原理
介绍
哈希表(Hash table,也叫散列表), 是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表hash table(key,value) 的做法其实很简单,就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,几乎可以看成是常数时间;而代价仅仅是消耗比较多的内存。然而在当前可利用内存越来越多的情况下,用空间换时间的做法是值得的。另外,编码比较容易也是它的特点之一。 哈希表又叫做散列表,分为“开散列” 和“闭散列”。
我们使用一个下标范围比较大的数组来存储元素。可以设计一个函数(哈希函数, 也叫做散列函数),使得每个元素的关键字都与一个函数值(即数组下标)相对应,于是用这个数组单元来存储这个元素;也可以简单的理解为,按照关键字为每一 个元素“分类”,然后将这个元素存储在相应“类”所对应的地方。
但是,不能够保证每个元素的关键字与函数值是一一对应的,因此极有可能出现对于不同的元素,却计算出了相同的函数值,这样就产生了“冲突”,换句话说,就是把不同的元素分在了相同的“类”之中。后面我们将看到一种解决“冲突”的简便做法。 总的来说,“直接定址”与“解决冲突”是哈希表的两大特点。
哈希函数构造
就是映射函数构造,看某个元素具体属于哪一个类别。
除余法: 选择一个适当的正整数 p ,令 h(k ) = k mod p ,这里, p 如果选取的是比较大的素数,效果比较好。而且此法非常容易实现,因此是最常用的方法。最直观的一种,上图使用的就是这种散列法,公式:
index = value % 16
学过汇编的都知道,求模数其实是通过一个除法运算得到的,所以叫“除法散列法”。
平方散列法
求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式:
index = (value * value) >> 28 ( 右移,除以2^28。记法:左移变大,是乘。右移变小,是除)
数字选择法: 如果关键字的位数比较多,超过长整型范围而无法直接运算,可以选择其中数字分布比较均匀的若干位,所组成的新的值作为关键字或者直接作为函数值。
斐波那契(Fibonacci)散列法:平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。
1,对于16位整数而言,这个乘数是40503
2,对于32位整数而言,这个乘数是2654435769
3,对于64位整数而言,这个乘数是11400714819323198485
这几个“理想乘数”是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列,即如此形式的序列:0,1,2,3,5,8,13,21,34,55,89,144,233,377,610, 987,1597,2584,4181,6765,10946,…。另外,斐波那契数列的值和太阳系八大行星的轨道半径的比例出奇吻合。
对我们常见的32位整数而言,公式:
index = (value * 2654435769) >> 28
冲突处理
线性重新散列技术易于实现且可以较好的达到目的。令数组元素个数为 S ,则当 h(k) 已经存储了元素的时候,依次探查 (h(k)+i) mod S,i=1,3…… ,直到找到空的存储单元为止(或者从头到尾扫描一圈仍未发现空单元,这就是哈希表已经满了,发生了错误。当然这是可以通过扩大数组范围避免的)。
举例
哈希表支持的运算主要有:初始化(makenull)、哈希函数值的运算(h(x))、插入元素(insert)、查找元素(member)。 设插入的元素的关键字为 x ,A 为存储的数组。
伪代码
初始化:
const empty=maxlongint; // 用非常大的整数代表这个位置没有存储元素 p=9997; 表的大小 procedure makenull; var i:integer; begin for i:=0 to p-1 do A[i]:=empty; End;
哈希函数值的运算根据函数的不同而变化,例如除余法的一个例子:
function h(x:longint):Integer; begin h:= x mod p; end;
我们注意到,插入和查找首先都需要对这个元素定位,即如果这个元素若存在,它应该存储在什么位置,因此加入一个定位的函数 locate:
function locate(x:longint):integer; orig,i:integer; begin orig:=h(x); i:=0; while (i<S)and(A[(orig+i)mod S]<>x)and(A[(orig+i)mod S]<>empty) inc(i); 当这个循环停下来时,要么找到一个空的存储单元,要么找到这个元 素存储的单元,要么表已经满了 locate:=(orig+i) mod S; end;
插入元素 :
procedure insert(x:longint); posi:integer; begin posi:=locate(x); 定位函数的返回值 if A[posi]=empty then A[posi]:=x else error; error 即为发生了错误,当然这是可以避免的 end;
查找元素是否已经在表中:
procedure member(x:longint):boolean; posi:integer; begin posi:=locate(x); if A[posi]=x then member:=true else member:=false; end;
当数据规模接近哈希表上界或者下界的时候,哈希表完全不能够体现高效的特点,甚至还不如一般算法。但是如果规模在中央,它高效的特点可以充分体现。试验表明当元素充满哈希表的 90% 的时候,效率就已经开始明显下降。这就给了我们提示:如果确定使用哈希表,应该尽量使数组开大,但对最太大的数组进行操作也比较费时间,需要找到一个平衡点。通常使它的容量至少是题目最大需求的 120% ,效果比较好(这个仅仅是经验,没有严格证明)。
什么时候适合应用哈希表呢?如果发现解决这个问题时经常要询问:“某个元素是否在已知集合中?”,也就是需要高效的数据存储和查找,则使用哈希表是最好不过的了!那么,在应用哈希表的过程中,值得注意的是什么呢?
哈希函数的设计很重要。一个不好的哈希函数,就是指造成很多冲突的情况,从前面的例子已经可以看出来,解决冲突会浪费掉大量时间,因此我们的目标 就是尽力避免冲突。前面提到,在使用“除余法”的时候,h(k)=k mod p ,p 最好是一个大素数。这就是为了尽力避免冲突。为什么呢?假设 p=1000 ,则哈希函数分类的标准实际上就变成了按照末三位数分类,这样最多1000类,冲突会很多。一般地说,如果 p 的约数越多,那么冲突的几率就越大。
简单的证明:假设 p 是一个有较多约数的数,同时在数据中存在 q 满足 gcd(p,q)=d >1 ,即有 p=a*d,q=b*d,则有 q mod p= q – p* [q div p] =q – p*[b div a] . ① 其中 [b div a ] 的取值范围是不会超过 [0,b] 的正整数。也就是说, [b div a] 的值只有 b+1 种可能,而 p 是一个预先确定的数。因此 ① 式的值就只有 b+1 种可能了。这样,虽然mod 运算之后的余数仍然在 [0,p-1] 内,但是它的取值仅限于 ① 可能取到的那些值。也就是说余数的分布变得不均匀了。容易看出, p 的约数越多,发生这种余数分布不均匀的情况就越频繁,冲突的几率越高。而素数的约数是最少的,因此我们选用大素数。记住“素数是我们的得力助手”。
另一方面,一味的追求低冲突率也不好。理论上,是可以设计出一个几乎完美,几乎没有冲突的函数的。然而,这样做显然不值得,因为这样的函数设计 很浪费时间而且编码一定很复杂,与其花费这么大的精力去设计函数,还不如用一个虽然冲突多一些但是编码简单的函数。因此,函数还需要易于编码,即易于实 现。综上所述,设计一个好的哈希函数是很关键的。而“好”的标准,就是较低的冲突率和易于实现。另外,使用哈希表并不是记住了前面的基本操作就能以不变应万变的。有的时候,需要按照题目的要求对哈希表的结构作一些改进。往往一些简单的改进就可以带来巨大的方便。
这些只是一般原则,真正遇到试题的时候实际情况千变万化,需要具体问题具体分析才行。
当然,以上讲解的都是闭散列,如果使用链表,做开散列的话就可以更方便存储和删除了。其实这个和之前做18-600的malloc里面说的东西很类似。
拉链法
上面的方法使用数组实现的,其实很多时候需要使用数组链表来做。开一个数组,数组每个元素都是一个链表。(hash函数选择,针对字符串,整数,排列,具体相应的hash方法。 碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。)
使用除法散列:
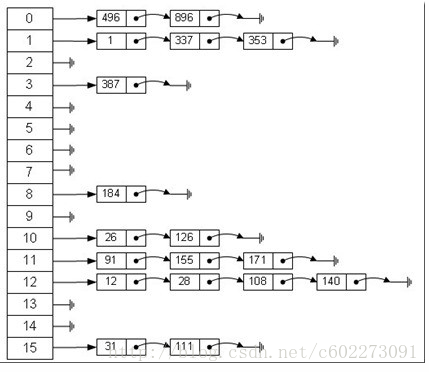
使用斐波那契散列:
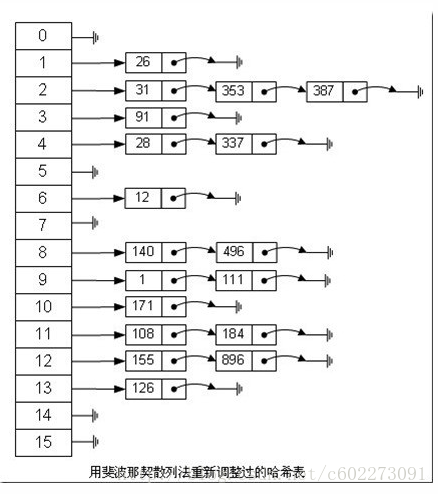
使用扩展法:
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
hash索引跟B树索引的区别。
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
(1)Hash 索引仅仅能满足”=”,”IN”和”<=>”查询,不能使用范围查询。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
(2)Hash 索引无法被用来避免数据的排序操作。
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
(3)Hash 索引不能利用部分索引键查询。
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
(4)Hash 索引在任何时候都不能避免表扫描。
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
(5)Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
实现
问题描述:设计哈希表实现电话号码查询系统,实现下列功能:
(1) 假定每个记录有下列数据项:电话号码、用户名、地址。
(2) 一是从数据文件old.txt(自己现行建好)中读入各项记录,二是由系统随机产生各记录,并且把记录保存到new.txt文件中以及显示到屏幕上,记录条数不要少于30,然后分别以电话号码和用户名为关键字建立哈希表。
(3) 分别采用伪随机探测再散列法和再哈希法解决冲突。
(4) 查找并显示给定电话号码的记录;查找并显示给定用户名的记录。
(5) 将没有查找的结果保存到结果文件Out.txt中,显示查找结果前,要有提示语句。
MyHashTable.cpp : 定义控制台应用程序的入口点。 ////设计哈希表实现电话号码查询系统 说明:一是从文件old.txt中读取的数据自己在程序运行前建立, 二是由系统随机生成数据,在程序运行由随机数产生器生成,并且将产生的记录保存到 new.txt文件。 存在的问题:使用随机产生的文件,在显示时出现乱码 #include "stdafx.h" #include<fstream>文件流 #include<iostream> #include <string> using namespace std; const int D[] = {3,5,1)">8,1)">11,1)">13,1)">14,1)">19,1)">21};预定再随机数 int HASH_MAXSIZE = 50;哈希表长度 记录信息类型 class DataInfo { public: DataInfo();默认构造函数 friend ostream& operator<<(ostream& out,const DataInfo& dataInfo); 重载输出操作符 friend class HashTable; private: string name;姓名 string phone;电话号码 string address;地址 char sign;冲突的标志位,'1'表示冲突,'0'表示无冲突 }; DataInfo::DataInfo():name(""),phone('0') { } ostream& const DataInfo& dataInfo) 重载输出操作符 { cout << 姓名:" << dataInfo.name << 电话:" << dataInfo.phone << 地址:" << dataInfo.address << endl; return out; } 存放记录的哈希表类型 HashTable { : HashTable();默认构造函数 ~HashTable();析构函数 int Random(int key,1)">int i); 伪随机数探测再散列法处理冲突 void Hashname(DataInfo *dataInfo);以名字为关键字建立哈希表 int Rehash(string str); 再哈希法处理冲突 注意处理冲突还有链地址法等 void Hashphone(DataInfo *dataInfo);以电话为关键字建立哈希表 void Hash(char *fname,1)">int n); 建立哈希表 fname 是数据储存的文件的名称,用于输入数据,n是用户选择的查找方式 int Findname(string name); 根据姓名查找哈希表中的记录对应的关键码 int Findphone(string phone); 根据电话查找哈希表中的记录对应的关键码 void Outhash(int key); 输出哈希表中关键字码对应的一条记录 void Outfile(string name,1)"> 在没有找到时输出未找到的记录 void Rafile(); 随机生成文件,并将文件保存在 new.txt文档中 void WriteToOldTxt();在运行前先写入数据 private: DataInfo *value[HASH_MAXSIZE]; int length;哈希表长度 }; HashTable::HashTable():length(0)默认构造函数 { memset(value,NULL,HASH_MAXSIZE*sizeof(DataInfo*)); for (int i=0; i<HASH_MAXSIZE; i++) { value[i] = new DataInfo(); } } HashTable::~HashTable()析构函数 { delete[] *value; } void HashTable::WriteToOldTxt() { ofstream openfile(old.txt); if (openfile.fail()) { cout << 文件打开错误! endl; exit(1); } string oldname; oldphone; oldaddress; 0; i<30; i++) { cout << 请输入第" << i+1 << 条记录: endl; cin >> oldname ; cin >> oldphone; cin >> oldaddress; openfile << oldname << " " << oldphone << " << oldaddress << , endl; } openfile.close(); } int HashTable::Random(int i) 伪随机数探测再散列法处理冲突 {key是冲突时的哈希表关键码,i是冲突的次数,N是哈希表长度 成功处理冲突返回新的关键码,未进行冲突处理则返回-1 int h; if(value[key]->sign == 1')有冲突 { h = (key + D[i]) % HASH_MAXSIZE; return h; } return -void HashTable::Hashname(DataInfo *dataInfo)以名字为关键字建立哈希表 {利用除留取余法建立以名字为关键字建立的哈希函数,在发生冲突时调用Random函数处理冲突 int i = ; int key = ; int t=0; dataInfo->name[t]!=\0'; t++) { key = key + dataInfo->name[t]; } key = key % 42; while(value[key]->sign == { key = Random(key,i++);处理冲突 } if(key == -1) exit(1);无冲突 length++;当前数据个数加 value[key]->name = dataInfo->name; value[key]->address = dataInfo->address; value[key]->phone = dataInfo->phone; value[key]->sign = ';表示该位置有值 cout << value[key]->name << " " << value[key]->phone << " " << value[key]->address << endl; } int HashTable::Rehash(string str) 再哈希法处理冲突 {再哈希时使用的是折叠法建立哈希函数 int num1 = (str[0] - ') * 1000 + (str[1] - 100 + (str[2] - 10 + (str[3] - int num2 = (str[4] - 5] - 6] - 7] - int num3 = (str[8] - 100 + (str[9] - 10 + (str[10] - ); h = num1 + num2 + num3; h = (h + key) % HASH_MAXSIZE; h; } void HashTable::Hashphone(DataInfo *dataInfo)以电话为关键字建立哈希表 {利用除留取余法建立以电话为关键字建立的哈希函数,在发生冲突时调用Rehash函数处理冲突 ; t; for(t=0; dataInfo->phone[t] != ) { key = key + dataInfo->phone[t]; } key = key % { key = Rehash(key,dataInfo->phone); } length++;phone; value[key]->sign = 表示该位置有值 void HashTable::Outfile(int key)在没有找到时输出未找到的记录 { ofstream fout; if((key == -1)||(value[key]->sign == '))判断哈希表中没有记录 { fout.open(out.txt",ios::app);打开文件 (fout.fail()) { cout << 文件打开失败! endl; exit(); } fout << name << endl;将名字写入文件,有个问题,每次写入的时候总是将原来的内容替换了 fout.close(); } } void HashTable::Outhash(输出哈希表中关键字码对应的记录 { if((key==-1)||(value[key]->sign==)) cout << 没有找到这条记录!else { for(unsigned 0; value[key]->name[i]!='; i++) { cout << value[key]->name[i]; } 10; i++) { cout << " ; } cout << value[key]->phone; for(; } cout << value[key]->address << endl; } } void HashTable::Rafile()随机生成文件,并将文件保存在new.txt文档中 { ofstream fout; fout.open(new.txt");打开文件,等待写入 (fout.fail()) { cout << 文件打开失败!); } int j=0; j<30; j++) { string name = ""; 20; i++)随机生成长个字的名字 { name += rand() % 26 + a名字是由个字母组成 } fout << name << " ";将名字写入文件 string phone = 11; i++)随机生成长位的电话号码 { phone += rand() % 10 + 电话号码是纯数字 } fout << phone << " 将电话号码写入文件 string address = 29; i++) { address += rand() % 地址是由个字母组成 } address += ; fout << address << endl;将地址写入文件 } fout.close(); } void HashTable::Hash(int n)建立哈希表 fname是数据储存的文件的名称,用于输入数据,n是用户选择的查找方式 函数输入数据,并根据选择调用Hashname或Hashphone函数进行哈希表的建立 { ifstream fin; i; fin.open(fname);读文件流对象 (fin.fail()) { cout << while(!fin.eof())按行读入数据 { DataInfo *dataInfo = DataInfo(); char* str = new char[100]; fin.getline(str,1)">100,1)">\n');读取一行数据 if(str[0] == *判断数据结束 { break; } i = 0;记录字符串数组的下标 a-z:97-122 A-Z:65-90 本程序的姓名和地址都使用小写字母 while((str[i] < 97) || (str[i] > 122))读入名字 { i++; } for(; str[i]!=' ) { dataInfo->name += str[i]; } while(str[i] == ) { i++0; str[i]!='; j++,i++)读入电话号码 { dataInfo->phone += str[i]; } 读入地址 { dataInfo->address +=if(n == ) { Hashname(dataInfo); } { Hashphone(dataInfo);以电话为关键字 } delete []str; delete dataInfo; } fin.close(); } int HashTable::Findname(string name)根据姓名查找哈希表中的记录对应的关键码 int j = t; ; for(key=0,t=0; name[t] != ) { key = key + name[t]; } key = key % while((value[key]->sign == ') && (value[key]->name != name)) { key = Random(key,i++); j++if(j >= length) ; } key; } int HashTable::Findphone(string phone)根据电话查找哈希表中的记录对应的关键码 0; phone[t] != ' ; t++) { key = key + phone[t]; } key = key % ') && (value[key]->phone != phone)) { key = Rehash(key,phone); j++if(j >= length) { ; } } main() { WriteToOldTxt(); k; ch; char *Fname; HashTable *ht = HashTable; while() { system(clscls命令清除屏幕上所有的文字 cout << 欢迎使用本系统!" << endl << endl; cout << 请选择数据1.使用已有数据文件2.随机生成数据文件0.结束输入相应序号选择功能:; cin >> k; switch(k) { case : : Fname = 从数据文件old.txt(自己现行建好)中读入各项记录 2: ht->Rafile(); Fname = 由系统随机产生各记录,并且把记录保存到new.txt文件中 default: cout << 输入序号有误,退出程序。 endl; { system(); cout << 请选择查找方式 endl; cout << 1.通过姓名查找2.通过电话查找; cin >> ch; if((ch != 1) && (ch != )) cout << 输入序号有误! endl; }while((ch != )); ht->Hash(Fname,ch); while(ch == ) { choice; cout << endl << 请选择功能1.输入姓名查找数据2.显示哈希表0.退出"<<endl; cout << choice; (choice) { : {注意此处应该加上大括号 key1; name; cout << 请输入姓名:; cin >> name; key1 = ht->Findname(name); ht->Outfile(name,key1); ht->Outhash(key1); } ; : { ) { if(ht->value[i]->sign!=) { ht->Outhash(i); } } } ; : cout << endl << 您的输入有误! endl; } if(choice == ) { ; } } 1.输入电话查找数据 key2; phone; cout << 请输入11位的电话号码:; { cin >> phone; if(phone.length() != 11) { cout << 电话号码应为11位!\n请重新输入:; } }while(phone.length() != ); key2 = ht->Findphone(phone); ht->Outfile(phone,key2); ht->Outhash(key2); } if(ht->value[i]->sign != ) { ht->Outhash(i); } } } : cout << endl << )) { cout << 您的输入有误!请输入相应需要选择功能:; } } system(pause); }
代码实现来源:
http:blog.csdn.net/htyurencaotang/article/details/7881427
原理说明来源:
http:www.tuicool.com/articles/BvI3Ir http:blog.csdn.net/nju_yaho/article/details/7402208 http:blog.csdn.net/duan19920101/article/details/51579136 http:blog.sina.com.cn/s/blog_6776884e0100pko1.html http:blog.csdn.net/v_july_v/article/details/6256463
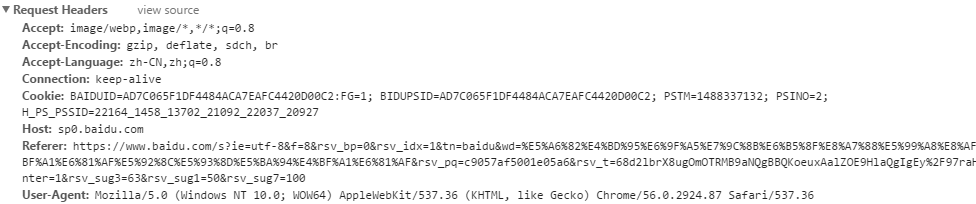 每个HTTP请求和响应都会带有相应的头部信息。默认情况下,在...
每个HTTP请求和响应都会带有相应的头部信息。默认情况下,在...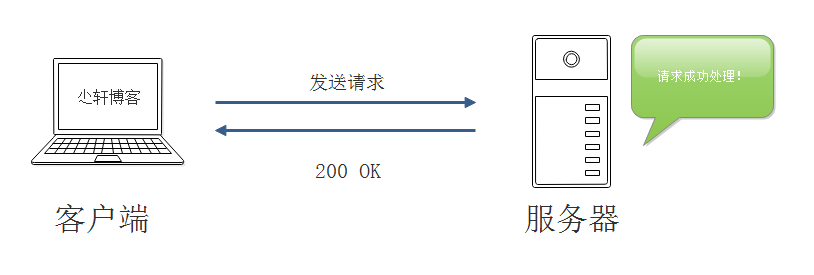 当我们从客户端向服务器发送请求时 服务器向我们返...
当我们从客户端向服务器发送请求时 服务器向我们返...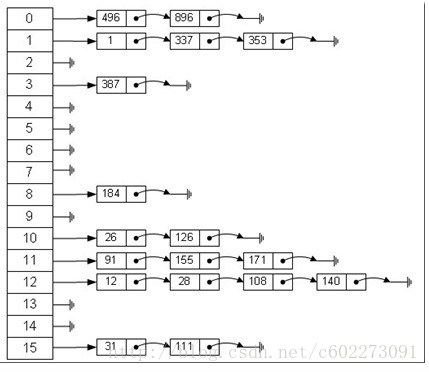 原理 介绍 哈希表(Hash table,也叫散列表), 是根据关键码...
原理 介绍 哈希表(Hash table,也叫散列表), 是根据关键码...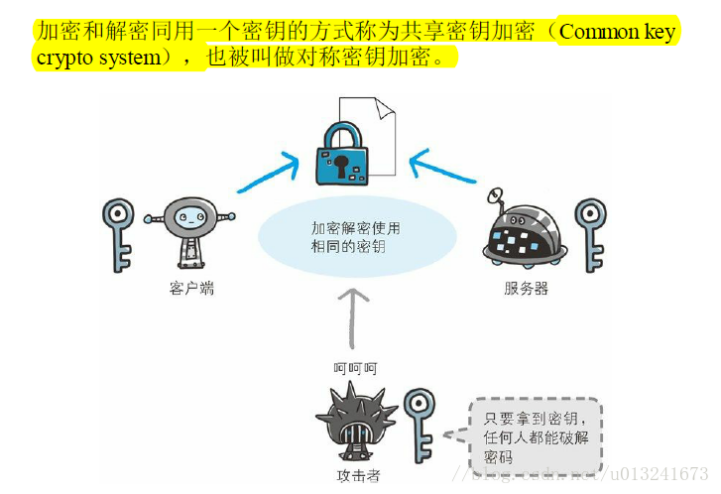 一 共享秘钥 1.1 概念 共享秘钥和我们生活中同一把锁的钥匙概...
一 共享秘钥 1.1 概念 共享秘钥和我们生活中同一把锁的钥匙概...