我正在重构一些Spring JDBC代码,其中一些成本较高的查询执行“SELECT * FROM …” – 并且即将开始检查实际需要哪些列,而只是SELECT x,y FROM ..它们.但通过ResultSet类读取似乎大多数数据都是延迟加载的.当您执行ResultSet.next()时,它会移动数据库中的游标(此应用程序中的Oracle 10g),当您执行ResultSet.getXX()时,它会检索该列.所以我的想法是,如果你做一个“SELECT *”但只检索你想要的列,你并没有真正受到性能影响.我正确地考虑了这个吗?我能想到的唯一可以解决这个问题的地方是数据库,因为它将查询结果存储在内存中并且必须使用更多内存,如果只选择了几行,那么它实际上只会存储指向那些击中查询的列甚至不是这种情况.
思考?
注意:这仅适用于标准ResultSet,我知道CachedResultSet的行为不同.
当您拥有优化程序可以使用的“覆盖索引”时,将会出现性能提高的最简单情况.如果您选择的所有列和您要过滤的所有列都是单个索引的一部分,则该索引是查询的覆盖索引.在这种情况下,Oracle可以避免从表中读取数据,并且可以只读取索引.
在其他情况下,性能也会得到改善.如果您有查询存在不影响最终输出的临时连接,则优化器可能能够执行table elimination.如果要选择所有列,则无法进行优化.如果您有包含链接行的表,则删除列也可以消除获取已删除列所在的其他块的需要.如果表中有LONG和LOB列,则不选择这些列也会带来很大的改进.
最后,消除列通常会减少Oracle在通过线路传输之前对结果进行排序和哈希所需的空间量.即使ResultSet可能会懒散地在应用程序服务器的RAM中加载数据,它也可能无法通过网络懒惰地获取列.如果从表中选择所有列,则JDBC驱动程序可能必须一次获取至少1个完整行(更有可能是每个网络往返获取10或100行).由于驱动程序不知道何时获取数据将要求哪些列,您必须通过网络传送所有数据.
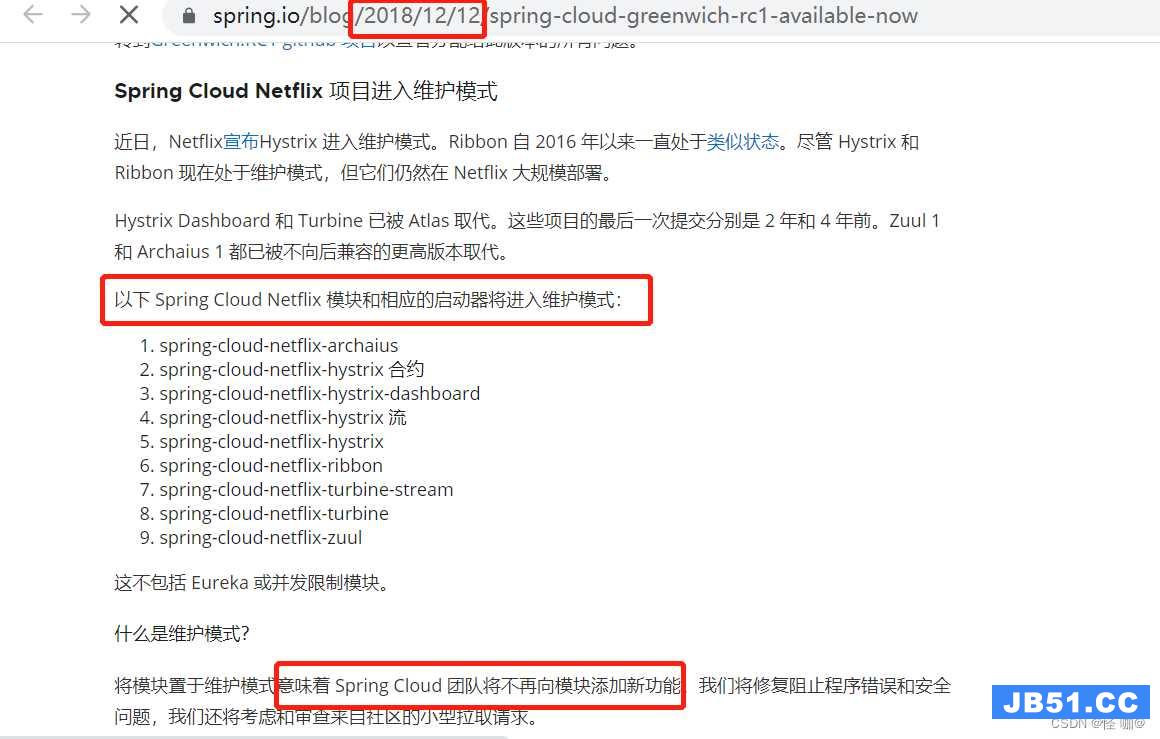 这篇文章主要介绍了SpringCloudAlibaba和SpringCloud有什么区...
这篇文章主要介绍了SpringCloudAlibaba和SpringCloud有什么区...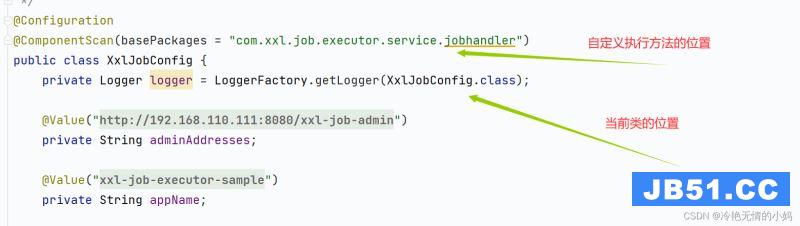 本篇文章和大家了解一下SpringCloud整合XXL-Job的几个步骤。...
本篇文章和大家了解一下SpringCloud整合XXL-Job的几个步骤。...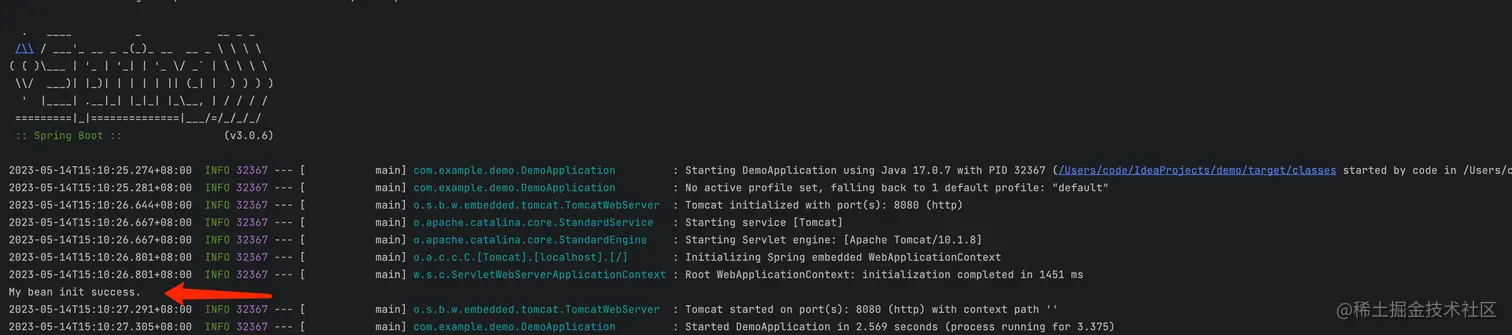 本篇文章和大家了解一下Spring延迟初始化会遇到什么问题。有...
本篇文章和大家了解一下Spring延迟初始化会遇到什么问题。有... 这篇文章主要介绍了怎么使用Spring提供的不同缓存注解实现缓...
这篇文章主要介绍了怎么使用Spring提供的不同缓存注解实现缓...