ElasticSearch 作为一款常见的搜索引擎,在项目中随时会用到。为方便在项目中访问 ElasticSearch,Spring 官方封装了对 ElasticSearch 的支持。通过 Spring Data 的 ElasticSearch 模块,我们可以方便地使用 ElasticSearch。
本文主要涉及的知识点有:
- ElasticSearch 的使用场景和技术。
- spring-data-elasticsearch 中 Operations 和 Repository 相关技术的使用。
- 如何在 Spring Boot 项目中引入 spring-data-elasticsearch。
ElasticSearch的使用场景和相关技术
搜索功能不仅在互联网项目中需要,在企业级项目中也需要。在通用型搜索引擎出现之前,通常实现搜索功能的方式是关系型数据库的模糊查询,但是使用模糊查询具有效率低、响应速度慢、不支持匹配度排序等缺陷。因此,在项目中引入搜索引擎就成了实现搜索功能的不二之选。
常用的搜索引擎除 ElasticSearch 之外还有 Solr,它和 ElasticSearch 都是基于 Lucene 开发出来的。Lucene 是 Apache 的开源搜索项目,这个项目的产出是一个搜索库,被称为 Lucene Core。Lucene Core 是 Java 实现的,提供了强大的索引和搜索功能,以及拼写检查,单击突出显示和高级分析/标记功能。
Apache Solr 是 Apache 的一个独立的顶级项目,其内置了完整的 Lucene 包。自从 Lucene 和 Solr 整合之后,Solr 和 Lucene 发布的版本都是一致的。
由于 Lucene Core 只是 Java 库,不能独立使用,因此平时在企业中使用最多的还是 ElasticSearch 或 Solr。ElasticSearch 和 Solr都能实现搜索,但是也不完全相同。Solr 有庞大的用户群,而且比较成熟,但是建立索引时会影响搜索效率,不适合用作实时搜索。而 ElasticSearch 支持分布式、实时分发,支持建立索引和搜索同时进行。也正是由于 ElasticSearch 的这些特点,使得 ElasticSearch 的使用变得越来越流行。
spring-data-elasticsearch 支持的ElasticSearch Client
要在项目中使用 ElasticSearch,首先要连接到 ElasticSearch。实现连接到 ElasticSearch 的模块被称作 ElasticSearch Client。
ElasticSearch 的 Client
ElasticSearch 官方提供了 3 个 Client,具体如下:
- org.elasticsearch.client.transport.TransportClient
- org.elasticsearch.client.RestClient
- org.elasticsearch.client.RestHighLevelClient
TransportClient 位于 Elasticsearch 包下,是 Elasticsearch 官方早期支持的 ElasticSearch Client,但是在 ElasticSearch 7.x 版本中已经标注为 Deprecated,并且将在 8.0 版本中移除,所以建议不使用 TransportClient 作为 ElasticSearch Client。
RestHighLevelClient 是 TransportClient 的直接替代者,也是 ElasticSearch 官方推荐和默认的 Client(松哥注:该客户端在最新版本中已经废弃)。
除了 ElasticSearch 官方提供的 Client,spring-data-elasticsearch 还支持响应式的客户端 ReactiveElasticsearchClient。ReactiveElasticsearchClient 是基于 WebClient 技术实现的 ElasticSearch Client,依赖于 Spring 的响应式栈。响应式栈在本书中不会涉及。
创建 RestHighLevelClient
spring-data-elasticsearch 提供了接口AbstractElasticsearchConfiguration,使用该接口可以非常方便地在容器中引入 RestHighLevelClient。
AbstractElasticsearchConfiguration 接口位于org.springframework.data.elasticsearch.config 包下,可以按照如下方式来使用:
@Configuration
public class ESConfigutration extends AbstractElasticsearchConfiguration {
@Override
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("192.168.110.128:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}如上面的代码,自定义一个配置类,继承 AbstractElasticsearchConfiguration 接口,并实现接口中定义的方法 RestHighLevelClient elasticsearchClient()。
上面的 ClientConfiguration 用来配置 ElasticSearch 客户端的属性,比如可以配置代理、连接超时时长以及 socket 超时时长等,上面的代码示例中只配置了 ElasticSearch 服务的地址和端口号。
使用 operations 相关 API 操作 ElasticSearch
spring-data-elasticsearch 中定义了 4 个命名以 Operations 结尾的接口,用来操作 ElasticSearch 的不同对象,接口分别是:
- IndexOperations
- DocumentOperations
- SearchOperations
- ElasticsearchOperations。
4 个 Operations 接口
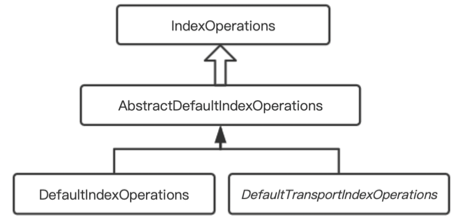
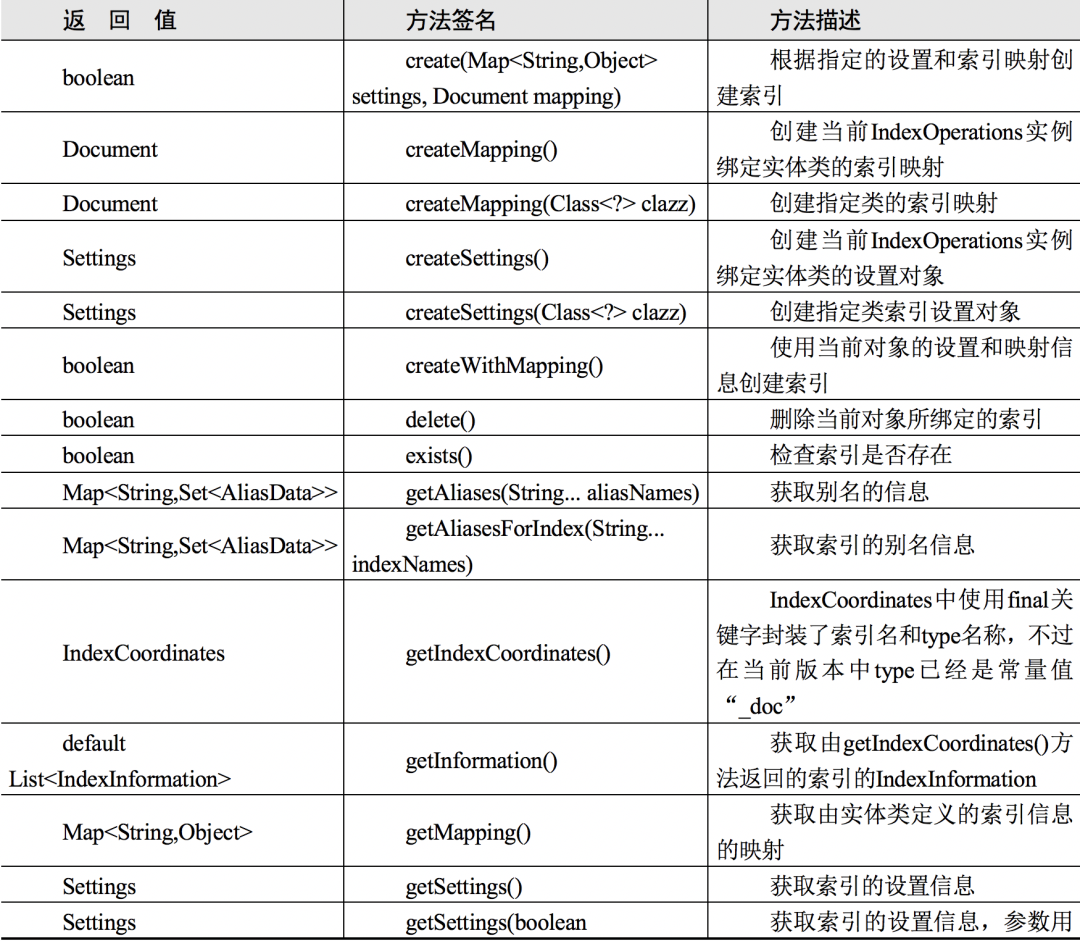
IndexOperations 和 DocumentOperations 接口从命名上可以看出,分别定义的是 Index 级别的接口和 Document 的接口,比如创建和删除索引(Index)以及创建和根据 id 更新、查询 entity。spring-data-elasticsearch 提供了 IndexOperations 的默认实现,如图 6.1 所示,有 DetaultIndexOperations 和 DefaultTransportIndexOperations 两个实现类。这两个实现类使用的客户端不同,前者使用的是 RestHighLevelClient,后者使用的是 TransportClient,当然更推荐使用前者。
在 spring-data-elasticsearch 的 4.2.3 版本中,IndexOperations 中定义了操作 Index 的方法,对应 ElasticSearch 官方文档的 Index APIs 部分,用于管理单个索引、索引设置、别名、映射和索引模板等。注意,表 6.1 中不包含已经被标记为过时的方法,以及不包含使用 ElasticSearch Legacy API 实现的方法。


SearchOperation、DocumentOperations 和 ElasticsearchOperations 的继承关系及其实现类的继承关系如图 6.2 所示。

从图 6.2 中可以看出,ElasticsearchOperations 继承了 SearchOperation 和 DocumentOperations,并且 spring-data-elasticsearch 为 ElasticsearchOperations 提供了两个实现类,即 ElasticsearchRestTemplate 和 ElasticsearchTemplate,同上面的实现类一致,也是基于两种客户端的实现。
DocumentOperations 接口中定义了 Document 级别的方法,对应 ElasticSearch 官方文档的 Document APIs 部分,包括对 Document 的增删改查等操作,具体方法列举在表 6.2 中。



接口 SearchOperations 中定义了搜索和聚合索引的相关操作,对应 ElasticSearch 官方文档的 Search APIs 部分,具体方法列举在表 6.3 中。


最后,接口 ElasticsearchOperations 继承了 DocumentOperations 和 SearchOperations,所以在接口 DocumentOperations 和 SearchOperations 中定义的方法都可以通过接口 ElasticsearchOperations 来使用。除了继承的方法外,接口 ElasticsearchOperations 中还定义了一些通用的辅助性的方法,具体列举在表 6.4 中。


搜索结果类型
ElasticSearch 搜索 API 在返回搜索数据的同时也会返回搜索产生的额外信息,比如匹配到的总数量、排序字段值、高亮显示等,这些伴随着搜索的额外信息就被放置在 spring-data-elasticsearch 提供的搜索结果包装类中。本节将介绍 spring-data-elasticsearch 搜索结果的包装类。
由于部分类使用了和 ElasticSearch官方提供的相同的类名,因此先对这些类所属的包说明一下,以下所提及的类如果没有特殊说明,默认都是包 org.springframework.data. elasticsearch.core 下的,而不是 ElasticSearch 官方的包 org.elasticsearch.search 下的同名类。
SearchHit
搜索接口返回的数据实体都会使用 SearchHit类作为包装,用来放置数据实体相关的搜索信息,具体字段(get方法)信息见表6.5。

SearchHits
上面的 SearchHit是对单条数据的封装,而接口 SearchHits是对整体搜索结果的封装,其内部定义了获取 SearchHit列表的方法,以及获取一次搜索的总体数据的方法等,具体方法信息见表 6.6。


查询条件的封装
在接口 SearchOperations 中定义的方法,除了最后两个查询建议的方法外,其他方法中都使用了类型为 org.springframework.data.elasticsearch.core.query.Query 的参数。该类型为接口类型,spring-data-elasticsearch 提供了 3 个实现类,分别是:
- CriteriaQuery
- StringQuery
- NativeSearchQuery。
下面将依次介绍这3个实现类。
- CriteriaQuery
CriteriaQuery 允许我们通过 API 调用的方式来定义查询条件,好处就是不需要用户理解 ElasticSearch 原生的查询语法。
CriteriaQuery 有两个构造器,也是创建 CriteriaQuery 的两种方式。这两个构造器都需要类为 org.springframework.data.elasticsearch.core.query.Criteria 的封装查询条件,所以可以理解为 CriteriaQuery只是 Criteria 的包装类,我们创建和封装查询条件主要通过 Criteria 来实现。
Criteria 方法的命名仿照了 sql 关键字,比如创建查询条件可以使用其静态方法 where()。另外,对于多个条件组合,可以使用 and() 和 or()。
下面通过示例说明 CriteriaQuery 类的使用方式。
【示例 6.1】查询出版时间为给定年份的图书
假定 publishYear 字段为图书出版年份,那么查询出版年份为 2021 年的图书的查询条件封装的代码如下:
Criteria criteria = Criteria.where("publishYear").is(2021);
Query query = new CriteriaQuery(criteria);【示例6.2】 查询出版时间在 2015~2019 年,并且类别为科学技术的图书。使用静态方法 and() 创建第二个条件并与第一个条件关联起来,具体代码如下:
Criteria criteria = Criteria.where("publishYear").between(2015,2019). and("category").is("科学技术");
CriteriaQuery criteriaQuery = new CriteriaQuery(criteria);【示例6.3】查询出版时间在 2015~2019 年,并且类别为科学技术或历史人文的图书。
这里用到了或和与的组合,使用 subCriteria 来实现,具体代码如下:
Criteria criteria = Criteria.where("publishYear").between(2015, 2019).subCriteria(Criteria.where("category").is("科学技术").or("category").is("历史人文"));
CriteriaQuery criteriaQuery = new CriteriaQuery(criteria);- StringQuery
StringQuery 以 ElasticSearch 可以理解 JSON 格式封装查询条件,因此比较适合熟悉 ElasticSearch 查询语法的用户。
这里的 JSON 格式可以对应 ElasticSearch 的 Query DSL(Domain Specific Language)语法,具体可以参考 ElasticSearch 官方文档的 Query DSL 部分。
【示例6.4】 使用 StringQuery 查询出版时间在 2015~2019 年,并且类别为历史人文的图书。使用到了 Boolean 查询来组合两个查询条件,具体代码如下:
Query query = new StringQuery("{\n" +
" \"bool\": {\n" +
" \"must\": [\n" +
" {\n" +
" \"match\": {\n" +
" \"category\": \"历史人文\"\n" +
" }\n" +
" },\n" +
" {\n" +
" \"range\": {\n" +
" \"publishYear\": {\n" +
" \"gte\": 2015,\n" +
" \"lte\": 2019\n" +
" }\n" +
" }\n" +
" }\n" +
" ]\n" +
" }\n" +
" }");
SearchHits<Book> searchHits = operations.search(query, Book.class);从上面的例子可以看出,使用 StringQuery 虽然创建对象简单,但是可读性差,并且需要熟悉 ElasticSearch 的 DSL 语法。
- NativeSearchQuery
NativeSearchQuery 使用实现比较复杂的查询,比如聚合操作等。由于其可以和 ElasticSearch 官方 API 结合使用,因此命名为 Native。
虽然从功能上讲 NativeSearchQuery 比 CriteriaQuery 强大,但是由于其使用既需要熟悉 ElasticSearch 官方 API,又需要学习 NativeSearchQuery 的 API,学习成本相比前两种要更高一些,并且调试起来也不比 DSL 容易,所以也没有比较明显的优势。
在工作中,简单的查询使用 CriteriaQuery,复杂的查询先在 Kibana 中使用 DSL 调试好查询语句,然后直接复制到代码中创建 StringQuery 来构建查询,这样或许效率更高一些。
以上内容节选自 《Spring Boot 从零开始学》,作者郭浩然。

送书啦送书啦~
小伙伴们留言说说你为什么需要这本书,松哥会从留言的小伙伴中选出来 10 位幸运小伙伴,《Spring Boot 从零开始学》包邮到家!