数据的操作无外乎就是对数据的增删改查
增加数据
基本方式:insert into 表名 [(字段列表)] values (值列表);
主键冲突:在插入数据的时候,主键值已经存在了,但是要求是必须使用该主键字段
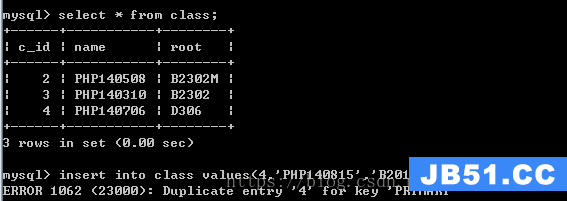
实现目标:如果该主键不存在那么就增加记录,如果存在,就修改部分字段的值
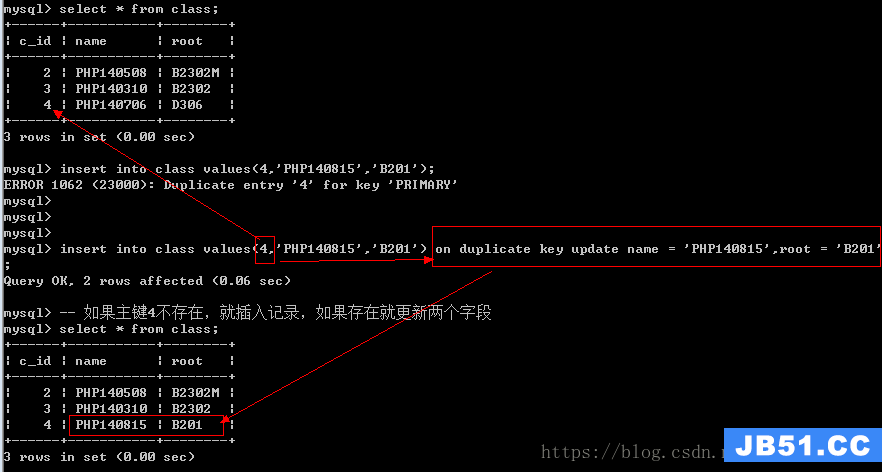
1.使用主键冲突方式
语法:insert into 表名 values(值列表) on duplicate key update 字段 = 值
2.使用替换插入
replace into 表名 (字段列表) values(值列表)
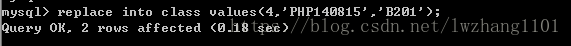
replace其实先删除存在的行,再进行插入。
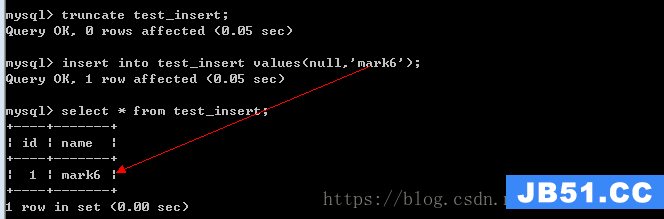
注意:大部分情况下,因为是使用逻辑主键,一般会自增长,所以使用null即可(insert),但是如果是使用业务主键,那么很有可能会存在冲突(replace)。
蠕虫复制
蠕虫能够一分为2,2分为4,在成倍增长
语法:insert into 表名 (字段列表) select 字段列表 from 表名;

蠕虫复制能够快速使用表中的数据量增加,没有办法改变数据
蠕虫复制也可以从其他的表中去获取数据。
更新数据
基本语法:update 表名 set 字段 = 值 [where条件]
高级语法:update 表名 set 字段 = 值 [where条件] [limit]

删除数据
基本语法:delete from 表名 [where条件]
高级语法:delete from 表名 [where条件] [limit]

删除数据并不能修改一张表的索引和自增长。如果想删除表的自增长重新来过
先删除表(drop),再新建表(create)
mysql提供了简单方式实现两个步骤:truncate
查询数据
基础语法:select 字段列表 from 表名 [where条件]
高级语法:select [select选项] 表达式 [from子句] [where子句] [group by 子句] [having 子句] [order by子句] [limit 子句]
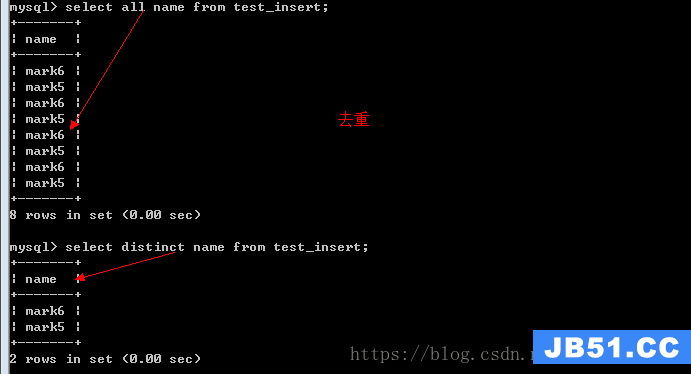
select选项:在查询得到数据是否需要进行合并,all表示获取所有数据(默认的),distinct将完全一致的记录进行合并

去重
from子句
用来指定数据源
普通:from 表名
高级:from 多表名;
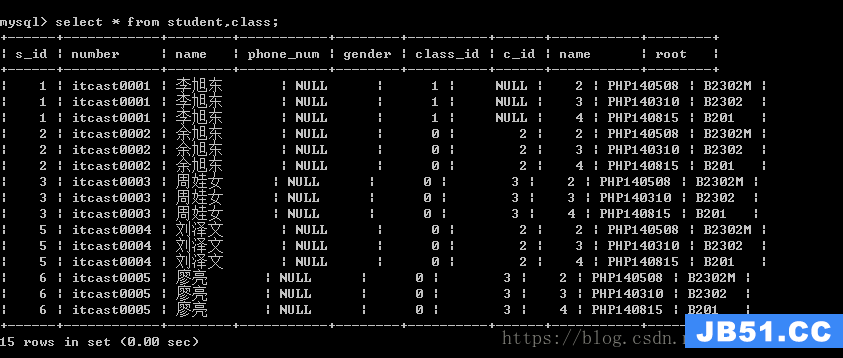
原理:拿着第一张表的记录去分别匹配第二张表的所有记录,将每次匹配的结果保存。
以上结果在数学上被称之为笛卡尔积。
在实际使用当中,笛卡尔积没有任何意义,所以要尽量避免出现笛卡尔积。
高级:from 表(不是真实存在的表,而是查询得到的结果–子查询)

别名
对某个数据源所起的简单的用来描述的名字
语法:数据源 [as] 别名
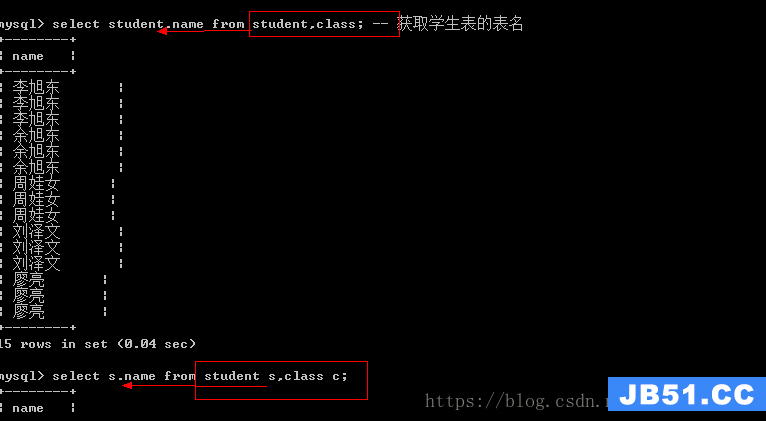
from后面如果跟的不是真实的表,那么必须使用别名来对数据源进行表述

where子句
依据条件筛选数据
where如何筛选时数据?通过运算符来进行数据筛选
运算符:
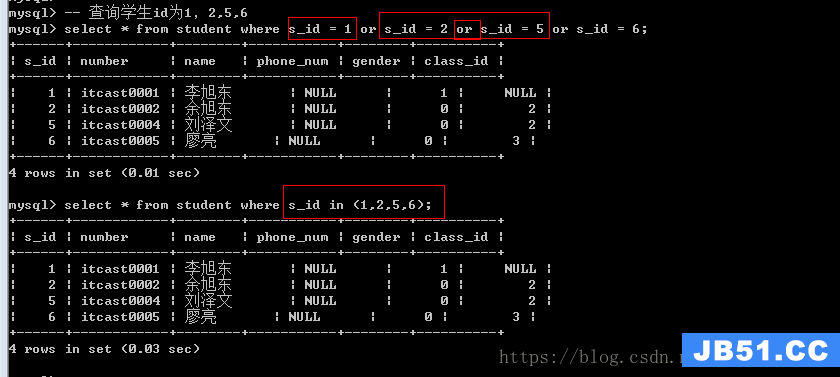
比较运算符:>,>=,<,<=,=(比较),!=,<>,in,between and,is [not]null
in:表示某个字段的值,在某个集合(包含多个数据)中
between and:语法是between A and B(A必须小于等于B),表示在某个区间内(闭区间)
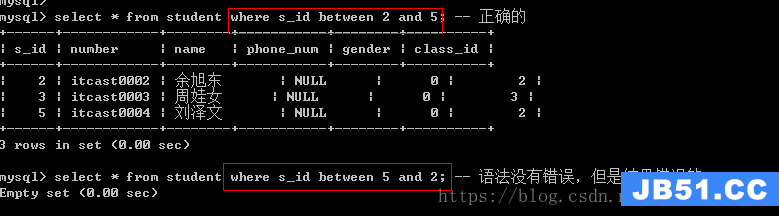
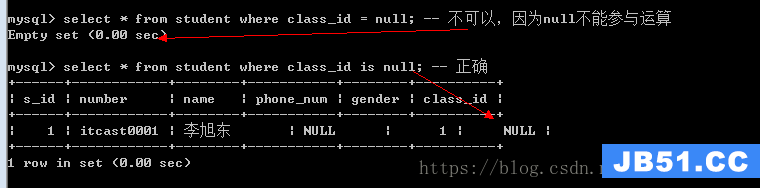
如果字段的值为null,那么该字段与任何值的运算的结果都是null

is null判断数据是否为null
逻辑运算符:&&and,||or,not
where后面得到的结果会被系统怎么处理?
结果会被系统当成布尔处理
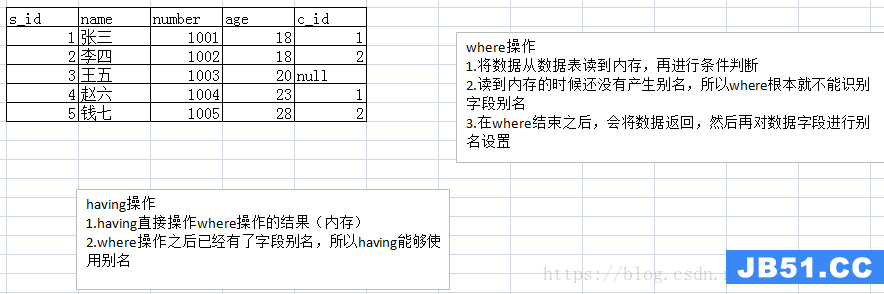
where工作原理

where是针对元数据进行操作,所有where之后的语句,都是针对数据结果进行操作,而不是针对数据表。
group by子句
分组统计
语法:group by 字段
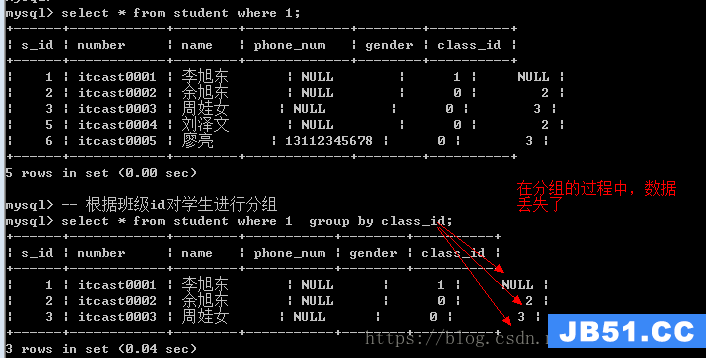
group by分组之后,会将数据进行合并,从而只象征性的保留每组的第一条记录。
通常group by**不是为了得到分组后的每组的全部数据,而是用来统计每组的信息。**
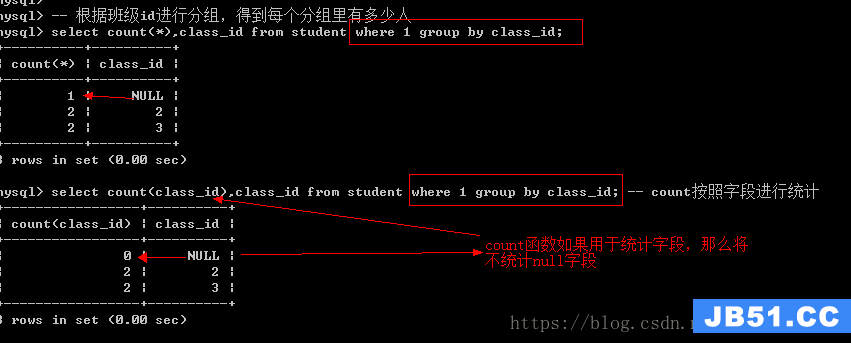
统计函数:都是数学统计
count:统计所有的记录的个数,也可以是所有字段(不统计null)
max:统计分组后每组里面的最大值,通常是某个字段
min:统计最小
avg:统计平均数
sum:求和
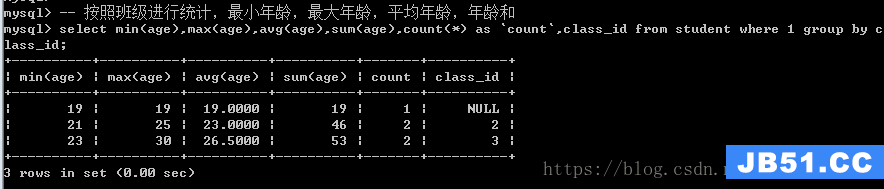
group by工作原理
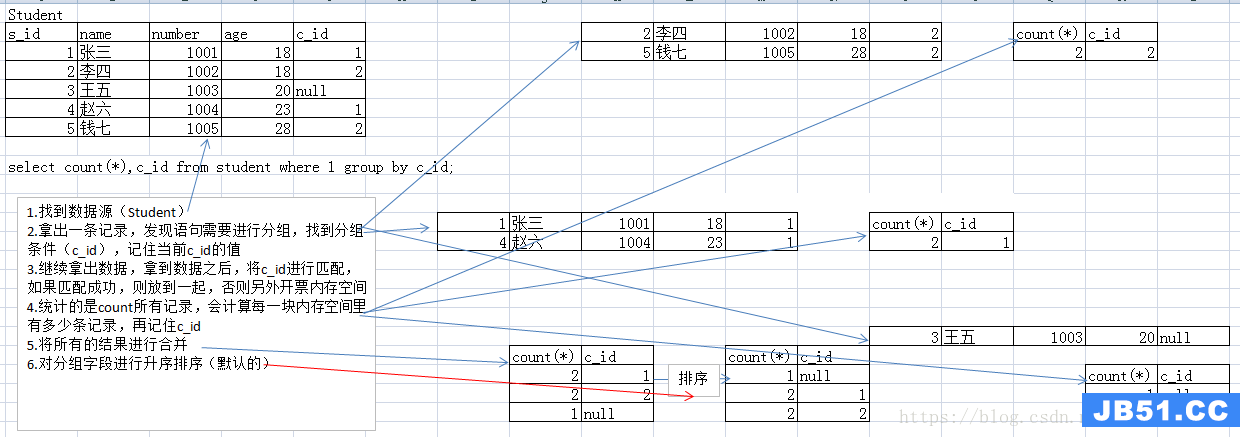
group by排序:能够直接排序
语法:group by 字段 [asc|desc]
根据分组字段进行排序

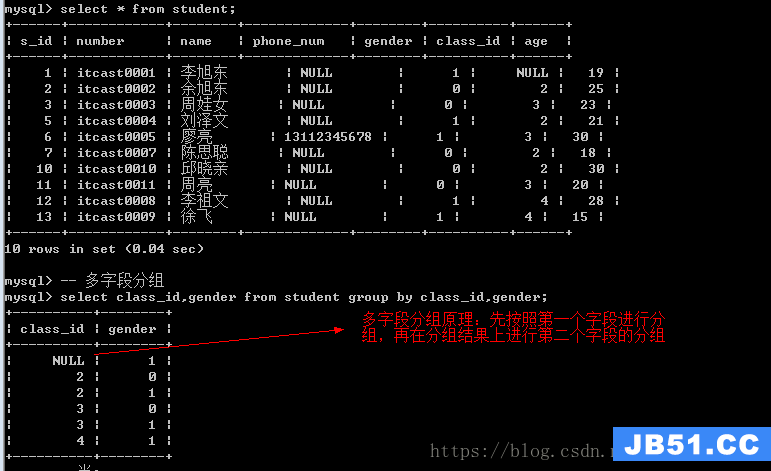
多字段分组:按照某个字段进行分组之后,将分组得到的数据再按照某个条件进行分组。
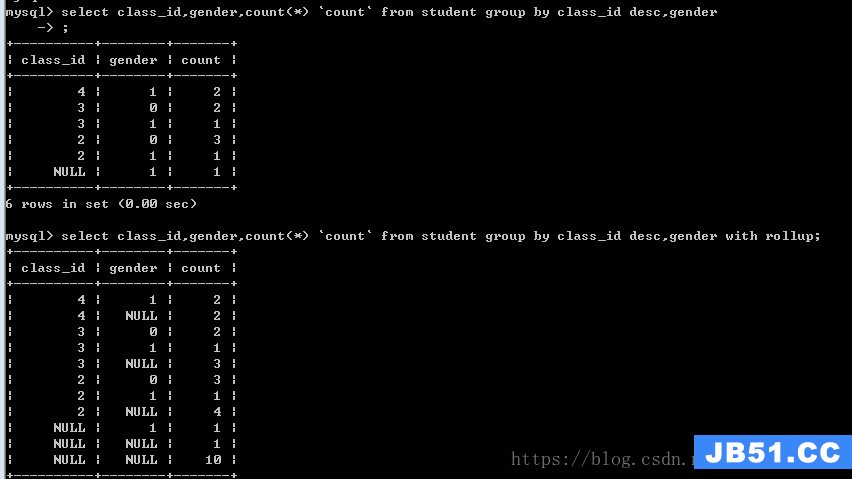
回溯统计:每一层分组之后,都会在最终的结果上,再进行一次额外的统计
语法:在分组之后增加 with rollup
having子句
having子句功能与where一样,用于做条件判断
where:对数据源进行条件处理
having:对where得到数据内存进行处理
相同点
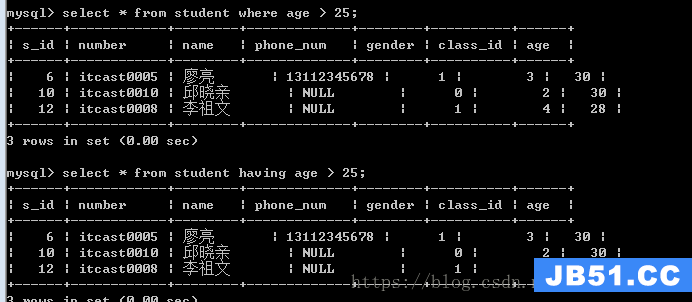
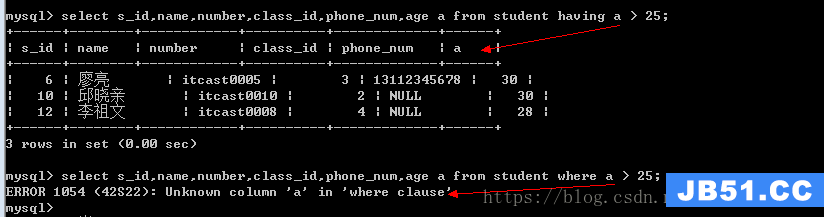
不同点:having可以使用字段别名,而where不能
原理
不同点:having可以使用统计函数

分组统计在数据操作的过程中经常使用,尤其是做一些报表开发。分组通常与分组函数一起使用。
order by子句
主要是对字段进行排序,有两种方式:asc默认的,desc降序排序,比较的依据是校对集。
limit子句
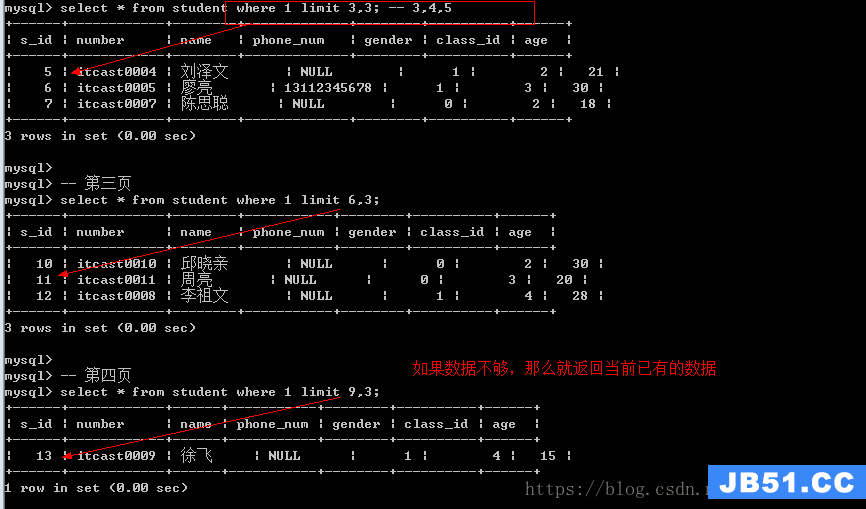
理解的是限制查找过程中返回数据的条数
实际:限制数据查询的起始位置和返回数据的条数
语法:limit offset,number
offset:从查询得到结果中的第几条开始,在数据库里,offset从0开始
number:一共返回多少记录(返回的记录数不一定完全等于number数量)
通常limit用于实现数据的分页。
需求:显示所有学生信息,每页只能显示20个数据,总共55个学生
第一页:最前面的20个——》20
第二页:21个到40—–》20
第三页:41到55—–》15
从from开始的6个子句,他们的顺序必须完全一致(如果子句都存在的情况下)
联合查询
将两个查询的结果,合并到一起,将记录数合并,而字段数不变
联合查询必须满足的条件
1.两个查询得到的字段数必须一致
语法:select语句 union [union选项] select语句
union选项:all和distinct(默认的)
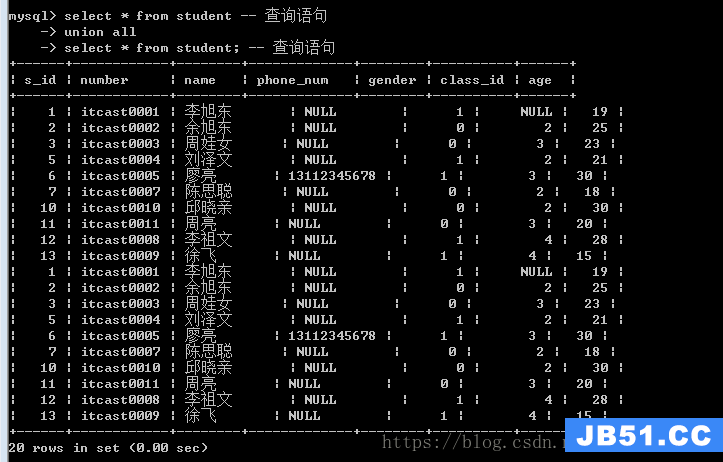
union刚需

union不管数据类型,只要字段数一致即可

所有的数据存储在磁盘上的时候是有数据类型的,但是一旦数据读入到内存里面,就都没有类型而言,全部都是字符串。
需求:查出2班的所有学生,按照年龄的升序排序;查出3班的所有学生,按照年龄降序排序
在union中使用order by必须对select语句进行括号处理

在union中使用order by必须配以limit才能生效
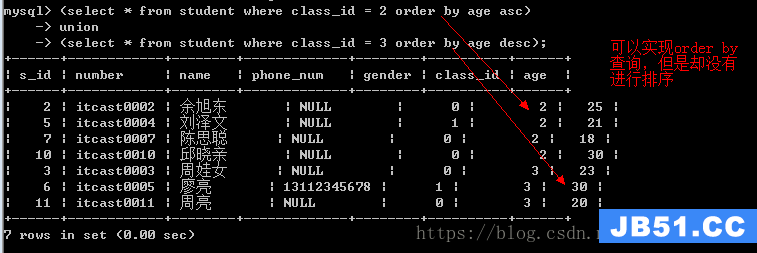
正确使用order by
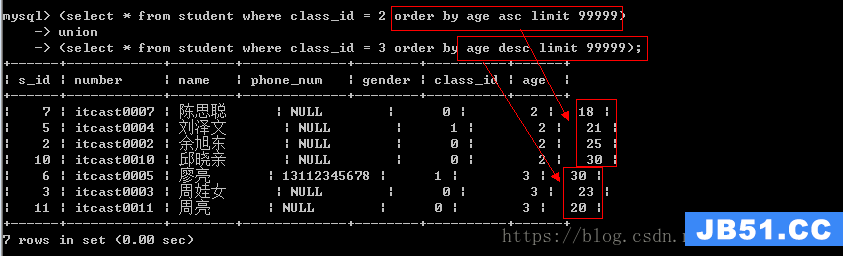
为何要使用union?
大数据处理,往往一个网站系统当数据量很大的时候,会进行数据的分表操作,将同样的数据存放在不同的表中,因为一张表的数据太大会影响数据查询的效率,增加维护的难度。所以,一般这样的数据的都是分表存放,但是在某些操作的时候,需要将所有的数据放到一起,这时会就使用联合查询。
连接查询
概念:将多个表中相关的数据记性字段上面的增加,从而使得最终的结果能够完全显示数据信息
连接查询根据查询结果以及条件的不一样可以分为几类:
1.内连接
2.外连接
3.自然连接
4.交叉连接
内连接
如果一张表的记录(有个字段记录另外一张表的主键),能够在另外一张表中匹配上,那么就保存,否则就不保存。
左表:join关键字左边的表称之为左表
右表:join关键字右边的表称之为右表
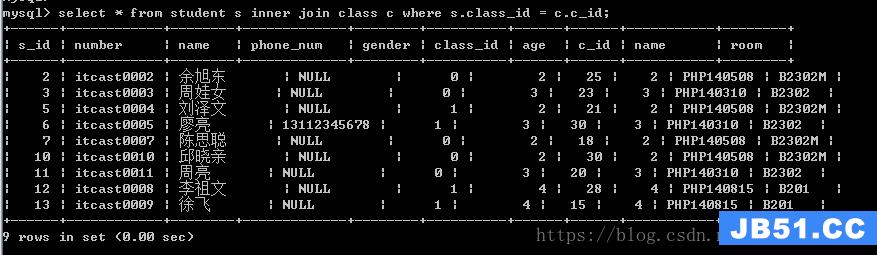
语法:左表 [inner] join 右表 on/where 连接条件
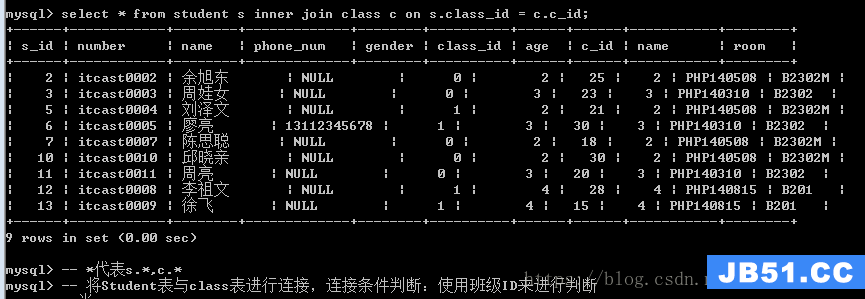
内连接原理:

内连接的on条件可以使用where来进行匹配
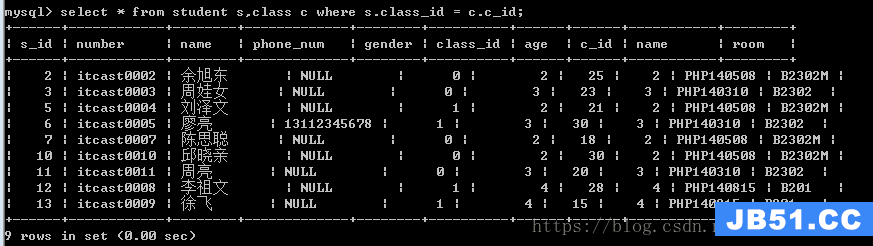
内连接还可以通过使用多表查询,但是使用条件匹配来实现
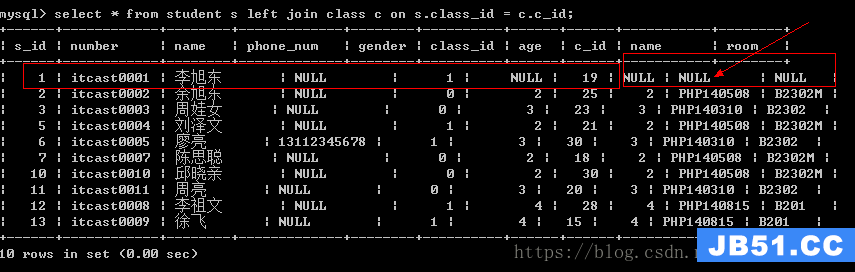
外连接
与内连接相似,如果主表(左外连接左表为主表,右外连接右表为主表)的记录在副表中匹配不上,那么该记录依然保留,只是副表字段都置空
语法:左表 left/right [outer] join 右表 on 连接条件
左外连接:以左表为主表,使用关键字left
右外连接:以右表为主表,使用关键字right
内连接与外连接的区别
1.内连接的条件可以使用where关键字,外连接不行
2.内连接可以没有条件,而外连接必须指定条件
3.内连接只保留匹配成功的记录,而外连接会保留主表的全部记录
外连接左右可以互相转换

不管是内连接还是外连接,都可以进行多表连接(超过两张表)

交叉连接
笛卡尔积
语法:左表 cross join 右表

自然连接
两个表之间的连接不需要指定连接条件,系统自动找条件,并按照条件进行处理。
自然连接可以包含内连接,外连接和交叉连接
语法:
左表 natural [left/right] join 右表
左表 natural join 右表:自然内连接
左表 natural [left/right] join右表:自然外连接
自然连接自动寻找连接条件:会判断两张表中是否有同样的字段名称,如果有,则作为连接条件,否则就没有条件
自然连接,会合并相同的字段
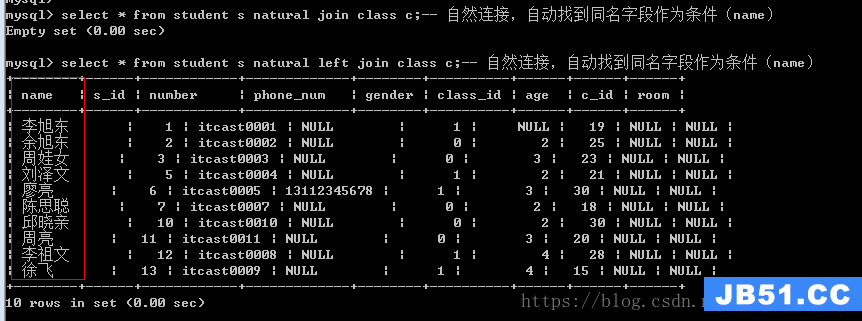
自然连接:会将主表放在左边显示,副表放在右边显示

连接条件,若两张表中的做为连接条件的字段,字段名称相同,那么可以使用using关键字,来确定连接条件,也会合并连接条件
语法:using(连接条件)
使用内连接模拟自然内连接

使用内连接模拟自然外连接
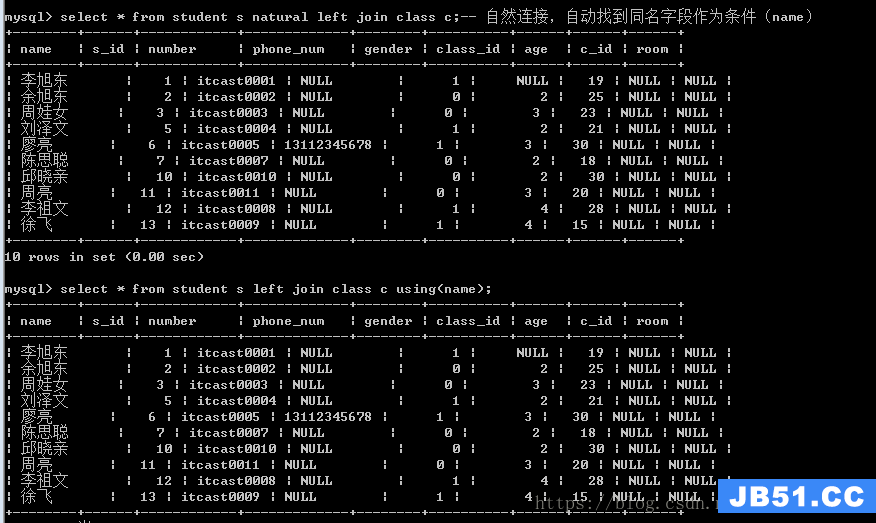
自然连接:无论两张表中有多少同名字段,通通拿过来作为连接条件。
连接查询:用于多表共同显示数据。
 文章浏览阅读8.4k次,点赞8次,收藏7次。SourceCodester Onl...
文章浏览阅读8.4k次,点赞8次,收藏7次。SourceCodester Onl... 文章浏览阅读3.4k次,点赞46次,收藏51次。本文为大家介绍在...
文章浏览阅读3.4k次,点赞46次,收藏51次。本文为大家介绍在... 文章浏览阅读1.1k次。- php是最优秀, 最原生的模板语言, 替代...
文章浏览阅读1.1k次。- php是最优秀, 最原生的模板语言, 替代...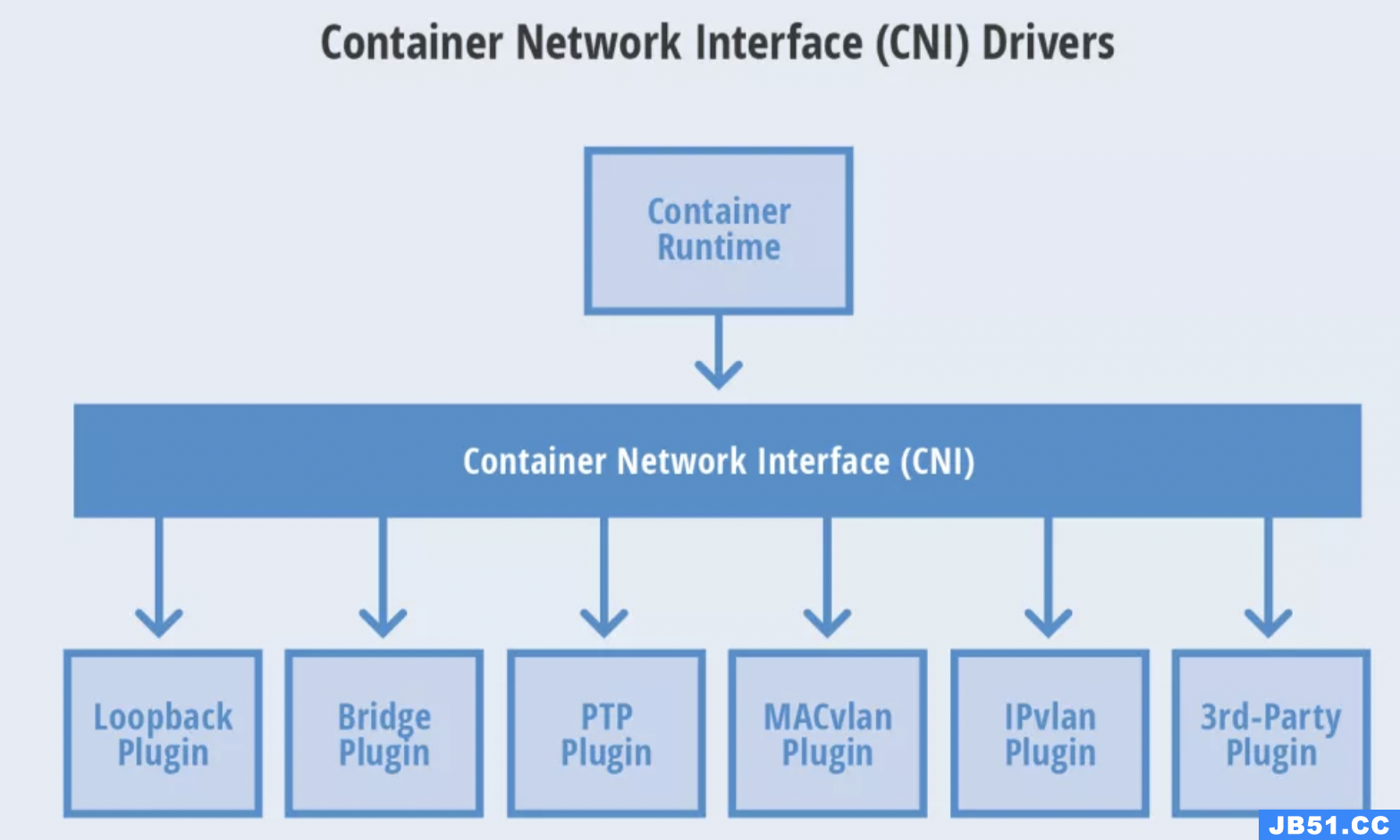 文章浏览阅读1.2k次,点赞22次,收藏19次。此网络模型提供了...
文章浏览阅读1.2k次,点赞22次,收藏19次。此网络模型提供了... 文章浏览阅读1.1k次,点赞14次,收藏19次。当我们谈论网络安...
文章浏览阅读1.1k次,点赞14次,收藏19次。当我们谈论网络安...