value_counts() 函数得作用
用来统计数据表中,指定列里有多少个不同的数据值,并计算每个不同值有在该列中的个数,同时还能根据指定得参数返回排序后结果。
返回得是Series对象
value_counts(values,sort=True, ascending=False, normalize=False,bins=None,dropna=True)
- sort=True: 是否要进行排序;默认进行排序
- ascending=False: 默认降序排列;
- normalize=False: 是否要对计算结果进行标准化并显示标准化后的结果,默认是False。
- bins=None: 可以自定义分组区间,默认是否
- dropna=True:是否删除缺失值nan,默认删除
数据集
要求:统计不同
lable出现得次数
任何参数都不带
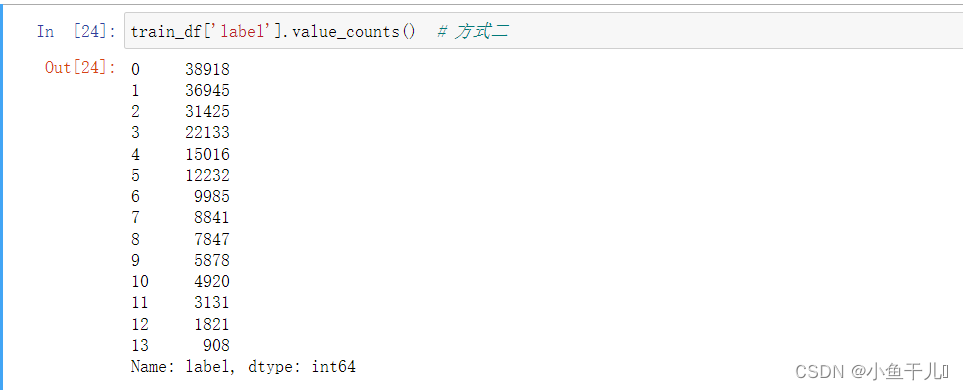
train_df['label'].value_counts()
默认统计个数并降序返回
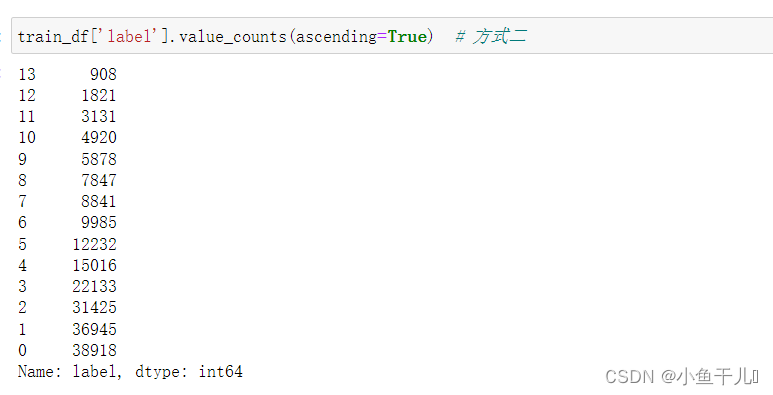
- ascending=True
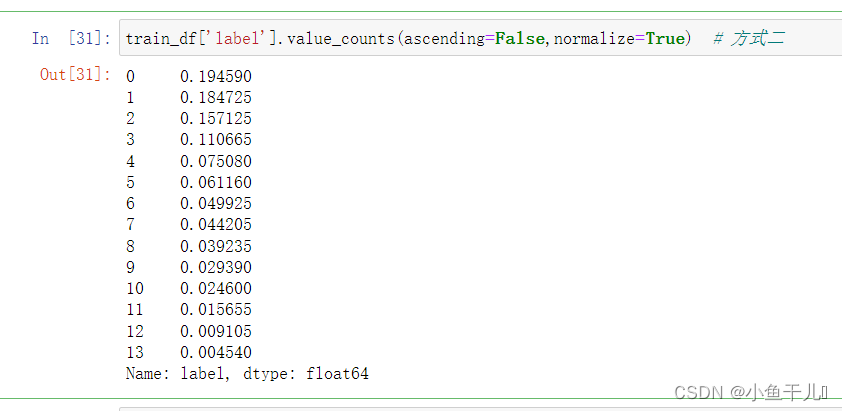
- normalize=True
数据标准化:在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
train_df['label'].value_counts(ascending=False,normalize=True)
数据标准化以后,所有得项得和为1(可能因为计算机存储数据而有误差)
常用来计算各数据占的比例
- bins分组统计
对于数值型的可以进行分组,分组以后返回结果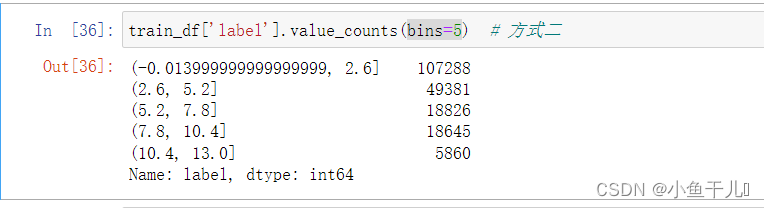
几种使用方式
- 先取出列(Series对象),然后调用函数这时候相当于
train_df['label'].value_counts()
- DataFrame
对每一列都进行统计
train_df.apply(pd.value_counts)
- 直接使用Pandas调用
pd.value_counts(train_df['label'],ascending=True)
同样的统计还可以使用 groupby,这个的过程是先按‘label’分组然后再统计每组的值,这样的效率较低,不建议使用
train_df.groupby('label').count()