SpringCloud
容易单点挂掉,并发能力弱,代码耦合度高
扩展,不好扩展,要么都并发,但后台不需要,造成浪费
好处:维护简单
基于http协议,这是和dubbo的本质区别,dubbo的核心是基于RPC:远程过程调用
分布式,垂直拆分:功能拆分
水平拆分:分层 web层、service、mapper
方便水平扩展
方便独立优化
解耦合
提高并发
缺点:增加成本,重复开发
SNAPSTOP 快照版本,随时修改
M:mileStone M1第一个里程碑版本
SR:service RELEASE 第一个正式版本 GA
前后台分离 ;用户后台 ,用户前台 、订单前台、订单前台 互相调用
缺点:调用关系错综复杂、维护困难
SOA:注册中心,容器 服务的提供者和调用者都注册到注册中心中
微服务架构
粒度很小,每一个服务对应唯一的业务能力
面向服务:restfulPI接口,跟语言无关
自治:服务之间互不干扰,各自独立
前后端分离:提供统一的rest接口
数据库分离:各自数据源
部署独立, 服务之间有调用,但是重启服务互不影响,利于持续集成和交付,每个服务都是独立的组件,可复用,可替换,渐低耦合,利于维护
Spring cloud 、 dubbo(阿里)
服务之间调用方式:
2、 HTTP 网络传输协议,基于tcp,规定了数据格式 Spring cloud
缺点:消息封装臃肿,优点:服务的提供和调用没有技术限定,自由灵活,可以rest风格。
HTTp客户端工具: 处理响应请求
HTTPclient
OKHttp
URLConnection
Jackson
工具类 ObjectMapper 可以序列化,反序列化
Private static final ObjectMapper mapper=new ObjectMapper();
序列化: mapper .writeValueAsstring(user)
反序列化mapper .readValue(response,User.class)
spring的restTemplate模板工具类,实现了序列化和反序列化
微服务
Spring Cloud
核心组件: 都在Netflix下
1、Eureka :服务治理组件。包含服务注册中心、服务注册和发现机制的实现
2、Zuul:网关组件,提供智能路由,访问过滤功能
3、Ribbon: 客户端负载均衡的服务调用组件(客户端负载)
4、Feign :服务调用,给与Ribon和Hystrix的声明式服务调用组件(声明式服务调用)
5、Hystrix:容错管理组件,实现断路器,帮助服务中延迟,为故障提供容错能力。
Eureka使用,创建模块 ,提供者,调用者,Eureka模块注册中心
区别于zookeper不用装在linux
Eureka Server 进入自我保护机制
防止误杀服务机制,个别客户端心跳失联,认为是客户端问题,剔除客户端。
大量客户端失联,认为网络问题,进入自我保护机制。恢复心跳,自动退出自我保护机制。
Renew:服务续约,每隔30秒发送一次心跳来续约。
eviction 服务剔除,Eureka客户端连续90秒没有向Eureka服务器发送服务续约,即心跳,剔除服务。
Cancel:服务下线
原理:
Eureka server 集群部署,异步数据同步,数据最终一致性
Service provider 提供者 注册到eureka
Service consumer 消费者 获取注册服务列表,消费服务
Eureka模块注册中心
server:
port: 10086
spring:
application:
name: wxb-eureka #作为微服务名称注入到eureka容器
eureka:
client:
service-url:
defaultZone: http://localhost:10086/eureka #http://localhost:${server.port}/eureka
启动类加注解
@EnableEurekaServer//启用eureka组件服务端
提供者加依赖eureka客户端依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
配置文件:
spring:
datasource:
url: jdbc:MysqL://localhost:3306/mybatis1?serverTimezone=UTC
username: root
password: wxb123456
application:
name: service-provider #作为微服务的名称
eureka:
client:
service-url:
defaultZone: http://localhost:10086/eureka
引导类 注解启用
//@EnableEurekaClient//启用客户端eureka
@EnablediscoveryClient//发现的客户端
List instances=discoveryClient.getInstances(service-provider )
ServiceInstance instance=Instances.get(0)
(“http://”+Instance.getHost()+”:”+instance.getPort()+”/user/”+id,User.class)
register-with-eureka: true #默认就是true
instance:
lease-expiration-duration-in-seconds: 10 #10秒过期时间
lease-renewal-interval-in-seconds: 5 # 5秒一次心跳 心跳时间
服务端配置文件中
server:
enable-self-preservation: false #关闭自我保护状态
eviction-interval-timer-in-ms: 5000 #提出无效连接的间隔时间
@autowired
discovertClient discovertClient 拉取所有服务信息
用法:
1、引入依赖(消费方) :eureka 已经依赖了 配置文件
2、加上@loadBalanced
@Bean
@LoadBalanced//开启负载均衡
public RestTemplate restTemplate(){
return new RestTemplate();
3、默认轮询
负载均衡算法=rest接口第几次请求数%服务器集群总数量 = 实际调用服务器位置下标,每次服务重启后rest接口计数从1开始
Ribbon负载均衡策略:
轮询:对所有的服务器节点按顺序分配,每个服务器的概率是等同的
加权轮询:对每个服务器加了权重比利,性能强劲的服务器的权重就高一些,性能弱的权重随机
重试
最低并发
可用过滤
响应时间加权重
区域权重
Hystrix 熔断,微服务的一种保护机制
为每个依赖调度分配一个小的线程池,如果线程池已满调用会立即被拒绝,默认不采用排队,加速失败判定时间。
用户请求将不在访问服务,而是通过线程池中的空闲线程来访问服务,如果线程已满,或者请求超时,则降级处理
服务降级处理:优先保证核心服务,非核心服务不可用和弱可用
请求失败,不会阻塞,不会无休止等待或直到系统崩溃,而是会至少看到一个执行结果,例如返回有好的提示信息
服务降级会导致请求失败,不会导致阻塞,最多影响这个请求,不会影响其他服务没有响应。
触发hystrix服务降级条件:1、线程池已满 2、请求超时
使用:(在customers 服务调用方 配置)
降级:
1、引入依赖 引入启动器
2、配置文件(可以不加)
设置Hystrix的超时时间
默认是1秒,开发环境够用
生产环境的话,修改:timeoutInMilliseconds: 6000ms
3、启动类加注解@EnableCicuitBreaker //开启熔断
4、两个方法产生关联 加注解@HystrixCommand(fallbackMethod=”熔断方法名”) 使用全局的熔断方法可以改成@HystrixCommand
5、局部的熔断,熔断和被熔断方法的返回值和参数列表一致
Public String 熔断方法名 (Long id){
Return “服务正忙,稍后再试”;
}
想要制定熔断方法为全局的
在类上面加注解@defaultProperties(defaultFallback=”熔断方法名”)
多个熔断方法,全局的:返回值和被熔断的方法一致,参数列表为空
Public String 熔断方法名 (){
Return “服务正忙,稍后再试”;
}
消费者consumers引导类上注解好几个,可以使用组合注解
@SpringBootApplication
@EnablediscoveryClient//发现的客户端
@EnableCircuitBreaker//开启熔断器
可以用组合注解代替
@Spring CloudApplication
服务熔断:熔断器,断路器
可以弹性容错,情况好转之后,可以自动重连
先是拒绝所有后续请求,一段时间后,允许部分请求,调用成功则恢复,否则继续断开
熔断:
熔断器的三个状态:
1、闭合状态
2、打开状态:对请求计数,失败请求百分比达到阈值,触发熔断,默认阈值50%,请求次数不低于20次
3、半开状态 open之后,休眠时间:5秒,进入半开,若请求都是健康的,关闭熔断器。否则继续休眠计时
可以修改参数:
出发熔断的最小次数,默认20、熔断失败的请求最小占比,50%、休眠时间,默认5秒
流程:
1、每次调用创建hystrixcommand,依赖调用封装在run方法,执行execute同步或异步调用
2、调用是否缓存,缓存直接返回结果,没有缓存,判断熔断器是否打开
3、打开熔断器,getfallback降级逻辑
4、没打开熔断器,判断线程池/队列/信号量是否跑满,满了进入fallback降级逻辑
5、没跑满调用hystrixcommand的run方法,执行依赖逻辑,没有出现异常,继续,否则fallback降级,没有超时返回调用结果,超时进入fallback降级。
两种资源隔离方式
1、线程池隔离模式 线程池存储请求,处理请求,设置超时时间,为每一个线程申请线程池,消耗资源,可以应对突发洪流(处理不完,放入线程池慢慢处理)
2、信号量隔离模式 使用原子计数器/信号量 来记录当前多少个线程运行,请求到来先判断计数器数值,超过设置的最大线程个数,放弃新的请求,不超过,计数器+1,请求返回计数器-1,无法应对突发洪流
Feign
伪装,把rest请求进行隐藏,伪装成类似于springmvc的controller一样,不用拼接url、参数,一切交给feign
使用:
常见一个接口,在接口上加一些注解即可
Springcloud中feign支持springmvc注解,整合了Ribbon和eureka
1、引入依赖 openfeign
2、引导类上加注解 @EnableFeignClients //启用feign组件
去掉
/*@Bean
@LoadBalanced//开启负载均衡
public RestTemplate restTemplate(){
return new RestTemplate();
*/
不用再注入restemplate。去掉之前的hystrix的熔断代码
1、创建一个接口 xxxclient
4、注入接口到controller中
有feign,默认关闭了Hystrix熔断,使用需要手动开启
Feign:
Hystrix:
Eanabled: true
Feign使用熔断
新建一个类xxxfallback 实现 xxxclient接口,实现熔断方法
接口的注解修改为:
@ FeignClient(value=“微服务的名称”,fallback=”xxxfallback ”)
把xxxfallback类上面加上 @Component 注入容器
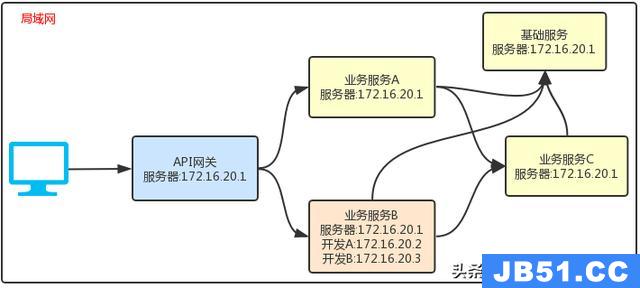
Zuul网关
路由: 分发不同的微服务
保证对外服务的安全性,需要实现对外访问的权限控制,每个微服务都需要,破坏了restfulapi的无状态特点
无法直接服用既有接口
使用网关,所有请求都先经过zuul网关
具备服务路由,负载均衡,权限控制
核心:是一系列的过滤器
功能:身份认证与安全、审查与监控、动态路由、压力测试、静态响应处理、负载均衡、多区域弹性
创建zuul模块
server:
port: 10001
spring:
application:
name: wxb-zuul
zuul:
routes:
service-provider: #路由名称,随便起,习惯上写服务名
path: /service-provider/**
url: http://localhost:8080 #路由到 http://localhost:8080这个地址
启动类加注解 @EnableZuulProxy //启用zuul组件
多个路径,负载均衡
需要把zuul注入到eureka中
1、添加eureka依赖
2、配置文件
加上eureka.client.service-url-defaultZone: http://localhost:100086/eureka
3、启用eureka @EnablediscoveryClient
4、
server:
port: 10001
spring:
application:
name: wxb-zuul
zuul:
routes:
service-provider: #路由名称,随便起,习惯上写服务名
path: /service-provider/**
ServiceId: service-provider
或者 常用
routes:
service-provider: /service-provider/** #可以随便改/user/**
service-consumer: /consumer/**
或者不写,访问路径直接自己加上 localhost:10001service-provider/user/1 即可
还可以加 /api 区分是否请求经过网关 可以不要(专业性)
routes:
service-provider: /service-provider/** #可以随便改/user/**
service-consumer: /consumer/**
Prefix: /api
路径前面必须加/api才能访问
Zuul过滤器:请求拦截
流程:
请求--》pre 类型过滤器---》route filter--》post filters ---响应
Pre、routing 出现异常的话---》error filter--post filter-》响应 error filter 本身异常,执行postfilter--响应
post filter 本身异常--》error filter--》响应
自定义:
1、一个类loginFilter 继承 ZuulFilter 接口,重写四个方法 类上加@component 放入spring容器
public abstract String filterType(); return “pre”;
//执行顺序,返回值越小,执行顺序越高
public abstract int filterOrder(); return 10;
//是否执行该过滤器:true:执行
boolean shouldFilter(); return true;
//编写过滤器逻辑
Object run() throws ZuulException{
Return null;//什么都不做
//初始化zuul网关的 上下文对象
Requestcontest con=Requestcontest.getCurrentContext();
//获取对象
Request rr=Con.getRequest();
//获取参数
String ss=Rr.getParameter(“”)
Con.setSentZuulResponse(false) //不转发请求
//设置状态码,401,身份未认证
Con.setResponseStatusCode(HttpStatus.SC_UNAUTHORIZED)
Con.setResponseBody(“request error”) //设置响应提示
}
2、过滤器类型 : pre routing、post、error
声明式:直接装配 和 编程式
浏览器browser---》consumer-----》provider
Consumer、provider都去注册中心Eureka,provider可能调用别的provider、redis、MysqL、elasticSearch等等 Consumer还可能调用别的provider
Eureka的时候 项目的返回从Json变为了Xml
SpringBoot项目中集成了EurekaServer,又需要jackson-dataformat-xml这个依赖 ,
可以将实体转换为xml也可以转换为json,根据发起请求的request头中Accept,application/xml在最后匹配json的*/ *前面,优先级高过json,所以返回了XML
解决:在请求的Mapping上加上produces = { “application/json;charset=UTF-8” }
Ribbon 客户端的负载均衡
Provider以集群的方式启动
增加端口号;1000\2000\3000 三个provider
1、Eclipse 直接修改配置文件的端口,main方法启动,在dashboerd看不到,
或者启动一个端口之后 Run As--》run configurations--》选择项目--》new configuration---》
选择arguments标题栏,program arguments中输入 --server.port=需要的端口号即可
2、Idea 不修改配置文件,在edit configuration 中 点击 copy configuration
在environment 选项下面,program arguments中写: --server.port=需要的端口号即可
Feign:声明式远程调用
// 表示当前接口和一个provider对应,springboot-provider指定要调用的微服务名称
@FeignClient("springboot-provider")
public interface EmployeeRemoteService {
主启动类加注解@EnableFeignClients
400:参数类型不匹配,需要的参数没有传参,违反数据校验规则
Common和provider传参都需要加注解
用来获取请求参数的注解@RequestParam @PathVariable @RequestBody不能省略,
简单类型
@RequestMapping("/provider/get/emp/list/remote")
List<Employee> getListRemote(@RequestParam("keyword") String keyword);
复杂类型:
@requestBody(Employee employee)
Hystrix:熔断、降级
微服务很多,多个调用同一个微服务,被调用的微服务超时,都开始等待
一个问题蔓延至整个系统。
CAP
一致性+可用性+P:分区容错性(必须的) 一致性+可用性(保证一个)
雪崩:某个服务出现故障,导致服务级联调用而引发雪崩
Provider的提供方案:
熔断:一段时间内侦测到多个类似错误,会强迫之后的多个调用快速失败,不在访问远程服务器,防止应用不断尝试,让程序继续执行,防止超时出现
使用ResultEntity作为返回值类型,成功失败返回同一个类型,result属性判断成功还是失败,失败:message 成功:data返回数据
Consumer的提供方案:
降级:防止用户一直等待,使用降级方式,调用FallBack(返回友好提示,不会去处理请求)
例如: 当前请求人数过多,请稍后重试
dubbo可以整合hystrix
<!--provider熔断-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
主启动类上面加注解:// 开启断路器功能 @EnableCircuitBreaker
// @HystrixCommand 指定当前方法出问题指定另一个备用方法
@HystrixCommand(fallbackMethod = "getEmpWithCircuitBreakerBackUp")
@RequestMapping(value = "/provider/get/emp/circuit/breaker",produces = { "ap
public ResultEntity<Employee> getEmpWithCircuitBreakerBackUp(@RequestParam("sinal") String sinal){
Consumer 客户端降级
1、实现consumer端 实现服务降级功能
2、实现fallbackFactory接口时,要传入@FeignClient标记的接口类型
3、在create() 方法中返回@FeignClient标记的接口类型的对象,当provider调用失败
* 会执行这个对象的对应方法
public class MyFallBackFactory implements FallbackFactory<EmployeeRemoteService> {
public EmployeeRemoteService create(final Throwable throwable) {
@FeignClient(value = "springboot-provider",fallbackFactory = MyFallBackFactory.class)
public interface EmployeeRemoteService {
feign:
hystrix:
enabled: true # 开启降级
监控: provider
1、加入监控依赖 spring-boot-starter-actuator
2、配置application.yml
management:
endpoints:
web:
exposure:
include: hystrix.stream
3、创建监控工程
加入依赖
spring-cloud-starter-netflix-hystrix-dashboard
在主启动类上面加注解
// 启用仪表盘
@EnableHystrixDashboard
配置文件配置:
server:
port: 8000
spring:
application:
name: springcloud-dashboard
监控访问地址:http://localhost:8000/hystrix
使用:
1、直接查看数据(provider)访问地址:localhost:1000/actuator/hystrix.stream (1000是provider的端口号) 不方便,因为一直在监控,数据不断增加
2、第二种访问 http://localhost:8000/hystrix ,在页面输入localhost:1000/actuator/hystrix.stream ,Delay设置毫秒,Title标题,使用默认值即可
Zuul网关:提供给一个统一的入口
没有的话,直接访问provider,有网关的话
请求到达网关
1、客户端直接请求不同的微服务,增加复杂性
2、存在跨域请求www.a.com www.b.com 浏览器跨域存在阻碍(出于安全考虑)
3、认证复杂,登陆问题:1、共享session 2、单点登录
4、难以重构,可能需要新的微服务
Zuul: 请求的路由 、 过滤
请求---》zuul----》请求特征---》微服务名称-----》Eureka---》具体的微服务
依赖: spring-cloud-starter-netflix-eureka-client
spring-cloud-starter-netflix-zuul
配置文件:
server:
port: 9000
spring:
application:
name: springcloud-zuul
eureka:
client:
service-url:
defaultZone: http://localhost:5000/eureka/
启动类:
// 开启zuul网关代理
@EnableZuulProxy
初步访问:服务名称最好小写,访问也要小写
http://localhost:9000/微服务名称/目标为服务具体功能地址
例如:http://localhost:9000/springcloud-feign-consumer/feign/consumer/test/fallback?signal=1
在配置文件中配置:
zuul:
routes:
employee:
service-id: springcloud-feign-consumer
path: /my/**
此时通过:微服务名称
http://localhost:9000/springcloud-feign-consumer/feign/consumer/test/fallback?signal=1
和 路由
http://localhost:9000/my/feign/consumer/test/fallback?signal=1
都可以访问。
可以设置禁用服务名称访问
ignored-services: # 禁用服务名称访问 ,忽略所有 ignored-services: '*'
- springcloud-feign-consumer
还可以在禁用的基础上增加前缀
ignored-services: ‘*’ // 所有微服务都不可以通过名称访问
prefix: /bbb
还可以
server:
port: 9000
servlet:
context-path: /aaa # 属于springboot 的application tomcat 访问之前加此路径
这是通过zuul访问的规则路径
还可以不通过zuul直接:http://localhost:7000/feign/consumer/test/fallback?signal=1 来访问
请求---》gateway(过滤器)-----》微服务
转发只允许在自己工程内部才可以
重定向可以访问新的资源
ZuulFilter
线程本地化技术 threadLocal
一个请求访问另一个请求:session域、application域等(横向)
同一个线程内部:可以直接调用方法,通过传参;还可以通过threadlocal技术先set() 使用再 get()
springcloud要基于springboot开发
Springcloud分布式架构一站式解决方案,可以天然基于spring全家桶开发
dubbo 熔断降级需要hystrix
阿里的Nacos加入spring,官方推荐Nacos代替eureka作为注册中心
Idea项目工程导入eclipse
找到项目——复制,删除idea特征,留下maven特征(src+Pom.xml目录)通过eclipse的import --》maven 已存在的项目即可,最好把项目复制到工作区,maven导入的不会复制项目再工作区。
Seata 分布式事务解决方案
全局的数据一致性问题
全局唯一的事务ID transation ID XID
三组件:
Transation Coordinator TC 事务协调者 驱动全局事务的提交回滚
Transation Manager TM 事务管理器 开始全局事务的提交回滚
Resource Manager RM 资源管理器 管理分支事务,驱动分支事务提交回滚
1、TM向TC申请开启一个全局事务@GlobalTransactional,创建成功并生成一个全局唯一XID
2、XID在微服务调用的上下文中传播
3、RM向TC注册分支事务,将其纳入XID对应全局事物的管辖
4、TM向TC发起针对XID的全局提交或回滚决议
5、TC调度XID下辖的全部分支事务完成提交或回滚
下载网址:https://github.com/seata/seata/releases
使用:本地@Transational 全局@GlobalTransational
下载使用1.1.0版本
1、备份file.conf配置文件
2、修改:自定义事务组名称+事务存储模式为DB+数据库连接信息
3、修改service模块和store模块
先启动nacos-server.cmd
再启动seata-server.bat
三个微服务:订单==库存==账户
用户下单==》创建一个订单==》远程调用库存服务扣减库存==》远程调用账户扣减余额==》订单状态修改成已完成。
@GlobalTransactional
没有加注解,超时超时之后,出现超时异常,库存减少,钱减少,但是订单显示未完成。
Feign有超时重试机制,可能多次扣减。
@GlobalTransactional(name = "wxb-create-order",rollbackFor = Exception.class)
异常:统统回滚 异常之后,没有插入写操作
Seata原理
Tc:seata服务器
Tm:@GlobalTransactional 事务发起者
TCC模式:可与AT混用,更灵活
SAGA模式:长事务,每个参与者都提交本地事务。无锁,高性能,不保证隔离性
XA模式(开发中)
一阶段
Seata拦截业务sql,,业务更新前,before images 前置镜像
执行业务sql,更新业务数据
更新之后,after images 后置镜像 生成行锁(locK_table表)
二阶段
顺利,seata把一阶段的的快照数据和行锁删除,解锁,清理数据
异常:二阶段回滚,回滚一阶段已经执行的业务sql,反向补偿,before images 还原数据,之前还需要校验脏写,如果有,转人工处理。还原之后,删除before images、after images 和行锁 删除un_log 表数据
Cap理论
不能同时满足c、a、p(必须保证)
一致性:强一致性,每次读写返回的值都是最新的,结果一致。
可用性:发出请求总能得到数据,不一定是最新数据
分区容错性:分布式系统,不同的节点,遇到分区故障,可以满足一致性和可用性,不能同步,但是也可以容忍。除非网络全部故障。
CA:放弃分区容错,一个整体应用,不是分布式,单体架构
CP:放弃可用性,保证一致性 例如 zookeeper,redis
AP:保证可用性 例如eureka,淘宝,最终一致性。
强一致性:复制是同步的
弱一致性:复制是异步的,即使过了不一致时间窗口期,读取的也不一定是最新值,存在问题。12306买票
最终一致性:弱一致性的特殊形式,没有更新的条件,最终访问的是最后的值。
随着时间推移,数据最终一致。
一般采用ap 保证可用性,采用最终一致性。
Base理论
BA:基本可用 和高可用的区别:基本可用(故障时)可以适当延长响应时间。
S:柔性状态 数据存在中间状态,同步中,正在同步。
E:最终一致性 一段时间后,数据必须一致。
分布式事务协议
二阶段提交2PC 常用方案 协调者一个 和 参与者 多个
1、准备阶段 投票阶段 可以不可以提交,记录日志,没有提交事务 ,同意/终止
2、提交阶段 所有参与者返回同意,发出commit请求,发送ack 完成,协调者收到所有的ack,完成事务。如果返回消息是 终止,或者超时未返回,撤销事务,告诉所有的参与者根据一阶段日志 ,回滚事务。无论成功与否,事务在二阶段都会完成。
优点:数据强一致性。
缺点:事务节点都是阻塞型 底层是锁 占用资源 需要补充超时机制,否则失联会一直阻塞。数据一致性问题,协调者或者某个参与者宕机,协调者发出消息,但是唯一接收消息的参与者宕机,即使再选举出新的协调者,事务的状态不确定。
三阶段提交 3PC 二阶段的改进
引入超时机制、插入准备阶段,保证提交之前各个节点状态一致。
多了先询问能不能操作执行,再执行事务,不提交,反馈之后再提交。
1、cancommit 询问 返回yes/no no/超时 直接中断事务。
2、Precommit 协调者根据参与者反馈进行操作 事务预提交,执行事务操作,但不提交事务,记录事务日志。返回ack,等待最终指令。
3、执行提交。二阶段 失败 (no/超时)中断事务 协调者撤销请求,回滚。
缺点:第三阶段:超时之后,会继续事务提交,造成数据不一致。
分布式方案:
1、TCC
2、全局消息
3、分布式事务 seata
TCC 事务补偿机制 二阶段提交(强一致性)
byteTcc(停止更新)
Try尝试 锁定资源
confirm确认 执行业务,释放锁
Cancel 取消 出问题,释放锁
库存、订单
一、Try:库存100,要购买2 先检查库存是否足够,冻结购买的库存2,创建订单,状态为待确认。
二、Confirm/cancle:根据try的服务是否正常 ,执行confirm或cancel,如果执行confirm或cancel失败,会一直重试。(保证了数据的强一致性)并发性一般。
数据最终一致性(基于confirm和cancle幂等性)
可靠性:集群解决单点故障
Seata at模式和tcc模式
AT模式:基于本地ACID事务的关系型数据库
TCC模式:不依赖底层数据库,数据库日志表、成功批量清理回滚日志、失败自动补偿,数据回滚。
自定义的prepare、commit、rollback逻辑