她犹豫了一下说道:你能不能带我活着出去,我在这个荒野上已经一无所有了,能依靠的只有你..
任小粟摇摇头说道:你并不是一无所有啊
骆磬雨愣住:什么意思?
“你还有脸让我带你活着走出去啊”,任小粟说完就不理骆磬雨了

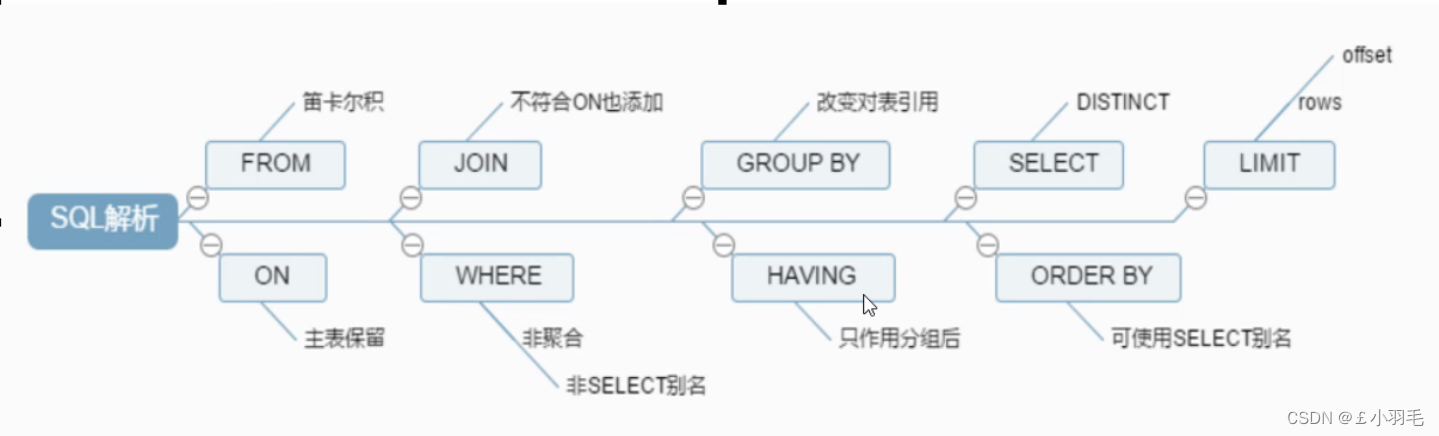
查询模板
1、SQL查询模板
SELECT DISTINCT
<select_list>
FROM
<left_table> <join_type>
JOIN <right_table> ON <join_condition>
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
ORDER BY
<order_by_condition>
LIMIT <limit_number>2、机读顺序

来张鱼骨头,更形象
mysql关心的是原材料,就是这些主人需要的字段,来自哪些表???
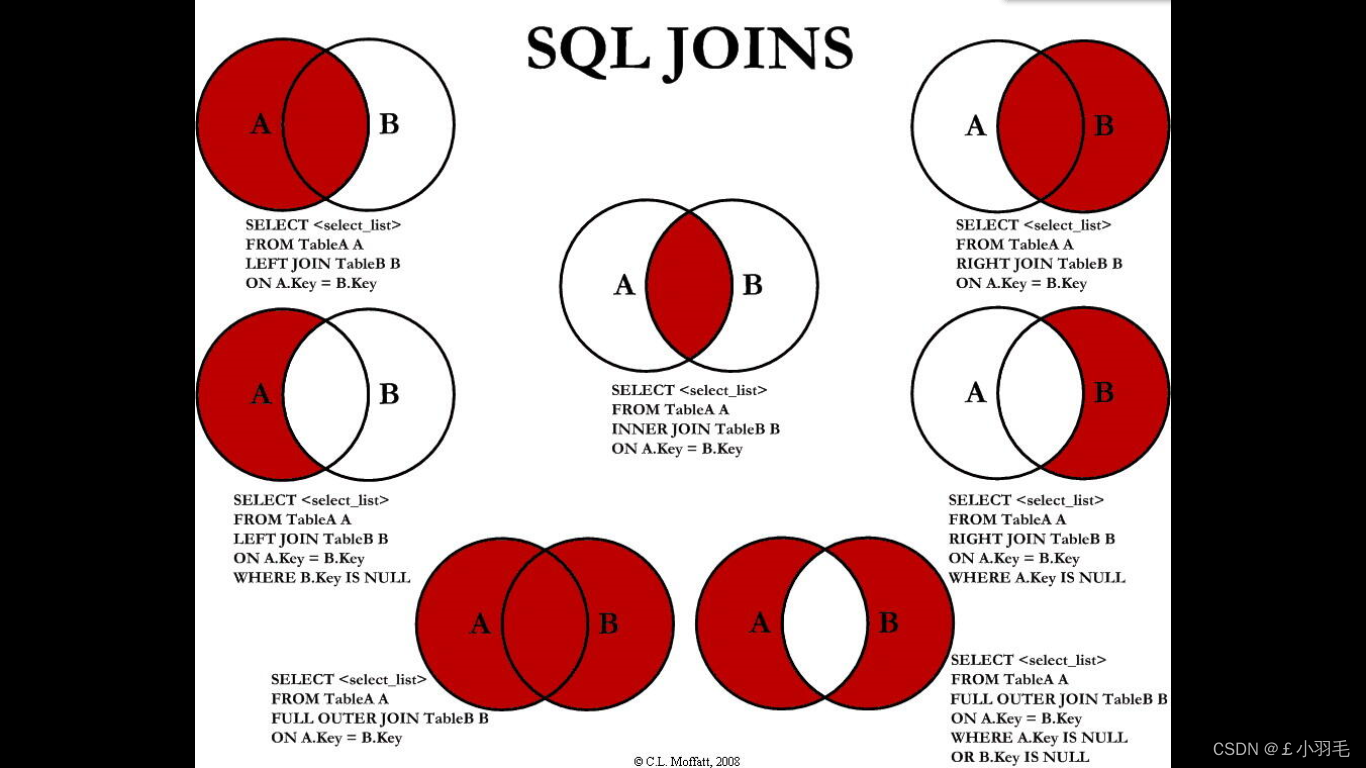
SQL 连接7式
Join 连接的 基本盘
join查询:从单表------》 多表查询。
1.内连接 inner join
2.外连接
左外连接 left outer join
右外连接 right outer jon
Join图
现在看着是把我吓到了,希望以后看着很小case
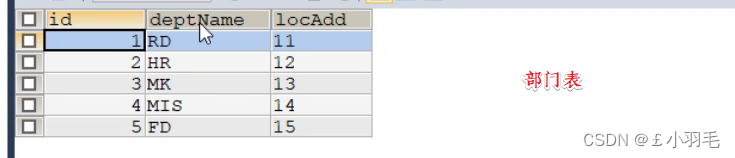
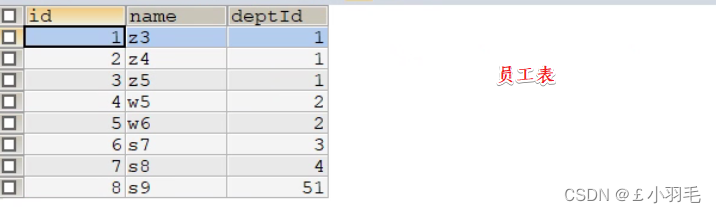
准备工作
建表sql
CREATE TABLE `tbl_dept` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `deptName` VARCHAR(30) DEFAULT NULL, `locAdd` VARCHAR(40) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; CREATE TABLE `tbl_emp` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `name` VARCHAR(20) DEFAULT NULL, `deptId` INT(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `fk_dept_id` (`deptId`) #CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `tbl_dept` (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; INSERT INTO tbl_dept(deptName,locAdd) VALUES('RD',11); INSERT INTO tbl_dept(deptName,locAdd) VALUES('HR',12); INSERT INTO tbl_dept(deptName,locAdd) VALUES('MK',13); INSERT INTO tbl_dept(deptName,locAdd) VALUES('MIS',14); INSERT INTO tbl_dept(deptName,locAdd) VALUES('FD',15); INSERT INTO tbl_emp(NAME,deptId) VALUES('z3',1); INSERT INTO tbl_emp(NAME,deptId) VALUES('z4',1); INSERT INTO tbl_emp(NAME,deptId) VALUES('z5',1); INSERT INTO tbl_emp(NAME,deptId) VALUES('w5',2); INSERT INTO tbl_emp(NAME,deptId) VALUES('w6',2); INSERT INTO tbl_emp(NAME,deptId) VALUES('s7',3); INSERT INTO tbl_emp(NAME,deptId) VALUES('s8',4); INSERT INTO tbl_emp(NAME,deptId) VALUES('s9',51);建完表的效果
------------------
1、第一式:内连接
inner关键字可以省略不写
#内连接 查询A,B俩表共有
SELECT * FROM tbl_emp a INNER JOIN tbl_dept b ON a.`deptId`= b.`id`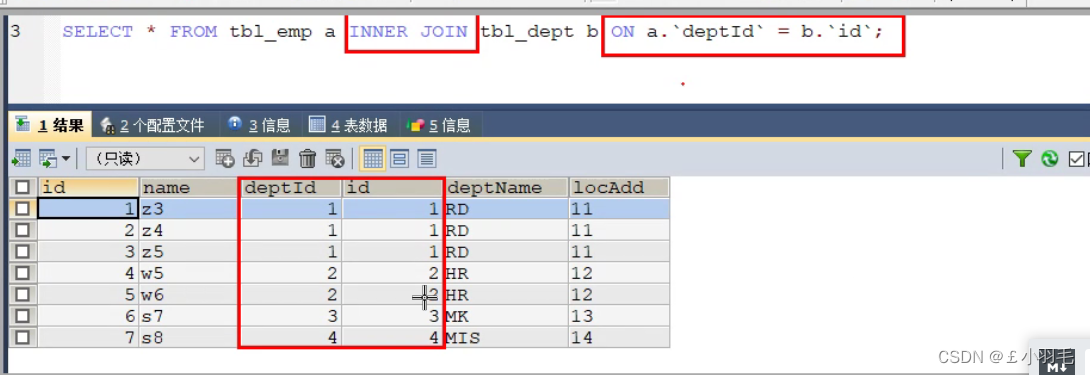
2、第二式:左外连接(左连接)
AB共有部分+A的独有部分 = 左边表的全部内容
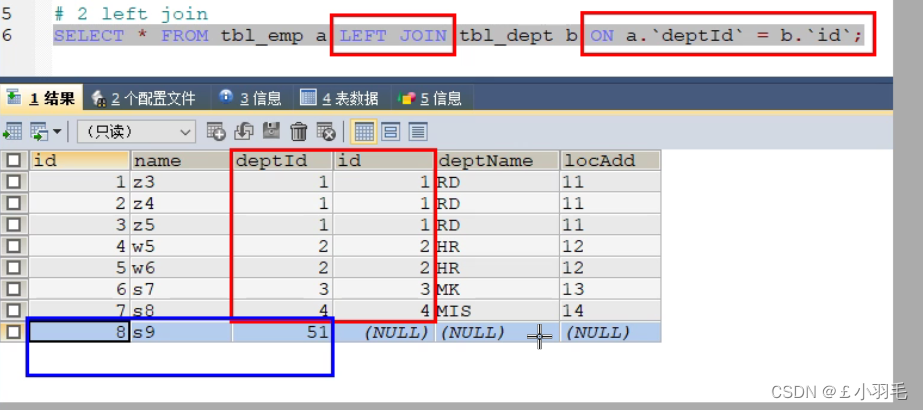
#左连接 查询A独有+AB共有
SELECT * FROM tbl_emp a LEFT JOIN tbl_dept b ON a.`deptId`= b.`id`左边有,但是右边无,如何保证匹配,右边用null补齐
3、第三式:右外连接(右链接)
AB共有部分+B的独有部分 = 右边表的全部内容
join关联的是主外键,跟属性是不是null没关系
#右连接 查询B独有+AB共有
SELECT * FROM tbl_emp a RIGHT JOIN tbl_dept b ON a.`deptId`= b.`id`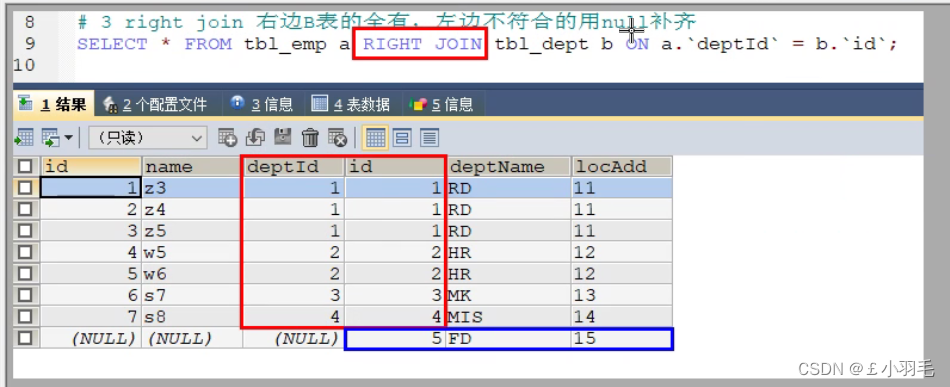
4、第四式:A独有
阳哥口诀:join到头where来补充
分析:
left连接少不了,那中间部分如何扣掉?
什么叫A独有,意思是B就不可再占有,则where B.key is null
#查询A独有
SELECT * FROM tbl_emp a LEFT JOIN tbl_dept b ON a.`deptId`= b.`id` WHERE b.`id` IS NULL;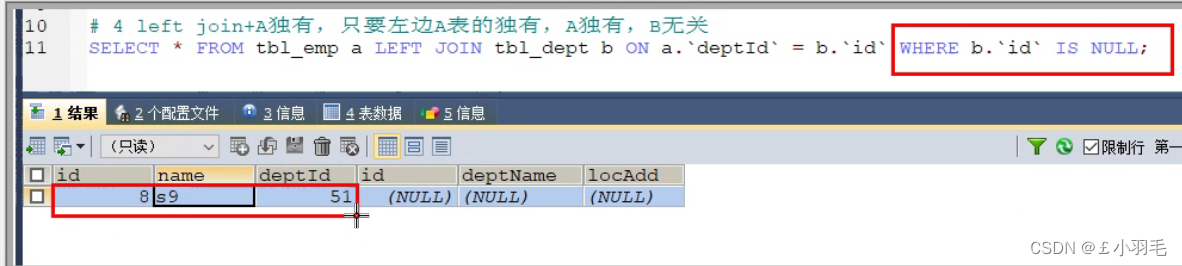
5、第五式:B独有
where A.key is null
#查询B独有
SELECT * FROM tbl_emp a RIGHT JOIN tbl_dept b ON a.`deptId`= b.`id` WHERE a.`deptId` IS NULL;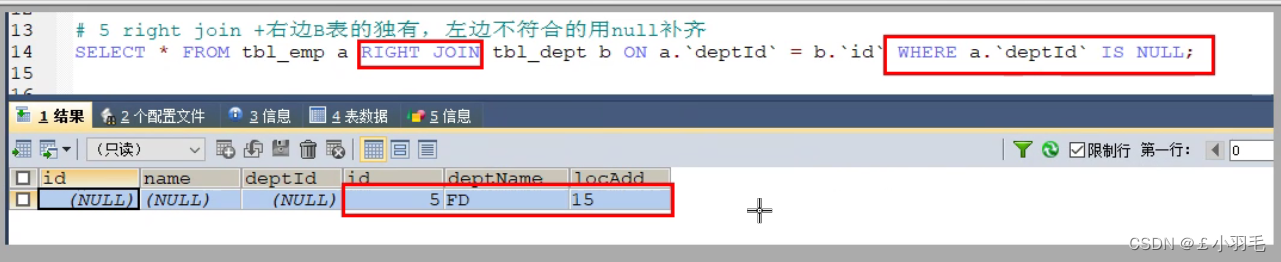
6、第六式:AB全有
full outer join全连接,outer可以省略
#AB全有 SELECT * FROM tbl_emp a FULL JOIN tbl_dept b ON a.`deptId`= b.`id`;在mysql中执行会报错,是因为
mysql产品本身不支持full join这个参数,但是它是规范,没有错误,oracle是支持的。
全集效果:

那在MySQL中怎么实现查询全集效果?
1.左连接+右链接=全连接
2.再需要去掉重复的部分。
MySQL里面合并去重,有什么功能支持??
- UNION 合并去重
- UNION ALL 只合并不去重
#AB全有,mysql中不支持FULL JOIN,下面是替代方法
SELECT * FROM tbl_emp A LEFT JOIN tbl_dept B ON A.deptId = B.id
UNION
SELECT * FROM tbl_emp A RIGHT JOIN tbl_dept B ON A.deptId = B.id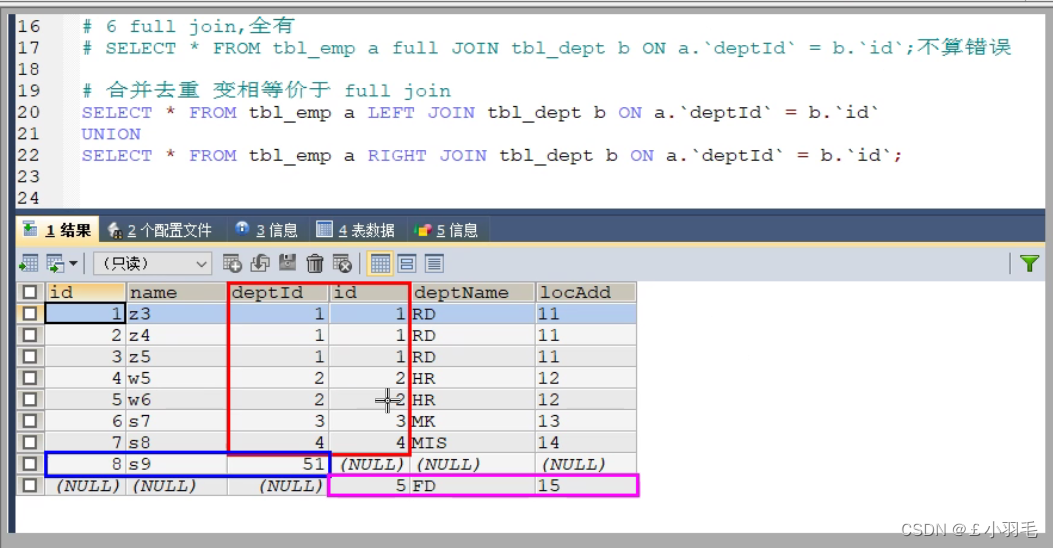
7、第七式:A独有+B独有
A全有的基础+
WHERE A.key is NULL or B.key IS NULL
但是mysql不支持 full join ,我们就选择把A独有+B独有,合并
#A独有+B独有
SELECT * FROM tbl_emp A LEFT JOIN tbl_dept B ON A.deptId = B.id WHERE B.`id` IS NULL
UNION
SELECT * FROM tbl_emp A RIGHT JOIN tbl_dept B ON A.deptId = B.id WHERE A.`deptId` IS NULL;
请画出3张表的join关系?
你不会画成这样吧

其实,3张表的join跟2张表的join是一样的,

理由如下:
2张表join后会得到一个临时表,这张新表再和第3张表join,巧妙避免了问题复杂化
SQL编程
sql除了增删改查等基本操作命令,是否可以像java一样,编程开发。有,这个东西就叫脚本!
1、开启白名单信任功能
mysql牛X的地方,是安全+稳定。在使用我们自定义的函数之前要开启这个白名单
1.查看是否开启白名单
-- 查看是否开启白名单 show variables like 'log_bin';

2.开启白名单
-- 查看 SHOW VARIABLES LIKE 'log_bin_trust_function_creators'; -- 开启 SET GLOBAL log_bin_trust_function_creators=1;开启后查看,效果如下:

2、变更当行结束符
mysql编程中,让多条sql作为一个整体同时来执行,就是一个大行,所以,原有的“;”作为结束符,不再合适。
将原来;修改$$, 由两个$$作为行的行结束符
让msyql知道,碰上了;,不代表结束
此时;只是一条普通的sql语句,从而达到,多条sql整体执行的效果
界定符$$:走到哪结束呢?走到他找到自定义的界定符结束。
DELIMITER $$
CREATE PROCEDURE select_data()
BEGIN
SELECT * FROM emp ORDER BY ename LIMIT 5;
END $$
DELIMITER ;
DELIMITER ;// 就是说执行完了再改回以 分号; 结束
3、函数
类比于创建表,就能知道怎么创建函数和存储过程了
| 创建表 | create table |
|---|---|
| 创建函数 |
create function |
| 创建存储过程 | CREATE PROCEDURE |
| 创建视图 | create view |
| 创建索引 | create index |
---------------------------
函数:有返回值 的mysql方法,就是函数,如
SELECT NOW();
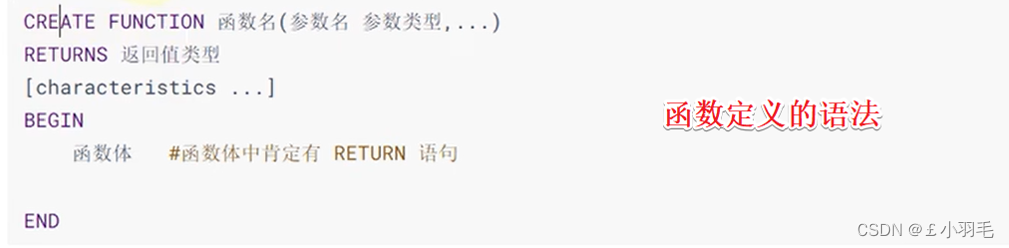
SELECT VERSION();自定义函数语法格式
[characteristics...] 特征/约束条件
取值信息如下:
不管我们不用暂且不管,一会也不会写这个约束条件

自定义函数的创建
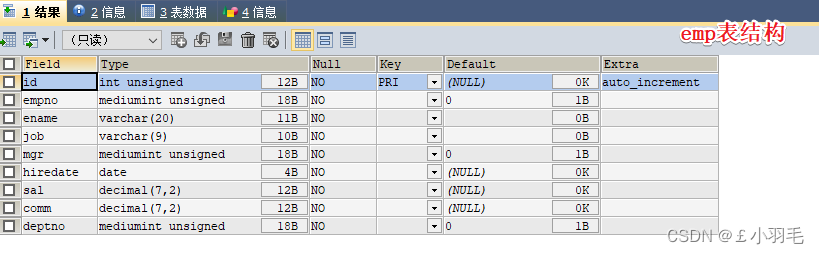
1、查看表结构,DESC emp
2、函数声明 CREATE FUNCTION
参数永远是IN类型的,IN 是什么意思呢?下面存储过程有详细介绍
这里有个要注意的点,不要把函数的参数也写成字段的名 id,这样就会让条件 where id=id;永远成立了
DELIMITER $$
CREATE FUNCTION ename_by_id(eid INT)
RETURNS VARCHAR(20)
BEGIN
RETURN (SELECT ename FROM emp WHERE id=eid);
END $$
DELIMITER ;创建之后,在左边就可以看到了

自定义函数的调用
使用select关键字
#函数调用
SELECT ename_by_id(1);
自定义函数的删除
#函数删除
drop function ename_by_id4、存储过程
存储过程:没有返回值 的mysql方法,就是存储过程
存储过程看中的是丰富的sql逻辑(相比于视图),且没有返回值(相比于函数)
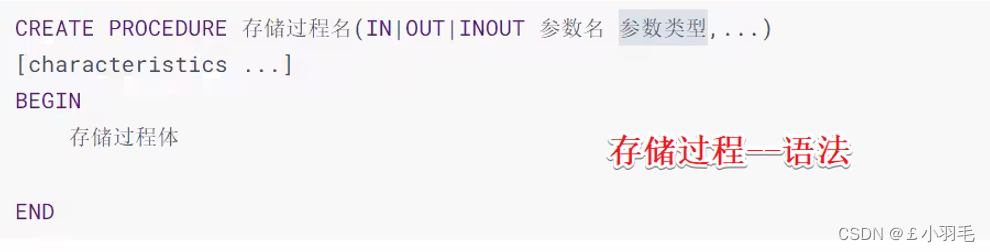
存储过程语法格式
1、参数前面 符号 的意思
IN:当前参数为输入参数; 存储过程只是读取这个参数的值。如果没有定义参数种类,默认就是IN,表示输入参数。
0UT:当前参数为输出参数; 执行完成之后,调用这个存储过程的客户端或者应用程序就可以读取这个参数返回的值了。
IN0UT:当前参数既可以为输入参数,也可以为输出参数。
2、形参类型 可以是MySQL数据库中的任意类型。
1、无参数 的存储过程
看的出来,调用存储过程关键字是 call
DELIMITER $$
CREATE PROCEDURE select_data()
BEGIN
SELECT * FROM emp ORDER BY ename LIMIT 5;
END $$
DELIMITER ;
#存储过程调用
CALL select_data();
#存储过程删除
DROP PROCEDURE select_data调用存储过程后,运行结果如下:
2、IN参数 的存储过程
这里的存储过程的参数名也是不能为ename,注意细节!
DELIMITER $$
#查看某个员工的薪资
CREATE PROCEDURE show_someone_salary(IN emp_name VARCHAR(20))
BEGIN
SELECT sal FROM emp WHERE ename = emp_name;
END $$
DELIMITER ;
#存储过程调用方式1
CALL show_someone_salary('FajUUR');
#存储过程调用方式2
SET @ename='FajUUR';
CALL show_someone_salary(@ename);
#存储过程删除
DROP PROCEDURE show_someone_salary
3、OUT参数 的存储过程
DELIMITER $$
#查看员工表最高工资
CREATE PROCEDURE show_max_salary(OUT ms DECIMAL)
BEGIN
SELECT MAX(sal) INTO ms FROM emp;
END $$
DELIMITER ;
#存储过程调用
CALL show_max_salary(@ms);
#查看变量值
SELECT @ms;
#存储过程删除
DROP PROCEDURE show_max_salary
查看变量结果:

大数据插入mysql脚本
第一步:准备表
把我们要插入大量数据的dept表和emp表先准备好
# 新建库
create database bigData;
use bigData;
#1 建表dept
CREATE TABLE dept(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ENGINE=INNODB DEFAULT CHARSET=utf8;
#2 建表emp
CREATE TABLE emp (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
)ENGINE=INNODB DEFAULT CHARSET=utf8; 第二步: 准备自定义函数
自定义函数:随机产生字符串
DELIMITER $$
#创建函数 rand_string
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
#假如要删除
#drop function rand_string;再写一个函数:用于随机产生部门编号
#用于随机产生部门编号
DELIMITER $$
CREATE FUNCTION rand_num( )
RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(100+RAND()*10);
RETURN i;
END $$
#假如要删除
#drop function rand_num;运行后可以在左侧看到
-------------------
测试该rand_string函数:
#随机生成一个指定长度的字符串 select rand_string(8)$$
---------------
测试rand_num函数:
#随机生成一个100-109的数字 SELECT rand_num()$$



第三步:创建2个存储过程
分别用来给emp表和dept表插入数据
创建给emp表插入数据的存储过程:
DELIMITER $$ CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10)) BEGIN DECLARE i INT DEFAULT 0; #set autocommit =0 把autocommit设置成0 SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO emp (empno, ename ,job ,mgr ,hiredate ,sal ,comm ,deptno ) VALUES ((START+i) ,rand_string(6),'SALESMAN',0001,CURDATE(),2000,400,rand_num()); UNTIL i = max_num END REPEAT; COMMIT; END $$ #删除命令 # DELIMITER ; # drop PROCEDURE insert_emp;
创建给dept表插入数据的存储过程:
#执行存储过程,往dept表添加随机数据 DELIMITER $$ CREATE PROCEDURE insert_dept(IN START INT(10),IN max_num INT(10)) BEGIN DECLARE i INT DEFAULT 0; SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO dept (deptno ,dname,loc ) VALUES ((START+i) ,rand_string(10),rand_string(8)); UNTIL i = max_num END REPEAT; COMMIT; END $$ #删除 # DELIMITER ; # drop PROCEDURE insert_dept;
创建完存储过程后,就可以在左边看到了

第四步:执行存储过程
DELIMITER ;
#给dept表插入数据
CALL insert_dept(100,10);
#给emp表添加50万条数据
CALL insert_emp(100001,500000); 确实慢啊,老师的电脑给emp表添加50万条数据是37s,阳哥说还是5年前的,我的电脑是51s。。。
