今天遇见一个问题需要将字段中包含中文字符串的筛选出来
--建表
CREATE TABLE HADOOP1.AAA
(
ID VARCHAR2(255)
);
--添加字段
INSERT INTO HADOOP1.AAA(ID)
VALUES('理解');
....
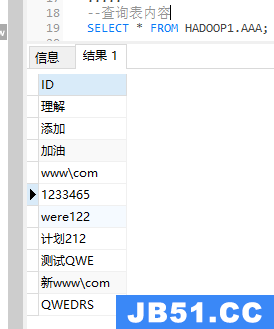
--查询表内容
SELECT * FROM HADOOP1.AAA;
在网上查找了一下有以下三种方式:
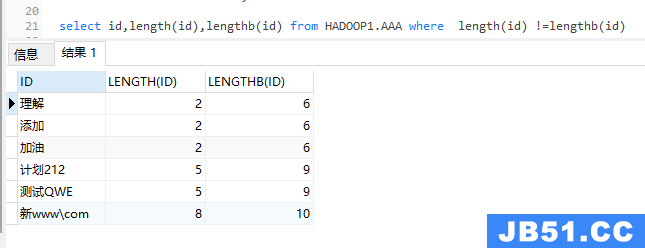
第一种:通过中文字符在length与lengthb的字节长度不同来判断
length计算字符长度,lengthb计算字节长度
select id,length(id),lengthb(id) from HADOOP1.AAA

筛选出包含中文的字符串
select id,lengthb(id) from HADOOP1.AAA where length(id) !=lengthb(id)
第二种:通过asciistr的转换性质将中文字符串筛选出来
ASCIISTR函数,参数是一个字符串,如果这个字符在ASCII码表中有,则转成ASCII表中的字符。如果没有,则转成\xxxx格式,xxxx是UTF-16的编码。
下面是ASCII表
chr(9) tab空格 chr(10) 换行 chr(13) 回车 Chr(13)&chr(10) 回车换行 chr(32) 空格符 chr(34) 双引号 chr(39) 单引号
chr(33) ! chr(34) " chr(35) # chr(36) $ chr(37) % chr(38) & chr(39) ' chr(40) ( chr(41) ) chr(42) *
chr(43) + chr(44) , chr(45) - chr(46) . chr(47) /
Chr(48) 0 Chr(49) 1 Chr(50) 2 Chr(51) 3 Chr(52) 4 Chr(53) 5 Chr(54) 6 Chr(55) 7 Chr(56) 8 Chr(57) 9
chr(58) chr(59) ; chr(60) < chr(61) = chr(62) > chr(63) ? chr(64) @
chr(65) A chr(66) B chr(67) C chr(68) D chr(69) E chr(70) F chr(71) G chr(72) H chr(73) I chr(74) J
chr(75) K chr(76) L chr(77) M chr(78) N chr(79) O chr(80) P chr(81) Q chr(82) R chr(83) S chr(84) T
chr(85) U chr(86) V chr(87) W chr(88) X chr(89) Y chr(90) Z
chr(91) [ chr(92) \ chr(93) ] chr(94) ^ chr(95) _ chr(96) `
chr(97) a chr(98) b chr(99) c chr(100) d chr(101) e chr(102) f chr(103) g chr(104) h chr(105) i
chr(106) j chr(107) k chr(108) l chr(109) m chr(110) n chr(111) o chr(112) p chr(113) q chr(114) r
chr(115) s chr(116) t chr(117) u chr(118) v chr(119) w chr(120) x chr(121) y chr(122) z
chr(123) { chr(124) | chr(125) } chr(126) ~ chr(127) chr(128) chr(153)™ chr(169) © chr(174) ®
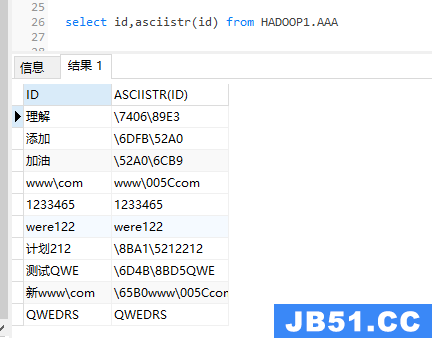
如果表中只有中文和英文、数字等字符,则可以用\来判断是否带有中文。
使用asciistr函数得出是否字段里面包含“/”,因为当中文字符转换为ascii后,变成“/FFFD/FFFD”,但是需要注意一个特殊字符“/”,当它出现的时候转换后的码为“/005C”
代码运行:
select id,asciistr(id) from HADOOP1.AAA
运用:
select * from HADOOP1.AAA where REPLACE(asciistr(id),'\005C','') like '%\%'
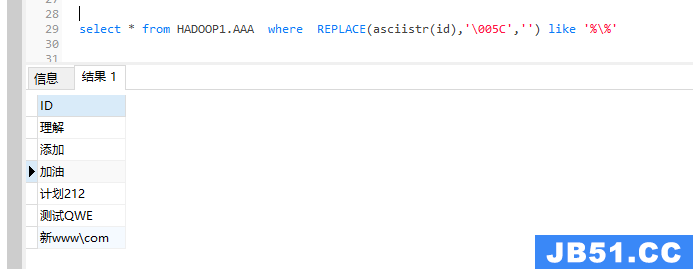
注释:在上面图结果中可以看出包含中文的字符串通过asciistr,转换成包含“\”的字符串,但是这个数据方法有个弊端,原始字符串中不能包含“\”。故我这里用了REPLACE将“\”替换了一下,
同时这个方法不止能筛查中文,还能筛选日文,如果有其他语言就不可以用这种方法
第三种:通过CONVERT 根据类型来进行筛选
CONVERT 函数是 SQL 中的一种类型转换函数,它用于将一个数据类型转换为另一个数据类型。
CONVERT(inputstring,dest_charset,source_charset) inputstring:
要转换的字符串
dest_charset:目标字符集
source_charset:原字符集
select id,CONVERT(id,'ZHS16GBK','utf8') from HADOOP1.AAA where id <> CONVERT(id,'utf8')
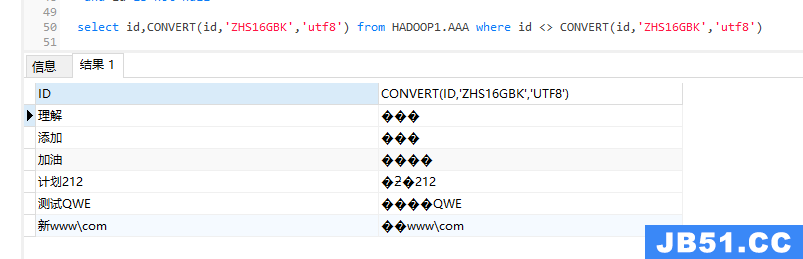
通过上面的可以将包含中文的字符串找出来,那如何能删除里面的中文呢
如要删除字符串中的中文可以用到正则表达式
regexp_replace(tel,‘[^\x00-\xff]’,‘’)
select id,regexp_replace(id,'[^\x00-\xff]','') from HADOOP1.AAA
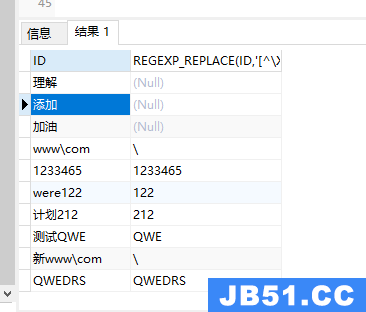
–只保留中文及小写字母
select id,'[\u4e00-\u9fa5]','') from HADOOP1.AAA
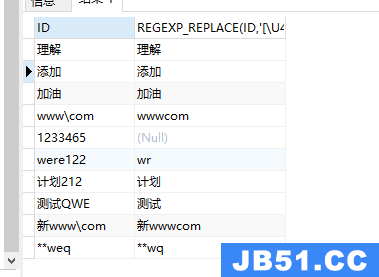
注释:这种表达需要注意字符串中如果包含小写字母,及不在这个范围内容同样可以删除,oracle正则表达式regexp_substr、regexp_like、regexp_replace是无法像其他正则表达式一样用[\u4e00-\u9fa5]来匹配中文的。
 文章浏览阅读8.7k次,点赞2次,收藏17次。此现象一般定位到远...
文章浏览阅读8.7k次,点赞2次,收藏17次。此现象一般定位到远... 文章浏览阅读2.8k次。mysql脚本转化为oracle脚本_mysql建表语...
文章浏览阅读2.8k次。mysql脚本转化为oracle脚本_mysql建表语... 文章浏览阅读2.2k次。cx_Oracle报错:cx_Oracle DatabaseErr...
文章浏览阅读2.2k次。cx_Oracle报错:cx_Oracle DatabaseErr... 文章浏览阅读1.1k次,点赞38次,收藏35次。本文深入探讨了Or...
文章浏览阅读1.1k次,点赞38次,收藏35次。本文深入探讨了Or... 文章浏览阅读1.5k次。默认自动收集统计信息的时间为晚上10点...
文章浏览阅读1.5k次。默认自动收集统计信息的时间为晚上10点...