参考:
尚硅谷netty学习博客 https://imlql.cn/post/3f9283e7.html
netty 入门-阿里云社区:https://blog.csdn.net/yunqiinsight/article/details/107953180
1.BIO

代码
package com.atguigu.bio;
import java.io.InputStream;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class BIOServer {
public static void main(String[] args) throws Exception {
//线程池机制
//思路
//1. 创建一个线程池
//2. 如果有客户端连接,就创建一个线程,与之通讯(单独写一个方法)
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
//创建ServerSocket
ServerSocket serverSocket = new ServerSocket(6666);
System.out.println("服务器启动了");
while (true) {
System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
//监听,等待客户端连接
System.out.println("等待连接....");
//会阻塞在accept(),等待 “建立链接的请求”
final Socket socket = serverSocket.accept();
System.out.println("连接到一个客户端");
//就创建一个线程,与之通讯(单独写一个方法)
newCachedThreadPool.execute(new Runnable() {
public void run() {//我们重写
//可以和客户端通讯
handler(socket);
}
});
}
}
//编写一个handler方法,和客户端通讯
public static void handler(Socket socket) {
try {
System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
byte[] bytes = new byte[1024];
//通过socket获取输入流
InputStream inputStream = socket.getInputStream();
//循环的读取客户端发送的数据
while (true) {
System.out.println("线程信息id = " + Thread.currentThread().getId() + "名字 = " + Thread.currentThread().getName());
System.out.println("read....");
int read = inputStream.read(bytes);
if (read != -1) {
System.out.println(new String(bytes, 0, read));//输出客户端发送的数据
} else {
break;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println("关闭和client的连接");
try {
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
优缺点
- 同步阻塞IO,一个请求(连接)一个线程处理
- 不适用高并发业务
- IO处理的话使用 字符流或者字节流,没有使用buffer和通道结合
- 如果使用线程池优化需要考虑 线程数目和 queue的 长度,并发不高
2. NIO
参考:https://blog.csdn.net/oMaoYanEr/article/details/79976359
NIO 三大核心: buffer,channel,selector

//创建一个服务端channel
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
//创建一个selector(调用 操作系统底层 epoll_create()方法)
Selector selector = Selector.open();
//绑定一个端口,在服务端监听
serverSocketChannel.socket().bind(new InetSocketAddress(6666));
//设置为非阻塞
serverSocketChannel.configureBlocking(false);
//serverSocketChannel注册到selector,并设置关心事件(调用 操作系统底层 epoll_ctl()方法)
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
// System.out.println("注册SelectionKey的数量" + selector.keys().size());
//循环等待客户链接
while (true){//一次循环解决一个事件集合里的全部事件,下次循环会再继续监听
//select方法(调用 操作系统底层 epoll_ctl()方法), 此处会造成CPU空转
if (selector.select(1000) == 0){//无事发生,继续循环等待
// selector.selectedKeys().size() // 有事件发生的事件的数量
System.out.println("服务器等待了一秒,无事发生,当前以注册的selectionKey数量为:" + selector.keys().size());
continue;
}
//返回》0,有事发生,获取客户端发生关注事件的集合
//通过selectionKeys可以反向获取Channel
Set<SelectionKey> selectionKeys = selector.selectedKeys();
//遍历selectionKeys,获取当前事件集
Iterator<SelectionKey> Keyiterator = selectionKeys.iterator();
while (Keyiterator.hasNext()){
//获取当前事件
SelectionKey selectionKey = Keyiterator.next();
//查看key发生的事件并作相应的处理
if(selectionKey.isAcceptable()) {//有新客户端链接
//为这个客户端生成一个channel
SocketChannel socketchannel = serverSocketChannel.accept();
socketchannel.configureBlocking(false);
System.out.println("客户端连接成功," + socketchannel.hashCode());
//将当前channel注册到selector,并关心这个事件有没有发生读事件OP_READ,同时给channel关联一个buffer
socketchannel.register(selector, SelectionKey.OP_READ,ByteBuffer.allocate(1024));
}
if(selectionKey.isReadable()){
//发生了读事件,通过key反向得到channel和绑定的buffer
SocketChannel socketchannel = (SocketChannel)selectionKey.channel();
//获取与该channel关联的buffer,在和连接时就已经绑定了,40行处
ByteBuffer buffer = (ByteBuffer) selectionKey.attachment();
socketchannel.read(buffer);//从客户端读到的数据
System.out.println("from 客户端 : " + new String(buffer.array()));
buffer.clear();
}
}
//及时将当前的SelectionKey,防止操作
Keyiterator.remove();
}
2.1 buffer
2.1.1 buffer

Buffer提供了一个字节缓冲区,其可以不断的从Channel中读取接收到的数据。Buffer的优点主要在于其提供了一系列的Api,能够让用户更方便的对数据进行读取和写入;
HeapByteBuffer & DirectByteBuffer的区别
| HeapByteBuffer | DirectByteBuffer |
|---|---|
| 操作JVM堆内存,可被 JVM直接管理 | 操作系统内存 |
| JVM可自动管理释放内存 | 适用于频繁IO的程序,DirectByteBuffer被释放,系统内存会被释放 |
2.1.2 直接内存
正常IO读写:
正常IO读写会有 内核态<=>用户态 之间转换,操作系统去读取磁盘的内容放入操作系统内存,然后才能转换为java内存
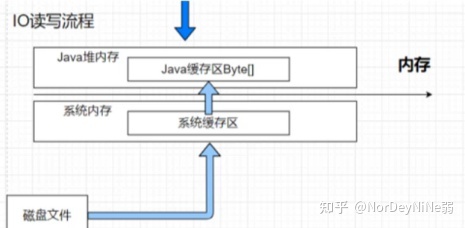
直接内存:

调用ByteBuffer.allocateDirect()时,会分配一块直接内存区间(direct memory),java和系统可以共享该区域,减少一次读写操作;
2.1.3 buffer方法
flip()方法读写切换
Scatter和Gather
Scatter和Gather支持分散和聚合模式;
Scatter 指一个channel0 通道的数据可以分散给多个缓冲区去读,
Gather 多个缓冲区的数据可以同时写入一个channel
2.2 channel
2.2.1 buffer , channel关系图

Channel简单来说就是一个信道,也就是客户端与服务器的一个连接,而且每个客户端都会对应一个Channel对象;
Channel 类似于传统的流对象,但有些不同:
- Channel 直接将指定文件的部分或全部直接映射 Buffer。
- 程序不能直接访 Channel 中的数据,包括读取、写入都不行,Channel只能与 Buffer 进行交互。意思是,程序要读数据时需要先通过Buffer从Channel中获取数据,然后从Buffer中读取数据。
- Channel通常可以异步读写,但默认是阻塞的,需要手动设置为非阻塞。
2.3 selector
Selector是Java nio能够支持高并发数据处理一个关键,其核心理念就是IO多路复用的原理,简单的说就是当多个客户端(Channel)连接服务器时,可以通过Selector同时对这些客户端请求进行监听,当客户端发送数据到服务器之后由Selector对这些Channel进行分发处理。
2.4 三大组件关系图

- 每个
Channel都会对应一个Buffer。 -
Selector对应一个线程,一个线程对应多个Channel(连接)。 - 该图反应了有三个
Channel注册到该Selector//程序 - 程序切换到哪个
Channel是由事件决定的,Event就是一个重要的概念。 -
Selector会根据不同的事件,在各个通道上切换。 -
Buffer就是一个内存块,底层是有一个数组。 - 数据的读取写入是通过
Buffer,这个和BIO是不同的,BIO中要么是输入流,或者是输出流,不能双向,但是NIO的Buffer是可以读也可以写,需要flip方法切换Channel是双向的,可以返回底层操作系统的情况,比如Linux,底层的操作系统通道就是双向的。
3.netty
3.1 netty 是什么?
本质: 网络应用程序框架
实现:异步、事件驱动
应用:客户端服务器开发
特性:高并发,可维护,快速开发
3.2netty与NIO的比较
- API使用简单,学习成本低。设计优雅:适用于各种传输类型的统一
API阻塞和非阻塞Socket;基于灵活且可扩展的事件模型,可以清晰地分离关注点;高度可定制的线程模型-单线程,一个或多个线程池 - 功能强大,内置了多种解码编码器,支持多种协议。
- 高性能、吞吐量更高:延迟更低;减少资源消耗;最小化不必要的内存复制。
- 社区活跃,发现BUG会及时修复,迭代版本周期短,不断加入新的功能。
- JDK NIO 的 Bug:例如臭名昭著的 Epoll Bug,它会导致 Selector 空轮询,最终导致 CPU100%
3.3 三种Reactor模型
3.3.1 单Reactor单线程

缺点:
处理链接和 业务都用一个线程,效率不高
无法发挥多核CPU的优势
当 1w个事件同时发生,那么处理 事件是耗时的,此时如果有accept请求进来 就无法 处理链接请求
3.3.2 单Reactor多线程

优点:可以充分利用多核CPU的能力;
缺点:多线程数据共享和访问比较复杂,reactor依旧是单线程去处理所有的事件监听和响应,在高并发下依旧存在性能问题。
3.3.3 主从Reactor 多线程(或者一主多从Reactor)

3.4 原理图
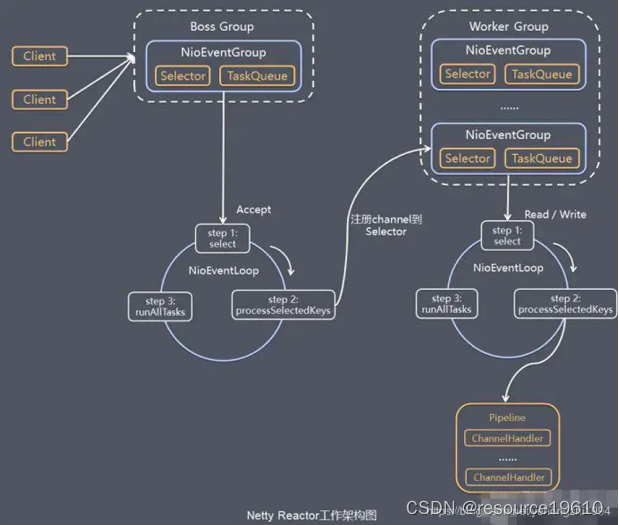
- 有两组线程BoosGroup和WorkerGroup,BoosGroup线程主要是复制客户端建立连接,WorkerGroup中的线程专门负责处理连接上的读写。
- BoosGroup和WorkerGroup含有多个不断循环的执行事件处理的程序,每个线程都包含一个Selector,用监听注册在其上的Channel。
- 每个BoosGroup中的线程执行以下三个步骤
- 每个WorkerGroup中的线程执行以下三个步骤
4.netty 问题以及解决方案
4.1粘包,半包
4.1.1发生原因
client和server 端通信会有 一对 socket套接字,两端都有套接字缓冲区
什么粘包,半包问题?
两批数据 abc def ,收到结果 abcdef 就是粘包问题,收到 ab cd ef 就是半包问题
粘包发生的原因:
- 发送方套接字缓冲区bytebuffer 过大,实际发送数据远 < bytebuffer 长度
- 接收方处理不及时且 bytebuffer 长度很大,且在当前滑动窗口期间
半包原因:
- 发送方bytebuffer < 实际发送数据
- 接收方当前滑动窗口剩余 长度 < 发送方发送的数据
4.1.2解决方案

1.短链接
有很多缺点,效率不高,频繁创建连接带来成本较大
- 定长解码器 FixedLengthFrameDecoder(固定长度)
消息长度不够 补位到固定长度
缺点: 增加消息体积,如果每次实际数据比较小,则数据有效率不高,浪费空间
- 行解码器 LineBasedFrameDecoder(匹配分隔符)
设置最大长度,以分隔符分割文本(比如使用:\r\n 分割数据)
缺点: 每次都要逐一匹配分割符,效率低
- LET 解码器 LengthFieldBasedFrameDecoder
每个消息体有个长度字段,记录消息头长度 ,总长度
/**
* 基于长度字段帧的解码器
*
* maxFrameLength: 帧的最大长度,如果超出此长度会抛出TooLongFrameException异常
* lengthFieldOffset: 长度字段偏移量,(即偏移多少可以读到长度)
* lengthFieldLength: 长度字段长度,(长度有多少个字节)
* lengthAdjustment: 长度字段为基准,还有多少字节内容
* initialBytesToStrip: 从头去除几个字节,(例如,长度是4个字节,去除长度,则值为4)
*/
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip){}
复制代码
4.1.3netty解决方案
Netty 对三种常用封帧方式的支持

使用 LengthFieldBasedFrameDecoder 实现了 ByteToMessageDecoder
4.1.3.1两次解码
一次解码: ByteToMessageDecoder
io.netty.buffer.ByteBuf (原始数据流)-> io.netty.buffer.ByteBuf (用户数据)
二次解码: MessageToMessageDecoder
io.netty.buffer.ByteBuf (用户数据)-> Java Object
一次解码 是 解决 “粘包半包问题”,二次解码将 byte 转换为我们 的 java对象
4.1.3.2解码中两种数据累加器(cumulator)的区别
MERGE_CUMULATOR
内存复制,然后扩容,追加数据
COMPOSITE_CUMULATOR
组合非内存复制,先扩容,如果数据空间够了,直接追加
4.1.4 Google ProtoBuf
4.1.4.1 netty 编解码的缺点
- netty使用java 序列化技术,效率不高
- 序列化后体积大
- 无法跨语言
4.1.4.2 ProtoBuf优缺点
- 跨平台,跨语言
- 轻量级,体积小
- 但是 可读性差
4.2 内存优化
参考:
内存优化:https://blog.csdn.net/m0_69860228/article/details/124799080
内存优化:https://blog.csdn.net/agonie201218/article/details/113687318?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2aggregatepagefirst_rank_ecpm_v1~rank_v31_ecpm-1-113687318-null-null.pc_agg_new_rank&utm_term=netty%E9%9B%B6%E6%8B%B7%E8%B4%9D%E6%98%AF%E4%BB%80%E4%B9%88&spm=1000.2123.3001.4430
netty对于bytebuffer 的实现:
- Heap ByteBuf:直接在堆内存分配
- Direct ByteBuf:直接在内存区域分配而不是堆内存,也可叫堆外内存 //使用mmap技术
- CompositeByteBuf:组合Buffer,不拷贝数据,扩容数据,组合内存 //使用mmap技术
对于文件传输的实现可沿用 Java Nio 的 transferTo()方法
FileChannel.transferTo() //使用 sendFile技术
4.2.1 传统IO的调用流程

这种方式需要四次数据拷贝和四次上下文切换:
- 数据从磁盘读取到内核的read buffer
- 数据从内核缓冲区拷贝到用户缓冲区
- 数据从用户缓冲区拷贝到内核的socket buffer
- 数据从内核的socket buffer拷贝到网卡接口的缓冲区
4.2.2 DirectByteBuffer(直接内存,堆外内存)(底层mmap技术)(继承MappedByteBuffer)

Netty的接收和发送都采用DIRECT BUFFERS,对应系统底层的mmap机制.
Linux提供的mmap系统调用, 它可以将一段用户空间内存映射到内核空间, 当映射成功后, 用户对这段内存区域的修改可以直接反映到内核空间;同样地, 内核空间对这段区域的修改也直接反映用户空间。正因为有这样的映射关系, 就不需要在用户态(User-space)与内核态(Kernel-space) 之间拷贝数据, 提高了数据传输的效率,这就是内存直接映射技术。
4.2.3 CompositeByteBuf(组合内存)
参考:
CompositeByteBuf:https://blog.csdn.net/youxijishu/article/details/104815309/
**byte[] -> bytebuf转换:**使用已存在的byte[] 做为 ByteBuf的 的变量
String a = "ccc";
byte[] bytesSrc = a.getBytes(CharsetUtil.UTF_8);
ByteBuf byteBuf = Unpooled.wrappedBuffer(bytesSrc);
byteBuf.writeBytes(bytesSrc);
多个ByteBuf组合:CompositeByteBuf
String a = "ccc";
String b = "dddd";
ByteBuf buf1 = Unpooled.wrappedBuffer(a.getBytes(CharsetUtil.UTF_8));
ByteBuf buf2 = Unpooled.wrappedBuffer(b.getBytes(CharsetUtil.UTF_8));
ByteBuf compositeByteBuf = Unpooled.wrappedBuffer(buf1,buf2);
int size = compositeByteBuf.readableBytes();
byte[] bytes = new byte[size];
compositeByteBuf.readBytes(bytes);
String value = new String(bytes,CharsetUtil.UTF_8);
System.out.println("composite buff result : " + value);
JVM内存不足,不能加载太大数据
CompositeByteBuf并没有真正将多个Buffer组合起来,而是保存了它们的引用,从而避免了数据的拷贝,实现了零拷贝。
它就像一个容器一样,里面可以包括多个ByteBuf,它是也ByteBuf接口的实现之一。
4.2.4 transferTo

- transferTo方法调用触发DMA引擎将文件上下文信息拷贝到内核缓冲区。
- 数据不会被拷贝到套接字缓冲区,只有数据的描述符(包括数据位置和长度)被拷贝到套接字缓冲区。DMA 引擎直接将数据从内核缓冲区拷贝到协议引擎,这样减少了最后一次需要消耗CPU的拷贝操作。
从一个FileChannel 拷贝 到另一个 FileChannel
- 文件较大,读写较慢,追求速度
- JVM内存不足,不能加载太大数据
- 内存带宽不够,即存在其他程序或线程存在大量的IO操作,导致带宽本来就小
4.2.5 mmap的优缺点
优点:
- **对垃圾回收停顿的改善。**因为full gc时,垃圾收集器会对所有分配的堆内内存进行扫描,垃圾收集对Java应用造成的影响,跟堆的大小是成正比的。过大的堆会影响Java应用的性能。如果使用堆外内存的话,堆外内存是直接受操作系统管理。这样做的结果就是能保持一个较小的JVM堆内存,以减少垃圾收集对应用的影响。(full gc时会触发堆外空闲内存的回收。)
- 减少内存copy 与cpu上下文切换
- 可以突破JVM内存限制,操作更多的物理内存。
缺点:
- 不易回收
- 堆外内存只能通过序列化和反序列化来存储,保存对象速度比堆内存慢,不适合存储很复杂的对象。一般简单的对象或者扁平化的比较适合。
- 申请直接内存 速度 低于 堆内存
4.2.6直接内存回收
调用Unsfe类 的 free() 方法