Numpy 可以读写磁盘上的文本数据或二进制数据
NumPy 为 ndarray 对象引入了一个简单的文件格式:npy
npy 文件用于存储重建 ndarray 所需的数据、图形、dtype 和其他信息
常用的 IO 函数有:
-
load() 和 save() 函数是读写文件数组数据的两个主要函数,默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为 .npy 的文件中
-
savze() 函数用于将多个数组写入文件,默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为 .npz 的文件中
-
loadtxt() 和 savetxt() 函数处理正常的文本文件(.txt 等)
numpy.save() 函数
将数组保存到以 .npy 为扩展名的文件中
numpy.save(file,arr,allow_pickle=True,fix_imports=True)
参数说明:
-
file:要保存的文件,扩展名为 .npy,如果文件路径末尾没有扩展名 .npy,该扩展名会被自动加上。
-
arr: 要保存的数组
-
allow_pickle: 可选,布尔值,允许使用 Python pickles 保存对象数组,Python 中的 pickle 用于在保存到磁盘文件或从磁盘文件读取之前,对对象进行序列化和反序列化。
-
fix_imports: 可选,为了方便 Pyhton2 中读取 Python3 保存的数据
示例:
In [1]: import numpy as np
In [2]: num = np.array([1,2,3,4,5])
In [3]: num
Out[3]: array([1,5])
In [4]: np.save('test_1.npy',num)
In [5]: np.save('test_2.npy',num)
In [6]: ls test_*
test_1.npy test_2.npy
In [7]: cat test_1.npy
?NUMPYv{'descr': '<i8','fortran_order': False,'shape': (5,),}
In [8]: cat test_2.npy
?NUMPYv{'descr': '<i8',}
可以看出文件是乱码的,因为它们是 Numpy 专用的二进制格式后的数据,我们可以使用 load() 函数来读取数据就可以正常显示了:
In [9]: b = np.load('test_1.npy')
In [10]: b
Out[10]: array([1,5])
numpy.savez() 函数
将多个数组保存到以 npz 为扩展名的文件中
numpy.savez(file,*args,**kwds)
参数说明:
-
file:要保存的文件,扩展名为
.npz,如果文件路径末尾没有扩展名.npz,该扩展名会被自动加上。 -
args: 要保存的数组,可以使用关键字参数为数组起一个名字,非关键字参数传递的数组会自动起名为
arr_0,arr_1,… -
kwds: 要保存的数组使用关键字名称
示例:
In [1]: import numpy as np
In [2]: a = np.array([[1,3],[4,5,6]])
In [3]: b = np.arange(0,1.0,0.1)
In [4]: c = np.sin(b)
In [5]: a
Out[5]:
array([[1,6]])
In [6]: b
Out[6]: array([0.,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9])
In [7]: c
Out[7]:
array([0.,0.09983342,0.19866933,0.29552021,0.38941834,0.47942554,0.56464247,0.64421769,0.71735609,0.78332691])
In [8]: np.savez('test.npz',a,b,sin_array=c)
In [9]: cat test.npz
sin_array.npy?NUMPYv{'descr': '<f8','shape': (10,},ˋˮ?????=#?m??4???????kg+?:????Kt???ZA?????Fin??????”???@?]???PK!?c?? arr_0.npy?NUMPYv{'descr': '<i8','shape': (2,3),}
PK!?U??? arr_1.npy?NUMPYv{'descr': '<f8',}
?sin_array.npyPK!?c??3????arr_0.npyPK!?U???fffff??arr_1.npyPK?????PK!??&m??
In [10]: r = np.load('test.npz')
In [11]: r
Out[11]: <numpy.lib.npyio.NpzFile at 0x10c6019e8>
In [12]: r.files
Out[12]: ['sin_array','arr_0','arr_1']
In [13]: r['sin_array'],r['arr_0'],r['arr_1']
Out[13]:
(array([0.,0.78332691]),array([[1,6]]),array([0.,0.9]))
savetxt() 函数
是以简单的文本文件格式存储数据,对应的使用 loadtxt() 函数来获取数据
np.loadtxt(FILENAME,dtype=int,delimiter=' ')
np.savetxt(FILENAME,fmt='%d',delimiter=',')
参数 delimiter 可以指定各种分隔符、针对特定列的转换器函数、需要跳过的行数等
In [1]: import numpy as np
In [2]: a = np.array([1,5])
In [3]: np.savetxt('test.txt',a)
In [4]: cat test.txt
1.000000000000000000e+00
2.000000000000000000e+00
3.000000000000000000e+00
4.000000000000000000e+00
5.000000000000000000e+00
In [5]: a
Out[5]: array([1,5])
In [6]: np.loadtxt('test.txt')
Out[6]: array([1.,2.,3.,4.,5.])
使用 delimiter 参数:
In [1]: import numpy as np
In [2]: a = np.arange(0,10,0.5).reshape(4,-1)
In [3]: a
Out[3]:
array([[0.,1.,1.5,2. ],[2.5,3.5,4.5],[5.,5.5,6.,6.5,7. ],[7.5,8.,8.5,9.,9.5]])
In [4]: np.savetxt('test.txt',')
In [5]: cat test.txt
0,1,2
2,4
5,6,7
7,8,9,9
In [6]: np.loadtxt('test.txt',')
Out[6]:
array([[0.,0.,2.],[2.,4.],5.,7.],[7.,9.]])
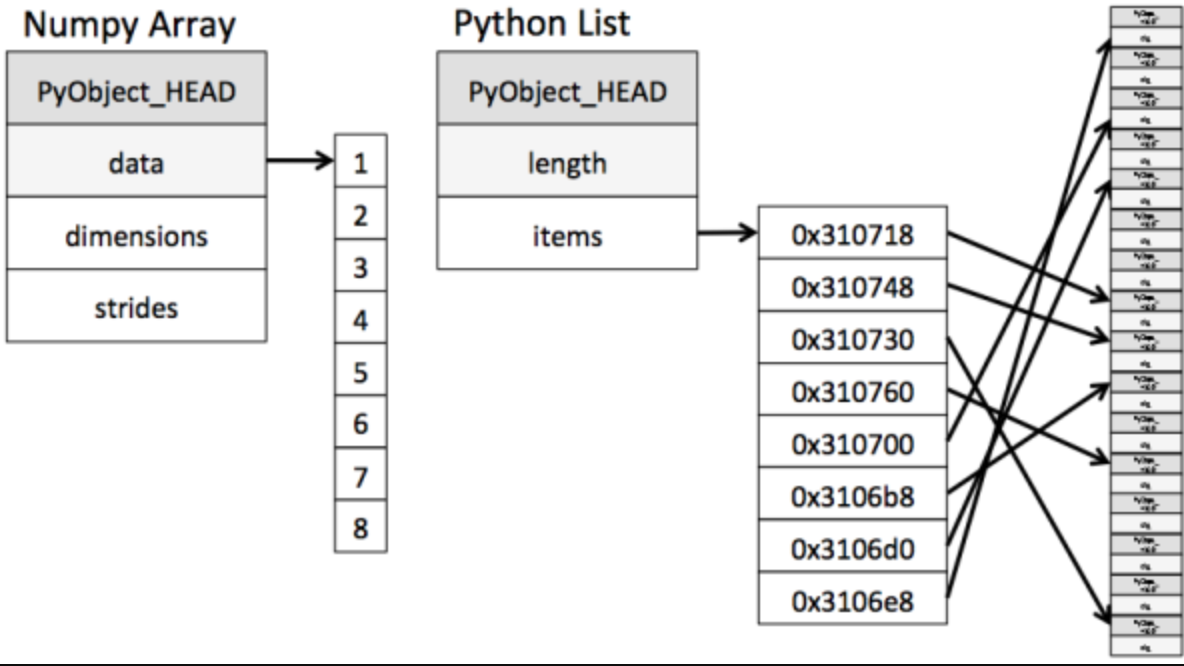 内存块风格 ndarray到底跟原生python列表有什么不同呢,请看...
内存块风格 ndarray到底跟原生python列表有什么不同呢,请看...