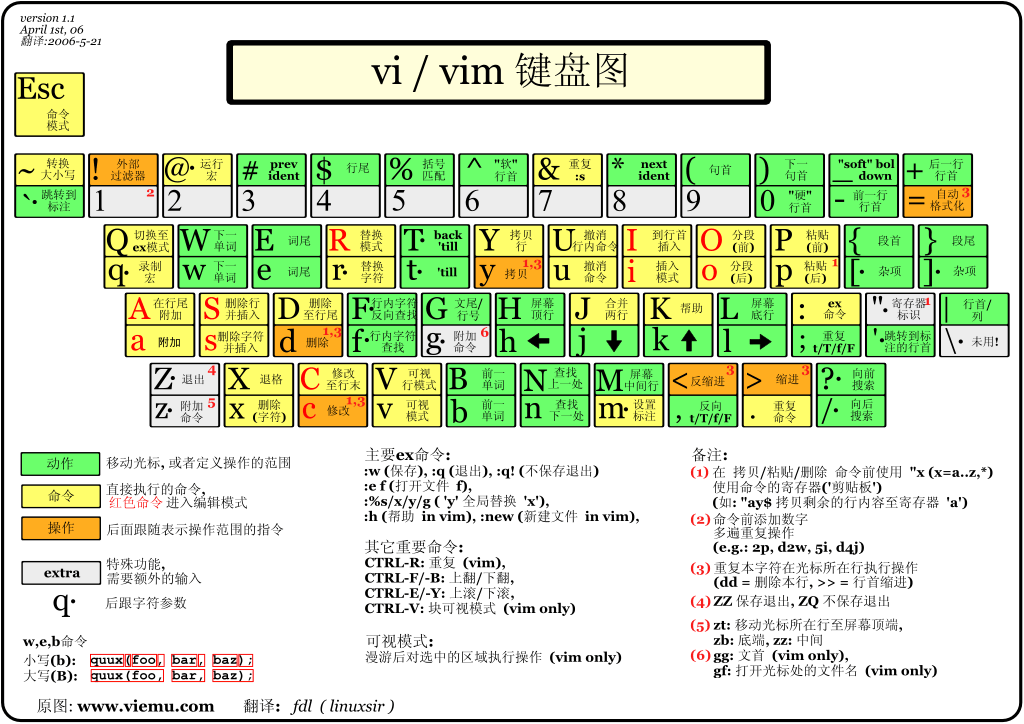
1. 需求
2. 方案1: vim 自带统计
-
概述
- vim 自带方案
-
操作
-
定位到 文段内某行
-
vim 标准模式
-
输入
g ctrl + g
-
-
结果
-
统计信息
-
Col 16-15 of 39-31
-
Line 38 of 102
- 行信息
- 解释
- 本文一共 102 行
- 当前光标处在, 38 行
- 解释
- 行信息
-
Word 72 of 189
- 单词信息
- 解释
- 本文一共 189 个单词
- 当前光标, 处在第 72 个单词
- 解释
- 单词信息
-
Char 389 of 1232
-
Byte 565 of 1862
- 字节信息
- 略
- 字节信息
-
-
问题
3. 方案2: 替换1
-
概述
- 尝试用 ex 命令行下的 s 命令
-
操作
-
结果
4. 方案3: 替换2
-
概述
- 继续尝试用 ex 命令行下的 s 命令
-
操作
-
结果
-
后续
-
字符集
-
可以自己调整字符集
# 汉字 [\u4E00-\u9FCC] # 汉字 和 数字 [\u4E00-\u9FCC0-9] # 汉字, 数字, 大小写字母 [\u4E00-\u9FCC0-9A-Za-z]
-
-
- 这个我暂时没有考虑过
- 总感觉会 慢上一些
- 这个我暂时没有考虑过
-
ps
- ref