作者 | 梁唐
出品 | 公众号:Coder梁(ID:Coder_LT)
大家好,我是梁唐。
今天我们接着之前,继续看B站2021算法岗校招笔试题选择题的最后一个部分。
题目来源于牛客网,感兴趣的同学可以点击阅读原文跳转。
第一题
分布式系统的CAP原则指分布式系统在三个要素中只能兼顾两点。下列不属于三要素中的是

这道题考察的是对分布式系统基本的了解,CAP是分布式系统当中的基本原则。
其中的C指的是consistency,即一致性,A指的是availability,即可用性,P指的是partition tolerance,即分区容错性。
事务性并不是CAP中的要素,别和数据库ACID四原则弄混。
第二题
对于n个带权样本的随机有放回带权采样,采样m次。最优时间复杂度为?

表面上来看,这题考的是时间复杂度,其实本质上是在考察算法。
加权有放回采样速度最快的算法叫做alias采样算法,它的时间复杂度分为两个部分,预处理部分和采样的部分。其中预处理部分的复杂度是O(n) ,每次采样的复杂度是O(1) ,加起来的复杂度是O(n+m) ,故选B。
简单介绍一下算法,显然,所有样本被抽中的概率和是1。算法上来会先对每一个样本的概率乘上N(样本总数),这样得到的概率和就是N。我们把每个样本的概率分布画出来:

其中有些大于1,也有一些小于1,但是均值肯定是等于1的。
接着我们把这个柱状图进行均摊,将长度超出1的部分分摊到其他柱上。确保每个小方格面积为1,并且每个小方格内最多只有两个样本,分摊之后得到的图如下:
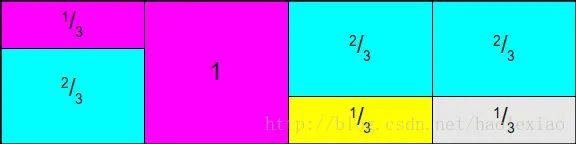
这样一来我们会得到两个数组,一个数组存的是事件i占据比例prob,在这个例子当中就是[2/3, 1, 1/3, 1/3]。第二个数组存的是填充的样本编号alias,在这个例子当中就是[1, null, 0, 0]。
我们在采样的时候会出两个随机数,第一个随机数在0-n之间,用来选择列。第二个随机数在0-1之间,如果它小于prob[i],那么选择样本ii,否则选择样本alias[i]。
大家感兴趣可以算一算,看看这样得到的结果是不是符合预期。
第三题
关于机器学习中FM算法(Factorization Machines) 与MF算法(Matrix Factorization),以下说法正确的是?

这道题考察的是对FM算法和MF算法的理解。
这两个算法都涉及向量交叉,有一些相似的地方,存在一些迷惑性。其中FM算法核心思想是使用向量交叉来计算二阶参数的系数,是推荐系统中的经典模型。MF算法是用来分解大规模的矩阵,将一个长和宽都非常巨大的矩阵分解成三个规模更小矩阵的乘积,达到压缩存储空间,以及表示user和item向量的效果,也是推荐系统中的经典算法。
从目的上来看,两者的目的完全不同,可以排除选项A。
选项B很有迷惑性,它的前半句是正确的,FM算法的确引入了二阶交叉特征。但后半句不对,FM算法本身的初衷正是为了解决二阶样本过于稀疏的问题,所以B也可以排除。
C算法是正确的,FM算法给每一个特征赋予了向量,用向量之间的内积来计算交叉特征的权重,MF算法则将user-item的庞大矩阵拆解成user向量和item向量,都可以看成是一种embedding。
第四题
下面哪一方法可以判断出一个有向图是否有环(回路)

算法基础题,节点的度可以判断是否存在欧拉回路,最短路径可以求最短路径,但不能求出是否有环,同样也可以排除D选项。
拓扑排序可以判断是否有环,如果还存在节点入度大于0,但又找不到入度为0的节点,那么说明存在环。
第五题
机器学习训练时,Mini-Batch 的大小优选为2个的幂,如 256 或 512。它背后的原因是什么?

通过排除法也可以知道选B。
梯度下降算法的速度和mini-batch的奇偶性显然没有关系,不使用偶数损失函数不稳定也站不住脚,所以排除AC。
其实严格说起来B选项也有一点不太准确,因为主要不是为了符合内存要求,而是符合线程的要求,CPU或GPU的线程数都是2的幂。
总体来说这题不是非常严谨,可以忽略。
第六题
以下哪些是bert预训练时学习的任务?1. Masked LM 2. NER 3. NSP 4. Capitalization Prediction Task

bert基础题,奈何老梁不做NLP,也不知道……
正确答案是C。
第七题
在以下的哪一个数据集上,一般不使用 Hidden markov model?

隐马尔可夫理论题,了解隐马尔可夫模型的话会知道,它是一个针对序列的算法,含有一条可见状态链和一条隐含状态链。
其中股票的价格、每日访问用户数、中文分词之间都是序列数据,只有电影评分数据集完全是离散的,没有时序的关系。
故选B。
第八题
假设数据集的输入x和输出y均为实数,数据集中有三个数据点如下: {(x,y)}={(0,1), (1,1), (2,0)}。在线性回归模型(y=a+bx+noise)下, 使用留一法(Leave One Out)交叉验证得到的均方误差是多少?

这道题比较麻烦一点,首先我们要清楚什么是留一法。
留一法的意思是,将数据平均分成k份,每次用k-1份进行训练,留下一份作为验证,一共进行k次,这是一种解决训练样本不足的方法。
由于我们只有3条数据,所以对应每次会用2条进行训练,一条验证。首先是(0, 1), (1, 1),训练之后得到的模型为y = 0x + 1。在(2, 0)位置的误差是1。
第二次选择(1, 1), (2, 0),得到的模型为y = -x + 2。在(0, 1)处的误差也是1。
第三次选择(0, 1), (2, 0),得到的模型为y = -0.5x + 1,在(1, 1)处的误差是0.5。我们把这三个误差综合起来算均方差,也就是\frac {\sqrt{1^2 + 1^2 + 0.5^2}} 3 = 0.75 ,所以选C。
到这里这一次笔试的所有选择题就和大家盘点完了,三道算法题之前写过一道,还剩下两道,之后会抽一期文章一起写了。
总的来说,这个笔试的难度还是可以的,涉及的知识面以及难度都不算太低,甚至老梁这个老江湖都有不会的。如果分数要求高的话,想要通过可能也不是太容易。为了面试找份好工作辛苦准备,结果倒在笔试上实在是太遗憾了,老梁有过类似的经历,所以才会有写一写这些题解的想法。
尤其是这两年市场行情不是非常好,找工作不是一件容易的事,希望能够帮助到一些小伙伴吧。
感谢大家的阅读~