时间序列论文: NeuralProphet: Explainable Forecasting at Scale
NeuralProphet: Explainable Forecasting at Scale
PDF: https://arxiv.org/pdf/2111.15397.pdf
PyTorch代码: https://github.com/shanglianlm0525/TimeSeries
1 概述
NeuralProphet是一个基于PyTorch实现的客户友好型时间序列预测工具,延续了2018年Facebook开源预测工具Prophet的主要功能,主要用于时序数据分析(个人使用体验:最好是具备显著时序特征的数据)。NeuralProphet是在一个完全模块化的架构中开发的,这使得它可以在未来增加额外组件,可扩展性很强。项目意在保留Prophet的原始特性,如Classic AR模型可解释性、可配置性,并使用了PyTorch后台进行优化,如Gradient Descent,另外还引入了AR-Net建模时间序列自相关、自己设置损失和指标、具备前馈神经网络的可配置非线性层等等特性。
2 NeuralProphet
NeuralProphet是一个可分解的时间序列模型,和Prophet相比,类似的组成部分有趋势(trend)、季节性(seasonality)、自回归(auto-regression)、特殊事件(special events),不同之处在于引入了未来回归项(future regressors)和滞后回归项(lagged regressors)。
未来回归项(future-known regressors)是指在预测期有已知未来值的外部变量,而滞后回归项(lagged covariates)是指那些只有观察期值的外部变量。趋势trend可以通过设置变化点来建立线性或者组合多个线性趋势的模型。季节性seasonality使用傅里叶项建模,因而可以解决高频率数据的多种季节性。自回归项(auto-regression)使用AR-Net的实现来解决,这是一个用于时间序列的自回归前馈神经网络(Auto-Regressive Feed-Forward Neural Network)。滞后回归项也使用单独的前馈神经网络进行建模。未来回归项和特殊事件都是作为模型的协变量,只要要single weight进行建模。
2-1 Model Components
NeuralProphet模型模型由多个模块组成,每个模块都有各自的输入和建模过程。 每个模块都有自己的个人输入和建模过程。 但是,所有模块都必须产生 h 个输出,其中h 定义了一次预测未来的步数。
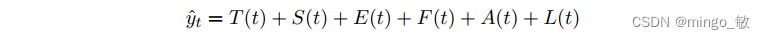
其中:
T(t) = 时间 t 的趋势
S(t) = 时间 t 的季节性影响
E(t) = 时间 t 的事件和假日效应
F(t) = 未来已知外生变量在时间 t 的回归效应
A(t) = 基于过去观察的时间 t 的自回归效应
L(t) = t 时刻外生变量滞后观测的回归效应
所有模型组件模块都可以单独配置和组合以组成模型。 如果所有模块都关闭,则仅安装一个静态偏移参数作为趋势分量。 默认情况下,仅激活 trend 和 seasonality 模块。
2-1-1 Trend
2-1-2 Seasonality
类似Prophet,NeuralProphet也使用傅立叶项(Fourier terms)来处理Seasonality。傅立叶项定义为正弦、余弦对并允许对多个季节性以及具有非整数周期的季节性进行建模。每个季节性可以定义为多个傅里叶项。
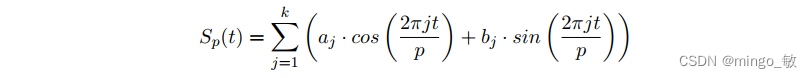
其中 k 具有周期性p的季节性的傅立叶的数量。每一个季节性对应 2k 个系数。在 t 时刻,模型涉及的所有季节性效应可以表示为:
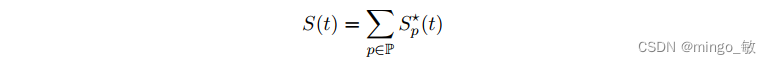
每个季节周期性可以单独表示为 additive 或者 multiplicative 的形式:
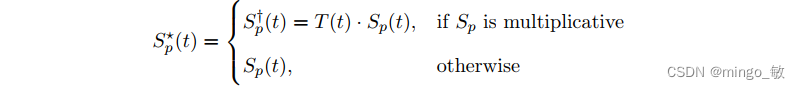
NeuralProphet根据数据频率和长度自动激活每日、每周或每年的季节性。 既 周期大于2个季节性,激活对应季节性。默认每个季节性的傅立叶项数为:年:k = 6,p = 365.25,周: k = 3,p = 7,日:p = 1,k = 6。
2-1-3
2-1-4
2-1-5
2-1-6
2-1-7
2-2 Preprocessing
2-2-1 Missing Data
当没有滞后变量的时候,直接丢掉缺失值就好。有滞后变量的情况下,每个缺失值会导致h + p被丢弃,因此引入数据插值机制;如果不特别指定的话,缺失值用 0 填充。
数据插值: 当Auto-regression 或者 lagged regressor使用的时候,主要采取三个步骤
- 1 对于不超过10个值的缺失,使用前后已知的值线性插值;
- 2 对于小于20个值的缺失,使用一个滑动窗口大小为30的计算平均值;
- 3 如果超过连续30个值缺失的话,不插值,直接丢弃这部分值;
2-2-2 Data Normalization
用户可以设定归一化的参数,如果不设定,对于二值化数值使用minmax,其他默认使用soft。

2-2-3 Tabularization
2-3 Training
Prophet 使用Stan 实现的 L-BFGS 拟合模型,NeuralProphet依赖PyTorch实现的SGD拟合模型;
2-3-1 Loss Function
NeuralProphet默认使用Huber loss,即smooth L1-loss,如下
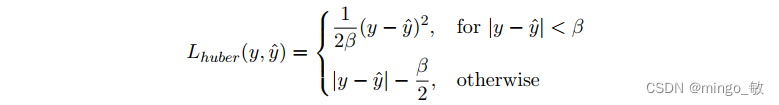
对于给定的阈值 β β β, 低于阈值 β β β,损失函数变为mean squared error (MSE);高于阈值 β β β,损失函数变为mean absolute error (MAE)。用户可以设定MSE, MAE 或者其他PyTorch实现的函数;
2-3-2 Regularization
2-3-3 Optimizer
默认使用AdamW
AdamW(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0.0001, maximize=False, capturable=False)
也可以选用SGD
SGD(params, lr=0.01, momentum=0.9, dampening=0, weight_decay=0.001, nesterov=False)
同时也可以使用PyTorch支持的其他 optimizer。
2-3-4 Learning Rate
通过测试的方式来估计一个学习率,针对特定的数据集大小,测试
100
+
l
o
g
10
(
10
+
T
)
∗
50
)
100 + log10(10 + T ) ∗ 50)
100+log10(10+T)∗50) 次, 从
η
=
1
e
−
7
η = 1e − 7
η=1e−7到
η
=
1
e
+
2
η = 1e + 2
η=1e+2 之间。
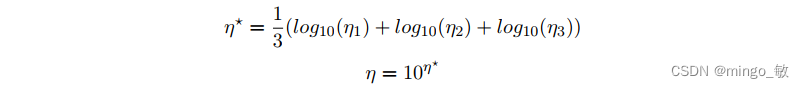
2-3-5 Batch Size
如果未指定,根据数据量T来决定,
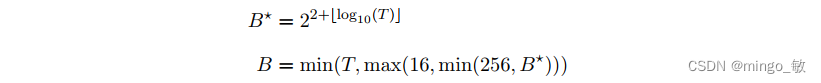
2-3-6 Epochs
如果未指定,根据数据量T来决定,
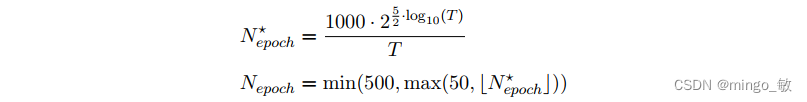
2-3-7 Scheduler
采用’1cycle’ policy,学习率在最初的30%训练时间内从 η 100 \frac{η}{100} 100η 上升到 η η η,接着cosine曲线下降到 η 5000 \frac{η}{5000} 5000η,直到训练结束。