB_NAME=/web4/db
DB_ENV_PG_VERSION=9.3
HOME=/root其中DB_开头的环境变量是供web容器连接db容器使用,前缀采用大写的连接别名。
除了环境变量, docker 还添加 host 信息到⽗容器的 /etc/hosts 的文件。 下面是⽗容器 web 的 hosts文件:
172.17.0.3 db 73fd1af29108
172.17.0.4 7e983b169dd5172.17.0.3 指定 db 容器和对应的 id,172.17.0.4 是 web 容器。当然使用多个 --link 就可以连接多个容器。
4)配置DNS
我们可以在宿主机的 /etc/docker/daemon.json 文件中增加以下内容来设置全部容器的 DNS:
{
"dns" : [
"114.114.114.114",
"8.8.8.8"
]
}设置后,启动容器的 DNS 会自动配置为 114.114.114.114 和 8.8.8.8。配置完,需要重启 docker 才能生效,查看容器的 DNS 是否生效可以使用以下命令,它会输出容器的 DNS 信息:
$ docker run -it --rm ubuntu cat etc/resolv.conf
如果只想在指定的容器设置 DNS,则可以手动指定容器的配置:
$ docker run -it --rm -h host_ubuntu --dns=114.114.114.114 --dns-search=test.com ubuntu参数说明:
-h HOSTNAME 或者 --hostname=HOSTNAME: 设定容器的主机名,它会被写到容器内的 /etc/hostname 和 /etc/hosts。
--dns=IP_ADDRESS: 添加 DNS 服务器到容器的 /etc/resolv.conf 中,让容器用这个服务器来解析所有不在 /etc/hosts 中的主机名。
--dns-search=DOMAIN: 设定容器的搜索域,当设定搜索域为 .example.com 时,在搜索一个名为 host 的主机时,DNS 不仅搜索 host,还会搜索 host.example.com。
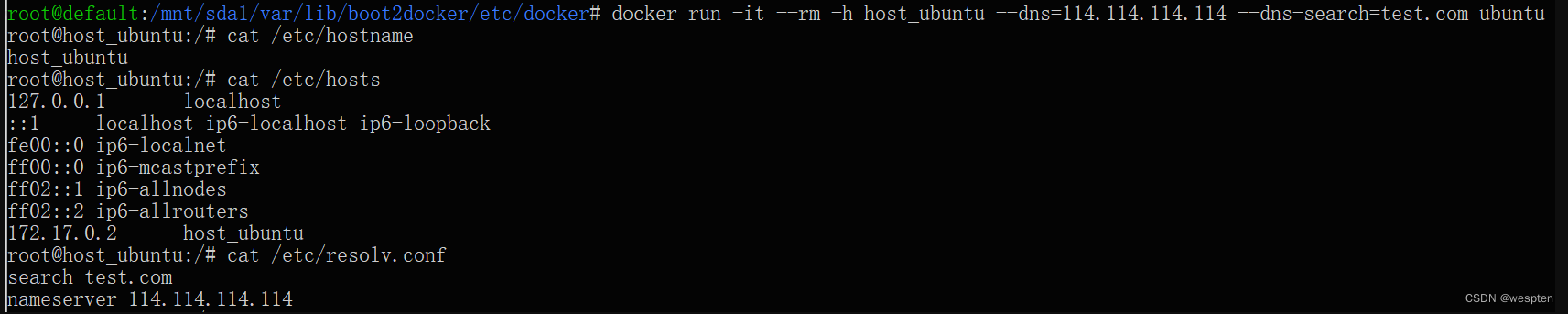
如果在容器启动时没有指定 --dns 和 --dns-search,Docker 会默认用宿主主机上的 /etc/resolv.conf 来配置容器的 DNS。
7、Docker 跨主机通讯
准备两台或以上的主机或者虚拟机,相关环境如下:
- 主机1:配置两张网卡 br0 192.168.10.10,ens33桥接br0,ens37(不需要IP),docker环境
- 主机2:配置两张网卡 br0 192.168.10.11,ens33桥接br0,ens37(不需要IP),docker环境
1)桥接方式
ens33 作为外部网卡,使 docker 容器可以和外部通信,ens37 作为内部网卡,和 docker0 桥接(所以不需要IP)让不同的主机间的容器可以相互通信。配置如下:
主机1配置:
1. 修改 docker 的启动参数文件 /etc/docker/daemon.json 并重启 docker daemon:
# vim /etc/docker/daemon.json
{
"bip": "172.17.0.1/16",
"fixed-cidr": "172.17.18.1/24"
}
# systemctl restart docker2. 将 ehs33 网卡接入到 docker0 网桥中:
# brctl addif docker0 ens373. 添加容器con1:
# docker run -it --rm --name con1 buysBox sh主机2配置:
1. 修改 docker 的启动参数文件 /etc/docker/daemon.json 并重启 docker daemon:
# vim /etc/docker/daemon.json
{
"bip": "172.17.0.2/16",
"fixed-cidr": "172.17.19.1/24"
}
# systemctl restart docker2. 将 ehs33 网卡接入到 docker0 网桥中:
# brctl addif docker0 ens373. 添加容器con2:
# docker run -it --rm --name con1 busyBox sh这时容器 con1 和 con2 既能彼此通信,也可以访问外部IP。
容器con1向容器con2发送数据的过程是这样的:首先,通过查看本身的路由表发现目的地址和自己处于同一网段,那么就不需要将数据发往网关,可以直接发给con2,con1通过ARP广播获取到con2的MAC地址;然后,构造以太网帧发往con2即可。此过程数据中docker0网桥充当普通的交换机转发数据帧。
2)直接路由
直接路由方式是通过在主机中添加静态路由实现。例如有两台主机host1和host2,两主机上的Docker容器是独立的二层网络,将con1发往con2的数据流先转发到主机host2上,再由host2转发到其上的Docker容器中,反之亦然。
注:这个实现失败!!!
直接路由的网络拓扑图如下:
host1上:
1. 配置 docker0 ip:
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.1.254/24"
}
# systemctl restart docker2. 添加路由,将目的地址为172.17.2.0/24的包转发到host2:
# route add -net 172.17.2.0 netmask 255.255.255.0 gw 192.168.10.113. 配置iptables规则:
# iptables -t nat -F POSTROUTING
# iptables -t nat -A POSTROUTING s 172.17.1.0/24 ! -d 172.17.0.0/16 -j MASQUERADE4. 打开端口转发:
# echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf5. 启动容器con1:
# docker run -it --name --rm --name con1 busyBox shhost2上:
1. 1. 配置 docker0 ip:
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.2.254/24"
}
# systemctl restart docker2. 添加路由,将目的地址为172.17.1.0/24的包转发到host1:
# route add -net 172.17.1.0 netmask 255.255.255.0 gw 192.168.10.103. 配置iptables规则:
# iptables -t nat -F POSTROUTING
# iptables -t nat -A POSTROUTING s 172.17.2.0/24 ! -d 172.17.0.0/16 -j MASQUERADE4. 打开端口转发:
# echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf5. 启动容器con2:
# docker run -it --name --rm --name con2 busyBox sh以上介绍的两种跨主机通信方式简单有效,但都要求主机都在同一个局域网中。
3)OVS 划分 VLAN
VLAN(Virtual Local Area Network)即虚拟局域网,按照功能、部门等因素将网络中的机器进行划分,使之属于不同的部分,每一个部分形成一个虚拟的局域网络,共享一个单独的广播域,从而避免因一个网络内的主机过多而产生的广播风暴问题。
VLAN如何在一个二层网络中区分不同流量呢?IEEE 的802.1q协议规定了VLAN的实现方法,即在传统的以太网帧中在添加一个VLAN tag字段,用于标识不同的VLAN。这样,支持VLAN的交换机在转发帧时,不仅会关注MAC地址,还会考虑到VLAN tag字段。VLAN tag中包含TPID、PCP、CFI、VID,其中VID(VLAN ID)部分用来具体指出帧属于哪个VLAN。VID占12为,所以取值范围为0到4095。

交换机有两种类型的端口access端口和trunk端口。图中,Port1、Port2、Port5、Port6、Port8为access端口,每个access端口都会分配一个VLAN ID,标识它所连接的设备属于哪一个VLAN。当数据帧从外界通过access端口进入交换机时,数据帧原本是不带tag的,access端口给数据帧打上tag(VLAN ID即为access端口所分配的VLAN ID);当数据帧从交换机内部通过access端口发送时,数据帧的VLAN ID必须和access端口的VLAN ID一致,access端口才接收此帧,接着access端口将帧的tag信息去掉,再发送出去。Port3,Port4为trunk端口,trunk端口不属于某个特定的VLAN,而是交换机和交换机之间多个VLAN的通道。trunk端口声明了一组VLAN ID,表明只允许带有这些VLAN ID的数据帧通过,从trunk端口进入和出去的数据帧都是带tag的(不考虑默认VLAN的情况)。PC1和PC3属于VLAN100,PC2和PC4属于VLAN200,所以PC1和PC3处于同一个二层网络中,PC2和PC4处于同一个二层网络中。尽管PC1和PC2连接在同一台交换机中,但它们之间的通信时需要经过路由器的。
VLAN tag又是如何发挥作用的呢?当PC1向PC3发送数据时,PC1将IP包封装在以太帧中,帧在目的MAC地址为PC3的地址,此时帧并没有tag信息。当帧到达Port1是,Port1给帧打上tag(VID=100),帧进入switch1,然后帧通过Port3,Port4到达Switch2(Port3、Port4允许VLAN ID为100、200的帧通过)。在switch2中,Port5所标记的VID帧相同,MAC地址也匹配,帧就发送到Port5中,Port5将帧的tag信息去掉,然后发给PC3。由于PC2、PC4于PC1的VLAN不同,因此收不到PC1发出的帧。
4)单主机docker容器的VLAN划分
docker默认网络模式下,所有容器都连在docker0网桥上。docker0网桥是普通的Linux网桥,不支持VLAN功能,这里就使用Open vSwitch代替。

接下来我们就来尝试在主机1上实现图中的效果。
1. 在主机上创建4个 docker 容器 con1、con2、con3、con4:
# docker run -itd --name con1 busyBox sh
# docker run -itd --name con2 busyBox sh
# docker run -itd --name con3 busyBox sh
# docker run -itd --name con4 busyBox sh2. 下载open vswitch,并启动:
# yum install -y openvswitch
# systemctl start openvswitch3. 使用pipework将con1、con2划分到一个VLAN中:
# pipework ovs0 con1 192.168.0.1/24 @100
# pipework ovs0 con2 192.168.0.2/24 @1004. 使用pipework将con3、con4划分到一个VLAN中:‘
# pipework ovs0 con3 192.168.0.3/24 @200
# pipework ovs0 con4 192.168.0.4/24 @200这样一来con1和con2,con3和con4就也是互相通信,但con1和con3是互相隔离的。使用Open vSwitch配置VLAN,创建access端口和trunk端口的命令如下:
# ovs-vsctl add port ovs0 port1 tag=100
# ovs-vsctl add port ovs0 port2 trunk=100,2005)多主机docker容器的VLAN划分
host1上:
# docker run -itd --net=none --name con1 busyBox sh
# docker run -itd --net=none --name con2 busyBox sh
# pipework ovs0 con1 192.168.0.1/24 @100
# pipework ovs0 con2 192.168.0.2/24 @200
# ovs-vsctl add-port ovs0 eth1 host2上:
# docker run -itd --net=none --name con3 busyBox sh
# docker run -itd --net=none --name con4 busyBox sh
# pipework ovs0 con3 192.168.0.3/24 @100
# pipework ovs0 con4 192.168.0.4/24 @200
# ovs-vsctl add-port ovs0 eth1 6)Overlay技术模型
使用VLAN来隔离docker容器网络有多方面的限制:
- VLAN是在二层帧上,要求主机在同个网络中
- VLAN ID只有12比特单位,可用的数量只有4000多个
- VLAN配置较繁琐。
因此现在比较普遍的解决方式为Overlay虚拟化网络技术。
Overlay网络也就是隧道技术,它将一种网络协议包装在另一种协议中传输。隧道被广泛应用于连接因使用不同网络而被隔离的主机和网络,使用隧道技术搭建的网络就是所谓的Overlay网络,它能有效地覆盖在基础网络上。
在传输过程中,将以太帧封装在IP包中,通过中间地因特网,最后传输到目的网络中再解封装,这样来保证二层帧头再传输过程中不改变。在多租户情况下,就采用不同租户不同隧道地方式进行隔离。
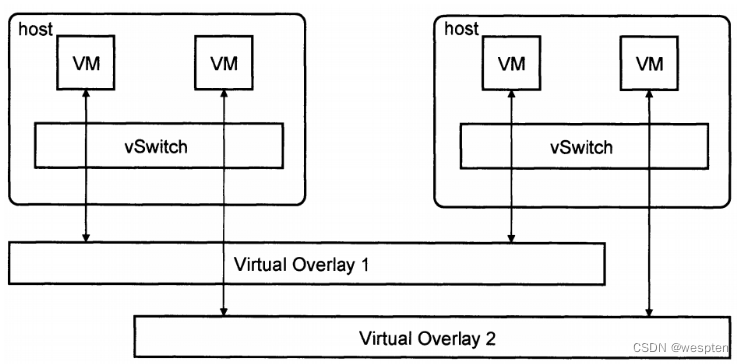
目前Overlay技术有VXLAN(Virtual Extensible LAN)和NVGRE(Network Virtualization using Generic Routing Encapsulation)。VXLAN是将以太网报文封装在UDP传输层上地一种隧道转发模式,它采用24位比特标识二层网络分段,称为VNI(VXLAN Network Idenfier),类似于VLAN ID地作用。NVGRE同VXLAN类似,它使用GRE方法来打通二层与三层之间的通路,采用24位比特的GRE key来作为网络标识(TNI)。
7)Overlay配合consul实现跨主机通信
准备两台或以上的主机或者虚拟机,相关环境如下:
- 主机1:配置两张网卡 ens33 192.168.10.10,docker环境
- 主机2:配置两张网卡 ens33 192.168.10.11,docker环境
- 主机3:consul 环境 192.168.10.12:8500
① 单通道实现容器互通
在两主机上配置docker启动的配置文件:
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"cluster-store": "consul://192.168.10.12:8500",
"cluster-advertise": "ens33:2376"
}
# systemctl restart docker同样生效的是启动脚本:/etc/systemd/system/docker.service.d/10-machine.conf:
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2376 -H unix:///var/run/docker.sock --storage-driver overlay2 --tlsverify --tlscacert /etc/docker/ca.pem --tlscert /etc/docker/server.pem --tlskey /etc/docker/server-key.pem --label provider=generic --cluster-store=consul://192.168.10.12:8500 --cluster-advertise=ens33:2376
Environment=这个时候,在192.168.10.12:8500的consul上就存储了docker的注册信息了。
在主机1上创建网络:
# docker network create -d overlay ov-net1
# docker network ls
NETWORK ID NAME DRIVER ScopE
ce13051e6bff bridge bridge local
ff8cf4a7552a host host local
8514568883d2 none null local
adef0a0c4d39 ov-net1 overlay global这是我们在主机2上也能看到新建的网络ov-net1,因为ov-net1网络已经存储到consul上,两个主机都可以看到该网络。
两个主机上容器:
# host1上
# docker run -itd --name con1 --network ov-net1 busyBox
# host2上
# docker run -itd --name con2 --network ov-net1 busyBox容器上分别生成两张网卡eth0 10.0.0.2/24,eth1 172.18.0.1/24,eth0连接外部网络,走overlay模式;eth1连接内部网络,连接docker-gwbridge。
② overlay网络隔离
那overlay这么实现网络的隔离呢?其实也很简单,就是利用多个overlay网络实现,不同overlay网络之间就存在隔离:
# docker network create -d overlay --subnet 10.22.1.0/24 ov-net2--subnet 参数用来限制分配子网的范围:
# docker run -itd --name con3 --network ov-net2 busyBox
# docker exec -it con3 ping 172.18.0.2
PING 172.18.0.2 (172.18.0.2): 56 data bytes创建容器con3并绑定网络ov-net2,con3不能ping通con1。
8) GRE实现docker容器跨网络通信
NVGRE使用GRE协议来封装需要传送的数据,GRE协议可以用来封装其他网络层的协议。
如图的网络如何通信呢?通过在双方路由器上配置GRE隧道实现。从IP地址为192.168.1.1/24的主机A ping IP地址为192.168.2.1/24的主机B中,主机A构造好IP包后,通过查看路由表发现目的地址和本身不在同一个子网中,要将其转发到默认网关192.168.1.254上。主机A将IP包封装在以太网帧中,源MAC地址为本身网卡的MAC地址,目的MAC地址为网关的MAC地址。
网关路由器收到数据帧后,去掉帧头,将IP取出,匹配目的IP地址和自身的路由表,确定包需要从GRE隧道设备发出,这就对这个IP包做GRE封装,即加上GRE协议头部。封装完成后,该包是不能直接发往互联网的,需要生成新的IP包作为载体来运输GRE数据包,新IP包的源地址为1.1.1.1,目的地址为2.2.2.2。并装在新的广域网二层帧中发出去。在传输过程中,中间的节点仅能看到最外层的IP包。当IP包到达2.2.2.2的路由器后,路由器将外层IP头部和GRE头部去掉,得到原始的IP数据包,再将其发往192.168.2.1。对于原始IP包来说,两个路由器之间的传输过程就如同单链路上的一样。
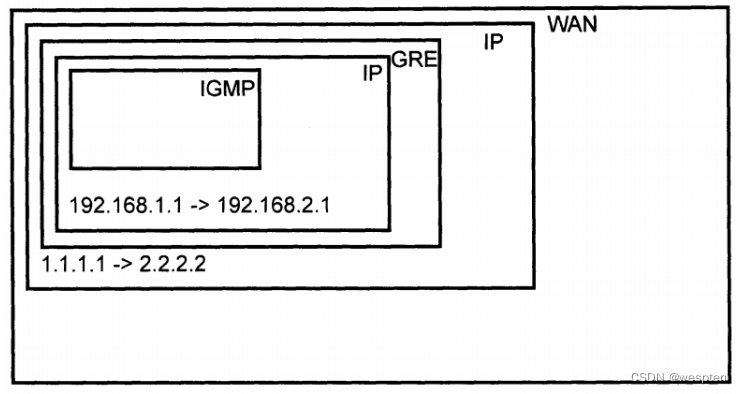
① 容器在同一子网中
host1上:
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.42.1/16",
"fixed-cidr": "172.17.1.1/24"
}
# systemctl restart docker2. 创建ovs0网桥,并将ovs0连在docker0上:
# ovs-vsctl add-br ovs0
# brctl addif docker0 ovs03. 在ovs0上创建GRE隧道:
# ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.105.235host2上
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.42.1/16",
"fixed-cidr": "172.17.1.1/24"
}
# systemctl restart docker2. 创建ovs0网桥,并将ovs0连在docker0上:
# ovs-vsctl add-br ovs0
# brctl addif docker0 ovs03. 在ovs0上创建GRE隧道:
# ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.105.91验证:
创建容器:
# host1上
# docker run -it --rm --name con1 busyBox sh
# ping 172.17.2.0
# host2上
# docker run -it --rm --name con2 busyBox sh
# ping 172.17.1.0con1向con2发送数据时,会发送ARP请求获取con2的MAC地址。APR请求会被docker0网桥洪泛到所有端口,包括和ovs0网桥相连的ovs0端口。ARP请求达到ovs0网桥后,继续洪泛,通过gre0隧道端口到达host2上的ovs0中,最后到达con2。host1和host2处在不同网络中,该ARP请求如何跨越中间网络到达host2呢?ARP请求经过gre0时,会首先加上一个GRE协议的头部,然后再加上一个源地址为10.10.105.91、目的地址为10.10.105.235的IP协议头部,再发送给host2。这里GRE协议封装的是二层以太网帧,而非三层IP数据包。con1获取到con2的MAC地址之后,就可以向它发送数据,发送数据包的流程和发送ARP请求的流程类似。只不过docekr0和ovs0会学习到con2的MAC地址该从哪个端口发送出去,而无需洪泛到所有端口。
② 容器在不同子网中
host1上:
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.1.254/16",
"fixed-cidr": "172.17.1.1/24"
}
# systemctl restart docker2. 创建ovs0网桥,并将ovs0连在docker0上:
# ovs-vsctl add-br ovs0
# brctl addif docker0 ovs03. 在ovs0上创建一个internal类型的端口rou0,并分配一个不引起冲突的私有IP:
# ovs-vsctl add-port ovs0 rou0 -- set interface rou0 type=internal
# ifconfig rou0 192.168.1.1/24
# 将通往docker容器的流量路由到rou0
# route add -net 172.17.0.0/16 dev rou04. 在ovs0上创建GRE隧道:
# ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.105.2355. 删除并创建iptables规则:
# iptables -t nat -D POSTROUTING -s 172.17.0.0/24 ! -o ens33 -j MASQUERADE
# iptables -t nat -A POSTROUTING -s 172.17.0.0/24 ! -o ens33 -j MASQUERADE host2上:
# vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://dhq9bx4f.mirror.aliyuncs.com"],
"bip": "172.17.2.254/16",
"fixed-cidr": "172.17.2.1/24"
}
# systemctl restart docker2. 创建ovs0网桥,并将ovs0连在docker0上:
# ovs-vsctl add-br ovs0
# brctl addif docker0 ovs03. 在ovs0上创建一个internal类型的端口rou0,并分配一个不引起冲突的私有IP:
# ovs-vsctl add-port ovs0 rou0 -- set interface rou0 type=internal
# ifconfig rou0 192.168.1.1/24
# 将通往docker容器的流量路由到rou0
# route add -net 172.17.0.0/16 dev rou04. 在ovs0上创建GRE隧道:
# ovs-vsctl add-port ovs0 gre0 -- set interface gre0 type=gre options:remote_ip=10.10.103.915. 删除并创建iptables规则:
# iptables -t nat -D POSTROUTING -s 172.17.0.0/24 ! -o eth0 -j MASQUERADE
# iptables -t nat -A POSTROUTING -s 172.17.0.0/24 ! -o eth0 -j MASQUERADE 七、DockerFile开发
Dockerfile 是一个文本格式的配置文件,通过一个指令来实现想要的功能,用户可以使用 Dockerfile 来快速创建自定义的镜像。
Dockerfile由一行行命令行组成,每条指令可带多个参数,并且支持以#开头的注释行。
| 指令 | 对象 | 含义 |
|---|---|---|
| FROM | 镜像 | 指定新镜像所基于的镜像,必须为第一条指令 |
| MAINTAINER | 名字 | 新镜像的维护人信息 |
| RUN | 命令 | 在所基于的镜像上执行命令,并提交到新镜像中 |
| EXPOSE | 端口号 | 指定新镜像加载到Docker时开启的端口号 |
| ENV | 环境变量 变量值 | 设置一个环境变量的值,会被后面的RUN使用 |
| ADD | 源文件/目录 目标文件/目录 | 将源文件复制到目标文件,源文件要与Docker位于同一目录下,或者为一个URL |
| copY | 源文件/目录 目标文件/目录 | 将本地主机上的源文件/目录复制到目标地点,源文件/目录要与Dockerfile在同一目录下 |
| VOLUME | ["目录"] | 在容器中创建一个挂载点 |
| USER | 用户名 /UID | 指定运行容器时的用户 |
| workdir | 路径 | 为后续的RUN、CMD、ENTRYPOINT指定工作目录 |
| ONBUILD | 命令 | 指定所生成的镜像作为一个基础镜像时所要运行的命令 |
| CMD | ["要运行的程序","参数1","参数2"] | 指定启动容器时运行的命令或脚本,只能有一条CMD命令,多条时只有最后一条被执行 |
主体内容分为四部分:基础镜像信息、维护者信息、镜像操作指令和容器启动时执行指令。
| 部分 | 命令 |
|---|---|
| 基础镜像信息 | FROM |
| 维护者信息 | MAINTAINER |
| 镜像操作指令 | RUN、ENV、copY、ADD、EXPOSE、workdir、ONBUILD、USER、VOLUME等 |
| 容器启动时执行指令 | CMD、ENTRYPOINT |
Dockerfile指令的一般格式为INSTRUCTION arguments,包括”配置指令“(配置镜像信息)和“操作指令”(具体执行操作):
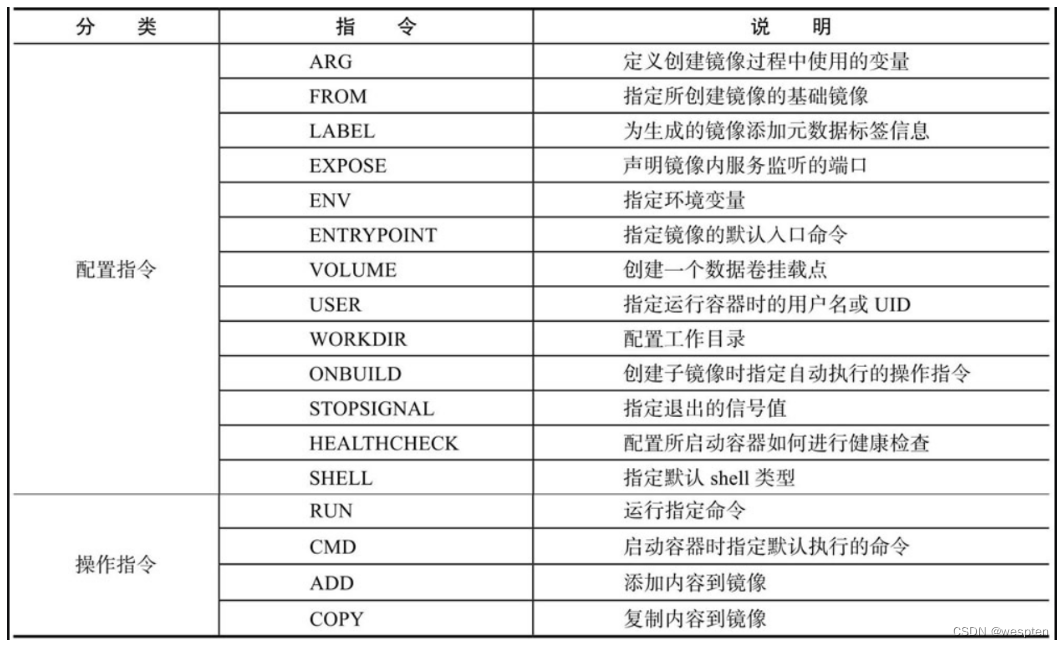
1)配置指令
① ARG
定义创建镜像过程中使用的变量,格式为:
ARG<name>[=<default value>]在执行docker build时, 可以通过 -build-arg[=] 来为变量赋值。 当镜像编译成功后, ARG指定的变量将不再存在(ENV指定的变量将在镜像中保留)。
Docker内置了一些镜像创建变量, 用户可以直接使用而无需声明, 包括(不区分大小写) HTTP_PROXY、 HTTPS_PROXY、 FTP_PROXY、NO_PROXY。`
② FROM
指定所创建镜像的基础信息。
格式:
FROM <image> [AS name] 或 FROM <image>:<tag> [AS <name> 或 FROM <image>@<DIGEST> [AS <name>]任何Dockerfile中第一条指令必须为FROM指令。如果在同一个Dockerfile中创建多个镜像时,可以使用多个FROM指令(每个镜像一次):
ARG VERSION=1.0
FROM debian:${VERSION}③ LABEL
LABEL指令可以为生成的镜像添加元数据标签信息。这些信息可以用来辅助过滤出特定的镜像。
格式:
LABEL <key>=<value> <key>=<value> <key>=<value>....如:
LABEL version="1.0" author="hello"④ EXPOSE
声明镜像内服务监听的端口。
格式:
EXPOSE <port>=[<port>/<protocol>......]如:
EXPOSE 22 808433注意该指令只是起到声明作用,并不会自动完成端口映射。如果要映射端口出来,在启动容器时可以使用-P参数或-p参数。
⑤ ENV
指定环境变量,在镜像生成过程中会被后续的RUN指令使用,在镜像启动的容器中也会存在。
格式:
ENV <key> <value> 或 ENV <key>=<value>......指令指定的环境变量在运行时可以被覆盖:
docker run -env <key>=<value> build_image。ARG 和 ENV 是经常容易被混淆的两个Dockerfile的语法,都可以用来设置一个“变量”。 但实际上两者有很多的不同。
FROM ubuntu:21.04
RUN apt-get update && \
apt-get install -y wget && \
wget https://github.com/ipinfo/cli/releases/download/ipinfo-2.0.1/ipinfo_2.0.1_linux_amd64.tar.gz && \
tar zxf ipinfo_2.0.1_linux_amd64.tar.gz && \
mv ipinfo_2.0.1_linux_amd64 /usr/bin/ipinfo && \
rm -rf ipinfo_2.0.1_linux_amd64.tar.gzENV:
FROM ubuntu:21.04
ENV VERSION=2.0.1
RUN apt-get update && \
apt-get install -y wget && \
wget https://github.com/ipinfo/cli/releases/download/ipinfo-${VERSION}/ipinfo_${VERSION}_linux_amd64.tar.gz && \
tar zxf ipinfo_${VERSION}_linux_amd64.tar.gz && \
mv ipinfo_${VERSION}_linux_amd64 /usr/bin/ipinfo && \
rm -rf ipinfo_${VERSION}_linux_amd64.tar.gzARG:
FROM ubuntu:21.04
ARG VERSION=2.0.1
RUN apt-get update && \
apt-get install -y wget && \
wget https://github.com/ipinfo/cli/releases/download/ipinfo-${VERSION}/ipinfo_${VERSION}_linux_amd64.tar.gz && \
tar zxf ipinfo_${VERSION}_linux_amd64.tar.gz && \
mv ipinfo_${VERSION}_linux_amd64 /usr/bin/ipinfo && \
rm -rf ipinfo_${VERSION}_linux_amd64.tar.gz区别:
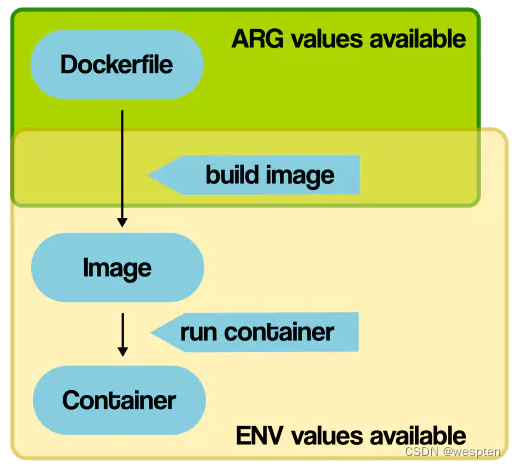
ARG可以在镜像build的时候动态修改value, 通过 --build-arg:
$ docker image build -f .\Dockerfile-arg -t ipinfo-arg-2.0.0 --build-arg VERSION=2.0.0 .
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
ipinfo-arg-2.0.0 latest 0d9c964947e2 6 seconds ago 124MB
$ docker container run -it ipinfo-arg-2.0.0
root@b64285579756:/#
root@b64285579756:/# ipinfo version
2.0.0
root@b64285579756:/#ENV 设置的变量可以在Image中保持,并在容器中的环境变量里。
⑥ ENTRYPOINT
ENTRYPOINT 也可以设置容器启动时要执行的命令,但是和CMD是有区别的。
CMD 设置的命令,可以在docker container run 时传入其它命令,覆盖掉 CMD 的命令,但是 ENTRYPOINT 所设置的命令是一定会被执行的。
ENTRYPOINT 和 CMD 可以联合使用,ENTRYPOINT 设置执行的命令,CMD传递参数。
格式:
ENTRYPOINT ["executable", "param1","param2"] //exec调用执行;
ENTRYPOINT command param1 param2 //shell中执行把Dockerfile build成一个叫 demo-cmd 的镜象:
FROM ubuntu:21.04
CMD ["echo", "hello docker"]$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
demo-cmd latest 5bb63bb9b365 8 days ago 74.1MBbuild成一个叫 demo-entrypoint 的镜像:
FROM ubuntu:21.04
ENTRYPOINT ["echo", "hello docker"]$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
demo-entrypoint latest b1693a62d67a 8 days ago 74.1MBCMD的镜像,如果执行创建容器,不指定运行时的命令,则会默认执行CMD所定义的命令,打印出hello docker:
$ docker container run -it --rm demo-cmd
hello docker但是如果我们docker container run的时候指定命令,则该命令会覆盖掉CMD的命令,如:
$ docker container run -it --rm demo-cmd echo "hello world"
hello world但是ENTRYPOINT的容器里ENTRYPOINT所定义的命令则无法覆盖,一定会执行:
$ docker container run -it --rm demo-entrypoint
hello docker
$ docker container run -it --rm demo-entrypoint echo "hello world"
hello docker echo hello world
$CMD和ENTRYPOINT同时支持shell格式和Exec格式。
Shell格式:
CMD echo "hello docker"
ENTRYPOINT echo "hello docker"Exec格式:
以可执行命令的方式。
ENTRYPOINT ["echo", "hello docker"]
CMD ["echo", "hello docker"]注意shell脚本的问题:
FROM ubuntu:21.04
ENV NAME=docker
CMD echo "hello $NAME"我们要把上面的CMD改成Exec格式,下面这样改是不行的,大家可以试试。
FROM ubuntu:21.04
ENV NAME=docker
CMD ["echo", "hello $NAME"]它会打印出 hello $NAME , 而不是 hello docker ,那么需要怎么写呢? 我们需要以shell脚本的方式去执行:
FROM ubuntu:21.04
ENV NAME=docker
CMD ["sh", "-c", "echo hello $NAME"]⑦ VOLUME
创建一个数据卷挂载点,Dockerifle中加入VOLUME就能将容器的数据持续化到对应的目录。
格式:
VOLUME ["/data"]运行容器时可以从本地主机或其他容器挂载数据卷,一般用来存放数据库和需要保持的数据等。
$ ls
Dockerfile my-cron
$ more Dockerfile
FROM alpine:latest
RUN apk update
RUN apk --no-cache add curl
ENV SUPERCRONIC_URL=https://github.com/aptible/supercronic/releases/download/v0.1.12/supercronic-linux-amd64 \
SUPERCRONIC=supercronic-linux-amd64 \
SUPERCRONIC_SHA1SUM=048b95b48b708983effb2e5c935a1ef8483d9e3e
RUN curl -fsSLO "$SUPERCRONIC_URL" \
&& echo "${SUPERCRONIC_SHA1SUM} ${SUPERCRONIC}" | sha1sum -c - \
&& chmod +x "$SUPERCRONIC" \
&& mv "$SUPERCRONIC" "/usr/local/bin/${SUPERCRONIC}" \
&& ln -s "/usr/local/bin/${SUPERCRONIC}" /usr/local/bin/supercronic
copY my-cron /app/my-cron
workdir /app
VOLUME ["/app"]
# RUN cron job
CMD ["/usr/local/bin/supercronic", "/app/my-cron"]
$
$ more my-cron
*/1 * * * * date >> /app/test.txtsupercronic:https://github.com/aptible/supercronic/ 这个专为容器而生的计划任务工具my-cron。
使用的my-cron就是一个crontab格式的计划任务,比如, 每隔一分钟输出时间到一个文件里。
crontab规则的网站https://crontab.guru
构建镜像:
$ docker image build -t my-cron .
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
my-cron latest e9fbd9a562c9 4 seconds ago 24.7MB创建容器(不指定-v参数)
此时Docker会自动创建一个随机名字的volume,去存储我们在Dockerfile定义的volume VOLUME ["/app"]
- 查看所有的VOLUME:docker volume ls
- 查看VOLUME的详细信息:docker volume inspect [volume-id]
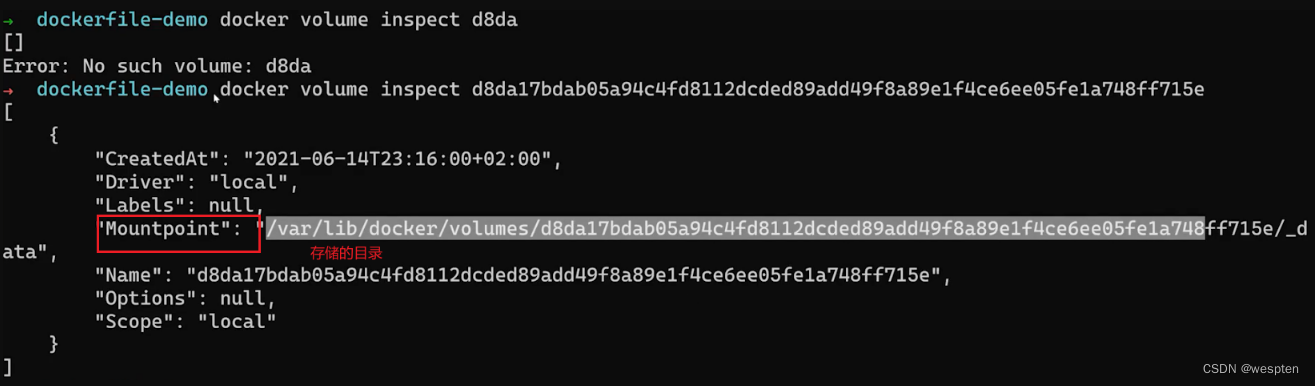
查看volume目录:

在这个Volume的mountpoint可以发现容器创建的文件:
$ docker run -d my-cron
9a8fa93f03c42427a498b21ac520660752122e20bcdbf939661646f71d277f8f
$ docker volume ls
DRIVER VOLUME NAME
local 043a196c21202c484c69f2098b6b9ec22b9a9e4e4bb8d4f55a4c3dce13c15264
$ docker volume inspect 043a196c21202c484c69f2098b6b9ec22b9a9e4e4bb8d4f55a4c3dce13c15264
[
{
"CreatedAt": "2021-06-22T23:06:13+02:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/043a196c21202c484c69f2098b6b9ec22b9a9e4e4bb8d4f55a4c3dce13c15264/_data",
"Name": "043a196c21202c484c69f2098b6b9ec22b9a9e4e4bb8d4f55a4c3dce13c15264",
"Options": null,
"Scope": "local"
}
]创建容器(指定-v参数)
在创建容器的时候通过 -v 参数我们可以手动的指定需要创建Volume的名字,以及对应于容器内的路径,这个路径是可以任意的,不必需要在Dockerfile里通过VOLUME定义
比如我们把上面的Dockerfile里的VOLUME删除:
FROM alpine:latest
RUN apk update
RUN apk --no-cache add curl
ENV SUPERCRONIC_URL=https://github.com/aptible/supercronic/releases/download/v0.1.12/supercronic-linux-amd64 \
SUPERCRONIC=supercronic-linux-amd64 \
SUPERCRONIC_SHA1SUM=048b95b48b708983effb2e5c935a1ef8483d9e3e
RUN curl -fsSLO "$SUPERCRONIC_URL" \
&& echo "${SUPERCRONIC_SHA1SUM} ${SUPERCRONIC}" | sha1sum -c - \
&& chmod +x "$SUPERCRONIC" \
&& mv "$SUPERCRONIC" "/usr/local/bin/${SUPERCRONIC}" \
&& ln -s "/usr/local/bin/${SUPERCRONIC}" /usr/local/bin/supercronic
copY my-cron /app/my-cron
workdir /app
# RUN cron job
CMD ["/usr/local/bin/supercronic", "/app/my-cron"]重新build镜像,然后创建容器,加-v(即volume)参数-v [volume_name]:[dir_name]:
$ docker image build -t my-cron .
$ docker container run -d -v cron-data:/app my-cron
43c6d0357b0893861092a752c61ab01bdfa62ea766d01d2fcb8b3ecb6c88b3de
$ docker volume ls
DRIVER VOLUME NAME
local cron-data
$ docker volume inspect cron-data
[
{
"CreatedAt": "2021-06-22T23:25:02+02:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/cron-data/_data",
"Name": "cron-data",
"Options": null,
"Scope": "local"
}
]
$ ls /var/lib/docker/volumes/cron-data/_data
my-cron
$ ls /var/lib/docker/volumes/cron-data/_data
my-cron test.txtVolume也创建了。
环境清理
强制删除所有容器,系统清理和volume清理:
$ docker rm -f $(docker container ps -aq)
$ docker system prune -f
$ docker volume prune -fBind Mount使用
data volume的缺陷:在Windows环境的docker中,无法查看volume所在的文件路径。使用bind mount就能在Windows本地打开volume所在目录。
在构建容器加上 -v 参数时,映射的路径改为自定义路径即可:
1. Windows环境:docker run -d -v ${pwd}:/app my-cron,花括号中代表当前路径,也可自定义;
2. 在Mac和Linux环境:docker run -d -v $(pwd):/app my-cron,括号中代表当前路径;
Windows环境需要先把目标路径在Docker Desktop中添加到设置里面:
镜像准备:
$ docker pull MysqL:5.7
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
MysqL 5.7 2c9028880e58 5 weeks ago 447MB容器创建:
$ docker container run --name some-MysqL -e MysqL_ROOT_PASSWORD=my-secret-pw -d -v MysqL-data:/var/lib/MysqL MysqL:5.7
02206eb369be08f660bf86b9d5be480e24bb6684c8a938627ebfbcfc0fd9e48e
$ docker volume ls
DRIVER VOLUME NAME
local MysqL-data
$ docker volume inspect MysqL-data
[
{
"CreatedAt": "2021-06-21T23:55:23+02:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/MysqL-data/_data",
"Name": "MysqL-data",
"Options": null,
"Scope": "local"
}
]
$数据库写入数据:
进入MysqL的shell,密码是 my-secret-pw。
$ docker container exec -it 022 sh
# MysqL -u root -p
Enter password:
Welcome to the MysqL monitor. Commands end with ; or \g.
Your MysqL connection id is 2
Server version: 5.7.34 MysqL Community Server (GPL)
copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered Trademark of Oracle Corporation and/or its
affiliates. Other names may be Trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MysqL> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| MysqL |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
MysqL> create database demo;
Query OK, 1 row affected (0.00 sec)
MysqL> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| demo |
| MysqL |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
MysqL> exit
Bye
# exit查看data volume:
$ docker volume inspect MysqL-data
[
{
"CreatedAt": "2021-06-22T00:01:34+02:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/MysqL-data/_data",
"Name": "MysqL-data",
"Options": null,
"Scope": "local"
}
]
$ ls /var/lib/docker/volumes/MysqL-data/_data
auto.cnf client-cert.pem ib_buffer_pool ibdata1 performance_schema server-cert.pem
ca-key.pem client-key.pem ib_logfile0 ibtmp1 private_key.pem server-key.pem
ca.pem demo ib_logfile1 MysqL public_key.pem sys
$⑧ USER
指定运行容器时的用户名或UID,后续的RUN等指令也会使用指定的用户身份。
格式:
USER daemon当服务不需要管理员权限时,可以通过该指令指定运行用户,并且可以在Dockerfile中创建所需要的用户,如:
RUN groupadd -r postgree && useradd --no-log-init -r -g postgres postgres⑨ workdir
为后续的RUN、CMD、ENTRYPOINT指令配置工作目录。
格式:
workdir /path/to/workdir可以使用多个workdir指令,后续命令如果参数是相对路径,则会基于之前指令指定的路径。如:
workdir /a
workdir b
workdir c
RUN pwd则最终路径为/a/b/c。
⑩ ONBUILD
格式:
ONBUILD [INSTRUCTION]⑪ HEALTHCHECK
配置所启动容器如何进行健康检查。
格式:
HEALTHCHECK [OPTIONS] CMD command //根据所执行命令返回值是否为0来判断;
HEALTHCHECK NONE //禁止基础镜像中的健康检查。OPTIONS支持如下参数:
- -interval=DURATION(default 30s):过多久检查一次;
- -timeout=DURATION(default 30s):每次检查等待结果的超时;
- -retries=N(default 3):如果失败了,重试几次才最终确定失败。
⑫STOPSIGNAL
指定所创建镜像启动的容器接收退出的信号值:
STOPSIGNAL signal⑬SHELL
指定其他命令使⽤ shell 时的默认 shell 类型:
SHELL `["executable", "parameters"]` 默认值为 ["/bin/sh", "-c"]。
对于Windows系统,Shell路径中使用了“\”作为分隔符, 建议在 dockerfile 开头添加 #escape='来指定转义符。
2)操作指令
① RUN
运行指定指令,格式:
RUN <command>或RUN ["executable","param1","param2"]注意后者指令会被解析为JSON数组,因此必须用双引号。
前者默认将在shell终端中运行命令,即/bin/sh -c;后者则使用exec执行,不会启动shell环境。
指定使用其他终端类型可以通过第二种方式实现, 例如RUN ["/bin/bash", "-c", "echo hello"]。
每条RUN指令将在当前镜像基础上执⾏指定命令, 并提交为新的镜像层。 当命令较长时可以使用\来换行, 例如:
RUN apt-get update \
&& apt-get install -y libsnappy-dev zlib1g-dev libbz2-dev \
&& rm -rf /var/cache/apt \
&& rm -rf /var/lib/apt/lists/*Dockerfile:
Image里安装软件,下载文件等。
FROM ubuntu:21.04
RUN apt-get update
RUN apt-get install -y wget
RUN wget https://github.com/ipinfo/cli/releases/download/ipinfo-2.0.1/ipinfo_2.0.1_linux_amd64.tar.gz
RUN tar zxf ipinfo_2.0.1_linux_amd64.tar.gz
RUN mv ipinfo_2.0.1_linux_amd64 /usr/bin/ipinfo
RUN rm -rf ipinfo_2.0.1_linux_amd64.tar.gz镜像的大小和分层:
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
ipinfo latest 97bb429363fb 4 minutes ago 138MB
ubuntu 21.04 478aa0080b60 4 days ago 74.1MB
$ docker image history 97b
IMAGE CREATED CREATED BY SIZE COMMENT
97bb429363fb 4 minutes ago RUN /bin/sh -c rm -rf ipinfo_2.0.1_linux_amd… 0B buildkit.dockerfile.v0
<missing> 4 minutes ago RUN /bin/sh -c mv ipinfo_2.0.1_linux_amd64 /… 9.36MB buildkit.dockerfile.v0
<missing> 4 minutes ago RUN /bin/sh -c tar zxf ipinfo_2.0.1_linux_am… 9.36MB buildkit.dockerfile.v0
<missing> 4 minutes ago RUN /bin/sh -c wget https://github.com/ipinf… 4.85MB buildkit.dockerfile.v0
<missing> 4 minutes ago RUN /bin/sh -c apt-get install -y wget # bui… 7.58MB buildkit.dockerfile.v0
<missing> 4 minutes ago RUN /bin/sh -c apt-get update # buildkit 33MB buildkit.dockerfile.v0
<missing> 4 days ago /bin/sh -c #(nop) CMD ["/bin/bash"] 0B
<missing> 4 days ago /bin/sh -c mkdir -p /run/systemd && echo 'do… 7B
<missing> 4 days ago /bin/sh -c [ -z "$(apt-get indextargets)" ] 0B
<missing> 4 days ago /bin/sh -c set -xe && echo '#!/bin/sh' > /… 811B
<missing> 4 days ago /bin/sh -c #(nop) ADD file:d6b6ba642344138dc… 74.1MB每一行的RUN命令都会产生一层image layer, 导致镜像的臃肿。
改进版Dockerfile:
FROM ubuntu:21.04
RUN apt-get update && \
apt-get install -y wget && \
wget https://github.com/ipinfo/cli/releases/download/ipinfo-2.0.1/ipinfo_2.0.1_linux_amd64.tar.gz && \
tar zxf ipinfo_2.0.1_linux_amd64.tar.gz && \
mv ipinfo_2.0.1_linux_amd64 /usr/bin/ipinfo && \
rm -rf ipinfo_2.0.1_linux_amd64.tar.gz指定dockerfile进行镜像构建
- 加上
-f参数
$ docker image build -f Dockerfile.good -t ipinfo-good:1.0 .
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
ipinfo-new latest fe551bc26b92 5 seconds ago 124MB
ipinfo latest 97bb429363fb 16 minutes ago 138MB
ubuntu 21.04 478aa0080b60 4 days ago 74.1MB
$ docker image history fe5
IMAGE CREATED CREATED BY SIZE COMMENT
fe551bc26b92 16 seconds ago RUN /bin/sh -c apt-get update && apt-get… 49.9MB buildkit.dockerfile.v0
<missing> 4 days ago /bin/sh -c #(nop) CMD ["/bin/bash"] 0B
<missing> 4 days ago /bin/sh -c mkdir -p /run/systemd && echo 'do… 7B
<missing> 4 days ago /bin/sh -c [ -z "$(apt-get indextargets)" ] 0B
<missing> 4 days ago /bin/sh -c set -xe && echo '#!/bin/sh' > /… 811B
<missing> 4 days ago /bin/sh -c #(nop) ADD file:d6b6ba642344138dc… 74.1MB
$② CMD
CMD可以用来设置容器启动时默认会执行的命令。
格式:
- CMD ["executable","param1","param2"]:相当于执行executable param1 param2,推荐方式;
- CMD command param1 param2:在默认的shell中执行,提供给需要交互的应用;
- CMD [“param1”,“param2”]:提供给ENTRYPOINT的默认参数;
FROM ubuntu:21.04
ENV VERSION=2.0.1
RUN apt-get update && \
apt-get install -y wget && \
wget https://github.com/ipinfo/cli/releases/download/ipinfo-${VERSION}/ipinfo_${VERSION}_linux_amd64.tar.gz && \
tar zxf ipinfo_${VERSION}_linux_amd64.tar.gz && \
mv ipinfo_${VERSION}_linux_amd64 /usr/bin/ipinfo && \
rm -rf ipinfo_${VERSION}_linux_amd64.tar.gz使用docker system prune -f可以将后台已经停止的容器全部删除,使用docker image prune -a可以将后台没有使用的镜像全部删除。
$ docker image build -t ipinfo .
$ docker container run -it ipinfo
root@8cea7e5e8da8:/#
root@8cea7e5e8da8:/#
root@8cea7e5e8da8:/#
root@8cea7e5e8da8:/# pwd
/
root@8cea7e5e8da8:/#默认进入到shell是因为在ubuntu的基础镜像里有定义CMD:
$docker image history ipinfo
IMAGE CREATED CREATED BY SIZE COMMENT
db75bff5e3ad 24 hours ago RUN /bin/sh -c apt-get update && apt-get… 50MB buildkit.dockerfile.v0
<missing> 24 hours ago ENV VERSION=2.0.1 0B buildkit.dockerfile.v0
<missing> 7 days ago /bin/sh -c #(nop) CMD ["/bin/bash"] 0B
<missing> 7 days ago /bin/sh -c mkdir -p /run/systemd && echo 'do… 7B
<missing> 7 days ago /bin/sh -c [ -z "$(apt-get indextargets)" ] 0B
<missing> 7 days ago /bin/sh -c set -xe && echo '#!/bin/sh' > /… 811B
<missing> 7 days ago /bin/sh -c #(nop) ADD file:d6b6ba642344138dc… 74.1MB注意:
每个Dockerfile只能由一条CMD命令。如果指定了多条命令,只有最后一条会被执行。
如果docker container run启动容器时指定了其它命令,则CMD命令会被忽略。
③ ADD
把本地的一个文件复制到镜像里,如果目标目录不存在,则会自动创建,格式为:
ADD <src> <dest> 将复制指定的<src>路径下内容到容器中的<dest>路径下。其中<src>可以时Dockerfile所在目录的一个相对路径(文件或目录),也可以是一个URL,还可以是一个tar文件(自动解压为目录)。<dest>可以时镜像内绝对路径,或者相对于工作目录(workdir)的相对路径。
把本地的 hello.py 复制到 /app 目录下。 /app这个folder不存在,则会自动创建:
FROM python:3.9.5-alpine3.13
ADD hello.tar.gz /app/ADD 比 copY高级一点的地方就是,如果复制的是一个gzip等压缩文件时,ADD会帮助我们自动去解压缩文件。
路径支持正则,如:
ADD *.c /code/workdir类似于切换目录cd操作,如果目标目录不存在会自动创建,且ADD和copY的文件会自动存放在workdir目录下:
FROM python:3.9.5-alpine3.13
workdir /app
ADD hello.tar.gz hello.py④ copY
复制内容到镜像。
格式:
copY <src> <dest>复制本地主机的<src>(为Dockerfile所在目录的相对路径,文件或目录)下内容到镜像中的<dest>,目标路径不存在时会自动创建,路径同样支持正则格式。
FROM python:3.9.5-alpine3.13
copY hello.py /app/hello.pycopYT于ADD指令功能类似,因此在 copY 和 ADD 指令中选择的时候,可以遵循这样的原则,所有的文件复制均使用 copY 指令,仅在需要自动解压缩的场合使用 ADD。
3)创建镜像
编写完Dockerfile之后,可以通过docker build命令来创建镜像。
格式:
docker build [OPTIONS] PATH [URL]-该命令将读取指定目录下(包括子目录)的Dockerfile,并将该路径下所有的数据作为上下文发送给Docker服务端,Docker服务端在校验Dockerfile格式通过后,逐条执行其中定义的指令,碰到ADD、copY和RUN指定会生成一层新的镜像。最终如果创建镜像成功,会返回最终镜像的ID。
如果上下文过大,会导致发送大量数据给服务端,延缓创建过程。因此除非是生成镜像所必须的文件,不然不要放到上下文路径下。如果使用非上下文路径下的Dockerfile,可以通过-f选项来指定其路径。
要指定生成镜像的标签信息,可以通过-t 选项。该选项可以重复使用多次为镜像一次添加多个名称。
docker build 支持以下的选项:
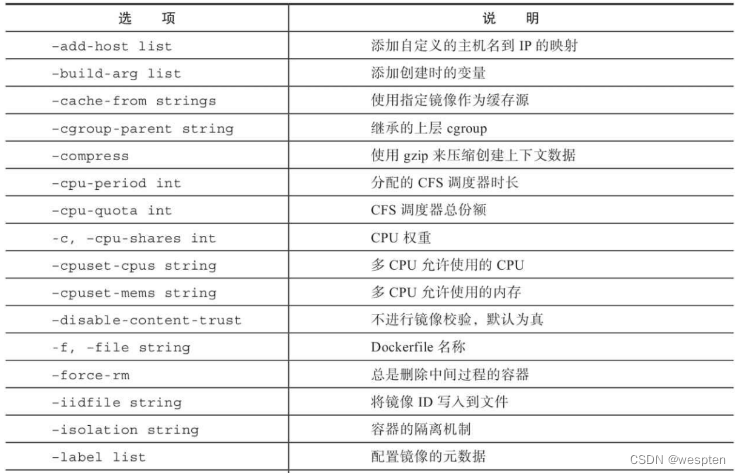
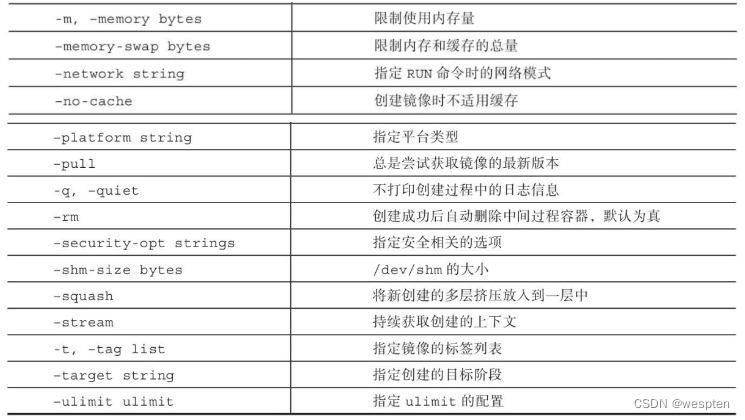
dockerfile 使用 FROM 指令指定父镜像,一般我们使用系统镜像来作为父镜像,但是我们也可以使用基础镜像(scratch)来作为父镜像:
FROM scratch
ADD binary /
CMD ["/binary"]docker 中镜像存在继承关系,用一张图来说明:
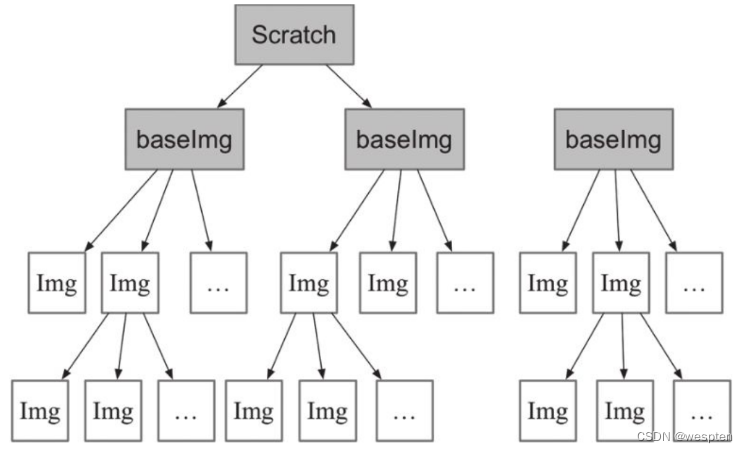
Docker build context
Docker是client-server架构,理论上Client和Server可以不在一台机器上。
在构建docker镜像的时候,需要把所需要的文件由CLI(client)发给Server,这些文件实际上就是build context:
$ dockerfile-demo more Dockerfile
FROM python:3.9.5-slim
RUN pip install flask
workdir /src
ENV FLASK_APP=app.py
copY app.py /src/app.py
EXPOSE 5000
CMD ["flask", "run", "-h", "0.0.0.0"]
$ dockerfile-demo more app.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, world!'构建的时候,第一行输出就是发送build context 11.13MB (这里是Linux环境下的log):
$ docker image build -t demo .
Sending build context to Docker daemon 11.13MB
Step 1/7 : FROM python:3.9.5-slim
---> 609da079b03a
Step 2/7 : RUN pip install flask
---> Using cache
---> 955ce495635e
Step 3/7 : workdir /src
---> Using cache
---> 1c2f968e9f9b
Step 4/7 : ENV FLASK_APP=app.py
---> Using cache
---> dceb15b338cf
Step 5/7 : copY app.py /src/app.py
---> Using cache
---> 0d4dfef28b5f
Step 6/7 : EXPOSE 5000
---> Using cache
---> 203e9865f0d9
Step 7/7 : CMD ["flask", "run", "-h", "0.0.0.0"]
---> Using cache
---> 35b5efae1293
Successfully built 35b5efae1293
Successfully tagged demo:latest. 这个参数就是代表了build context所指向的目录。
此文件与Dockerfile在同一目录下,内容写上要忽略的文件夹,如下面的.vscode/和env/,重新构建时就会忽略这两个文件夹
- 作用:一是提高构建镜像的速度;二是保护敏感文件等
.vscode/
env/
有了.dockerignore文件后,我们再build, build context就小了很多,4.096kB:
$ docker image build -t demo .
Sending build context to Docker daemon 4.096kB
Step 1/7 : FROM python:3.9.5-slim
---> 609da079b03a
Step 2/7 : RUN pip install flask
---> Using cache
---> 955ce495635e
Step 3/7 : workdir /src
---> Using cache
---> 1c2f968e9f9b
Step 4/7 : ENV FLASK_APP=app.py
---> Using cache
---> dceb15b338cf
Step 5/7 : copY . /src/
---> a9a8f888fef3
Step 6/7 : EXPOSE 5000
---> Running in c71f34d32009
Removing intermediate container c71f34d32009
---> fed6995d5a83
Step 7/7 : CMD ["flask", "run", "-h", "0.0.0.0"]
---> Running in 7ea669f59d5e
Removing intermediate container 7ea669f59d5e
---> 079bae887a47
Successfully built 079bae887a47
Successfully tagged demo:latest.dockerignore文件(每一行 添加一条匹配 模式)来让Docker忽略匹配路径或文件,在创建镜像时不将无关数据发送到服务端:
*/temP*
*/*/temP*
tmp?
~*
Dockerfile
!README.mddockerignore文件中模式语法支持Golang风格的路径正则格式:
- “*”表示任意多个字符;
- “? ”代表单个字符;
- “!”表示不匹配(即不忽略指定的路径或⽂件) ;
自17.05版本开始,Docker支持多步骤创建镜像特性,可以精简最终生成的镜像大小。例如我们先指定一个编译的环境镜像进行编译,在指定一个运行的镜像来运行编译的代码。
以 Go 语言为例,创建一个空目录,在目录中创建 Go 代码文件 main.go:
package main
import "fmt"
func main() {
fmt.Println("Hello World")
}编写 dockerfile:
FROM golang:1.9 as builder
RUN mkdir -p /go/src/test
workdir /go/src/test
copY main.go .
RUN CGO_ENABLED=0 GOOS=linux go build -o app .
FROM alpine:latest
workdir /root/
copY --from=builder /go/src/test/app .
CMD ["./app"]执行创建镜像:
使用多步骤发现生成的镜像很精简,当也可以用多个 dockerfile 实现这个功能,但需要两个 dockerfile,维护成本提高了。
4)dockerfile 要点
编写 dockerfile 存在注意的点,遵守这些点可以生成更精简的镜像:
- 精简镜像用途: 尽量让每个镜像的用途都比较集中单一, 避免构造大而复杂、 多功能的镜像;
- 选择合适的基础镜像: 容器的核心是应用。 选择过大的父镜像(如Ubuntu系统镜像) 会造成最终生成应用镜像的臃肿, 推荐选瘦身过的应用镜像(如node: slim) , 或者较为小巧的系统镜像(如alpine、 busyBox或debian) ;
- 提供注释和维护者信息: Dockerfile也是一种代码, 需要考虑方便后续的扩展和他人的使用;
- 正确使用版本号: 使用明确的版本号信息, 如1.0, 2.0,而非依赖于默认的latest。 通过版本号可以避免环境不一致导致的问题;
- 减少镜像层数: 如果希望所生成镜像的层数尽量少, 则要尽量合并RUN、 ADD和copY指令。 通常情况下, 多个RUN指令可以合并为一条RUN指令;
- 恰当使用多步骤创建(17.05+版本支持) : 通过多步骤创建, 可以将编译和运行等过程分开, 保证最终生成的镜像只包括运用行应所需要的最小化环境。 当然,用 户也可以通过分别构造编译镜像和运行镜像来达到类似的结果, 但这种方式需要维护多个Dockerfile。
- 使用.dockerignore文件: 使用它可以标记在执行docker build时忽略的路径和文件, 避免发送不必要的数据内容, 从而加快整个镜像创建过程。
- 及时删除临时文件和缓存文件: 特别是在执行apt-get指令后, /var/cache/apt下便会缓存了一些安装包;
- 提升生成速度: 如合理使用cache, 减少内容目录下的文件, 或使用.dockerignore文件指定等;
- 调整合理的指令顺序: 在开启cache的情况下, 内容不变的指令尽量放在前面, 这样可以尽量复用;
- 减少外部源的干扰: 如果确实要从外部引用数据, 需要指定持久的地址, 并带版本信息等, 让他人可以复用而不出错。
dockerfile通俗寿命:
FROM 这个镜像的妈妈是谁?(指定基础镜像)
MAINTAINER 告诉别人,谁负责养它?(指定维护者信息,可以没有,这只是一个标签,没有实际作用)
RUN 你想让它干啥(在命令前面加上RUN即可)
ADD 给它点创业资金(copY文件,会自动解压)与copY功能一样,但是copy不会自动解压
workdir 我是cd,今天刚化了妆(设置当前工作目录)
VOLUME 给它一个存放行李的地方(设置卷,挂载主机目录)
EXPOSE 它要打开的门是啥(指定对外的端口)(-P 随机端口)
CMD 奔跑吧,兄弟!(指定容器启动后的要干的事情)(容易被替换)
dockerfile其他指令:
copY 复制文件
ENV 环境变量
ENTRYPOINT 容器启动后执行的命令(无法被替换,启容器的时候指定的命令,会被当成参数)
合理使用Cache:
当某一层(layer)修改后,后面的layer都不能使用缓存。
Dockerfile修改之前:
FROM python:3.9.5-slim
copY app.py /zhangtao/app.py
RUN pip3 install flask
workdir /zhangtao
ENV FLASK_APP=app.py
EXPOSE 5000
CMD ["flask","run","-h","0.0.0.0"]如果修改了app.py,那么后面的layer均不能使用缓存。
调整Dockerfile的顺序:
FROM python:3.9.5-slim
RUN pip3 install flask
copY app.py /zhangtao/app.py
workdir /zhangtao
ENV FLASK_APP=app.py
EXPOSE 5000
CMD ["flask","run","-h","0.0.0.0"]调整之后pip3 install flask就能使用缓存,从而加快镜像的构建。
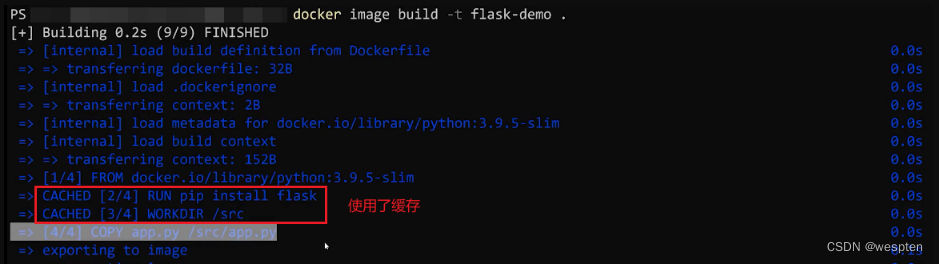
5)使用Docker run 覆盖 Dockerfile 中的设置
通常,我们首先定义Dockerfile文件,然后通过docker build命令构建得到镜像文件。然后,才能够基于镜像文件通过docker run启动一个容器的实例。
那么在启动一个容器的时候,就可以改变镜像文件中的一些参数,而镜像文件中的这些参数往往是通过Dockerfile文件定义的。
但并非Dockerfile文件中的所有定义都可以在启动容器的时候被重新定义。docker run不能覆盖的Dockerfile文件指令如下:
- FROM
- MAINTAINER
- RUN
- ADD
- copY
1. 覆盖ENTRYPOINT指令
Dockerfile文件中的ENTRYPOINT指令,用以给出容器启动后默认入口。
ENTRYPOINT指令给出容器启动后的默认行为,一般难以在启动容器时覆盖,但是可以追加命令参数。示例如下:
- docker run --entrypoint /bin/bash ...,给出容器入口的后续命令参数
- docker run --entrypoint="/bin/bash ..." ... ,给出容器的新Shell
- docker run -it --entrypoint="" MysqL bash ,重置容器入口
2. 覆盖CMD指令
Dockerfile文件中的CMD指令,给出容器启动后默认执行的指令。
可以在启动容器的时候,为docker run设置新的命令选项,从而覆盖掉Dockerfile文件中的CMD指令(不会再咨询Dockerfile文件中的CMD指令)。示例如下:
如果Dockerfile文件中还声明了ENTRYPOINT指令,则上述指令都将作为参数追加到ENTRYPOINT指令。
3. 覆盖EXPOSE指令
Dockerfile文件中的EXPOSE指令,用以向容器所在主机保留端口。
显然这是运行时容器的一个特性,所以docker run可以方便地覆盖该指令。示例如下:
- docker run --expose="port_number:port_number"
- docker run -p port_number:port_number/tcp ,打开指定范围的端口
- docker run --link="another_container_id" ,链接到其他容器
- docker run -P ,打开所有端口
4. 覆盖ENV指令
Dockerfile文件中的ENV指令,用以设置容器中的环境变量。
启动容器时,自动为容器设置如下环境变量:
- HOME,基于USER设置用户主目录
- HOSTNAME,默认容器的主机名
- PATH,默认:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
- TERM,默认xterm,如果容器被分配了伪TTY
docker run可以方便地覆盖该指令。
示例如下:
docker run -e "key=value" ... ,//设置新的环境变量key
docker run -h ... ,//覆盖HOSTNAME
docker run ubuntu /bin/bash -c export //通过脚本,设置或覆盖环境变量5. 覆盖VOLUME指令
Dockerfile文件中的VOLUME指令,用以为容器设置的data volumes。
- docker run -v ...
- docker run -volumes-from ...
6. 覆盖USER指令
容器内部的默认用户是root(uid=0)。
Dockerfile文件中可以通过USER指定其他用户为容器的默认用户。
- docker run -u="" ...
- docker run --user="" ...
docker run支持-u如下形式:
- user
- user:group
- uid
- uid:gid
- user:gid
- uid:group
7. 覆盖workdir指令
Dockerfile文件中的workdir指令,用以为后续指令设置工作目录。
如果设置的路径不存在,则创建该路径,即时在后续指令中根本未使用。
在一个,可以存在多个workdir。对于相对路径,后续指令继承前续指令。
在workdir中,可以引用前续已经定义的环境变量。
- docker run -w="" ...
- docker run --workdir="" ...
6)镜像的构建与分享
Dockerfile是用于构建docker镜像的文件,且Dockerfile里包含了构建镜像所需的“指令”。
1. 创建python程序
容器及进程,所以镜像就是一个运行这个进程所需要的环境。假如我们要在一台ubuntu 21.04上运行下面这个hello.py的Python程序。
print("hello docker")准备Python环境:
apt-get update && \
DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y python3.9 python3-pip python3.9-dev运行hello.py:
$ python3 hello.py
hello docker2. 创建Dockerfile
FROM ubuntu:21.04
RUN apt-get update && \
DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y python3.9 python3-pip python3.9-dev
ADD hello.py /
CMD ["python3", "/hello.py"]3. 镜像的构建
docker image build -t hello.py:1.0 .-
-t:tag指定镜像名称和版本
[root@localhost ~]# docker image build -t hello:1.0 .
Sending build context to Docker daemon 3.242GB
Step 1/4 : FROM ubuntu:21.04
21.04: Pulling from library/ubuntu
80d63867ecd7: Pull complete
Digest: sha256:26cd4ff32a9c031eaca3d6f589a7799f28b34a539e1bd81acbf1a6efeec4b1ce
Status: Downloaded newer image for ubuntu:21.04
---> de6f83bfe0b6
Step 2/4 : RUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y python3.9 python3-pip python3.9-dev
---> Running in 5e8b3201ac57
...4. 镜像的分享
首先需要dockerhub上注册账号,根据自己的账号id修改镜像的tag:
[root@localhost ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
hello 1.0 e3a733c6921a 3 minutes ago 207MB
Nginx latest ea335eea17ab 6 days ago 141MB
busyBox latest 7138284460ff 12 days ago 1.24MB
ubuntu 21.04 de6f83bfe0b6 7 weeks ago 80MB
jenkins/jenkins lts 619aabbe0502 3 months ago 441MB
prom/prometheus v2.20.0 0da625e71069 16 months ago 145MB
[root@localhost ~]#
[root@localhost ~]# docker image tag hello:1.0 insaneloafer/hello:1.0
[root@localhost ~]#
[root@localhost ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
hello 1.0 e3a733c6921a 10 minutes ago 207MB
insaneloafer/hello 1.0 e3a733c6921a 10 minutes ago 207MB
Nginx latest ea335eea17ab 6 days ago 141MB
busyBox latest 7138284460ff 12 days ago 1.24MB
ubuntu 21.04 de6f83bfe0b6 7 weeks ago 80MB
jenkins/jenkins lts 619aabbe0502 3 months ago 441MB
prom/prometheus v2.20.0 0da625e71069 16 months ago 145MB将image push到docker hub,登录docker hub:docker login 然后输入账号密码。进行image的push:
[root@localhost ~]# docker login
Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
Username: insaneloafer
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
[root@localhost ~]#
[root@localhost ~]# docker image push insaneloafer/hello:1.0
The push refers to repository [docker.io/insaneloafer/hello]
4dc361a50bd7: Pushed
b64918d42f0f: Pushed
14636cce64ea: Mounted from library/ubuntu
1.0: digest: sha256:ad2157dfe0eae8456c98644165c3f1f3cb091d667078c760e16d227652225ce1 size: 9485. 查看docker hub上的镜像
6. 镜像的拉取
[root@localhost ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
Nginx latest ea335eea17ab 6 days ago 141MB
busyBox latest 7138284460ff 12 days ago 1.24MB
jenkins/jenkins lts 619aabbe0502 3 months ago 441MB
prom/prometheus v2.20.0 0da625e71069 16 months ago 145MB
[root@localhost ~]#
[root@localhost ~]#
[root@localhost ~]# docker pull insaneloafer/hello:1.0
1.0: Pulling from insaneloafer/hello
80d63867ecd7: Pull complete
afd09be562fb: Pull complete
1a5879efd499: Pull complete
Digest: sha256:ad2157dfe0eae8456c98644165c3f1f3cb091d667078c760e16d227652225ce1
Status: Downloaded newer image for insaneloafer/hello:1.0
docker.io/insaneloafer/hello:1.0
[root@localhost ~]#
[root@localhost ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
insaneloafer/hello 1.0 e3a733c6921a 22 minutes ago 207MB
Nginx latest ea335eea17ab 6 days ago 141MB
busyBox latest 7138284460ff 12 days ago 1.24MB
jenkins/jenkins lts 619aabbe0502 3 months ago 441MB
prom/prometheus v2.20.0 0da625e71069 16 months ago 145MB7)镜像的多阶段构建
假如有一个C的程序,我们想用Docker去做编译,然后执行可执行文件:
#include <stdio.h>
void main(int argc, char *argv[])
{
printf("hello %s\n", argv[argc - 1]);
}本地测试(如果你本地有C环境):
$ gcc --static -o hello hello.c
$ ls
hello hello.c
$ ./hello docker
hello docker
$ ./hello world
hello world
$ ./hello friends
hello friends
$构建一个Docker镜像,因为要有C的环境,所以我们选择gcc这个image:
FROM gcc:9.4
copY hello.c /src/hello.c
workdir /src
RUN gcc --static -o hello hello.c
ENTRYPOINT [ "/src/hello" ]
CMD []build和测试:
$ docker build -t hello .
Sending build context to Docker daemon 5.12kB
Step 1/6 : FROM gcc:9.4
---> be1d0d9ce039
Step 2/6 : copY hello.c /src/hello.c
---> Using cache
---> 70a624e3749b
Step 3/6 : workdir /src
---> Using cache
---> 24e248c6b27c
Step 4/6 : RUN gcc --static -o hello hello.c
---> Using cache
---> db8ae7b42aff
Step 5/6 : ENTRYPOINT [ "/src/hello" ]
---> Using cache
---> 7f307354ee45
Step 6/6 : CMD []
---> Using cache
---> 7cfa0cbe4e2a
Successfully built 7cfa0cbe4e2a
Successfully tagged hello:latest
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
hello latest 7cfa0cbe4e2a 2 hours ago 1.14GB
gcc 9.4 be1d0d9ce039 9 days ago 1.14GB
$ docker run --rm -it hello docker
hello docker
$ docker run --rm -it hello world
hello world
$ docker run --rm -it hello friends
hello friends
$可以看到镜像非常的大,1.14GB
实际上当我们把hello.c编译完以后,并不需要这样一个大的GCC环境,一个小的alpine镜像就可以了,这时候我们就可以使用多阶段构建了:
FROM gcc:9.4 AS builder
copY hello.c /src/hello.c
workdir /src
RUN gcc --static -o hello hello.c
FROM alpine:3.13.5
copY --from=builder /src/hello /src/hello
ENTRYPOINT [ "/src/hello" ]
CMD []上面的Dockerfile中第一阶段用于构建,第二阶段用于执行。第一阶段通过AS来取别名,在第二阶段的copY中就可以使用--from=builder来引用第一阶段编译出来的hello文件。
$ docker build -t hello-apline -f Dockerfile-new .
Sending build context to Docker daemon 5.12kB
Step 1/8 : FROM gcc:9.4 AS builder
---> be1d0d9ce039
Step 2/8 : copY hello.c /src/hello.c
---> Using cache
---> 70a624e3749b
Step 3/8 : workdir /src
---> Using cache
---> 24e248c6b27c
Step 4/8 : RUN gcc --static -o hello hello.c
---> Using cache
---> db8ae7b42aff
Step 5/8 : FROM alpine:3.13.5
---> 6dbb9cc54074
Step 6/8 : copY --from=builder /src/hello /src/hello
---> Using cache
---> 18c2bce629fb
Step 7/8 : ENTRYPOINT [ "/src/hello" ]
---> Using cache
---> 8dfb9d9d6010
Step 8/8 : CMD []
---> Using cache
---> 446baf852214
Successfully built 446baf852214
Successfully tagged hello-apline:latest
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-alpine latest 446baf852214 2 hours ago 6.55MB
hello latest 7cfa0cbe4e2a 2 hours ago 1.14GB
demo latest 079bae887a47 2 hours ago 125MB
gcc 9.4 be1d0d9ce039 9 days ago 1.14GB
$ docker run --rm -it hello-alpine docker
hello docker
$ docker run --rm -it hello-alpine world
hello world
$ docker run --rm -it hello-alpine friends
hello friends
$可以看到这个镜像非常小,只有6.55MB。
8)安装并配置sshd服务
1. 编写dockerfile
mkdir -p /opt/dockerfile/centos6_ssh && cd /opt/dockerfile/centos6_ssh
#进入容器yum源可能会无效,需要在容器内设置下yum源,能用就不用设置了
[root@docker01 centos6_ssh]# cat >> dockerfile << 'EOF'
>
> FROM centos:6.9
> RUN sed -i "s|enabled=1|enabled=0|g" /etc/yum/pluginconf.d/fastestmirror.conf
> RUN mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
> RUN curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo
> RUN yum clean all
> RUN yum makecache
> RUN yum -y install openssh-server
> RUN /etc/init.d/sshd start
> RUN echo 123456 | passwd --stdin root
> CMD ["/usr/sbin/sshd","-D"]
>
> EOF
[root@docker01 ~]# cat /etc/resolv.conf
# Generated by NetworkManager
search localdomain
nameserver 192.168.23.2
nameserver 233.5.5.5 这个能解析yum源
2. docker build 构建镜像
在当前路径下生成一个镜像(.代表当前目录下有dockerfile文件,相当于执行这个文件):
[root@docker01 centos6_ssh]# docker build -t centos69-ssh:v2 . 

3. 启动容器
测试新构建的镜像:
[root@docker01 centos6_ssh]# docker run -d --name ren2 -p 1322:22 centos69-ssh:v2
[root@docker01 centos6_ssh]# docker ps -a -l --no-trunc //显示全ID
4. 登录创建好的容器
映射用的宿主机是1322端口:
[root@docker01 centos6_ssh]# ssh root@192.168.23.144 -p 1322
5. 查询容器:
查询容器ip地址:
[root@docker01 centos6_ssh]# docker inspect 3ed6edb9df0 | grep -i ipaddress
docker ps -a 
6. 停掉容器
删除容器:
docker stop 3b83cf3faa0edocker rm -f 3b83cf3faa0e
7. 删除所有容器
[root@docker01 centos6_ssh]# docker rm `docker ps -a -q`
9) 手动制作支持ssh-http双服务的docker镜像
1. 编写dockerfile
[root@docker01 centos6_ssh]# cat init.sh
cat >>init.sh << 'EOF'
/etc/init.d/httpd start
/usr/sbin/sshd -D
EOF
[root@docker01 centos6_ssh]# cat >> dockerfile << 'EOF'
cat >> dockerfile << 'EOF'
FROM centos:6.9
RUN sed -i "s|enabled=1|enabled=0|g" /etc/yum/pluginconf.d/fastestmirror.conf
RUN mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
RUN curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo
RUN yum clean all
RUN yum makecache
RUN yum -y install openssh-server
RUN /etc/init.d/sshd start
RUN echo 123456 | passwd --stdin root
#安装Apache
RUN yum -y install httpd
#把当前路径下的init.sh(dockefile所在的路径)放到容器的根目录下
ADD init.sh /init.sh
CMD ["/bin/bash","/init.sh"]
EOF
2. docker build 构建镜像
[root@docker01 centos6_ssh]# docker build -t centos69-ssh_http:v2 . 
3. 启动容器来测试新构建的镜像
[root@docker01 centos6_ssh]# docker run -d -p 1321:22 -p 85:80 centos69-ssh_http:v2 因为docker镜像要开启80和22端口,宿主机做映射的端口是85、1321:
docker ps -a -l --no-trunc //显示全ID
测试Apache是否OK:
curl -I 192.168.23.144:85
4. ssh登录
[root@docker01 centos6_ssh]# ssh root@192.168.23.144 -p 1321
5. 停容器、删容器

6. docker镜像开启容器的时候自动开启22、80端口
[root@bms-6e4a-0918 centos6_ssh_http]# cat dockerfile
FROM centos:6.9
RUN yum -y install openssh-server
RUN /etc/init.d/sshd start
RUN echo 123456 | passwd --stdin root
RUN yum -y install httpd
ADD init.sh /init.sh
EXPOSE 22 80 //自动开启22、80端口
CMD ["/bin/bash","/init.sh"]
[root@bms-6e4a-0918 centos6_ssh_http]# cat >>init.sh << 'EOF'
> /etc/init.d/httpd start
> /usr/sbin/sshd -D
> EOF构建镜像:
[root@docker01 centos6_ssh]# docker build -t centos69-ssh_http:v3 . 

宿主机会自动分配端口和容器的22、80做映射,通过docker ps -a -l查看,可知宿主机的49154和容器的22做映射,宿主机的49153和容器80端口映射:

验证:
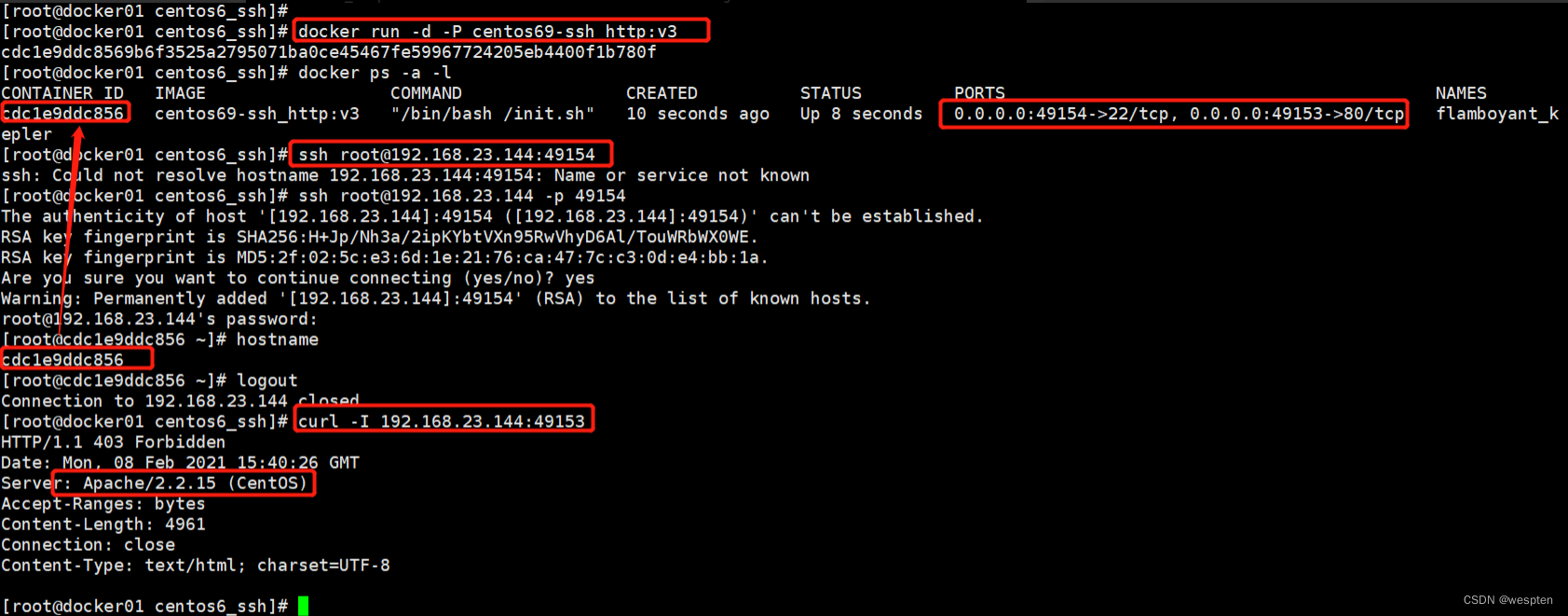
7. 手动进入容器
exec方式:
[root@docker01 centos6_ssh]#
[root@docker01 centos6_ssh]# docker exec -it flamboyant_kepler(容器NAMES或者容器ID) /bin/bash
现在进去容器,当前目录是/根目录,若想开启容器就进入/root目录。需要在dockerfile中加:
workdir /root
ENV 环境变量
CMD ["/usr/sbin/sshd","-D"] 启动容器的初始命令
ENTRYPOINT 容器启动后执行的命令(无法被替换,启容器的时候指定的命令,会被当成参数)当启动容器的时候手动写sleep 10的时候,会把dockefile中默认的CMD中的命令覆盖(也就是CMD指定的命令不被执行):
[root@docker01 centos6_ssh]# docker run -d -P centos69-ssh_http:v3 sleep 10 docker ps -a查看的时候,COMMAND下面就变成sleep 10了,而不是/usr/sbin/sshd","-D。
若想dockerfile中写的CMD的命令不被覆盖,需要将CMD换成ENTRYPOINT(ENTRYPOINT ["/usr/sbin/sshd","-D"] ),这样docker ps -a查看的时候,COMMAND下面会有/usr/sbin/sshd","-D"和sleep 10两个。
八、Docker容器三剑客
1、docker-machine
docker-machine 是 docker 官方三剑客项目之一,它是一个命令行工具。
Docker Machine 是一种可以让您在虚拟主机上安装 Docker 的工具,并可以使用 docker-machine 命令来管理主机。Docker Machine 也可以集中管理所有的 docker 主机,比如快速的给 100 台服务器安装上 docker。
Docker Machine管理的虚拟主机可以是机上的,也可以是云供应商,如阿里云,腾讯云,AWS,或 DigitalOcean。使用 docker-machine 命令,您可以启动,检查,停止和重新启动托管主机,也可以升级 Docker 客户端和守护程序,以及配置 Docker 客户端与您的主机进行通信。
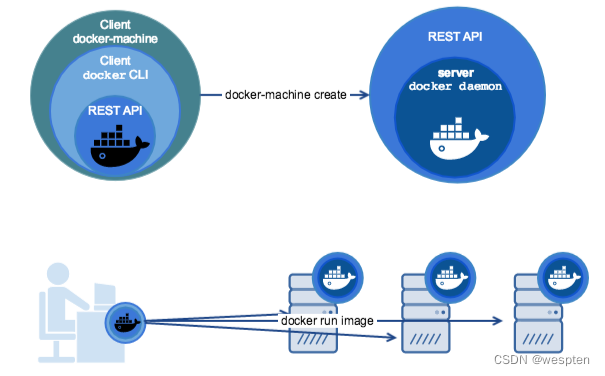
上图是 docker-machine 的原理图,它连接不同类型的操作平台是通过对应驱动来实现的, 目前它已经支持多种云计算环境包括AWS、 IBM、 Google, 以及OpenStack、 VirtualBox、 vSphere等多种云平台的支持,让用户能在多种平台上安装和维护 docker 运行环境。
1)安装 docker-machine
在 linux 上安装 docker-machine 只需要从官方的release库中直接下载编译好的二进制文件即可:
base=https://github.com/docker/machine/releases/download/v0.16.0 &&
curl -L $base/docker-machine-$(uname -s)-$(uname -m) >/tmp/docker-machine &&
sudo mv /tmp/docker-machine /usr/local/bin/docker-machine
chmod +x /usr/local/bin/docker-machine安装完成后,查看其版本信息:
# docker-machine version
docker-machine version 0.16.0, build 702c267fdocker-machine 支持命令的补全,需要下载 machine 库中的bash文件:
base=https://raw.githubusercontent.com/docker/machine/v0.16.0
for i in docker-machine-prompt.bash docker-machine-wrapper.bash docker-machine.bash
do
sudo wget "$base/contrib/completion/bash/${i}" -P /etc/bash_completion.d
done然后执行:
source /etc/bash_completion.d/docker-machine-prompt.bash要启用 docker-machine shell 提示,请添加$(__docker_machine_ps1)到PS1设置中 ~/.bashrc:
PS1='[\u@\h \W$(__docker_machine_ps1)]\$ '2)docker-machine 安装docker
docker-machine支持多种环境的安装docker,这里我们介绍几种:
① virtualBox
docker-machine 支持通过 virtualBox 驱动安装并配置 docker 主机,前提是我需要安装 virtualBox:Downloads – Oracle VM VirtualBox
docker-machine create --driver virtualBox default② genernic
genernic 方式可以通过 ssh 直接在远程上安装 docker,但在这之前先要配置 ssh 认证。
1. 生成密钥:
# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:V7kl+8c0paW/yGFCA+TOvBoH86MtLdKBBZ432TwlrN0 root@centos1
The key's randomart image is:
+---[RSA 2048]----+
| .. |
| . oo . . |
| . o *o+ + . o|
| o *+=.E = +.|
| +oS+ooo o..|
| . .+.o .. +.|
| ..o= . o. +|
| . +*.. + o..|
| .oo. o . |
+----[SHA256]-----+
2. 主机上安装密钥:
# ssh-copy-id root@192.168.10.11这样一来本机就可以不需要密码登陆远程主机了。
3. genernic安装docker:
# docker-machine create --driver generic --generic-ip-address 192.168.10.11 --generic-ssh-key ~/.ssh/id_rsa --generic-ssh-user=root centos2如果主机上没有安装 docker,这一过程的等待时间就会较长。
4. 查看主机:
# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
centos2 - generic Running tcp://192.168.10.11:2376 v19.03.1③ 其他平台
其他平台的安装方式这里就不再详细说明,需要的话可以查阅 https://docs.docker.com/machine。
3)docker-machine 命令
docker-machine 提供一系列的子命令,对应不同的功能:
- config:查看当前激活状态 Docker 主机的连接信息。
- create:创建 Docker 主机
- env:显示连接到某个主机需要的环境变量
- inspect: 以 json 格式输出指定Docker的详细信息
- ip: 获取指定 Docker 主机的地址
- kill: 直接杀死指定的 Docker 主机
- ls: 列出所有的管理主机
- provision: 重新配置指定主机
- regenerate-certs: 为某个主机重新生成 TLS 信息
- restart: 重启指定的主机
- rm: 删除某台 Docker 主机,对应的虚拟机也会被删除
- ssh: 通过 SSH 连接到主机上,执行命令
- scp: 在 Docker 主机之间以及 Docker 主机和本地主机之间通过 scp 远程复制数据
- mount: 使用 SSHFS 从计算机装载或卸载目录
- start: 启动一个指定的 Docker 主机,如果对象是个虚拟机,该虚拟机将被启动
- status: 获取指定 Docker 主机的状态(包括:Running、Paused、Saved、Stopped、Stopping、Starting、Error)等
- stop: 停止一个指定的 Docker 主机
- upgrade: 将一个指定主机的 Docker 版本更新为最新
- url: 获取指定 Docker 主机的监听 URL
- version: 显示 Docker Machine 的版本或者主机 Docker 版本
- help: 显示帮助信息
① active
格式为:
docker-machine active [arg...]支持-timeout, -t "10" 选项, 代表超时时间, 默认为10s。 查看当前激活状态的Docker主机。 激活状态意味着当前的DOCKER_HOST环境变量指向该主机。
例如, 下面命令列出当前激活主机为dev主机:
# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
centos2 - generic Running tcp://192.168.10.11:2376 v19.03.1 ② config
格式为:
docker-machine config [OPTIONS] [arg...]支持 --swarm参数, 表示打印Swarm集群信息, 而不是Docker信息。 查看到Docker主机的连接配置信息。 例如, 下面显示dev主机的连接信息:
# docker-machine config centos2
--tlsverify
--tlscacert="/root/.docker/machine/machines/centos2/ca.pem"
--tlscert="/root/.docker/machine/machines/centos2/cert.pem"
--tlskey="/root/.docker/machine/machines/centos2/key.pem"
-H=tcp://192.168.10.11:2376③ create
格式为:
docker-machine create [OPTIONS] [arg...]- --driver, -d "virtualBox": 指定驱动类型;
- --engine-install-url "https://get.docker.com": 配置Docker主机时的安装URL;
- --engine-opt option: 以键值对格式指定所创建Docker引擎的参数;
- --engine-insecure-registry option: 以键值对格式指定所创建Docker引擎允许访问的不支持认证的注册仓库服务;
- --engine-registry-mirror option: 指定使用注册仓库镜像;
- --engine-label option: 为所创建的Docker引擎添加标签;
- --engine-storage-driver: 存储后端驱动类型;
- --engine-env option: 指定环境变量;
- --swarm: 配置Docker主机加入到Swarm集群中;
- --swarm-image"swarm: latest": 使用Swarm时候采⽤的镜像;
- --swarm-master: 配置机器作为Swarm集群的master节点;
- --swarm-discovery: Swarm集群的服务发现机制参数;
- --swarm-strategy“spread”: Swarm默认调度策略;
- --swarm-opt option: 任意传递给Swarm的参数;
- --swarm-host "tcp: //0.0.0.0: 3376": 指定地址将监听Swarm master节点请求;
- --swarm-addr: 从指定地址发送广播加入Swarm集群服务。
例如, 通过如下命令可以创建一个Docker主机的虚拟机镜像:
# docker-machine create -d virtualBox \
--engine-storage-driver overlay \
--engine-label name=testmachine \
--engine-label year=2018 \
--engine-opt dns=8.8.8.8 \
--engine-env HTTP_PROXY=http://proxy.com:3128 \
--engine-insecure-registry registry.private.com \
mydockermachine所创建Docker主机虚拟机中的Docker引擎将:
- 使用overlay类型的存储驱动;·带有name=mydockermachine和year=2018两个标签;
- 引擎采用8.8.8.8作为默认DNS;
- 环境变量中指定HTTP代理服务http://proxy.com:3128。
- 允许使用不带验证的注册仓库服务registry.private.com。
④ env
格式为:
docker-machine env [OPTIONS] [arg...]显示连接到某个主机需要的环境变量。
·-swarm: 显示Swarm集群配置;
·-shell: 指定所指向的Shell环境, 默认为当前自动探测;
·-unset, -u: 取消对应的环境变量;
·-no-proxy: 添加对象主机地址到NO_PROXY环境变量。
例如, 显示连接到default主机所需要的环境变量:
# docker-machine env centos2
export DOCKER_TLS_VERIFY="1"
export DOCKER_HOST="tcp://192.168.10.11:2376"
export DOCKER_CERT_PATH="/root/.docker/machine/machines/centos2"
export DOCKER_MACHINE_NAME="centos2"
# Run this command to configure your shell:
# eval $(docker-machine env centos2)⑤ inspect
格式为:
docker-machine inspect [OPTIONS] [arg...]以json格式输出指定Docker主机的详细信息。 支持 -format, -f 选项使用指定的Go模板格式化输出。
⑥ ip
获取指定Docker主机地址。
例如, 获取 centos2 主机的地址, 可以用如下命令:
# docker-machine ip mydockermachine
192.168.10.11⑦ kill
直接杀死指定的Docker主机,指定Docker主机会强制停止。
⑧ stop
停止机器。
docker-machine stop mydockermachine⑨ 启动机器
docker-machine stop mydockermachine⑩ 进入机器
$ docker-machine ssh mydockermachine⑪ ls
列出所有管理的主机。 格式为:
docker-machine ls [OPTIONS] [arg...]可以通过--filter只输出某些Docker主机, 支持过滤器包括名称正则表达式、 驱动类型、 Swarm管理节点名称、 状态等。
例如:
$ docker-machine ls --filter state=Running
NAME ACTIVE DRIVER STATE URL
dev - virtualBox Running tcp://192.168.99.103:2376
staging * digitalocean Running tcp://203.0.113.81:2376
$ echo $DOCKER_HOST
tcp://203.0.113.81:2376
$ docker-machine active
staging
- --quiet, -q: 减少有关输出信息;
- --filter [--filter option--filter option]: 只输出符合过滤条件主机;
- -timeout, -t "10": 命令执行超时时间, 默认为10s;
- -format, -f: 使⽤所指定的Go模板格式化输出。
2、docker-compose
先来想一下我们平时是怎么样使用docker的?把它进行拆分一下:
1、docker search 镜像,是不是先查找一个镜像;
2、docker run -itd 镜像名称 ,然后在运行这个镜像;
3、然后如果你要在运行第二个镜像、第三个镜像.....等等镜像,你是不是又要docker search、docker run运行;
上面“ docker run it 镜像名称 ”这只是最小的动作, 如果你要映射硬盘,设置nat网络或者映射端口等等…你就要做更多的 docker 操作, 这显然是非常没有效率的,况且如果你要大规模部署,是不是觉得就很麻烦了。如果将上面的操作写在docker-compose.yml里面,你只需要写好后只运行一句:docker-compose up -d就好了。
docker-compose 的前身是开源的 docker 容器集群编排工具 fig,2014年7月,fig 被 Docker 收购并更名成为 docker-compose。
之前我们已经学习了关于 docker 的 dockerfile,使用它可以让用户快速生成一个需要的镜像,进而生成容器,快速配置一个应用。但是云计算的使用更多是面对庞大的用户群体,这样一来所发布的容器数量必然不少。而单机的 dockerfile 相比起来就相形见绌了。因此,像 fig 这样的工具就孕育而生了。如果说 dockerfile 重现一个容器,那 docker-componse 就是重现容器的配置和集群了。
一个项目一般会由多个应用服务组成。例如一个Django的web项目,由Django后端服务,数据库,uwsgi服务,Nginx反向代理服务等组成。如果使用容器技术当然不会将所有的服务都部署到一个容器中,一般是一个独立的服务一个容器。因此上面的项目需要一个python环境的容器用来运行django后端服务和uwsgi服务,一个数据库容器,一个Nginx容器。单独部署时,需要一个个手动部署,构建镜像,添加网络,以及各容器之间的依赖和通信等问题,非常繁琐。
docker-compose就是批量部署容器,并自动构建镜像,处理依赖和通信的工具。只需要在一个YAML文件中配置好应用程序的服务,然后通过docker-compose命令就可以创建并启动配置中的所有服务。
在 docker 中,“编排”和“部署”这两个词是时常出现的,那么它们具体指什么呢?
- 编排(orchestration):它根据被部署的对象之间的耦合关系,以及被部署对象对环境的依赖,制定部署流程中各个动作的执行顺序,部署过程中所需要的依赖文件和被部署文件的存储位置和获取方式,以及如何验证部署成功。这些信息都会在编排工具中以指定的格式(比如配置文件或者特定的代码)来要求运维人员定义并保存起来,从而保证这个流程能够随时在全新的环境中可靠有序地重现出来。
- 部署(deployment),它是指按照编排所指定地内容和流程,在目标机器上执行编排指定环境初始化,存放指定地依赖和文件,运行指定地部署动作,最终按照编排中地规则来确定部署成功。
总地来说,编排制定流程,部署执行流程,协同完成容器云的创建。
使用docker-compose有三个基本步骤:
- 在Dockerfile中定义好你的应用程序的环境,以便在任何地方它都可以复制。
- 在docker-compose.yml中定义组成应用程序的服务,以便它们可以在一个独立的环境中一起运行。
- 运行docker-compose up, docker-compose命令会启动并运行整个应用程序。
docker-compose.yml:
Services:
- 一个service代表一个container,这个container可以通过dockerhub的image创建,或者通过本地的Dockerfile build出来的image创建出来。
- Service的启动类似docker run,我们可以给其指定network和volume,所以可以给service指定network和Volume的引用
eg1:
docker run -d --name db -v db-data:/var/liv/postgresql/data --network back-tier postgres:9.4
对应docker-compose:
services:
db: #service 的名称为 db
image: postgres:9.4 #service image 为 postgres:9.4 这是从远程拉取的
volumes:
- "db-data:/var/liv/postgresql/data" #将外部db-data挂载到container 的 /var/liv/postgresql/data 内
networks:
- back-tier #网络为 back-tier
eg2:
docker run -d --link db --link redis --network back-tier worker
对应docker-compose:
services:
worker:
build: ./worker
links:
- db
- redis
networks:
- back-tier #在同一个网络上 不需要linksNerworks:
- 会有单独的一个 networks (与 services 同级别) 对网络定义进行阐述;
eg1:
docker nerwork create -d bridge back-tier
对应docker-compose:
Nerworks:
networks:
- back-tier #在同一个网络上 不需要links,单独的一个networks对back-tier进行阐述
networks:
front-tier:
driver: bridge
back-tier:
driver: bridgeVolumes:
- 会有单独的一个 volumes (与 services 同级别) 对挂载定义进行阐述;
docker volume create db-data
对应docker-compose:
Volumes:
volumes:
- "db-data:/var/liv/postgresql/data" #将外部db-data挂载到container 的 /var/liv/postgresql/data内,对db-data进行阐述
volumes:
db-data:1)docker-componse 安装
Docker Compose依赖于Docker Engine来完成任何有意义的工作,所以请确保在本地或远程安装Docker Engine。
1. 在windows和mac上安装
Docker Desktop for Mac和Windows 默认包括Compose命令。因此,Windows和Mac用户不需要单独安装Compose V2。
2. 在liunx系统上安装
在Linux上,您可以从GitHub上的Compose存储库发布页面下载Docker Compose二进制文件,然后按照下面的步骤来安装:
# curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# chomd +x /usr/local/bin/docker-compose
# docker-compose --version
docker-compose version 1.25.0要安装不同版本的Compose,请将1.24.1替换为您想要使用的Compose版本。
对于alpine,需要以下依赖包:
py-pip, python3-dev, libffi-dev, openssl-dev, gcc, libc-dev, rust, cargo and make.3. 通过pip安装
Compose可以使用pip从pypi安装。如果您使用pip安装,我们建议您使用virtualenv,因为许多操作系统有与docker-compose依赖项冲突的python系统包。
pip install docker-compose新的compose V2版本支持将compose命令作为docker cli的一部分,也即是可以去掉docker-compose命令中的-,直接使用docker compose命令。
v2版本的做了很多更新和优化,未来会取代v1版本。
4. 在windows和mac上安装:
Docker Desktop for Mac和Windows 3.2.1及以上版本包括新的Compose命令和Docker CLI。因此,Windows和Mac用户不需要单独安装Compose V2。
5. 在linux上安装
直接通过从项目发布页面下载适合您系统的二进制文件并将其复制为$HOME/.docker/cli-plugins目录下的docker-compose文件。
运行以下命令下载Docker Compose的当前稳定版本:
mkdir -p ~/.docker/cli-plugins/
curl -SL https://github.com/docker/compose/releases/download/v2.0.1/docker-compose-linux-x86_64 -o ~/.docker/cli-plugins/docker-compose这个命令将为当前活动用户安装Compose V2到$HOME目录下。为系统上的所有用户安装Docker Compose,替换~/.docker/cli-plugins/为/usr/local/lib/docker/cli-plugins。
$ chmod +x ~/.docker/cli-plugins/docker-compose
$ docker compose version
Docker Compose version v2.0.12)docker-compose 简单实例
1. 创建一个 docker-compose 的目录:
# mkdir composetest
# cd composetestimport time
import redis
from flask import Flask
app = Flask(__name__)
cache = redis.Redis(host='redis', port=6379)
def get_hit_count():
retries = 5
while True:
try:
return cache.incr('hits')
except redis.exceptions.ConnectionError as exc:
if retries == 0:
raise exc
retries -= 1
time.sleep(0.5)
@app.route('/')
def hello():
count = get_hit_count()
return 'Hello World! I have been seen {} times.\n'.format(count)在上面的程序中,redis的主机名为'redis',并使用默认端口6379。
3. 在目录下创建 python 代码的依赖文件 requirements.txt 并添加依赖项:
redis
flask4. 创建 Dockerfile 文件:
# 以 python:3.7-alpine 为基础镜像,创建镜像
FROM python:3.7-alpine
# 设置工作目录为 /code
workdir /code
# 设置环境变量
ENV FLASK_APP app.py
ENV FLASK_RUN_HOST 0.0.0.0
# alpine 安装软件包
RUN apk add --no-cache gcc musl-dev linux-headers
# 从主机上复制 python 的依赖文件
copY requirements.txt requirements.txt
# 安装依赖
RUN pip install -r requirements.txt
# 复制 composetest 目录中的所有文件到工作目录中
copY . .
# 运行 python 应用
CMD ["flask", "run"]我们构建了一个镜像,该映像包含Python应用程序所需的所有依赖项,包括Python本身。
这告诉Docker:
- 从Python 3.7映像开始构建映像。
- 将工作目录设置为/code。
- 设置flask命令使用的环境变量。
- 安装gcc和其他依赖项
- 复制requirements.txt并安装Python依赖项。
- 向映像添加元数据,以说明容器正在监听端口5000
- 复制项目当前目录到镜像的工作目录中
- 设置容器的默认运行命令为flask run
5. 定义 docker-compose.yml 文件:
version: "3.9" # optional since v1.27.0
services:
web:
build: .
ports:
- "5000:5000"
volumes:
- .:/code
- logvolume01:/var/log
links:
- redis
redis:
image: redis
volumes:
logvolume01: {}compose file中定义了web和redis服务。web 服务会使用项目当前目录下的dockerfile构建的镜像。 然后它将容器的5000端口绑定到主机的5000端口上。redis服务使用从Docker Hub下载的公共redis镜像。
6. 从 docker-compose 构建并启动应用:
# docker-compose up
Creating composetest_web_1 ... done
Creating composetest_redis_1 ... done
Attaching to composetest_redis_1, composetest_web_1
redis_1 | 1:C 14 Oct 2021 11:34:42.291 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
redis_1 | 1:C 14 Oct 2021 11:34:42.291 # Redis version=6.2.1, bits=64, commit=00000000, modified=0, pid=1, just started
redis_1 | 1:C 14 Oct 2021 11:34:42.291 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
redis_1 | 1:M 14 Oct 2021 11:34:42.291 * monotonic clock: POSIX clock_gettime
redis_1 | 1:M 14 Oct 2021 11:34:42.292 * Running mode=standalone, port=6379.
redis_1 | 1:M 14 Oct 2021 11:34:42.292 # Server initialized
redis_1 | 1:M 14 Oct 2021 11:34:42.294 * Ready to accept connections
web_1 | * Serving Flask app 'app.py' (lazy loading)
web_1 | * Environment: production
web_1 | WARNING: This is a development server. Do not use it in a production deployment.
web_1 | Use a production Wsgi server instead.
web_1 | * Debug mode: off
web_1 | * Running on all addresses.
web_1 | WARNING: This is a development server. Do not use it in a production deployment.
web_1 | * Running on http://192.168.80.3:5000/ (Press CTRL+C to quit)compose下载了一个Redis镜像,为代码构建了一个镜像,并启动定义好的服务,代码在构建时静态地复制到镜像中。执行成功后,服务会启动并绑定端口 5000。
在浏览器中输入http://localhost:5000/或者http://127.0.0.1:5000/访问我们运行的web服务程序:
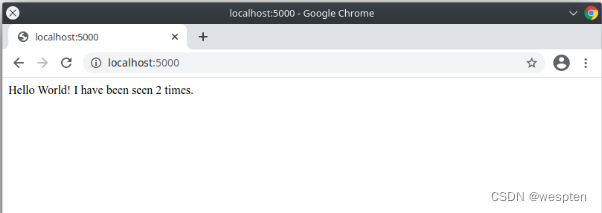
切换到另一个终端并输入docker image ls查询所有本地镜像:
直接在当前运行终端Ctrl + C,或者是再开启一个终端在项目目录下运行docker-compose down关闭运行的应用。
7. 添加挂载点
编辑docker-compose.yml,给web服务添加挂载点:
version: "3.9"
services:
web:
build: .
ports:
- "5000:5000"
volumes:
- .:/code
environment:
FLASK_ENV: development
redis:
image: "redis:alpine"volumes键将主机上的项目目录(当前目录)挂载到容器内的/code中,并允许动态地修改代码,而不必重新构建映像。
environment键设置FLASK_ENV环境变量,该变量告诉flask以开发模式运行并在代码发送更改时重新加载。这种模式只能在开发中使用。
在项目目录下运行docker-compose up使用更新后的compose文件重新构建并运行应用:
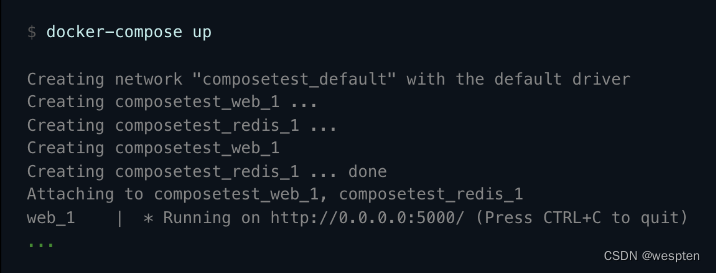
8. 更新应用
因为现在使用卷将应用程序代码挂载到容器中,所以您可以对其代码进行更改并立即查看更改,而无需重新构建镜像。
修改app.py中的返回问候语,例如:
return 'Hello from Docker! I have been seen {} times.\n'.format(count)在浏览器中刷新应用程序,欢迎语应该更新,计数器应该仍然在增加。
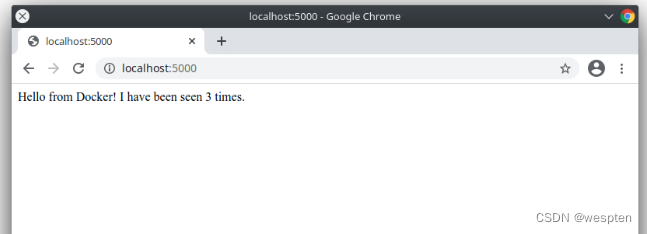
如果你想在后台运行你的服务,你可以将-d标志(用于“分离”模式)传递给docker-compose up,并使用docker-compose ps来查看当前正在运行的服务:
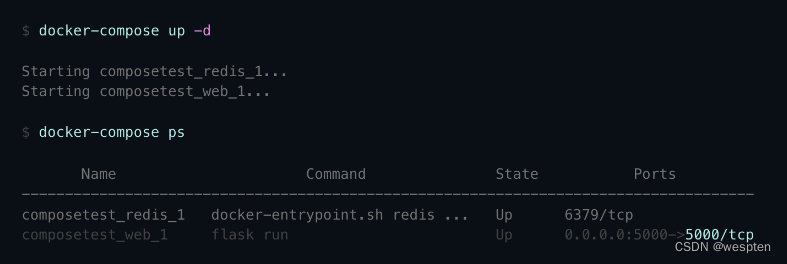
docker-compose run命令允许您为您的服务运行一次性命令。例如,要查看web服务可用的环境变量:
docker-compose run web env
Creating composetest_web_run ... done
PATH=/usr/local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
HOSTNAME=7929330f0f39
TERM=xterm
FLASK_ENV=development
LANG=C.UTF-8
GPG_KEY=0D96DF4D4110E5C43FBFB17F2D347EA6AA65421D
PYTHON_VERSION=3.7.10
PYTHON_PIP_VERSION=21.0.1
PYTHON_GET_PIP_URL=https://github.com/pypa/get-pip/raw/b60e2320d9e8d02348525bd74e871e466afdf77c/get-pip.py
PYTHON_GET_PIP_SHA256=c3b81e5d06371e135fb3156dc7d8fd6270735088428c4a9a5ec1f342e2024565
FLASK_APP=app.py
FLASK_RUN_HOST=0.0.0.0
HOME=/root如果使用docker-compose up -d命令启动服务,停止服务可以使用命令:
docker-compose stop也可以使用down命令删除所有,完全删除容器。通过——volumes来删除Redis容器使用的数据卷:
docker-compose down --volumes这些就是docker-compose的基本使用方法。
3)docker-compose 多容器部署
谈到微服务的话题,技术上我们往往会涉及到多服务、多容器的部署与管理。
Docker 有三个主要的作用:Build, Ship和Run,使用docker compose我们可以在Run的层面解决很多实际问题,如:通过创建compose(基于YUML语法)文件,在这个文件上面描述应用的架构,如使用什么镜像、数据卷、网络、绑定服务端口等等,然后再用一条命令就可以管理所有的服务(如启动、停止、重启、日志监控等等)。
一键部署lnmp平台
我们先来看下/compose_lnmp目录下的docker-compose.yml文件:
[root@ganbing compose_lnmp]# ls
docker-compose.yml MysqL Nginx PHP wwwroot
[root@ganbing compose_lnmp]# cat docker-compose.yml
version: '3'
services:
Nginx:
hostname: Nginx
build:
context: ./Nginx
dockerfile: Dockerfile
ports:
- 80:80
networks:
- lnmp
volumes:
- ./wwwroot:/usr/local/Nginx/html
PHP:
hostname: PHP
build:
context: ./PHP
dockerfile: Dockerfile
networks:
- lnmp
volumes:
- ./wwwroot:/usr/local/Nginx/html
MysqL:
hostname: MysqL
image: MysqL:5.6
ports:
- 3306:3306
networks:
- lnmp
volumes:
- ./MysqL/conf:/etc/MysqL/conf.d
- ./MysqL/data:/var/lib/MysqL
command: --character-set-server=utf8
environment:
MysqL_ROOT_PASSWORD: 123456
MysqL_DATABASE: wordpress
MysqL_USER: ganbing
MysqL_PASSWORD: ganbing123
networks:
lnmp:
driver: bridge可以看到一份标准配置文件应该包含 version、services、networks 三大部分,共有三级标签,每一级都是缩进两个空格。
说明:
1、version: '3'
这是定义compose的版本号为version 3
2、services:
Nginx:这是services下面的二级标签,名字用户自己定义,它将是服务运行后的名称;
hostname: Nginx 这是定义容器的主机名,将写入到/etc/hostname中;
build:
context: ./Nginx 指定Nginx服务的上下文路径;
dockerfile:Dockerfile 指定通过上面指定路径中的Dockerilfe来构建;
ports:
- 80:80 端口映射没什么好说的;
networks:
-lnmp 指定的网络环境
volumes:把宿主机的/wwwroot目录绑定到容器中的/usr/local/Nginx/html目录;
PHP:这个二级标签服务和下面的内容跟Nginx差不多;
MysqL:这个二级标签服务也和Nginx、PHP差不多,唯一不同的是多了个images标签、还有定义了些环境变量。
image: MysqL:5.6 它是通过MysqL:5.6镜像来构建MysqL服务器,前面Nginx、PHP都指定了上下文通过Dockerfile来构建的。
environment:
MysqL_ROOT_PASSWORD:定义root用户密码变量为123456;
MysqL_DATABASE:定义了数据变量为wordpress;
MysqL_USER:定义了普通用户变量为ganbing;
MysqL_PASSWORD:定义了普通用户密码变量为ganbing123;
3、networks:
lnmp: 相当于执行docker network create lnmp命令了;最后来运行docker-compose命令来启动:
[root@ganbing /]# cd compose_lnmp/
[root@ganbing compose_lnmp]# docker-compose -f docker-compose.yml up -d来查看一下是否启动完成:
[root@ganbing compose_lnmp]# docker-compose ps
Name Command State Ports
-------------------------------------------------------------------------------------
composelnmp_MysqL_1 docker-entrypoint.sh --cha ... Up 0.0.0.0:3306->3306/tcp
composelnmp_Nginx_1 ./sbin/Nginx -g daemon off; Up 0.0.0.0:80->80/tcp
composelnmp_PHP_1 ./sbin/PHP-fpm -c /usr/loc ... Up 9000/tcp 从上面可以看出这3个服务都是UP状态,运行 docker-compose ps必须要在有docker-compose.yml文件目录下执行才可以。
4)docker-compose 模板语法
目前 docker-compose 模板已经更新到 v3 版本,支持众多指令:
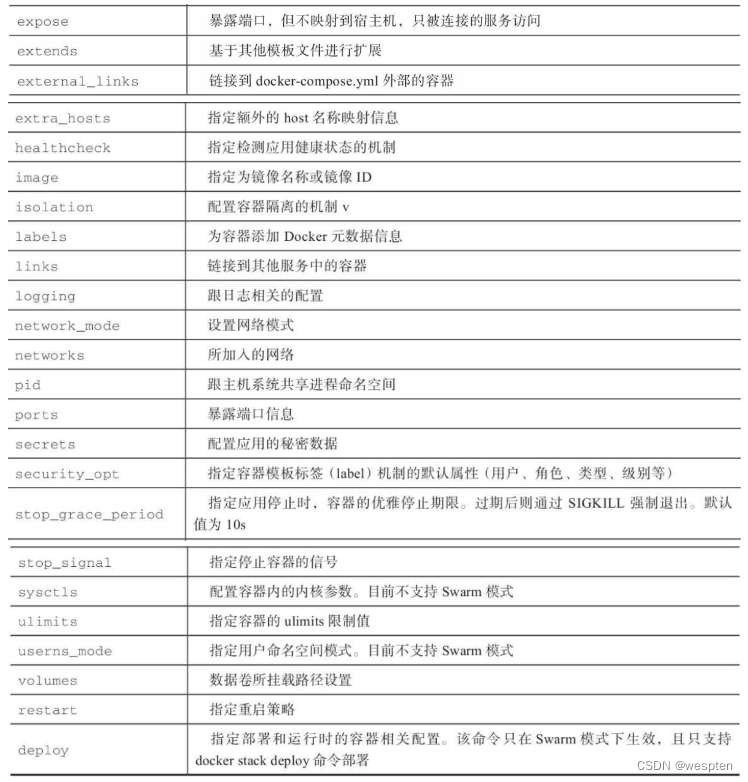
1. version
指定compose file的版本。
可以参考官方文档详细了解具体有哪些版本: https://docs.docker.com/compose/compose-file/
2. networks
创建网络。
3. services
定义服务程序,每个服务对应会创建一个容器。
4. build
设置为一个字符串,指定 Dockerfile 所在文件夹的路径(可以是绝对路径, 或者相对dockercompose.yml文件的路径) 。 Compose将会利用它自动构建应用镜像, 然后使用这个镜像, 例如:
version: '3'
services:
app:
build: /path/to/build/dirbuild设置为一个对象,指令还可以指定创建镜像的上下文、 Dockerfile路径、 标签、 参数和缓存来源等, 例如:
version: '3'
services:
app:
build:
context: /path/to/build/dir
dockerfile: Dockerfile-app
labels:
version: "2.0"
released: "true"
shm_size: '2gb'
args:
key: value
name: myApp
cache_from:
- myApp:1.0当同时设置build和image配置项时,Compose会使用image中指定的webapp和tag来命名构建的图像:
build: ./dir
image: webapp:tag5. cap_add, cap_drop
指定容器的内核能力(capacity) 分配。 例如, 让容器拥有所有能力可以指定为:
cap_add:
- ALL去掉NET_ADMIN能力可以指定为:
cap_drop:
- NET_ADMIN6. command
覆盖容器启动后默认执行的命令, 可以为字符串格式或JSON数组格式。
例如:
command: echo "hello world"也可以是一个列表:
command: ["bash", "-c", "echo", "hello world"]7. configs
在Docker Swarm模式下, 可以通过configs来管理和访问敏感的配置信息,支持从文件读取或外部读取。
例如:
version: "3.3"
services:
app:
image: myApp:1.0
deploy:
replicas: 1
configs:
- file_config
- external_config
configs:
file_config:
file: ./config_file.cfg
external_config:
external: true8. cgroup_parent
指定cgroup组, 意味着将继承该组的资源限制。 目前不支持在Swarm模式中使用。
cgroup_parent: cgroups_19. container_name
指定启动容器的名字。 默认将会使用“项目名称_服务名称_序号”这样的格式,目前不支持在Swarm模式中使用。
例如:
container_name: docker-web-container指定容器名称后, 该服务将无法进行扩展, 因为Docker不允许多个容器实例重名。
10. devices指定设备映射关系, 不支持Swarm模式。
例如:
devices:
- "/dev/ttyUSB1:/dev/ttyUSB0"11. depends_on
表示服务之间的依赖关系。 服务依赖会导致以下行为:
- docker-compose up按依赖顺序启动服务。 在下面的示例中,db和redis在web之前启动。
- docker-compose up service自动包括service的依赖项。在下面的例子中,docker-compose up web也创建并启动db和redis。
- docker-compose stop按依赖顺序停止服务。
启动时,会先启动被依赖服务。 例如, 可以指定依赖于db服务:
depends_on: db在下面的例子中,web在db和redis之前停止:
version: "3.9"
services:
web:
build: .
depends_on:
- db
- redis
redis:
image: redis
db:
image: postgres在使用depends_on时需要注意:
depends_on不会等待db和redis是“准备好”之后再启动web -只是等他们启动。如果需要等待服务就绪,请参阅控制启动顺序了解有关此问题和解决该问题的策略的更多信息。
12. dns
例如:
dns: 8.8.8.8
dns:
- 8.8.8.8
- 9.9.9.913. dns_search
配置DNS搜索域。 可以是一个值, 也可以是一个列表。 例如:
dns_search: example.com
dns_search:
- domain1.example.com
- domain2.example.com14. dockerfile
如果需要, 指定额外的编译镜像的Dockefile文件, 可以通过该指令来指定。
例如:
dockerfile: Dockerfile-alternate注意: 该指令不能跟image同时使用, 否则Compose将不知道根据哪个指令来生成最终的服务镜像。
15. entrypoint
覆盖容器中默认的原来的entrypoint,注意也会取消掉镜像中指定的命令和默认启动命令。
例如, 覆盖为新的entrypoint命令:
entrypoint: python app.py
Or
entrypoint: /code/entrypoint.sh也可以写成列表的形式:
entrypoint: ["PHP", "-d", "memory_limit=-1", "vendor/bin/PHPunit"]注意设置了entrypoint后,不仅会覆盖服务镜像Dockerfile中的ENTRYPOINT指令还会忽略其中的CMD指令。
16. env_file
从文件中获取环境变量, 可以为单独的文件路径或列表。 如果通过 docker-compose-f FILE方式来指定Compose模板文件, 则env_file中变量的路径会基于模板文件路径。 如果有变量名称与environment指令冲突, 则按照惯例, 以后者为准。
例如:
env_file: .env
env_file:
- ./common.env
- ./apps/web.env
- /opt/secrets.env环境变量文件中每一行必须符合格式, 支持#开头的注释行, 例如:
# common.env: Set development environment
PROG_ENV=development17. environment
设置环境变量, 可以使用数组或字典两种格式。 只给定名称的变量会自动获取运行Compose主机上对应变量的值, 可以用来防止泄露不必要的数据。任何布尔值(true, false, yes, no)都需要用引号括起来,以确保它们不会被YML解析器转换为True或False。
例如:
environment:
RACK_ENV: developmentSESSION_SECRET:或者:
environment:
RACK_ENV:development
SHOW: 'true'
SESSION_SECRET:注意:如果变量名称或者值中⽤到 true | false, yes | no 等表达布尔含义的词汇, 最好放到引号里, 避免YAML自动解析某些内容为对应的布尔语义:
y|Y|yes|Yes|YES|n|N|no|No|NO
|true|True|TRUE|false|False|FALSE
|on|On|ON|off|Off|OFF18. expose
暴露端口, 但不映射到宿主机, 只被连接的服务访问。 仅可以指定内部端口为参数, 如下所示:
expose:
- "3000"
- "8000"19. extends
基于其他模板文件进行扩展。 例如, 我们已经有了一个webapp服务,定义一个基础模板文件为 common.yml, 如下所示:
# common.yml
webapp:
build: ./webapp
environment:
- DEBUG=false
- SEND_EMAILS=false再编写一个新的development.yml文件, 使用common.yml中的webapp服务进行扩展:
# development.yml
web:
extends:
file: common.yml
service: webapp
ports:
- "8000:8000"
links:
- db
environment:
- DEBUG=true
db:
image: postgres后者会自动继承 common.yml 中的 webapp 服务及环境变量定义。 使用extends需要注意以下两点:
- 要避免出现循环依赖, 例如A依赖B, B依赖C, C反过来依赖A的情况。
- extends不会继承 links 和 volumes_from 中定义的容器和数据卷资源。一般情况下, 推荐在基础模板中只定义一些可以共享的镜像和环境变量, 在扩展模板中具体指定应用变量、 链接、 数据卷等信息。
20.external_links
链接到docker-compose.yml外部的容器, 甚至并用Compose管理的外部容器。 参数格式跟links类似:
external_links:
- redis_1
- project_db_1:MysqL
- project_db_1:postgresql21.extra_hosts
类似 Docker 中的 --add-host 参数, 指定额外的host名称映射信息。
例如:
extra_hosts:
- "googledns:8.8.8.8"
- "dockerhub:52.1.157.61"会在启动后的服务容器中 /etc/hosts 文件中添加如下两条条目:
8.8.8.8 googledns
52.1.157.61 dockerhub22.healthcheck
指定检测应用健康状态的机制, 包括检测方法(test) 、 间隔(interval) 、 超时(timeout) 、 重试次数(retries) 、 启动等待时间(start_period) 等。
例如, 指定检测方法为访问8080端口, 间隔为30秒, 超时为15秒, 重试3次, 启动后等待30秒再做检查:
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080"]
interval: 30s
timeout: 15s
retries: 3
start_period: 30s23. image
指定容器启动的镜像。可以是镜像名,也可以是镜像ID的部分。
例如:
image: ubuntu
image: ubuntu:18.04
image: orchardup/postgresql
image: a4bc65fd如果镜像不存在compose会pull它。如果还制定了build指令,将作为构建后的镜像的名字。
24. isolation
配置容器隔离的机制, 包括default、 process 和 hyperv。
25. labels
例如可以为容器添加辅助说明信息:
labels:
com.startupteam.description: "webapp for a startup team"
com.startupteam.department: "devops department"
com.startupteam.release: "rc3 for v1.0"26. links
注意: links命令属于旧的方法, 可能在后续版本中被移除。链接到其他服务中的容器。
使用服务名称(同时作为别名) 或服务名称: 服务别名(SERVICE: ALIAS) 格式都可以:
links:
- db
- db:database
- redis使用的别名将会自动在服务容器中的 /etc/hosts 来创建。 例如:
172.17.2.186 db
172.17.2.186 database
172.17.2.187 redis被链接容器中相应的环境变量也将被创建。
27. logging
跟日志相关的配置, 包括一系列的配置。
logging.driver: 类似于 Docker 中的 --log-driver 参数, 指定日志驱动类型。 目前支持三种日志驱动类型:
- driver: "json-file"
- driver: "syslog"
- driver: "none"logging.
options: 日志驱动的相关参数。
例如:
logging:
driver: "syslog"
options:
syslog-address: "tcp://192.168.0.42:123"或:
logging:
driver: "json-file"
options:
max-size: "1000k"
max-file: "20"28. network_mode
设置网络模式,使用方式和docker client的--network 参数一样的值:
network_mode: "none"
network_mode: "bridge"
network_mode: "host"
network_mode: "service:[service name]"
network_mode: "container:[name or id]"29.networks
配置容器连接的网络,引用顶级 networks 下的条目 。 需要在顶级的 networks 字段中定义具体的网络信息。
例如, 指定web服务的网络为web_net, 并添加服务在网络中别名为web_app:
services:
web:
networks:
web_net:
aliases: web_app
ipv4_address: 172.16.0.10
networks:
web_net:
driver: bridge
enable_ipv6: true
ipam:
driver: default
config:
subnet: 172.16.0.0/2430. pid
跟主机系统共享进程命名空间。 打开该选项的容器之间, 以及容器和宿主机系统之间可以通过进程ID来相互访问和操作。
pid: "host"31. ports
端口映射。
有三种格式:
使用宿主: 容器(HOST: CONTAINER) 格式, 或者仅仅指定容器的端口(宿主将会随机选择端口) 都可以。
ports:
- "3000"
- "3000-3005"
- "8000:8000"
- "9090-9091:8080-8081"
- "49100:22"
- "127.0.0.1:8001:8001"
- "127.0.0.1:5000-5010:5000-5010"
- "127.0.0.1::5000"
- "6060:6060/udp"
- "12400-12500:1240"或者:
ports:
- target: 80
published: 8080
protocol: tcp
mode: ingress注意:当使用HOST: CONTAINER格式来映射端口时, 如果你使用的容器端口用于60并且没放到引号里, 可能会得到错误结果, 因为YAML会自动解析 xx: yy 这种数字格式为60进制。 为避免出现这种问题, 建议数字串都采用引号包括起来的字符串格式。
32. secrets
配置应用的秘密数据。可以指定来源秘密、 挂载后名称、 权限等。
例如:
version: "3.1"
services:
web:
image: webapp:stable
deploy:
replicas: 2
secrets:
- source: web_secret
target: web_secret
uid: '103'
gid: '103'
mode: 0444
secrets:
web_secret:
file: ./web_secret.txt33. security_opt
指定容器模板标签(label) 机制的默认属性(用户、 类型、 级别等) 。
security_opt:
- label:user:USER
- label:role:ROLE34.stop_grace_period
指定应用停止时, 容器的优雅停止期限。 过期后则通过SIGKILL强制退出。默认值为10s。
35.stop_signal
指定停⽌容器的信号, 默认为SIGTERM。
36. sysctls
配置容器内的内核参数。 Swarm模式中不支持。例如, 指定连接数为4096和开启TCP的syncookies:
sysctls:
net.core.somaxconn: 4096
net.ipv4.tcp_syncookies: 137. ulimits
指定容器的ulimits限制值。例如, 指定最多进程数为65535, 指定文件句柄数为20000(软限制,应用可以随时修改, 不能超过硬限制) 和40000(系统硬限制, 只能root用户提升) 。
ulimits:
nproc: 65535
nofile:
soft: 20000
hard: 4000038. userns_mode
指定用户命名空间模式。 Swarm模式中不支持。 例如, 使用主机上的用户命名空间:
userns_mode: "host"39.volumes
挂着一个主机路径或者绑定一个命名卷到服务,可以将主机路径挂载为单个服务的定义的一部分,不需要在顶级volumes中定义它。但是,如果您想跨多个服务重用卷,那么在顶级卷键中定义一个命名卷。
可以设置宿主机路径(HOST:CONTAINER) 或加上访问模式(HOST: CONTAINER: ro) 。支持driver、 driver_opts、 external、 labels、 name等配置。
语法格式:
[SOURCE:]TARGET[:MODE]- SOURCE可以是宿主机的路径或者是卷名
- TARGET卷挂着的容器中的路径
- MODE默认为rw表示可读写,ro表示只读
该指令中路径保持相对路径,例如:
volumes:
# Just specify a path and let the Engine create a volume
- /var/lib/MysqL
# Specify an absolute path mapping
- /opt/data:/var/lib/MysqL
# Path on the host, relative to the Compose file
- ./cache:/tmp/cache
# User-relative path
- ~/configs:/etc/configs/:ro
# Named volume
- datavolume:/var/lib/MysqL或者可以使用更详细的语法格式:
volumes:
- type: volume
source: mydata
target: /data
volume:
nocopy: true
volumes:
mydata:更多信息详见官方文档
40.restart
指定重启策略,no是默认的重新启动策略,在任何情况下都不会重新启动容器。
可以为no(不重启) 、 always(容器总是重新启动) 、 onfailure(如果退出码指示一个on-failure错误,on-failure策略将重新启动容器) 、 unless-stopped(则除非容器被停止(手动或其他方式),否则该容器总是会重新启动) 。
注意Swarm模式下要使用restart_policy。 在生产环境中推荐配置为always或者unless-stopped。例如, 配置除外停止:
restart: "no"
restart: always
restart: on-failure
restart: unless-stopped41. deploy
指定部署和运行时的容器相关配置。 该命令只在Swarm模式下生效,且只支持docker stack deploy命令部署。
例如:
version: '3'
services:
redis:
image: web:stable
deploy:
replicas: 3
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failuredeploy命令中包括 endpoint_mode、 labels、 mode、 placement、replicas、 resources、 restart_policy、 update_config等配置项。
(1) endpoint_mode
指定服务端点模式。 包括两种类型:
例如:
version: '3'
services:
redis:
image: web:stable
deploy:
mode: replicated
replicas: 3
endpoint_mode: vip(2) labels
例如:
version: "3"
services:
web:
image: web:stable
deploy:
labels:
description: "This is a web application service."(3) mode
定义容器副本模式, 可以为:global: 每个Swarm节点上只有一个该应用容器;replicated: 整个集群中存在指定份数的应用容器副本, 默认值。
例如, 指定集群中web应用保持3个副本:
version: "3"
services:
web:
image: web:stable
deploy:
mode: replicated
replicas: 3(4) placement
定义容器放置的限制(constraints) 和配置(preferences) 。 限制可以指定只有符合要求的节点上才能运行该应用容器; 配置可以指定容器的分配策略。
例如, 指定集群中web应用容器只存在于该安全的节点上, 并且在带有zone标签的节点上均匀分配:
version: '3'
services:
db:
image: web:stable
deploy:
placement:
constraints:
- node.labels.security==high
preferences:
- spread: node.labels.zone(5) replicas
容器副本模式为默认的replicated时, 指定副本的个数。
(6) resources
指定使用资源的限制, 包括cpu、 内存资源等。 例如, 指定应用使用的cpu份额为10%~25%, 内存为200 MB到500 MB。
version: '3'
services:
redis:
image: web:stable
deploy:
resources:
limits:
cpus: '0.25'
memory: 500M
reservations:
cpus: '0.10'
memory: 200M(7) restart_policy
指定容器重启的策略。
例如, 指定重启策略为失败时重启, 等待2s,重启最多尝试3次, 检测状态的等待时间为10s:
version: "3"
services:
redis:
image: web:stable
deploy:
restart_policy:
condition: on-failure
delay: 2s
max_attempts: 3
window: 10s(8) update_config
有些时候需要对容器内容进行更新, 可以使用该配置指定升级的方为。 包括每次升级多少个容器(parallelism) 、 升级的延迟(delay) 、 升级失败后的自动(failure_action) 、 检测升级后状态的等待时间(monitor) 、 升级后容忍的最大失败率(max_failure_ratio) 、 升级顺序(order) 等。 例如, 指定每次更新两个容器、 更新等待10s、 先停止旧容器再升级。
version: "3.4"
services:
redis:
image: web:stable
deploy:
replicas: 2
update_config:
parallelism: 2
delay: 10s
order: stop-first42. 其他指令
此外, 还有包括domainname、 hostname、 ipc、 mac_address、privileged、 read_only、 shm_size、 stdin_open、 tty、 user、 working_dir等指令, 基本跟docker-run中对应参数的功能一致。
例如, 指定容器中工作目录:
working_dir: /code指定容器中搜索域名、 主机名、 mac地址等:
domainname: your_website.com
hostname: test
mac_address: 08-00-27-00-0C-0A允许容器中运行这些特权命令:
privileged: true43.读取环境变量
从1.5.0版本开始, Compose模板文件支持动态读取主机的系统环境变量。
例如, 下面的Compose文件将从运行它的环境中读取变量${MONGO_VERSION}的值(不指定时则采用默认值3.2) , 并写入执行的指令中。
db:
image: "mongo:${MONGO_VERSION-3.2}"如果直接执行docker-compose up则会启动一个mongo: 3.2 镜像的容器; 如果执行MONGO_VERSION=2.8 docker-compose up 则会启动一个mongo: 2.8镜像的容器。
44. 扩展特性
从3.4开始, Compose还支持用户自定义的扩展字段。 利用YAML语法里的锚点引用功能来引用一定义字段内容。 例如:version: '3.4':
x-logging:
&default-logging
options:
max-size: '10m'
max-file: '10'
driver: json-file
services:
web:
image: webapp:stable
logging: *default-logging5)docker-compose 命令
docker-compose 命令的格式为:
docker-compose [-f=<arg>...] [options] [COMMAND] [ARGS...]命令支持以下选项:
- -f, --file FILE: 指定使用的Compose模板文件, 默认为dockercompose.yml, 可以多次指定;
- -p, --project-name NAME: 指定项目名称, 默认将使用所在目录名称作为项目名;
- --verbose: 输出更多调试信息;
- -v, --version: 打印版本并退出;
- -H, -host HOST: 指定所操作的Docker服务地址;
- -tls: 启用TLS, 如果指定-tlsverify则默认开启;
- -tlscacert CA_PATH: 信任的TLS CA的证书;
- -tlscert CLIENT_CERT_PATH: 客户端使用的TLS证书;
- -tlskey TLS_KEY_PATH: TLS的私钥文件路径;
- -tlsverify:启用TLS并远程校验;
- -skip-hostname-check: 不使用客户端证书中指定的名称校验Docker守护进程的主机名;
- -project-directory PATH: 指定工作目录, 默认为Compose文件所在路径;
- -compatibility:如果设置,Compose将尝试把v3文件中配置的配置项转换为等效的非Swarm配置项;
- -env-file PATH:指定一个环境文件。
docker-compose 还支持以下子命令:
build:构建或重新构建项目中的服务。config:验证和查看Compose配置文件。create:创建服务容器。down:停止项目并删除容器、网络、挂载卷和up创建的镜像。events:实时监控容器的事件信息。exec:在一个运行的容器中执行命令。help:获取一个命令的帮助信息。images:列出项目中所有镜像。kill:发送SIGKILL信号来强制停止服务容器。logs:查看服务容器的日志输出。pause:暂停服务。port:打印某个容器端口映射的公共端口。ps:列出项目中目前的所有容器。pull:拉取服务依赖的镜像。push:推送服务创建的镜像到镜像仓库。restart:重启服务。rm:删除所有停止状态的服务容器。run:在指定服务上执行一个命令。scale:设置指定服务的容器数量。start:启动已存在的服务容器。stop:停止运行中的服务容器。top:显示项目中正在运行的进程信息。unpause:恢复处于暂停状态中的服务。up:自动完成构建服务镜像,创建并启动服务容器等一系列操作。version:打印Docker Compose的版本信息。
① build
格式为:
docker-compose build [options] [SERVICE...]构建(重新构建) 项目中的服务容器。服务容器一旦构建后, 将会带上一个标记名, 例如对于Web项目中的一个db容器, 可能是web_db。可以随时在项目目录下运行docker-compose build来重新构建服务。选项包括:
- --force-rm: 强制删除构建过程中的临时容器;
- --no-cache: 构建镜像过程中不使用cache(这将加长构建过程) ;
- --pull: 始终尝试通过pull来获取更新版本的镜像;
- -m, -memory MEM: 指定创建服务所使用的内存限制;
- -build-arg key=val: 指定服务创建时的参数。
② bundle
格式为:
docker-compose bundle [options]创建一个可分发(distributed Application Bundle, DAB) 的配置包,包括整个服务栈的所有数据, 可以利用该文件启动服务栈。支持选项包括:
- -push-images: 自动推送镜像到仓库;
- -o, -output PATH: 配置包的导出路径。
③ config
格式为:
docker-compose config [options]- -resolve-image-digests: 为镜像添加对应的摘要信息;
- -q, -quiet: 只检验格式正确与否, 不输出内容;
- --services: 打印出Compose中所有的服务信息;
- -volumes: 打印出Compose中所有的挂载卷信息;
④ down
格式为docker-compose down [options]。停止服务栈, 并删除相关资源, 包括容器、 挂载卷、 网络、 创建镜像等。默认情况下只清除所创建的容器和网络资源。支持选项包括:
- --rmi type: 指定删除镜像的类型, 包括all(所有镜像) , local(仅本地) ;
- -v, -volumes: 删除挂载数据卷;
- --remove-orphans: 清除孤立容器, 即未在Compose服务中定义的容器;
- -t, -timeout TIMEOUT: 指定超时时间, 默认为10s。
⑤ events
格式为:
docker-compose events [options] [SERVICE...]实时监控容器的事件信息。
支持选项包括 -json: 以Json对象流格式输出事件信息。
⑥ exec
格式为:
docker-compose exec [options] [-e KEY=VAL...] SERVICECOMMAND [ARGS...]- -d: 在后台运行命令;
- --privileged: 以特权来运行命令;
- -u, -user USER: 以给定用户身份运行命令;
- -T: 不分配TTY伪终端, 默认情况下会打开;
- --index=index: 当服务有多个容器实例时指定容器索引, 默认为第一个;
- -e, -env KEY=VAL: 设置环境变量。
⑦ help
获得一个命令的帮助。
⑧ images
格式为:
docker-compose images [options] [SERVICE...]列出服务所创建的镜像。支持选项为:
- --q: 仅显示镜像的ID。
⑨ kill
格式为:
docker-compose kill [options] [SERVICE...]通过发送SIGKILL信号来强制停止服务容器。支持通过-s参数来指定发送的信号, 例如通过如下指令发送SIGINT信号。
⑩ logs
格式为:
docker-compose logs [options] [SERVICE...]查看服务容器的输出。 默认情况下, docker-compose 将对不同的服务输出使用不同的颜色来区分。 可以通过 --no-color 来关闭颜色。该命令在调试问题的时候十分有用。支持选项为:
- --no-color: 关闭彩色输出;
- -f, -follow: 持续跟踪输出日志消息;
- --t, -timestamps: 显示时间戳信息;
- --tail="all": 仅显示指定个数的最新日志消息。
⑪pause
格式为:
docker-compose pause [SERVICE...]暂停一个服务容器。
⑫ port
格式为:
docker-compose port [options] SERVICE PRIVATE_PORT打印某个容器端⼜所映射的公共端口。选项:
⑬ ps
格式为:
docker-compose ps [options] [SERVICE...]列出项目中当前的所有容器。选项包括:
- -q: 只打印容器的ID信息。
⑭ pull
格式为:
docker-compose pull [options] [SERVICE...]拉取服务依赖的镜像。
选项包括:
--ignore-pull-failures: 忽略拉取镜像过程中的错误。
⑮ push
格式为:
docker-compose push [options] [SERVICE...]推送服务创建的镜像到镜像仓库。
选项包括: --ignore-push-failures: 忽略推送镜像过程中的错误。
⑯ restart
格式为:
docker-compose restart [options] [SERVICE...]重启项目中的服务。选项包括:
- -t, --timeout TIMEOUT: 指定重启前停止容器的超时(默认为10秒) 。
⑰ rm
格式为:
docker-compose rm [options] [SERVICE...]删除所有(停止状态的) 服务容器。 推荐先执行docker-compose stop命令来停止容器。选项:
⑱ run
格式为:
docker-compose run [options] [-p PORT...] [-eKEY=VAL...] SERVICE [COMMAND] [ARGS...]在指定服务上执行一个命令。
例如:
$ docker-compose run ubuntu ping docker.com将会启动一个ubuntu服务容器, 并执行ping docker.com命令。默认情况下, 如果存在关联, 则所有关联的服务将会自动被启动, 除了这些服务已经在运行中。该命令类似启动容器后运行指定的命令, 相关卷、 链接等等都将会按照配置自动创建。
两个不同点:
- 给定命令将会覆盖原有的自动运行命令;
- 会自动创建端口, 以避免冲突。如果不希望自动启动关联的容器, 可以使用--no-deps选项,例如:
$ docker-compose run --no-deps web python manage.py shell
将不会启动web容器所关联的其他容器。选项:
- -d: 后台运行容器;
- --name NAME: 为容器指定一个名字;·--entrypoint CMD: 覆盖默认的容器启动指令;
- -e KEY=VAL: 设置环境变量值, 可多次使用选项来设置多个环境变量;
- -u, --user="": 指定运行容器的用户名或者uid;
- --no-deps: 不自动启动关联的服务容器;
- --rm: 运行命令后自动删除容器, d模式下将忽略;
- -p, --publish=[]: 映射容器端口到本地主机;
- --service-ports: 配置服务端口并映射到本地主机;
- -T: 不分配伪tty, 意味着依赖tty的指令将无法运行。
⑲ scale
格式为:
docker-compose scale [options] [SERVICE=NUM...]设置指定服务运行的容器个数。通过service=num的参数来设置数量。
例如:
$ docker-compose scale web=3 db=2将启动3个容器运行web服务, 2个容器运行db服务。一般的, 当指定数目多于该服务当前实际运行容器, 将新创建并启动容器; 反之, 将停止容器。选项包括-t, --timeout TIMEOUT: 停止容器时候的超时(默认为10秒) 。
⑳ start
格式为:
docker-compose start [SERVICE...]启动已经存在的服务容器。
㉑ stop
格式为:
docker-compose stop [options] [SERVICE...]停止已经处于运行状态的容器, 但不删除它。 通过 docker-compose start 可以再次启动这些容器。选项包括
- -t, --timeout TIMEOUT: 停止容器时候的超时(默认为10秒) 。
㉒ top
格式为:
docker-compose top [SERVICE...]显示服务栈中正在运行的进程信息。
㉓ unpause
格式为:
docker-compose unpause [SERVICE...]恢复处于暂停状态中的服务。
㉔ up
格式为:
docker-compose up [options] [SERVICE...]该命令十分强大, 它将尝试自动完成包括构建镜像, (重新) 创建服务, 启动服务, 并关联服务相关容器的一系列操作。链接的服务都将会被自动启动, 除了已经处于运行状态。可以说, 大部分时候都可以直接通过该命令来启动一个项目。
默认情况, docker-compose up 启动的容器都在前台, 控制台将会同时打印所有容器的输出信息, 可以很方便进行调试。当通过 Ctrl-C 停止命令时, 所有容器将会停止。如果使用docker-compose up -d, 将会在后台启动并运行所有的容器。
一般推荐生产环境下使用该选项。
默认情况, 如果服务容器已经存在, docker-compose up将会尝试停止容器, 然后重新创建(保持使用volumes-from挂载的卷) , 以保证新启动的服务匹配 docker-compose.yml 文件的最新内容。 如果用户不希望容器被停止并重新创建, 可以使用 docker-compose up --no-recreate。 这样将只会启动处于停止状态的容器,而忽略已经运行的服务。 如果用户只想重新部署某个服务, 可以使用docker-compose up --no-deps -d <SERVICE_NAME>来重新创建服务并后台停止旧服务, 启动新服务, 并不会影响到其所依赖的服务。
选项:
- -d: 在后台运行服务容器;
- --no-color: 不使用颜色来区分不同的服务的控制台输出;
- --no-deps: 不启动服务所链接的容器;
- --force-recreate: 强制重新创建容器, 不能与--no-recreate同时使用;
- --no-recreate: 如果容器已经存在了, 则不重新创建, 不能与--forcerecreate同时使用;
- --no-build: 不⾃动构建缺失的服务镜像;
- --abort-on-container-exit: 当有容器停止时中止整个服务, 与-d选项冲突。
- -t, --timeout TIMEOUT: 停⽌容器时候的超时(默认为10秒) , 与 -d 选项冲突;
- --remove-orphans: 删除服务中未定义的孤立容器;
- --exit-code-from SERVICE: 退出时返回指定服务容器的退出符;
- --scale SERVICE=NUM: 扩展指定服务实例到指定数目。
㉕ version
格式为:
docker-compose version打印版本信息。
3、docker swarm
docker-compose 为用户提供单节点中多容器的创建,docker-machine 让用户管理不同的 docker 环境,而 docker swarm 则帮助用户实现 docker 的集群管理,从单机走向集群。
Swarm 的前身是Beam项目和libswarm项目,2014年12月推出 Swarm。之后又在2016年2月整合到 docker engine 1.12 中。使用命令 docker swarm 可以直接使用 swarm(之前是单独的命令 swarm),并支持超过 1K 个的节点。
Swarm 采用“主从”结构,通过Raft协议来在多个管理节点(Manager)中实现共识。工作节点(Worker) 上运行agent接受管理节点的统一管理和任务分配。 用户提交服务请求只需要发给管理节点即可, 管理节点会按照调度策略在集群中分配节点来运行服务相关的任务。
如上图所示,swarm 集群由管理节点(manager)和工作节点(work node)构成。
- swarm mananger:负责整个集群的管理工作包括集群配置、服务管理等所有跟集群有关的工作。
- work node:即图中的 available node,主要负责运行相应的服务来执行任务(task)。
在Swarm V2中, 集群中会自动通过Raft协议分布式选举出Manager节点, 必须额外的发现服务支持, 避免了单点瓶颈。 同时, V2中内置了基于DNS的负载均衡和对外部负载均衡机制的集成支持。
Docker Swarm 提供了标准的 Docker API,所有任何已经与 Docker 守护程序通信的工具都可以使用 Swarm 轻松地扩展到多个主机。
- Dokku
- Docker Compose
- Docker Machine
- Jenkins
1)Swarm集群
Swarm集群(Cluster) 为一组被统一管理起来的Docker主机。 集群是Swarm所管理的对象。 这些主机通过Docker引擎的Swarm模式相互沟通,其中部分主机可能作为管理节点(manager) 响应外部的管理请求, 其他主机作为工作节点(worker) 来实际运行Docker容器。 当然, 同一个主机也可以即作为管理节点, 同时作为工作节点。
当用户使用Swarm集群时, 首先定义一个服务(指定状态、 复制个数、 网络、 存储、 暴露端口等) , 然后通过管理节点发出启动服务的指令, 管理节点随后会按照指定的服务规则进行调度, 在集群中启动起来整个服务, 并确保它正常运行。
① 节点
节点(Node) 是Swarm集群的最小资源单位。 每个节点实际上都是一台Docker主机。通过命令:
docker node [COMMAND]可以管理节点。
Swarm集群中节点分为两种:
- 管理节点(manager node) : 负责响应外部对集群的操作请求, 并维持集群中资源, 分发任务给工作节点。 同时,多个管理节点之间通过Raft协议构成共识。 一般推荐每个集群设置5个或7个管理节点;
- 工作节点(worker node) : 负责执行管理节点安排的具体任务。 默认情况下, 管理节点自身也同时是工作节点。 每个工作节点上运行代理(agent) 来汇报任务完成情况。用户可以通过
docker node promote命令来提升一个工作节点为管理节点; 或者通过docker node demote命令来将一个管理节点降级为工作节点。
② 服务
服务(Service) 是Docker支持复杂多容器协作场景的利器。
docker service [COMMAND]该命令可以用来操作服务。
一个服务可以由若干个任务组成, 每个任务为某个具体的应用。 服务还包括对应的存储、 网络、 端口映射、 副本个数、 访问配置、 升级配置等附加参数。
一般来说, 服务需要面向特定的场景, 例如一个典型的Web服务可能包括前端应用、 后端应用, 以及数据库等。 这些应当都属于该服务的管理范畴。
Swarm集群中服务类型也分为两种(可以通过-mode指定) :
- 复制服务(replicated services) 模式: 默认模式, 每个任务在集群中会存在若干副本, 这些副本会被管理节点按照调度策略分发到集群中的工作节点上。 此模式下可以使用 --replicas 参数设置副本数量;
- 全局服务(global services) 模式: 调度器将在每个可以节点都执行一个相同的任务。 该模式适合运行节点的检查, 如监控应用等。
③ 任务
任务是Swarm集群中最小的调度单位, 即一个指定的应用容器。 例如仅仅运行前端业务的前端容器。 任务从生命周期上将可能处于创建(NEW) 、 等待(PENDING) 、 分配(ASSIGNED) 、 接受(ACCEPTED) 、 准备(PREPARING) 、 开始(STARTING) 、 运行(RUNNING) 、 完成(COMPLETE) 、 失败(Failed) 、 关闭(SHUTDOWN) 、 拒绝(REJECTED) 、 孤立(ORPHANED) 等不同状态。
Swarm集群中的管理节点会按照调度要求将任务分配到工作节点上。例如指定副本为2时, 可能会被分配到两个不同的工作节点上。 一旦当某个任务被分配到一个工作节点, 将无法被转移到另外的工作节点, 即Swarm中的任务不支持迁移。
④ Swarm 外部访问
Swarm集群中的服务要被集群外部访问, 必须要能允许任务的响应端口映射出来。 Swarm中支持负载均衡(ingress load balancing) 的映射模式。 该模式下, 每个服务都会被分配一个公开端口(PublishedPort) ,该端口在集群中任意节点上都可以访问到, 并被保留给该服务。
当有请求发送到任意节点的公开端口时, 该节点若并没有实际执行服务相关的容器, 则会通过路由机制将请求转发给实际执行了服务容器的工作节点。
2)创建 docker swarm 集群
环境上使用的 docker 版本为 19.03,已经集成了 swarm,所以直接使用 docker swarm。
docker 集群的操作命令如下:
- swarm init: 在管理节点上创建一个集群;
- node list: 列出集群中的节点信息;
- swarm join: 加入一个新的节点到已有集群中;
- swarm update: 更新一个Swarm集群;
- swarm leave: 离开一个Swarm集群。
1. 创建 swarm 集群管理节点(manager)
创建 docker 机器:
$ docker-machine create -d virtualBox swarm-manager
初始化 swarm 集群,进行初始化的这台机器,就是集群的管理节点。
创建 swarm 集群:
$ docker-machine ssh swarm-manager
$ docker swarm init --advertise-addr 192.168.99.107 #这里的 IP 为创建机器时分配的 ip。
以上输出,证明已经初始化成功。需要把以下这行复制出来,在增加工作节点时会用到:
docker swarm join --token SWMTKN-1-4oogo9qziq768dma0uh3j0z0m5twlm10iynvz7ixza96k6jh9p-ajkb6w7qd06y1e33yrgko64sk 192.168.99.107:2377
2. 创建 swarm 集群工作节点(worker)
这里直接创建好俩台机器,swarm-worker1 和 swarm-worker2 。

分别进入两个机器里,指定添加至上一步中创建的集群,这里会用到上一步复制的内容:

上图中,由于上一步复制的内容比较长,会被自动截断,实际上在图运行的命令如下:
docker@swarm-worker1:~$ docker swarm join --token SWMTKN-1-4oogo9qziq768dma0uh3j0z0m5twlm10iynvz7ixza96k6jh9p-ajkb6w7qd06y1e33yrgko64sk 192.168.99.107:2377
3. 查看集群信息
进入管理节点,执行:docker info 可以查看当前集群的信息。

通过画红圈的地方,可以知道当前运行的集群中,有三个节点,其中有一个是管理节点。
4. 部署服务到集群中
注意:跟集群管理有关的任何操作,都是在管理节点上操作的。
以下例子,在一个工作节点上创建一个名为 helloworld 的服务,这里是随机指派给一个工作节点:
docker@swarm-manager:~$ docker service create --replicas 1 --name helloworld alpine ping docker.com

5. 查看服务部署情况
查看 helloworld 服务运行在哪个节点上,可以看到目前是在 swarm-worker1 节点:
docker@swarm-manager:~$ docker service ps helloworld

查看 helloworld 部署的具体信息:
docker@swarm-manager:~$ docker service inspect --pretty helloworld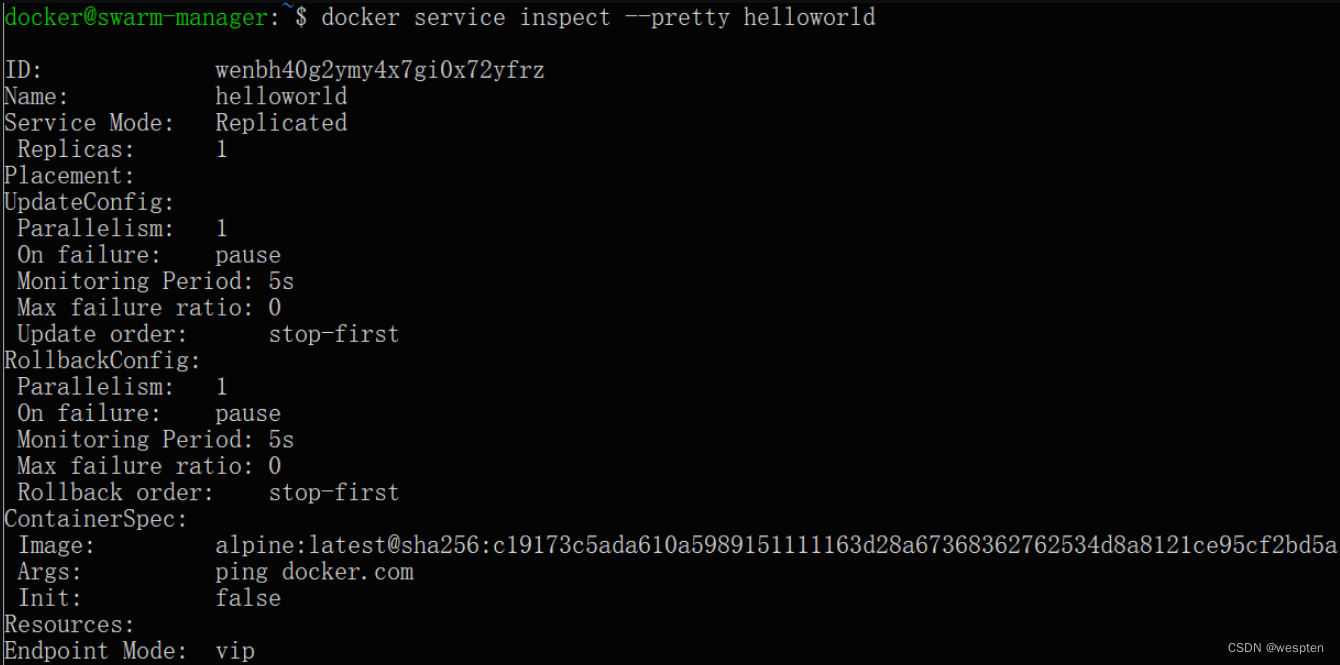
6. 扩展集群服务
我们将上述的 helloworld 服务扩展到俩个节点:
docker@swarm-manager:~$ docker service scale helloworld=2可以看到已经从一个节点,扩展到两个节点:

7. 删除服务
docker@swarm-manager:~$ docker service rm helloworld查看是否已删除:

8. 滚动升级服务
以下实例,我们将介绍 redis 版本如何滚动升级至更高版本。
docker@swarm-manager:~$ docker service create --replicas 1 --name redis --update-delay 10s redis:3.0.6
docker@swarm-manager:~$ docker service update --image redis:3.0.7 redis
看图可以知道 redis 的版本已经从 3.0.6 升级到了 3.0.7,说明服务已经升级成功。
9. 停止某个节点接收新的任务
查看所有的节点:
docker@swarm-manager:~$ docker node ls
可以看到目前所有的节点都是 Active, 可以接收新的任务分配。
停止节点 swarm-worker1:

注意:swarm-worker1 状态变为 Drain。不会影响到集群的服务,只是 swarm-worker1 节点不再接收新的任务,集群的负载能力有所下降。
可以通过以下命令重新激活节点:
docker@swarm-manager:~$ docker node update --availability active swarm-worker1
3)使用 docker swarm 集群
创建集群使用命令:
docker swarm [COMMAND]管理集群使用:
docker node [COMMAND]利用集群管理服务则是命令:
docker service [COMMAND]1. 创建一个服务:
# docker service create --replicas 2 --name ping debian:jessie ping docker.com
skyaj8ukmi8t42c05qba3k6rm
overall progress: 2 out of 2 tasks
1/2: running [==================================================>]
2/2: running [==================================================>]
verify: Service converged 2. 查看一个服务:
# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
skyaj8ukmi8t ping replicated 2/2 debian:jessie
# docker service ps ping
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
x02dsx5to2xq ping.1 debian:jessie centos1 Running Running about a minute ago
3od5f9rzjjzt ping.2 debian:jessie centos2 Running Running about a minute ago
# docker service inspect --pretty ping
ID: skyaj8ukmi8t42c05qba3k6rm
Name: ping
Service Mode: Replicated
Replicas: 2
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: debian:jessie@sha256:c72197393c39c05e19c8ef3388af53a6daa2baa0bed6111b09e40a298d9f7eca
Args: ping docker.com
Init: false
Resources:
Endpoint Mode: vi3. 扩展服务:
# docker service scale ping=1
ping scaled to 1
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
# docker service scale ping=3
ping scaled to 3
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged 4. 使用外部端口:
# docker service create --replicas 2 --name Nginx -p 8080:80 Nginx或者:
# docker service create --replicas 2 --name Nginx --publish published=8080,target=80 Nginxdocker swarm 内部已经实现负载均衡,访问 swarm 集群任意节点的地址都有效,即使该节点没有运行该服务。
service 子节点管理:
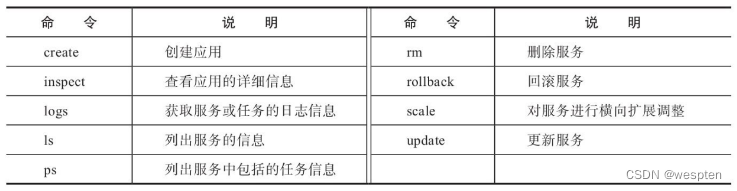
管理 swarm 集群节点的命令是docker node,支持以下选项:
- demote:从管理节点切换为工作节点
- inspect:查看节点
- ls:输出所有节点
- promote:从工作节点切换为管理节点
- ps:输出节点上的任务信息
- rm:从集群中删除节点
- update:更新节点信息
4)swarm 部署多任务
之前我们已经使用过 docker-compose,它能在一次部署多个容器,现在 docker engine 中集成了同样的能,而且能在 swarm 集群环境下部署多个任务。
命令:
docker stack [command]支持以下选项:
1. 创建 docker-compose.yml
docker stack 直接支持 docker-compose 格式的配置文件:
version: "3"
services:
Nginx:
image: Nginx:latest
ports:
- 8088:80
deploy:
mode: replicated
replicas: 42. 部署 stack
# docker stack deploy -c docker-compose.yml web
Creating service web_Nginx
# docker stack ls
NAME SERVICES orchestraTOR
web 1 Swarm
# docker stack ps web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
q34tk96cssvp web_Nginx.1 Nginx:latest centos1 Running Running 6 seconds ago
k6p4iol3vs0v web_Nginx.2 Nginx:latest centos2 Running Running 7 seconds ago
hen5phupzow4 web_Nginx.3 Nginx:latest centos2 Running Running 7 seconds ago
ugr8sgg6lpv9 web_Nginx.4 Nginx:latest centos3 Running Running 6 seconds ago
# docker stack services web
ID NAME MODE REPLICAS IMAGE PORTS
hf5dbvn0a8ww web_Nginx replicated 4/4 Nginx:latest *:8088->80/tcp3. 删除 stack
# docker stack rm web
Removing service web_Nginx
Removing network web_default九、Docker 图形化管理和监控
Portainer:Portainer (基于Go开发)是一个轻量级的管理界面,可以轻松的管理Docker或者Docker相关的集群。
Portainer使用意图是简单部署,它包含可以在任何Docker引擎上运行的单个容器(Dockerfor Linux && Docker for Windows) Portainer允许管理Docker容器、image、volume、network等。它与独立的Docker引擎和Docker Swarm兼容。
1)Portainer 图形化界面
参考官方文档:Install Portainer CE or Portainer Business
$ docker volume create portainer_data
$ docker run -d -p 8000:8000-p 9000:9000-v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer使用portainer需要映射8000和9000端口,同时需要将docker.sock映射到容器中。
接下来使用浏览器访问ip:9000端口,打开页面我们就需要创建一个密码,用户名默认是admin (密码需要是8位数):
这里的连接方式有几种,常见的就是本地直接连接,就是宿主机本身连接,使用宿主机连接自己就需要-v参数,将/var/run/docker.sock映射到容器。 大家的步骤和我一样,就按照我的步骤操作即可。
这里就是主页面,我们在这可以镜像、network、以及容器的相关信息:
这里显示的也比较全,在里面也可以创建容器,设置网络相关。 我就不一一演示了,喜欢的可以自己看一下:
2)Rancher 图形化界面
Rancher是一个开源的企业级容器管理平台,通过Rancher,企业不必自己使用一系列的开源软件去从头搭建容器服务平台。Rancher提供了在生产环境中使用管理Docker和Kubernetes的全栈化容器部署与管理平台 。
3)cAdvisor
cAvisor是Google开发的容器监控工具。
1. 监控Docker Host cAdvisor会显示当前host的资源使用情况,包括cpu、内存、网络、文件系统等。
2. 监控容器 点击Docker Containers链接,显示容器列表。可以详细的打印出每个容器的监控页面。
由于cAvisor提供的操作界面略显简陋,而且需要在不同页面之间跳转,并且只能监控一个主机,不支持集群。但是cAdvisor的一个亮点是它可以将监控到的数据导出给第三方工具,由这些工具进行进一步处理。
这里可以将cAdvisor定位为一个监控数据收集器,收集和导出数据是它的强项,而并非展示数据,cAdvisor支持很多第三方工具,其中就包括prometheus
通过docker运行cAvisor:
#由于cAvisor是国外的镜像,这里我们使用微软的代理拉取镜像启动容器
$ docker pull gcr.azk8s.cn/google_containers/cadvisor:latest
$ docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
gcr.azk8s.cn/google_containers/cadvisor:latest我这里已经将端口映射到宿主机的8080端口,我们检查docker容器启动成功后,就可以直接访问ip:8080端口:
这里我们可以看到宿主机的一些信息:
同时也可以访问http://ip:8080/docker/查看容器的运行状态:
同时aAdvisor还提供了一个Rest API:cadvisor/api.md at master · google/cadvisor · GitHub
cAdvisor通过该REST API暴露监控数据(metrics),格式如下:
http://<hostname>:<port>/api/<version>/<request>
十、Docker企业应用实战
1、scratch构建一个基础镜像
Scratch是一个空的Docker镜像。
1. 编写C程序
hello.c:
#include <stdio.h>
int main()
{
printf("hello docker\n");
}$ gcc --static -o hello hello.c
$ ./hello
hello docker
$3. 编写Dockerfile
FROM scratch
ADD hello /
CMD ["/hello"]4. 构建
$ docker build -t hello .
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
hello latest 2936e77a9daa 40 minutes ago 872kB5. 运行
$ docker container run -it hello
hello docker2、创建自己的centos
1. 原始的centos没有vim和ifconfig
[root@localhost dockerfile]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest feb5d9fea6a5 3 weeks ago 13.3kB
centos latest 5d0da3dc9764 4 weeks ago 231MB
elasticsearch 7.14.2 2abd5342ace0 4 weeks ago 1.04GB
[root@localhost dockerfile]# docker run -it centos
[root@7a61c7e92b9f /]# pwd
/
[root@7a61c7e92b9f /]# vim
bash: vim: command not found
[root@7a61c7e92b9f /]# ifconfig
bash: ifconfig: command not found
[root@7a61c7e92b9f /]# ifconfig
bash: ifconfig: command not found2. 构建dockerfile文件
[root@localhost dockerfile]# vi mydockerfile.centos
[root@localhost dockerfile]# cat mydockerfile.centos
FROM centos
MAINTAINER whw<353538982@qq.com>
ENV MYPATH /usr/local
workdir $MYPATH
RUN yum -y install vim
RUN yum -y install net-tools
EXPOSE 80
ENTRYPOINT echo $MYPATH
ENTRYPOINT echo "---END---"
ENTRYPOINT /bin/bashEXPOSE 80,使用了80 端口进行映射,即使去掉此语法也能使用-p参数进行端口映射。
3. 构建镜像
[root@localhost dockerfile]# docker build -f mydockerfile.centos -t mycentos:0.1 .4. 运行容器并验证
[root@localhost dockerfile]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
mycentos 0.1 93cdc922f14e 43 seconds ago 336MB
hello-world latest feb5d9fea6a5 3 weeks ago 13.3kB
centos latest 5d0da3dc9764 4 weeks ago 231MB
elasticsearch 7.14.2 2abd5342ace0 4 weeks ago 1.04GB
[root@localhost dockerfile]# docker run -it mycentos:0.1 /bin/bash
[root@c8f0ff352c8a local]# pwd
/usr/local
[root@c8f0ff352c8a local]# ifconfig
eth0: flags=4163<UP,broADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.2 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:ac:11:00:02 txqueuelen 0 (Ethernet)
RX packets 8 bytes 656 (656.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 03、创建自己的tomcat镜像
1. 准备镜像文件tomcat压缩包、jdk压缩包
[root@localhost dockerfile]# ll
total 153428
-rw-r--r--. 1 root root 11576317 Oct 17 01:52 apache-tomcat-9.0.54.tar.gz
-rw-r--r--. 1 root root 145520298 Oct 17 01:52 jdk-8u301-linux-x64.tar.gz
-rw-r--r--. 1 root root 201 Oct 16 15:02 mydockerfile.centos
-rw-r--r--. 1 root root 550 Oct 17 02:10 mydockerfile.tomcat2. 编写Dockerfile文件
[root@localhost dockerfile]# cat mydockerfile.tomcat
#基础镜像
FROM centos
#作者
MAINTAINER whw<353538982@qq.com>
#设置工作目录
ENV MYPATH /usr/local
workdir $MYPATH
#复制文件
copY readme.txt $MYPATH/readme.txt
#添加jdk和tomcat到容器
ADD apache-tomcat-9.0.54.tar.gz $MYPATH
ADD jdk-8u301-linux-x64.tar.gz $MYPATH
#安装vim
RUN yum -y install vim
#设置环境变量
ENV JAVA_HOME $MYPATH/jdk1.8.0_301
ENV PATH $PATH:$JAVA_HOME/bin
#暴露端口
EXPOSE 8080
#启动tomcat(注意:这里CMD建议用ENTRYPOINT代替,否则启动容器时如果后面加了命令如/bin/bash很可能不会启动tomcat)
CMD ["/usr/local/apache-tomcat-9.0.54/bin/catalina.sh","run"]3. 构建镜像
[root@localhost dockerfile]# docker build -f mydockerfile.tomcat -t mytomcat:1.0 .4. 运行镜像并验证
docker run -it -p 9090:8080 --name diytomcat mytomcat:1.0
4、把PHP项目封装成docker镜像
项目下载地址: http://static.kodcloud.com/update/download/kodexplorer4.37.zip
项目官网:下载 - 可道云-私有云存储&协同办公平台_企业网盘_企业云盘_网盘_云盘
步骤:
1:先运行一个基础容器,手动制作docker镜像,把制作命令记录下来
2:编写dockerfile,构建镜像
3:测试运行
1. 先进容器
[root@docker01 ~]# docker run -it -p 8080:80 centos:6.92. 进入已经启动容器命令
docker exec -it 775c7c9ee1e1 /bin/bash3. 运行可道云项目
[root@1e0bcbd68686 /]# sed -i "s|enabled=1|enabled=0|g" /etc/yum/pluginconf.d/fastestmirror.conf
[root@1e0bcbd68686 /]# mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
[root@1e0bcbd68686 /]# curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo
[root@1e0bcbd68686 /]# yum -y install httpd unzip PHP-cli PHP PHP-gd PHP-mbstring
[root@1e0bcbd68686 /]# /etc/init.d/httpd start
[root@1e0bcbd68686 /]# cd /var/www/html/ --项目代码放这
[root@1e0bcbd68686 html]# curl -o kodBox.1.15.zip http://static.kodcloud.com/update/download/kodBox.1.15.zip
[root@44f9bad4114a html]# curl -o kodBox.4.37.zip http://static.kodcloud.com/update/download/kodexplorer4.37.zip --用这个
[root@44f9bad4114a html]# chmod -Rf 777 ./*
[root@44f9bad4114a html]# /etc/init.d/httpd restart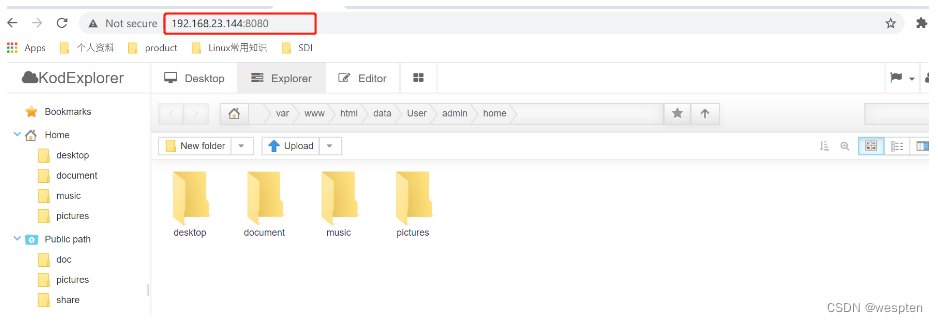
[root@44f9bad4114a html]# history
1 sed -i "s|enabled=1|enabled=0|g" /etc/yum/pluginconf.d/fastestmirror.conf
2 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
3 curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo
4 yum -y install httpd unzip PHP-cli PHP
5 /etc/init.d/httpd start
6 cd /var/www/html/
7 curl -o kodBox.1.15.zip http://static.kodcloud.com/update/download/kodBox.1.15.zip
8 curl -o kodBox.1.15.zip http://static.kodcloud.com/update/download/kodexplorer4.37.zip
9 ls
10 curl -o kodBox.1.15.zip http://static.kodcloud.com/update/download/kodBox.1.15.zip
11 curl -o kodBox.4.37.zip http://static.kodcloud.com/update/download/kodexplorer4.37.zip
12 ls
13 unzip kodBox.4.37.zip
14 ls
15 chmod -Rf 777 ./*
16 yum -y install PHP-gd PHP-mbstring
17 /etc/init.d/httpd restart
18 ll
19 history4. 根据在容器中操作命令编写dockerfile文件
[root@docker01 dockerfile]# mkdir kod && cd kod
[root@docker01 kod]# vim dockerfile
[root@docker01 kod]# cat dockerfile
FROM centos:6.9
RUN sed -i "s|enabled=1|enabled=0|g" /etc/yum/pluginconf.d/fastestmirror.conf
RUN mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
RUN curl -o /etc/yum.repos.d/CentOS-Base.repo https://www.xmpan.com/Centos-6-Vault-Aliyun.repo
RUN yum -y install httpd unzip PHP-cli PHP PHP-gd PHP-mbstring
workdir /var/www/html
RUN curl -o kodBox.4.37.zip http://static.kodcloud.com/update/download/kodexplorer4.37.zip
RUN unzip kodBox.4.37.zip
RUN chmod -Rf 777 /var/www/html
ADD init.sh /init.sh
EXPOSE 80暴露容器的端口
CMD ["/bin/bash","/init.sh"]
[root@docker01 kod]# vim init.sh
[root@docker01 kod]# cat init.sh
#! /bin/bash
/etc/init.d/httpd start
tail -F /var/log/httpd/access_log 为了让服务hang住,哪怕路径不对也没问题
[root@docker01 kod]# ls
dockerfile init.sh
[root@docker01 kod]# docker build -t kod:v1 .
5、部署Python Flask+Redis
1. 准备一个Python文件,名字为 app.py 内容如下:
from flask import Flask
from redis import Redis
import os
import socket
app = Flask(__name__)
redis = Redis(host=os.environ.get('REdis_HOST', '127.0.0.1'), port=6379)
@app.route('/')
def hello():
redis.incr('hits')
return f"Hello Container World! I have been seen {redis.get('hits').decode('utf-8')} times and my hostname is {socket.gethostname()}.\n"2. 准备一个Dockerfile
FROM python:3.9.5-slim
RUN pip install flask redis && \
groupadd -r flask && useradd -r -g flask flask && \
mkdir /src && \
chown -R flask:flask /src
USER flask
copY app.py /src/app.py
workdir /src
ENV FLASK_APP=app.py REdis_HOST=redis
EXPOSE 5000
CMD ["flask", "run", "-h", "0.0.0.0"]$ docker image pull redis
$ docker image build -t flask-demo .
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
flask-demo latest 4778411a24c5 About a minute ago 126MB
python 3.9.5-slim c71955050276 8 days ago 115MB
redis latest 08502081bff6 2 weeks ago 105MB4. 创建一个docker bridge:
$ docker network create -d bridge demo-network
8005f4348c44ffe3cdcbbda165beea2b0cb520179d3745b24e8f9e05a3e6456d
$ docker network ls
NETWORK ID NAME DRIVER ScopE
2a464c0b8ec7 bridge bridge local
8005f4348c44 demo-network bridge local
80b63f711a37 host host local
fae746a75be1 none null local
$5. 创建一个叫 redis-server 的redis container,连到 demo-network上:
$ docker container run -d --name redis-server --network demo-network redis
002800c265020310231d689e6fd35bc084a0fa015e8b0a3174aa2c5e29824c0e
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
002800c26502 redis "docker-entrypoint.s…" 4 seconds ago Up 3 seconds 6379/tcp redis-server
$6. 创建flask container
$ docker container run -d --network demo-network --name flask-demo --env REdis_HOST=redis-server -p 5000:5000 flask-demo打开浏览器访问 http://127.0.0.1:5000
Hello Container World! I have been seen 36 times and my hostname is 925ecb8d111a.
7. 如果把上面的步骤合并到一起,成为一个部署脚本
# prepare image
docker image pull redis
docker image build -t flask-demo .
# create network
docker network create -d bridge demo-network
# create container
docker container run -d --name redis-server --network demo-network redis
docker container run -d --network demo-network --name flask-demo --env REdis_HOST=redis-server -p 5000:5000 flask-demo6、微服务Spring Cloud与docker整合
1. 使用Docker的maven插件,构建springboot应用
官方文档:Getting Started | Spring Boot with Docker
创建springboot工程,选择web:
启动运行:
2. Maven添加配置
pom.xml:
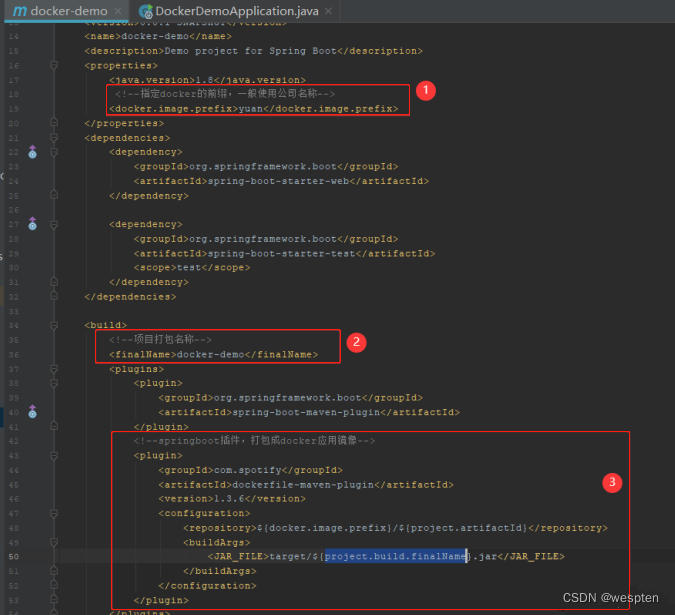
<properties>
<docker.image.prefix>yuan</docker.image.prefix>
</properties>
<build>
<finalName>docker-demo</finalName>
<plugins>
<plugin>
<groupId>com.spotify</groupId>
<artifactId>dockerfile-maven-plugin</artifactId>
<version>1.3.6</version>
<configuration>
<repository>${docker.image.prefix}/${project.artifactId}</repository>
<buildArgs>
<JAR_FILE>target/${project.build.finalName}.jar</JAR_FILE>
</buildArgs>
</configuration>
</plugin>
</plugins>
</build>配置说明:
Spotify 的 docker-maven-plugin 插件是用maven插件方式构建docker镜像的。
${project.build.finalName} 产出物名称,缺省为${project.artifactId}-${project.version}
3. 打包SpringCloud镜像并上传私有仓库并部署
创建Dockerfile,默认是根目录,可以修改为src/main/docker/Dockerfile,如果修则需要制定路径:
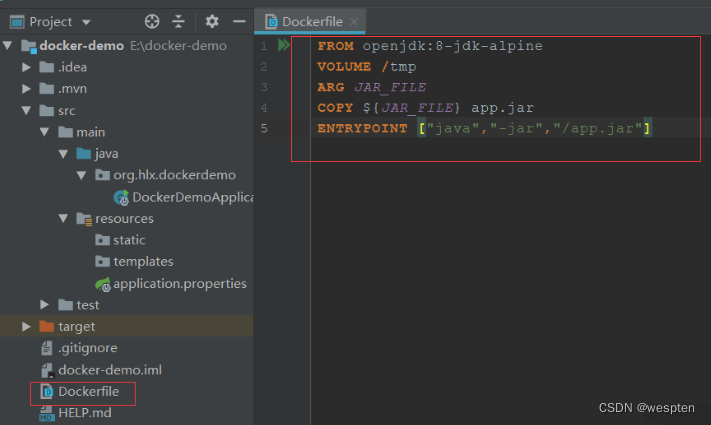
FROM openjdk:8-jdk-alpine
VOLUME /tmp
ARG JAR_FILE
copY ${JAR_FILE} app.jar
ENTRYPOINT ["java","-jar","/app.jar"]参数讲解:
FROM <image>:<tag> 需要一个基础镜像,可以是公共的或者是私有的, 后续构建会基于此镜像,如果同一个Dockerfile中建立多个镜像时,可以使用多个FROM指令
VOLUME 配置一个具有持久化功能的目录,主机 /var/lib/docker 目录下创建了一个临时文件,并链接到容器的/tmp。改步骤是可选的,如果涉及到文件系统的应用就很有必要了。/tmp目录用来持久化到 Docker 数据文件夹,因为 Spring Boot 使用的内嵌 Tomcat 容器默认使用/tmp作为工作目录
ARG 设置编译镜像时加入的参数, ENV 是设置容器的环境变量
copY : 只支持将本地文件复制到容器 ,还有个ADD更强大但复杂点
ENTRYPOINT 容器启动时执行的命令
EXPOSE 8080 暴露镜像端口4. 构建镜像
mvn install dockerfile:build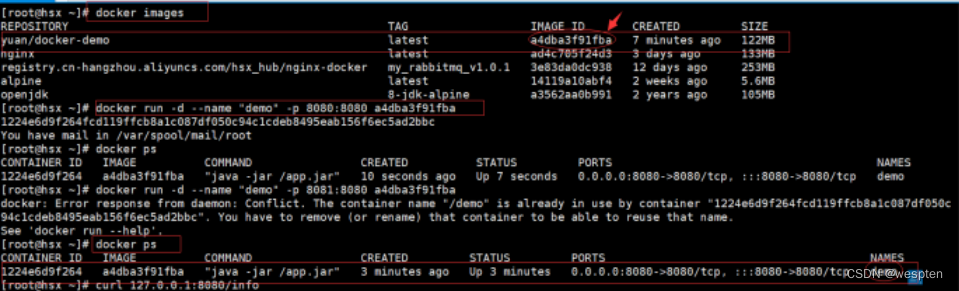
5. 登录阿里云容器镜像服务
docker login --username=yyds registry.cn-hangzhou.aliyuncs.com6. 打标签
docker tag a4dba3f91fba registry.cn-hangzhou.aliyuncs.com/hsx_hub/Nginx-docker:docker-demo-v2021097. 推送到镜像仓库
docker push registry.cn-hangzhou.aliyuncs.com/hsx_hub/Nginx-docker:docker-demo-v202109
8. 应用服务器拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/hsx_hub/Nginx-docker:docker-demo-v202109
docker run -d --name my_docker_demo1 -p 8099:8080 a4dba3f91fba
docker logs -f 178b60772db34cf482ac0a5ac1e8e03ea6ffbb3618cf0ceb43f8ec17ae315e93
9. 访问:http://IP远程:8089/user/find