必须走如下步骤:
sess=tf.Session()
sess.run(result)
sess.close()
才能执行运算。
With tf.Session() as sess:
Sess.run()
通过会话计算结果:
with sess.as_default():
print(result.eval()) 表示输出result的值
tf.Variable(tf.random_normal([2,3],stddev=2)) 通过满足正态分布的随机数来初始化神经网络中的参数是一个常用方法。
init_op=tf.global_variables_initializer() 初始化变量
变量类型在赋值后不能再改变,维度可以发生变化。
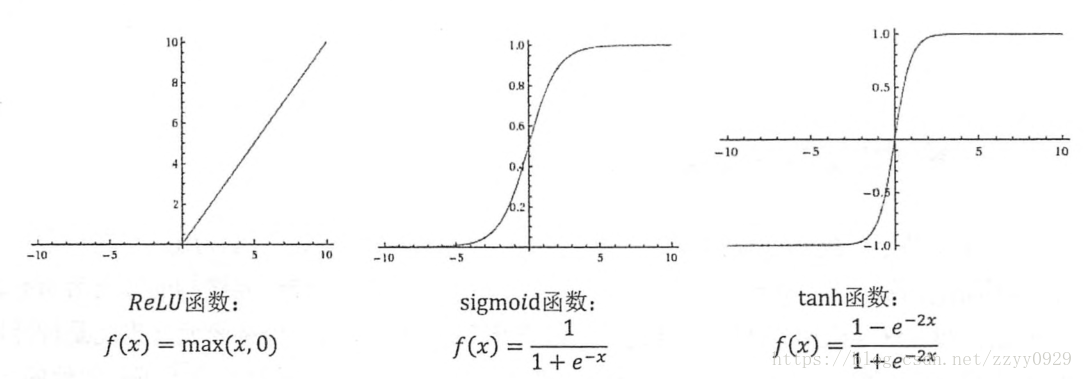
通过激活函数实现去线性化。
decayed_learning_rate为每一轮优化时使用的学习率 learning_rate为事先设定好的初始学习率;decay_rate为衰减系数,decay_steps为衰减速度。
每完整地过完一遍训练数据,学习率就减小一次,这使得数据集中所有数据对模型训练有相等的作用。
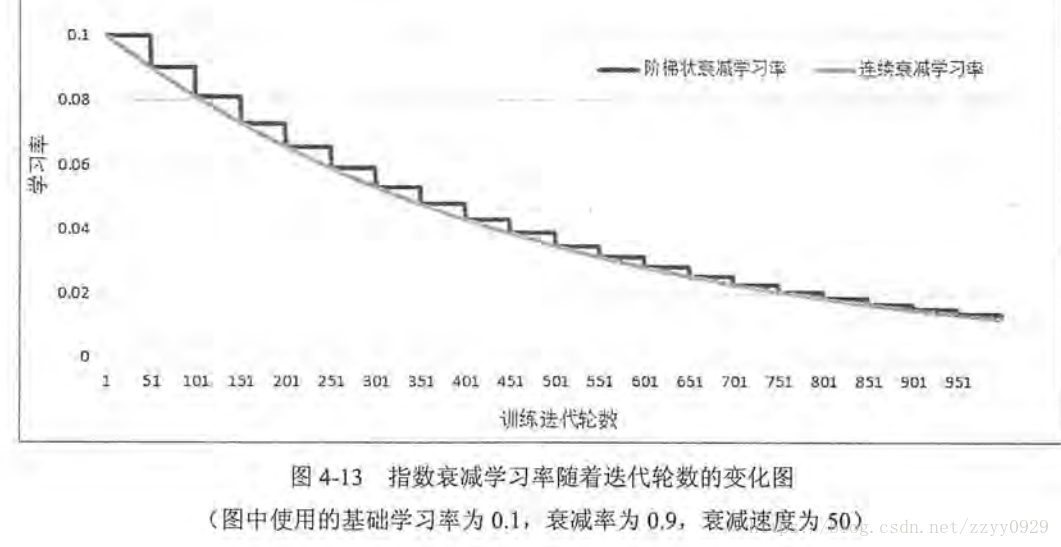
每次都乘0.9 每50轮减小一次。
既可以加快训练初期的训练速度,同时后期又不会出现损失函数在极小值周围徘徊往返的情况。
过拟合与正则化:
V1*v2 对应相乘
Matmul(v1,v2)矩阵相乘
交叉熵:cross_entropy=tf.nn.sparse_softmax_cross_entropy_with_logits(y,y_)
Mse=tf.reduce_mean(tf.square(y_-y)) y_标签值,y为预测值
Tf.greater 选择出较大值。
Tf.select tf.select(tf.greater(v1,v2),v1,v2) 并且复制
L1正则化会让参数变的更稀疏(有更多的参数变为0),计算公式不可导;L2不会。L1可用于特征选择。
L2正则化优化会比较简洁,防止模型过拟合,有助于减小方差,构造模型参数较小,使得抗扰动能力强。
定义L2正则化损失函数:
loss=tf.reduce_mean(tf.square(y_-y))+tf.contrib.layers.l2_regularizer(lambda)(w)
L2 正则化
def get_weight(shape,lambda1):
var=tf.Variable(tf.random_normal(shape),dtype=tf.float32)
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(lambda1)(var))
return var
x=tf.placeholder(tf.float32,shape=(None,2))
y_=tf.placeholder(tf.float32,shape=(None,1))
batch_size=8
每一层节点数
layer_dimension=[2,10,10,10,1]
网络层数
n_layers=len(layer_dimension)
cur_layer=x
in_dimension=layer_dimension[0]
for i in range(1,n_layers):
out_dimension=layer_dimension[i]
weight=get_weight([in_dimension,out_dimension],0.001)
bias=tf.Variable(tf.constant(0.1,shape=[out_dimension]))
cur_layer=tf.nn,relu(tf.matmul(cur_layer,weight)+bias)
in_dimension=layer_dimension[i]
mse_loss=tf.reduce_mean(tf.square(y_-cur_layer))
tf.add_to_collection('losses',mse_loss)
loss=tf.add_n(tf.get_collection('losses'))
滑动平均模型:
tf.train.ExponentialMovingAverage 会维护一个影子变量

MNIST 数据集 60000(55000+5000验证集)+10000 28*28
在模型参数调整的过程中,不应当依赖测试集的准确率来确定参数(要尽量使得测试集是不可见的)为的是拟合未知数据的能力。所以在训练集中划分出验证集对参数进行评估和选取。
tf.variable_scope
模型保存:saver=tf.train.Saver()
Saver.save(sess,”….ckpt”)
直接加载:saver=tf.train.import_Meta_graph(“/ckpt.Meta”)
卷积与池化:
卷积:
1.stride [1,2,2,1] 卷积步长为2, 第1\4参数为1.分别表示batch和channel
VALID:without padding(仅丢弃下面或右边最多的行/列)
SAME:with zero padding 左奇右偶,在左边补一个0,右边补2个0
weight_variable:
第一二参数值得卷积核尺寸大小,即patch=5*5,第三个参数是图像通道数=1,第四个参数是卷积核的数目=32,代表会出现多少个卷积特征图像;
W_conv1 = weight_variable([5, 5, 1, 32])
对于每一个卷积核都有一个对应的偏置量。
b_conv1 = bias_variable([32])
图片乘以卷积核,并加上偏执量,卷积结果28x28x32
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
池化:
ksize [1,2,2,1] 池化窗口大小2*2 第1\4参数为1.
池化结果14x14x32 卷积结果乘以池化卷积核
h_pool1 = max_pool_2x2(h_conv1)
第二层卷积操作
32通道卷积,卷积出64个特征
w_conv2 = weight_variable([5,5,32,64])
64个偏执数据
b_conv2 = bias_variable([64])
注意h_pool1是上一层的池化结果,#卷积结果14x14x64
h_conv2 = tf.nn.relu(conv2d(h_pool1,w_conv2)+b_conv2)
全连接层:
二维张量,第一个参数7764的patch,也可以认为是只有一行7764个数据的卷积,第二个参数代表卷积个数共1024个
W_fc1 = weight_variable([7764, 1024])
1024个偏置数据
b_fc1 = bias_variable([1024])
tf.cats:转换数据类型
tf.round() 舍入最近的整数
tf.reduce_sum(x,1/0):按某一维度以求和方式降维 0纵向求和,1横向求和,不填默认为所有元素求和
tf.reduce_mean(x,1/0):按某一维度以求和方式降维 同上
np.shuffle(a):对矩阵进行洗牌,原矩阵改变.无返回值
定义初始化变量。但是这里仍然不会立即执行。需要通过sess来将数据流动起来 。
切记:所有的运算都应在在session中进行:
with tf.Session() as sess:
对变量进行初始化,执行(run)init语句
Feed_dict:
step_loss = sess.run([loss], Feed_dict={X: train_X, Y: train_Y})#Feed_dict的作用是给使用placeholder创建出来的tensor赋值。其实,他的作用更加广泛:Feed 使用一个 值临时替换一个 op 的输出结果. 你可以提供 Feed 数据作为 run() 调用的参数. Feed 只在调用它的方法内有效, 方法结束, Feed 就会消失.train_X替换X,train_Y替换Y
sess.run(b)只会计算和b有关的流程
