Redis支持string、list、set、zset、hash等数据类型,这一篇学习redis的数据类型、命令及某些使用场景。
一、String,字符串
字符串是 Redis 最基本的数据类型。一个字符串最大为 512M 字节。字符串数据类型适用于很多场景,例如,缓存 HTML 片段或者页面。
Redis 字符串是二进制安全的,也就是说,一个 Redis 字符串可以包含任意类型的数据,例如一张 JPEG 图像,或者一个序列化的对象。
我们可以把字符串当做位数组(位图)来处理,很容易统计一些基于0/1逻辑的业务;
使用 INCR 命令族 (INCR,DECR,INCRBY),将字符串作为原子计数器;
使用 APPEND 命令追加字符串等等。
1、set key value [ex 秒数]/[px 毫秒数] [nx]/[xx]
set name tom,永久有效。
set name tom ex 60,60秒后过期。
set name tom px 6000,6000毫秒(6秒)后过期。
ex、px 不能同时写,否则以后面一个时间为准。
如set name tom ex 60 px 6000,实际上6秒后就过期了。
nx表示key不存在时执行操作,xx表示key存在时执行操作。

2、setnx key value:key不存在时设置value

3、get key:获取key的值

4、mset k1 v1 k2 v2 ... kn vn:multi set 一次性设置多个键值
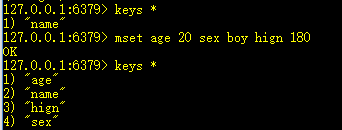
5、msetnx k1 v1 k2 v2 ... kn vn:设置多个键值,当键不存在时才设置
只要有一个存在就都不会被设置。

6、mget k1 k2 .. kn:获取多个key的值

7、setrange key offset value:将key对应的值,偏移offset位置的字符替换为value。
返回新字符串的长度。
偏移量的下标以0开始,value有多少个长度,则替换多少个长度的字符。
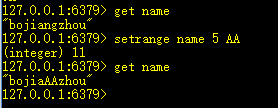
如果offset超出字符串的长度,则以空白的部分以0x00填充。

8、getrange key start end:获取字符串中[start,end]范围的值
字符串下标左数从0开始,右数从-1开始。
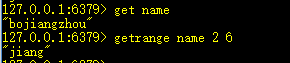
获取左边第二个(1)到右边第一个(-2)的值。
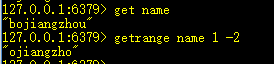
start >= length,返回空字符串。end >= length,截取至字符结尾。
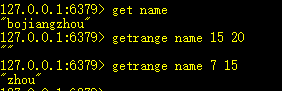
9、getset key newvalue:获取原值,并设置新值

10、append key value:把value追加到key的原值上

11、strlen key:获取key值的长度
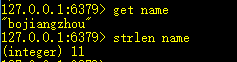
12、incr/decr key:指定key的值加1或减1,返回加1或减1后的值
incr/decr 命令将字符串值解析为整数,可作为原子计数器。incr 命令是原子的,因为即使多个客户端对同一个键发送 incr 命令也不会造成竞争条件,读 - 加/减 - 写操作在执行时,其他客户端此时不会执行相关命令。
incr/decr通常可用于计数、抢单的场合,例如有2000张火车票,同时有10万人抢2000张火车票,可能一分钟内就抢完了。如果同时去数据库查询剩余票数或下订单,数据库压力很大。
此时可在redis中设置一个票数的缓存,抢票的人先抢到下订单的资格,后台再慢慢去下订单更新数据库。获得资格后,自动减一,并返回了剩余票数。剩余票数为0,就可过滤掉绝大部分请求了。

如果key不存在,则默认key为0,再执行加减的操作。

13、incrby/decrby key num:指定的key值加或减num,返回加num或减num后的值
num为整数。

14、incrbyfloat key float:key值加float,float为浮点数
如果要减少,float为负数即可。

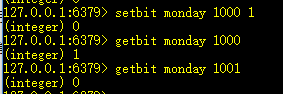
15、setbit key offset value:设置key值的二进制位上offset对应的值
例如,我要将大写的字母变为小写的字母,大写字母和小写字母相差32,差异就是大写字母二进制位偏移量2的位置为0,小写字母为1,。

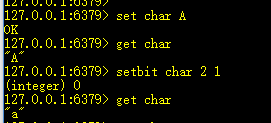
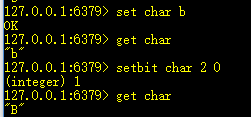
经典的应用就是使用位图法统计活跃用户,例如统计连续一周登录用户。
如果有1亿用户,登录日志存储在数据库表中,表急剧增大,直接在数据库中统计,计算较慢。
那么使用位图法就能轻松解决这个问题,每天按日期生成一个位图(位数组),用户是否登录就用1/0标识,用户登录后,把user_id位上的值置为1,标识该用户已登录。把一周的位图做and运算,位上为1的就是连续登录的用户。
一个位图算1亿个位,100000000/8/1024/1024 ≈ 12M,也就是说每天只需要12M就能存储1亿用户是否登录的情况,节约空间,计算方便。
ID为100000000的用户,设置周一、周二、周三连续登录,最后做AND操作,得出该用户连续登录:

ID为5000的用户,周一登录,周二不登录,周三登录(可以不设置,默认填充0),做AND操作,得出未连续登录:
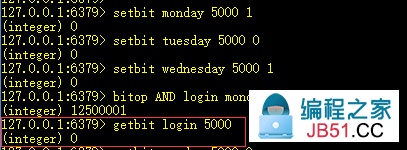
16、getbit key offset:获取key值的二进制位上offset对应的值
17、bitop operation destkey key1 key2 ... keyn:对key1、key2 ... keyn做operation操作,并将结果保存到destkey上
operation 可以是AND、OR、NOT、XOR
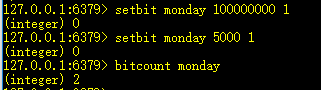
18、bitcount key:返回被置为1的位的数量
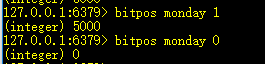
19、bitops key 1/0:返回第一个被置为1/0的位
二、List,链表
Redis列表是简单的字符串列表,排序为插入的顺序。列表的最大长度为2^32 - 1 。
Redis 的列表是使用链表实现的。这意味着,即使你的列表中有上百万个元素,增加一个元素到列表的头部或者尾部的操作都是在常量时间完成。Redis 采用链表来实现列表是因为,对于数据库系统来说,快速插入一个元素到一个很长的列表非常重要。
我们可以用列表获取最新的内容(像帖子、微博等),用ltrim很容易就获取最新的内容,并移除旧的内容。
用列表可以实现生产者消费者模式,生产者调用 lpush 添加项到列表中,消费者调用 rpop 从列表提取,如果没有元素,则轮询去获取,或者使用brpop等待生产者添加项到列表中。
1、lpush key value:把值插入链表头部
插入成功,返回列表的个数。可以同时插入多个值。
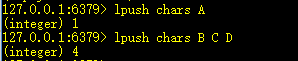
lpushx key value:当key存在是才插入数据

2、lrange key start end:返回链表中[start,end]中的元素
左数从0开始,右数从-1开始。所以想取出全部元素可以用lrange key 0 -1。

3、rpush key value:把值插入链表的尾部
rpushx key value:当key存在是才插入数据。

4、lpop key:返回并删除链表头元素

5、rpop key:返回并删除链表尾部元素

6、lrem key count value:从链表中删除value值
删除count绝对值个value,count>0,从头部开始删除;count<0,从尾部开始删除。
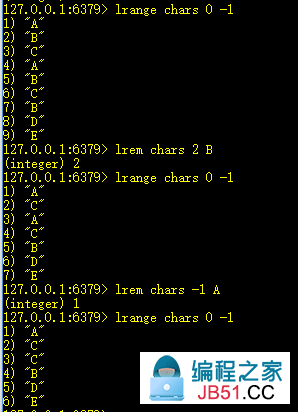
7、ltrim key start end:截取[start,end]的列表并重新赋给key
有些时候我们只想用列表存储最近的项,我们可以使用ltrim命令仅仅只记住最近的10项,而丢弃所有老的项。可以很容易实现新增一个元素而抛弃超出的元素。


8、lindex key index:返回列表索引index上的值

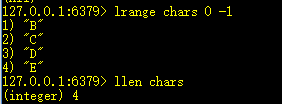
9、llen key:返回列表的个数
10、linsert key after|before search value:在列表中查找search,在search之后|之前插入value
只会在第一个匹配的search之后|之前插入,不会插入多个value。
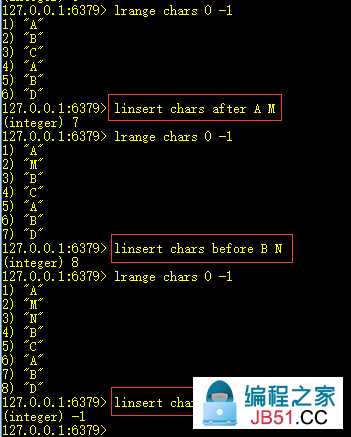
11、lset key index value:设置列表index位置的元素为value

12、brpop/blpop key timeout:等待弹出key的尾部/头部元素
如果有元素则直接弹出,没有则阻塞,timeout为等待超时时间,如果timeout为0,则一直等待。
一般可用于轮询,在线聊天,例如有一个message列表,在获取消息的时候,没有就等待,有就弹出。
使用一个终端来等待消息:
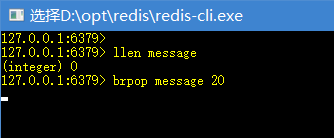
另一个终端插入消息:
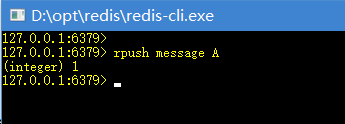
消息被弹出:

等待超时:

13、rpoplpush source dest:把source的尾部拿出来放到dest的头部
使用rpoplpush相比分开rpop,lpush两步操作是原子性的,使用 rpoplpush 可以构建更安全的队列和旋转队列。
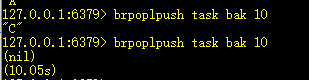
rpoplpush一般可用于构建安全任务队列,比如有一个任务队列task,每次从中取出一个任务来执行,放到另一个列表bak来备份。这样任务如果执行成功,从bak列表中移除该任务;失败,可以再拿回task列表。

14、brpoplpush source dest timout:等待弹出,放到dest中
结合了brpop喝rpoplpush的特性,有则弹出放到另一个列表,没有则等待。
三、Set,集合
Redis 集合是无序的字符串集合,集合中的值是唯一的、无序的。可以对集合执行很多操作,例如,测试元素是否存在,对多个集合执行交集、并集和差集,等等。
我们通常可以用集合存储一些无关顺序的,表达对象间关系的数据,例如用户的角色,可以用sismember很容易就判断用户是否拥有某个角色。
在一些用到随机值的场合是非常适合的,可以用 srandmember/spop 获取/弹出一个随机元素。
1、sadd key val1 val2 ... valn:向集合中添加元素
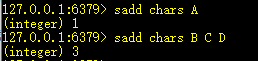
2、srandmember key:随机或一个元素
在string和list的命令中,可以通过range来获取某几个字符或某几个元素,但集合是无序的,无法通过下标或范围来访问部分元素,因此要么随机选一个,要么全选。
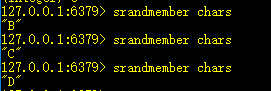
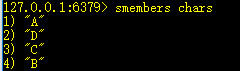
3、smembers key:返回列表的所有元素
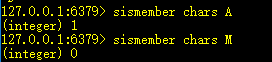
4、sismember key value:判断是否存在某个元素
存在则返回1,不存在则返回0
5、scard key:返回集合的个数

6、spop key:返回并删除其中一个随机元素

7、srem val1 val2 ... valn:删除元素

8、smove source dest value:将source集合中的value删除并移到dest中

9、sinter k1 k2 ... kn:求集合的交集

sinterstore dest k1 k2 ... kn:求集合的交集,并将结果赋给dest

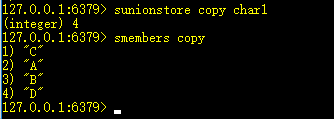
11、sunion k1 k2 ... kn:求集合的并集

同理,sunionstore则将并集的结果赋给dest。

可以用sunionstore复制一个集合
12、sdiff k1 k2 ... kn:求集合的差集
即k1-k2-kn

四、Sorted Set,有序集合
有序集合由唯一的,不重复的字符串元素组成。有序集合中的每个元素都关联了一个浮点值,称为分数。可以把有序看成hash和集合的混合体,分数即为hash的key。
有序集合中的元素是按序存储的,不是请求时才排序的。
1、zadd key score1 value1 score2 value2 ... scoren valuen:添加元素
score为分数,他们按照如下规则排序:
- 如果 A 和 B 是拥有不同分数的元素,A.score > B.score,则 A > B。
- 如果 A 和 B 是有相同的分数的元素,如果按字典顺序 A 大于 B,则 A > B。A 和 B 不能相同,因为排序集合只能有唯一元素。
向有序集合中添加元素,会自动排序且为升序

有序集合的分数可以重复,但值不能重复,元素是唯一的。
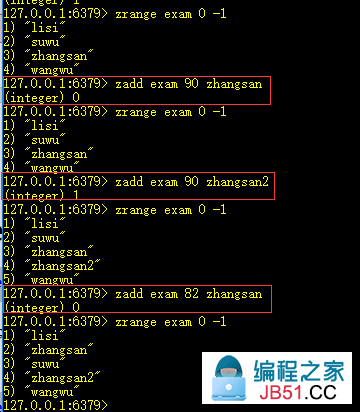
2、zrange key start end [withscores]:获取[start,end]的元素(升序)
withscores,是否显示排序分数。zrange默认返回升序序列。
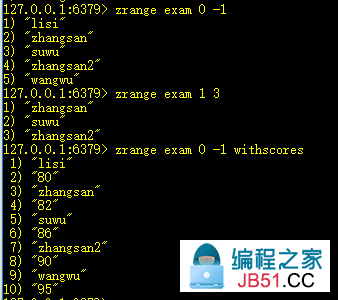
3、zrevrange key start end [withscores]:获取[start,end]的元素(降序)
与zrange获取的顺序相反。

4、zrank key member:查member的排名(升序)
返回的排名升序从下标0开始

5、zrevrank key member:查member的排名(降序)
返回的排名降序从下标0开始

6、zcard key:返回元素个数
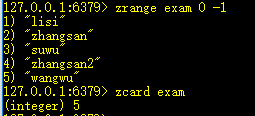
7、zcount key min max:返回分数[min,max]区间的元素个数
+inf表示正无穷,-inf表示负无穷。

8、zscore key member:获取元素的分数
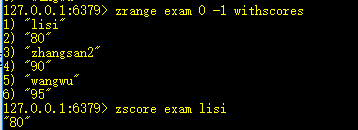
9、zrangebyscore key min max [withscores] [limit offset N]:获取[min,max]区间并偏移offset个,取出后N个元素(升序)
类似于分页查询,如果N超出个数,返回直到结尾。
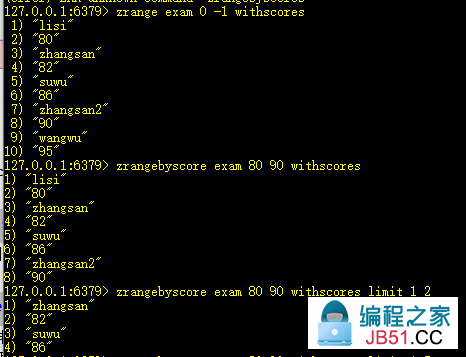
10、zrevrangebyscore key max min [withscores] [limit offset N]:获取[max,min]区间并偏移offset个,取出后N个元素(降序)
与zrangebyscore顺序相反,注意范围是[max,min]

11、zrem key value1 value2 ... valuen:删除元素
从这里也可以看出有序集合中的元素是唯一性的。

12、zremrangebyscore key min max:删除分数[min,max]范围的元素

13、zremrangebyrank key start end:删除排名[min,max]之间的元素
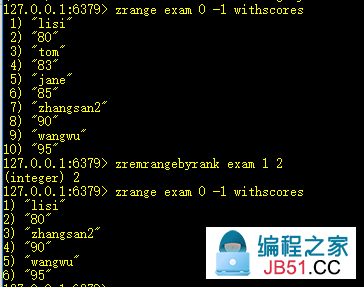
14、zinterstore dest numkeys key1 [key2 ... keyn] [weights weight1 [weight2 ... weightn]] [aggregate sum|min|max]
求key1、key2的交集,key1、key2的权重分别是weight1、weight2;numkeys指定key的个数。
聚合方法为sum|min|max,结果保存到dest中,默认交集求和。可以看做先做交集再做后面的运算。
同样,取并集用zunionstore,其余参数一样。
添加两组数据:

交集求和:


交集最大值:

交集加上权重取最大值:加上权重时:score = score * weight

五、Hash,哈希
Redis的哈希值是字符串字段和字符串值之间的映射,是表示对象的完美数据类型。
哈希中的字段数量没有限制,所以你可以在你的应用程序以不同的方式来使用哈希。
1、hset key field value:设置key中field的值
没有field则写入,有则覆盖

2、hsetnx key field value:当键不存在时才设置值
使用hsetnx就不会覆盖原值

3、hmset key field1 value1 ... fieldn valuen:设置多个键值

4、hget key field:获取key中field的值
5、hmget key field1 ... fieldn:获取多个值

6、hgetall key:获取key中所有的键值
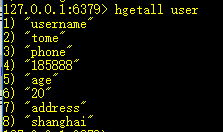
7、hdel key field:删除key中的field
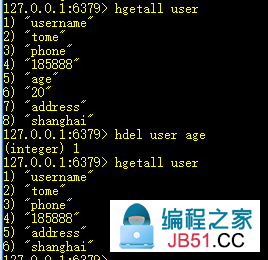
8、hlen key:返回key中的个数

9、hexists key field:判断是否存在某个key

10、hkeys key:返回所有的键

11、hvals key:返回所有的值

12、hincyby key field value:增加整数值
只能增加整数,不能增加小数。也可以增加负数。

13、hincrbyfloat key field value:增加小数

redis数据类型基本学完,下一篇学习事物、消息订阅等。
完!!!
 文章浏览阅读1.3k次。在 Redis 中,键(Keys)是非常重要的概...
文章浏览阅读1.3k次。在 Redis 中,键(Keys)是非常重要的概... 文章浏览阅读3.3k次,点赞44次,收藏88次。本篇是对单节点的...
文章浏览阅读3.3k次,点赞44次,收藏88次。本篇是对单节点的... 文章浏览阅读978次,点赞25次,收藏21次。在Centos上安装Red...
文章浏览阅读978次,点赞25次,收藏21次。在Centos上安装Red... 文章浏览阅读1.2k次,点赞21次,收藏22次。Docker-Compose部...
文章浏览阅读1.2k次,点赞21次,收藏22次。Docker-Compose部... 文章浏览阅读2.2k次,点赞59次,收藏38次。合理的JedisPool资...
文章浏览阅读2.2k次,点赞59次,收藏38次。合理的JedisPool资...