常用Oracle分析函数详解
学习步骤: 1. 拥有Oracle EBS demo 环境 或者 PROD 环境 2. copy以下代码进 PL/SQL 3. 配合解释分析结果 4. 如果网页有点乱请复制到TXT中查看 /*假设一个经理代表了一个部门 */ SELECT emp.full_name,emp.salary,emp.manager_id,row_number() over(PARTITION BY emp.manager_id ORDER BY emp.salary DESC) row_number_dept,--部门排行 rownum row_number,--行号 round((rownum + 1) / 4) page_number,--每4行一页 ntile(2) over(ORDER BY emp.salary DESC) page_number_nt,--平均分成两类 AVG(emp.salary) over(PARTITION BY emp.manager_id) avg_salary_department,--该部门薪水均值 SUM(emp.salary) over(PARTITION BY emp.manager_id) sum_salary_department,--该部门薪水总额 COUNT(emp.salary) over(PARTITION BY emp.manager_id) count_emp_department,--部门所有的员工 dense_rank() over(PARTITION BY emp.manager_id ORDER BY emp.salary DESC) rank_salary_dept,--该人员的部门薪水排行 dense_rank() over(ORDER BY emp.salary DESC) rank_salary_company,--该人员的全公司排行 MIN(emp.salary) over(PARTITION BY emp.manager_id) min_salary_dept,--部门的最低薪水 MIN(emp.salary) keep(dense_rank FIRST ORDER BY emp.salary) over(PARTITION BY emp.manager_id) min_salary_dept_first,--部门的最低薪水 first_value(emp.salary) over(PARTITION BY emp.manager_id ORDER BY emp.salary) min_salary_dept_firstv,--部门的最低薪水 MAX(emp.salary) over(PARTITION BY emp.manager_id) max_salary_dept,--部门的最高薪水 MAX(emp.salary) keep(dense_rank LAST ORDER BY emp.salary) over(PARTITION BY emp.manager_id) max_salary_dept_last,--部门的最高薪水 last_value(emp.salary) over(PARTITION BY emp.manager_id ORDER BY emp.salary) max_salary_dept_lastv,--部门的最高薪水 lag(emp.full_name,1,'00') over(ORDER BY emp.salary DESC) last_persion,--薪水在自己前一位的人 lead(emp.full_name,'00') over(ORDER BY emp.salary DESC) next_persion --薪水在自己后一位的人 FROM fwk_tbx_employees emp ORDER BY emp.salary DESC 1. 基本概念理解 分析函数 1. 顾名思义,分析函数是在主查询结果的基础上进行一定的分析,如分部门汇总,分部门求均值等等。 数据窗口 1. Oracle 分析函数建立在所谓的数据窗口之上,数据窗口可以理解为一个数据集合。主查询的数据可以按照不同的标准分割成不同的数据集。比如partition BY manager_id 按照manager_id将主查询的数据分成N(N代表有多少个不同的Manager_id)个不同的数据窗口。 2. 其次,数据窗口内部还应该与一定的顺序通过 ORDER BY 实现 分析函数和GROUP BY的区别和联系 1. 分析函数的功能大部分都可以通过GROUP BY 来聚合完成 2. 分析函数查询出来的行数是由主查询决定的,GROUP BY 的行数结果是由GROUP BY 后面的集合构成的唯一性组合决定的,通常比主查询的结果行数少。 2. 典型格式详解 SUM(emp.salary) over(PARTITION BY emp.manager_id) sum_salary_department,--该部门薪水总额 功能简介: 当前行对应人员所在部门的薪水总额 AVG,count与之类似 过程理解 1. 首先将查询出来的数据集按照MANAGER_ID分割 2. 查找到当前行的MANAGER_ID对应的数据集 3. 对以上数据集合求和,生成一个结果附在新添加的列中 dense_rank() over(PARTITION BY emp.manager_id ORDER BY emp.salary DESC) rank_salary_dept,--该人员的部门薪水排行 功能简介: 当前行对应人员在所在部门的薪水排名(不出现并列情况,相同的值也会依次有不同的排序,且排序连续) RANK 函数与之相反,要出现并列的情况啊,且并列将导致排名不连续如A和B并列第一,那么将没有第二名,而直接出现第三名 过程理解 1. 首先将查询出来的数据集按照MANAGER_ID分割 2. 对当前行MANAGER_ID对应的数据集进行排序 3. 将本行对应的行号提取并附在附加列中 MIN(emp.salary) keep(dense_rank FIRST ORDER BY emp.salary) over(PARTITION BY emp.manager_id)min_salary_dept_first,--部门的最低薪水 功能简介: 当前行对应人员在所在部门的最低薪水 MAX函数与之类似 过程理解 1. 首先将查询出来的数据集按照MANAGER_ID分割 2. 对当前行MANAGER_ID对应的数据集进行排序,提取最前面的行,最前面的行的值有相等的,那么返回多行 3. 在返回的多行中,提取薪水最小的行,并提取salary字段 first_value(emp.salary) over(PARTITION BY emp.manager_id ORDER BY emp.salary) min_salary_dept_firstv,--部门的最低薪水 功能简介: 当前行对应人员在所在部门的最低薪水 last_value与之相反,求的是最后一个值 过程理解 1. 首先将查询出来的数据集按照MANAGER_ID分割 2. 对当前行MANAGER_ID对应的数据集进行排序 3. 提取第一行的salary字段 LAG(EMP.FULL_NAME,'00') OVER (ORDER BY EMP.SALARY DESC)LAST_PERSION,--薪水在自己前一位的人 功能简介: 总体薪水排名中,比自己高一位的人的名字 lead 函数与之相反求的在自己后面的人 参数介绍: LAG(p_segment,p_distance,p_defaualt_val) 1. p_segment: 需要提取的字段 2. p_distance:>=0的数,表示比当前人员前面了几位 3. p_defaualt_val: 当当前行没有比它前的行的时候,显示默认值 过程理解 1. 首先将查询出来的数据集按照薪水进行降序排序 2. 提取前p_distance位的p_segment字段
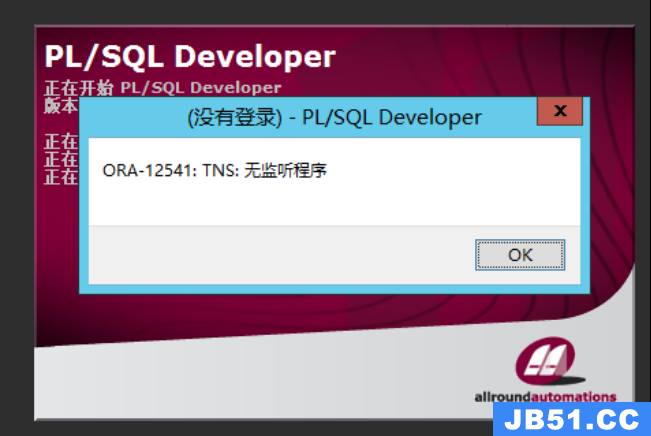 文章浏览阅读8.7k次,点赞2次,收藏17次。此现象一般定位到远...
文章浏览阅读8.7k次,点赞2次,收藏17次。此现象一般定位到远...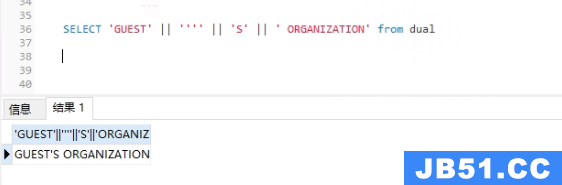 文章浏览阅读2.8k次。mysql脚本转化为oracle脚本_mysql建表语...
文章浏览阅读2.8k次。mysql脚本转化为oracle脚本_mysql建表语...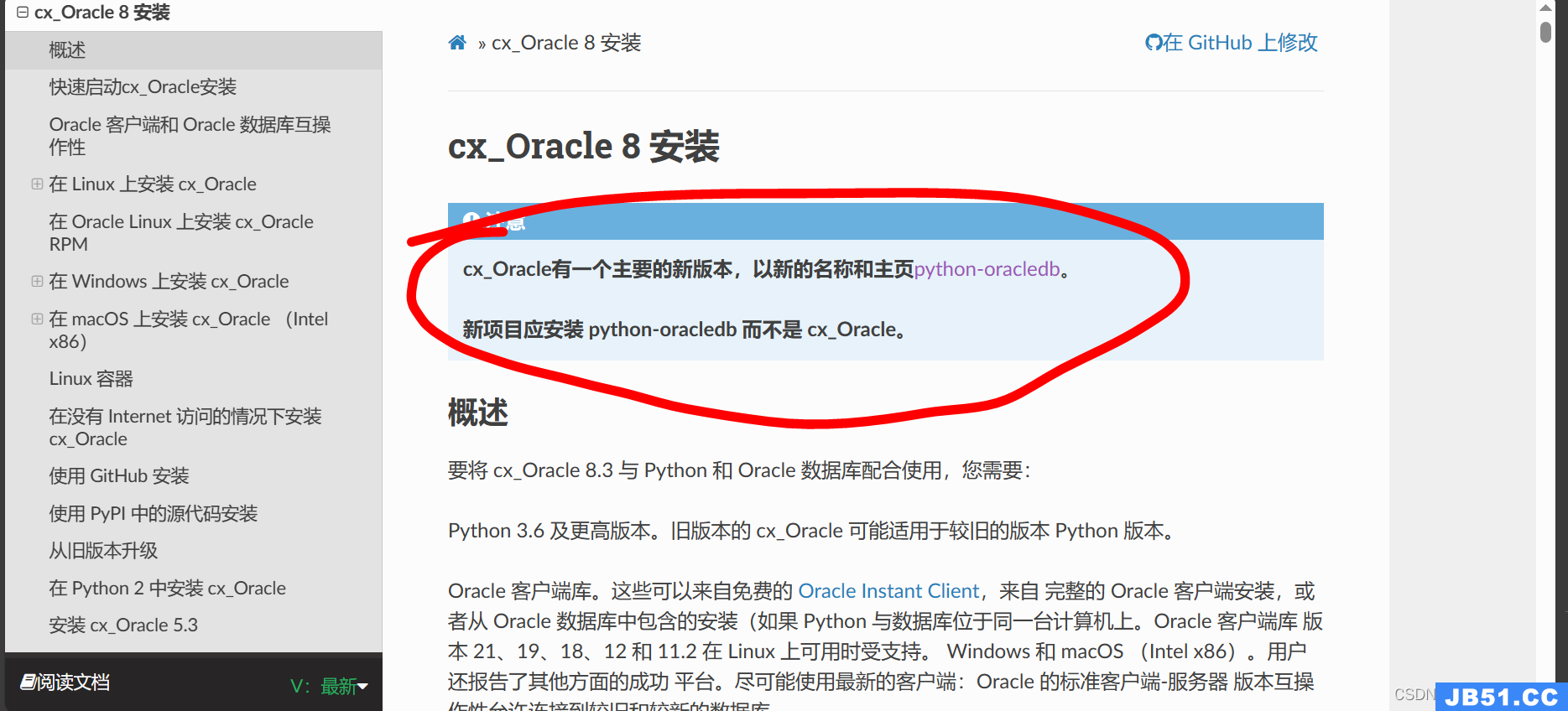 文章浏览阅读2.2k次。cx_Oracle报错:cx_Oracle DatabaseErr...
文章浏览阅读2.2k次。cx_Oracle报错:cx_Oracle DatabaseErr... 文章浏览阅读1.1k次,点赞38次,收藏35次。本文深入探讨了Or...
文章浏览阅读1.1k次,点赞38次,收藏35次。本文深入探讨了Or... 文章浏览阅读1.5k次。默认自动收集统计信息的时间为晚上10点...
文章浏览阅读1.5k次。默认自动收集统计信息的时间为晚上10点...