df = pd.read_csv('https://raw.githubusercontent.com/selva86/datasets/master/BostonHousing.csv',chunksize=50) df2 = pd.DataFrame() for chunk in df: df2 = df2.append(chunk.iloc[0,:]) df2
输出
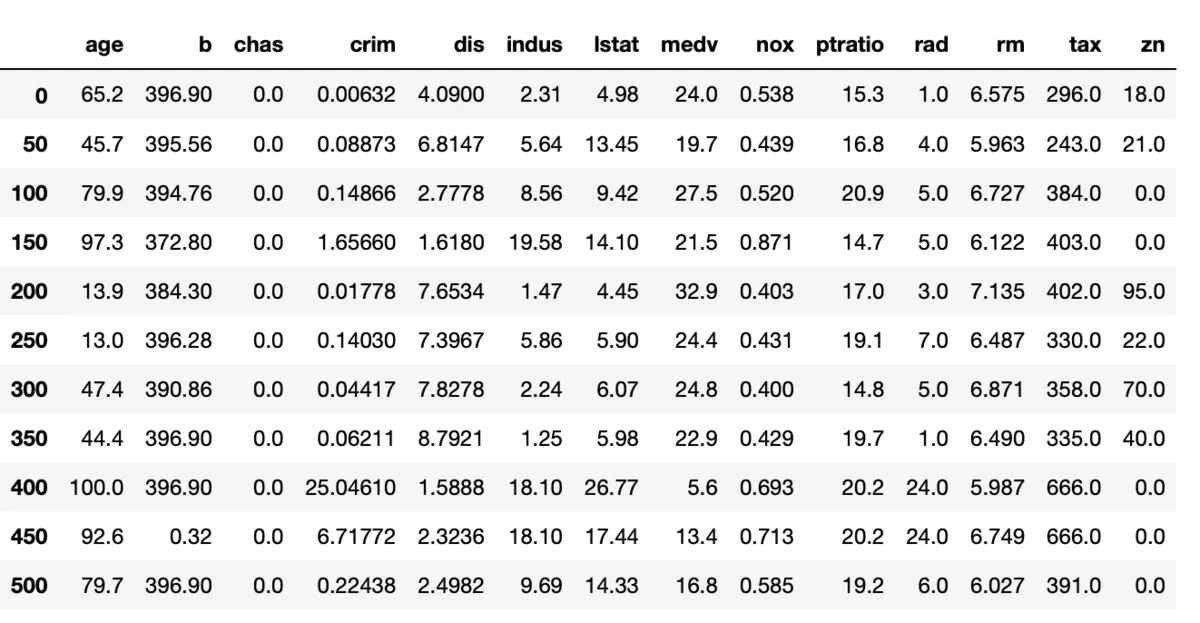
重点解读: pd.read_csv中最重要的是chunksize=50这个参数会把整个csv文件按照50行一个chunk分成多个chunk。 这样在for chunk in df执行循环的时候,每个chunk都能取到50行数据,chunk.iloc[0,:]可以让我们每次从拥有50行的chunk中拿到第一行,然后通过append添加到df2中,就得到了最后的结果。
导入csv中指定的列数据到df中
df = pd.read_csv(crimmedv']) print(df.head())
输出

查询df的相关信息
df = pd.read_csv(https://raw.githubusercontent.com/selva86/datasets/master/Cars93_miss.csv')
查询有多少行多少列
print(df.shape)
输出
(93,27)
查询该df有多少类型
print(df.dtypes)
输出
Manufacturer object
Model object
Type object
Min.Price float64
Price float64
Max.Price float64
MPG.city float64
MPG.highway float64
AirBags object
DriveTrain object
Cylinders object
EngineSize float64
Horsepower float64
RPM float64
Rev.per.mile float64
Man.trans.avail object
Fuel.tank.capacity float64
Passengers float64
Length float64
Wheelbase float64
Width float64
Turn.circle float64
Rear.seat.room float64
Luggage.room float64
Weight float64
Origin object
Make object
dtype: object
查询每种类型的数据统计
print(df.dtypes.value_counts())
输出
float64 18 object 9 dtype: int64
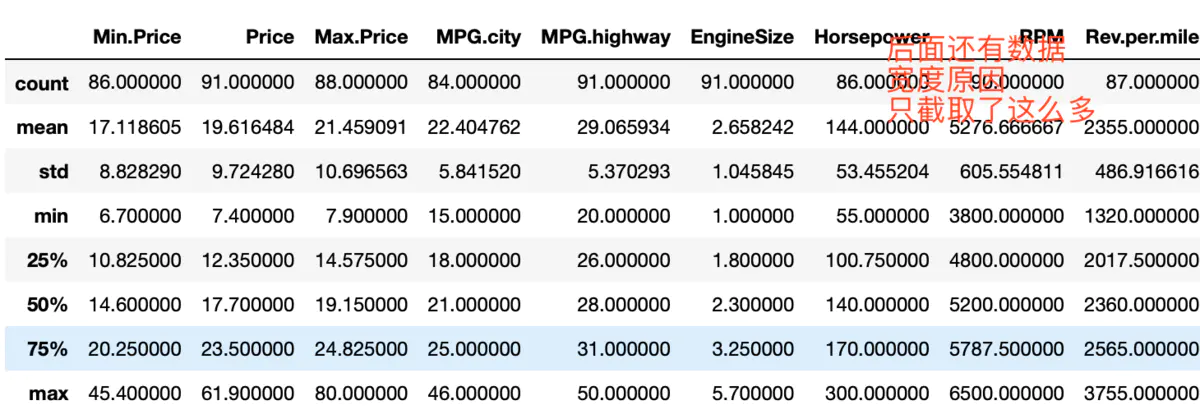
获取该df的统计信息
df_stats = df.describe()
df_stats
把df的value快速转换为array
df_arr = df.values
df_arr
输出

把df的value快速转换为list
df_list = df.values.tolist()
df_list
输出
 转载:一文讲述Pandas库的数据读取、数据获取、数据拼接、数...
转载:一文讲述Pandas库的数据读取、数据获取、数据拼接、数... 一、numpy小结 二、pandas2.1为...
一、numpy小结 二、pandas2.1为... 1、时间偏移DateOffset对象DateOffset类似于时间差Timedelta...
1、时间偏移DateOffset对象DateOffset类似于时间差Timedelta... 1、pandas内置样式空值高亮highlight_null最大最小值高亮背景...
1、pandas内置样式空值高亮highlight_null最大最小值高亮背景...