数据分析流程
- 建立需求:报告(财报、运营报:公司业务框架;过去)、痛点(当下)、未来;
- 建立与统计的关系:y的量化(业务与统计的桥梁),boss关心的指标;
- X的选择:归因(重要的X→业务;不重要X→非业务);
- 描述:大数据研究行,小数据研究列;
- 预分析
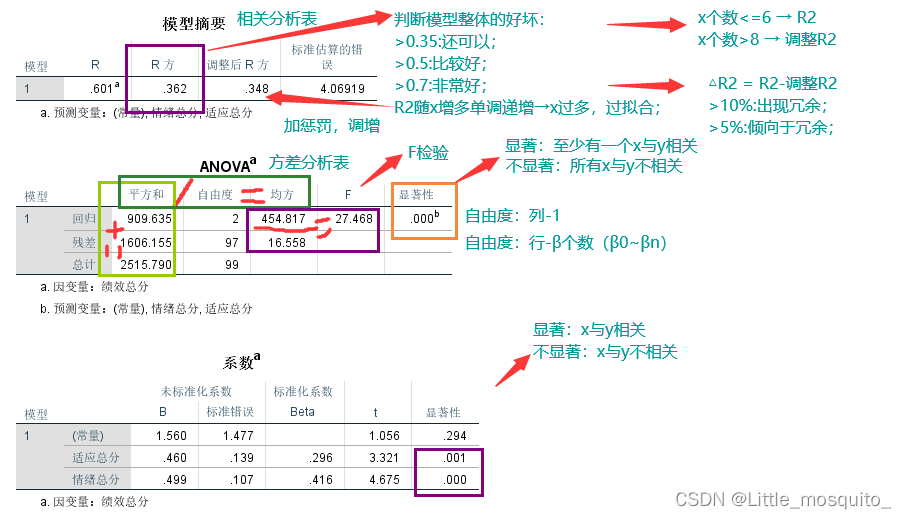
- 建模:模型判定系数:R2(确定性;随机性);
- 模型修正
- 评估:R2→小数据;boss→大数据;
- 应用:归因、预测;
- 可视化
数据分析俩大方向:
- 对客户的数据挖掘
- 机器学习优化
小数据分析重要性:小众>异常>大众;
大数据分析重要性:大众>异常>小众;
数据描述:均值、标准差、最大值、最小值、截距;
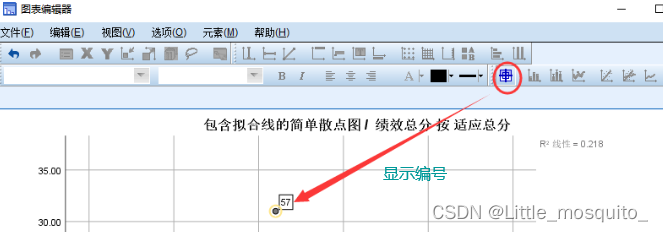
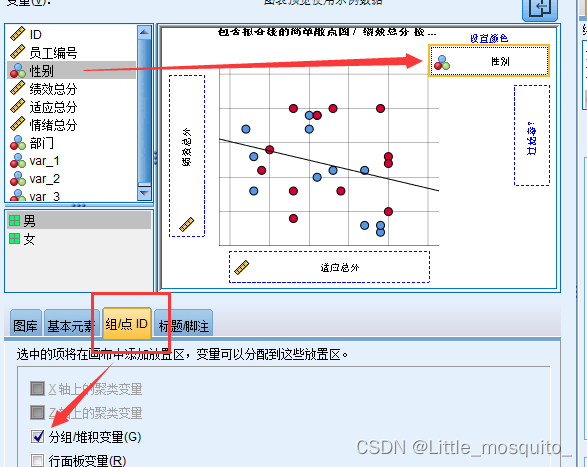
图形:低微探索数据以推演高维;
模型:高维探索数据用低微描述;
一、SPSS建立线性回归模型(建模):
分析 → 回归 → 线性 → 因变量:y(关心的指标);自变量:x(一般把不重要的指标放后面)→ 确定
二、线性回归模型流程
- 图形:散点图(相关、线性趋势、异常);
- 相关性:r(相关系数)→ 删除变量,精简模型(x控制在15个以内);
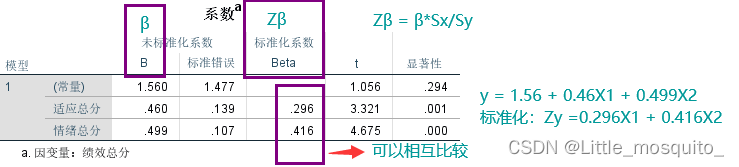
- 构建回归:β→和boos沟通的唯一渠道,强调模型细节; Zβ R2→强调模型整体
- 误差:
- 应用:归因(主次、规则);预测(老样本:內延;新样本:外推);
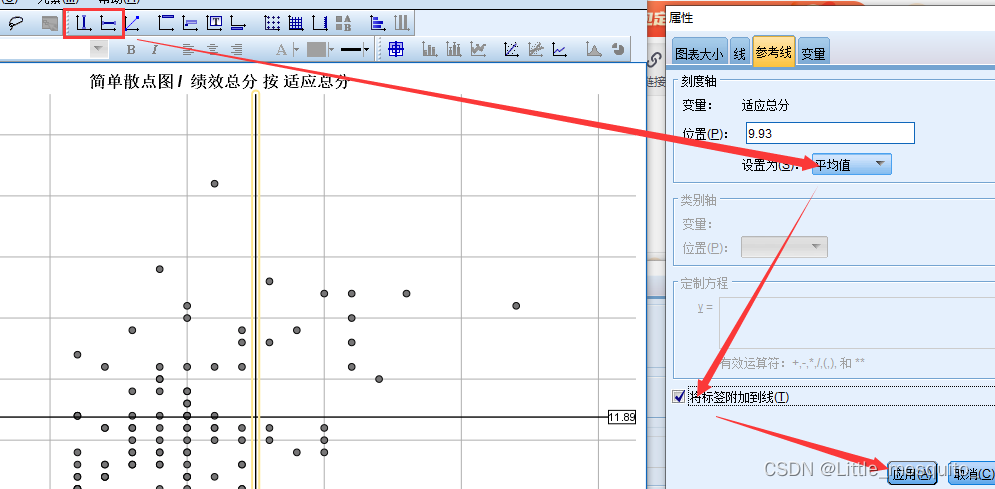
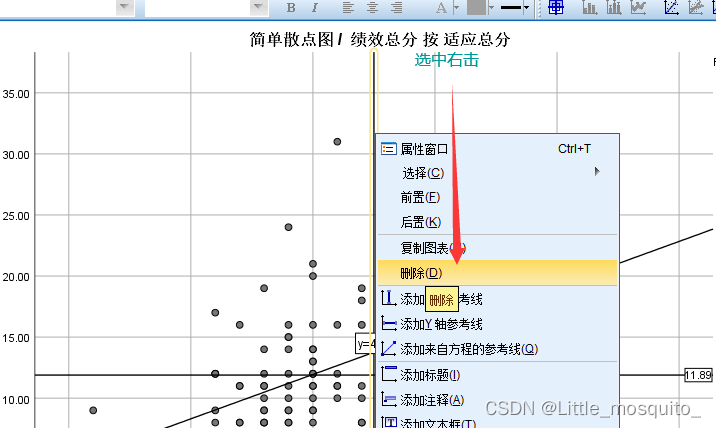
1、图形:y与每个x画散点图
图形→图形构建器→图库→散点图→简单散点图→y:纵坐标;x:横坐标→确定;
2、相关性
2.1、协方差
高尔顿:发明协方差,最大贡献优生学,表哥达尔文,学生皮尔逊(统计学之父);
自己与自己的协方差是方差;
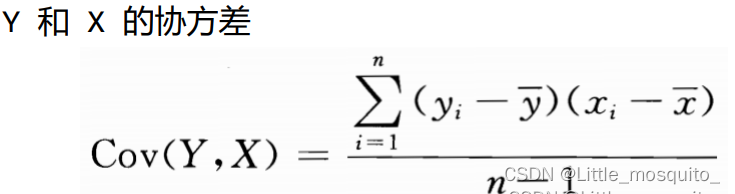
2.2相关系数
分子有差,分母有误差;
皮尔逊相关系数的本质:数据之间的密集程度,>0 正相关,<0 负相关;
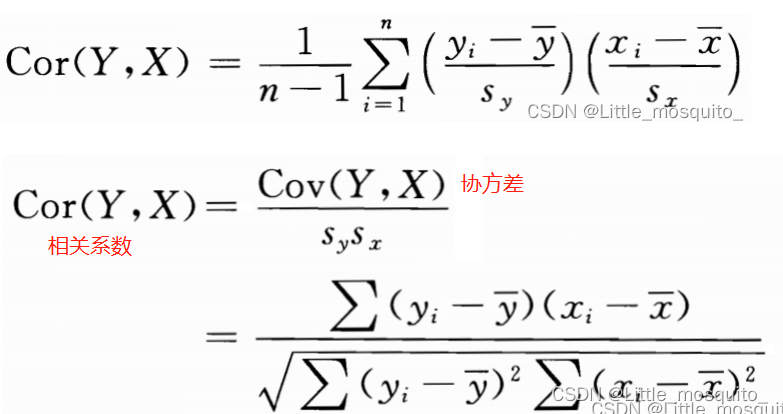
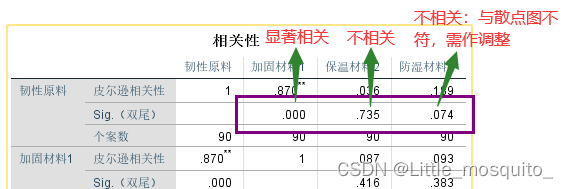
2.3、spss求相关
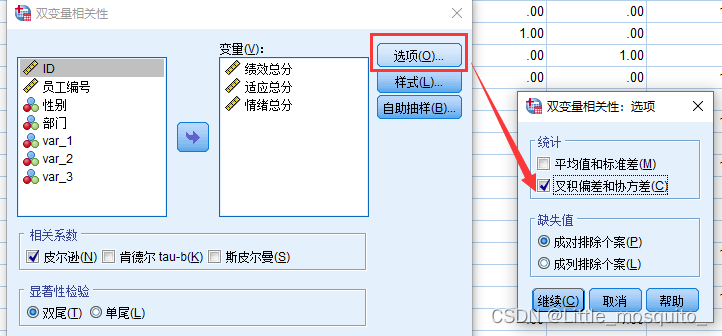
分析→相关→双变量→将x、y放入变量(spss可以一次对所有x与y求相关)→相关系数:皮尔逊→确定;
相关性假设检验:H0:y与x不相关;H1:y与x相关;
假设检验<0.5: 拒绝H0,y与x显著相关;
假设检验>0.5:接受H0,y与x不相关,删除x;
小数据:归因 ; 大数据:不归因(工具归因);
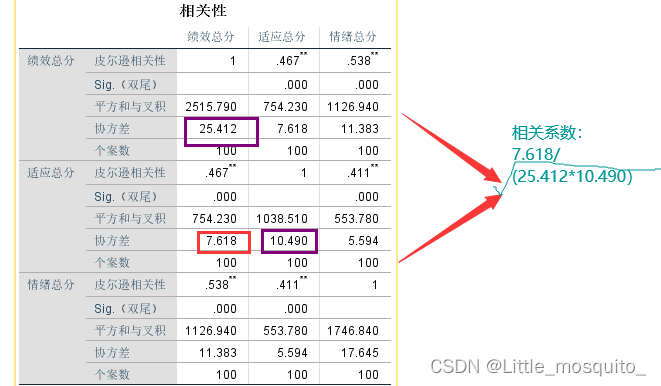
相关系数分类:
3、构建回归
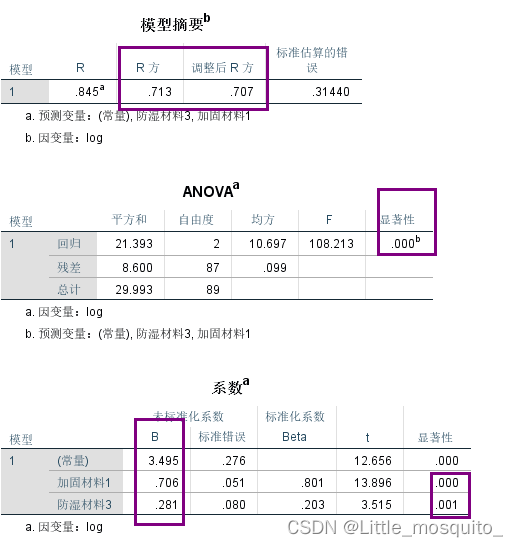
3.1、R2

3.2、spps建回归
分析→回归→线性→应变量:x;自变量:y;→确定;
3.3、回归模型结果解读
R2>0.6,容易过拟合;

4、残差、
回归:向均值回归的现象;
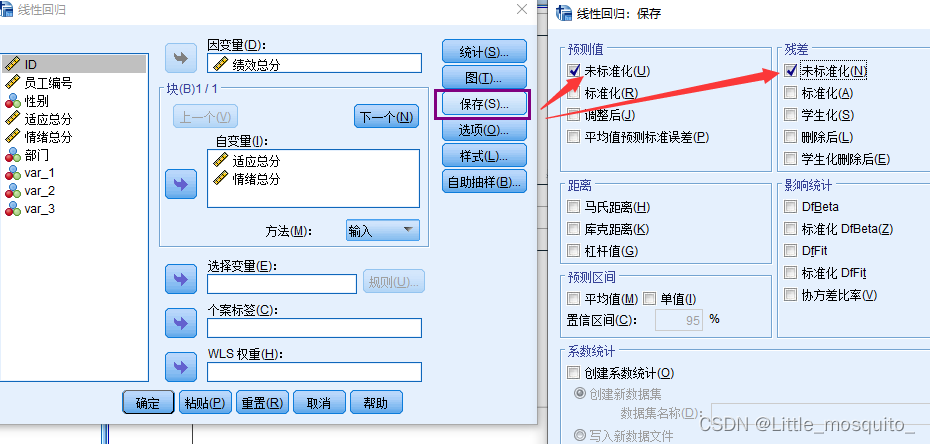
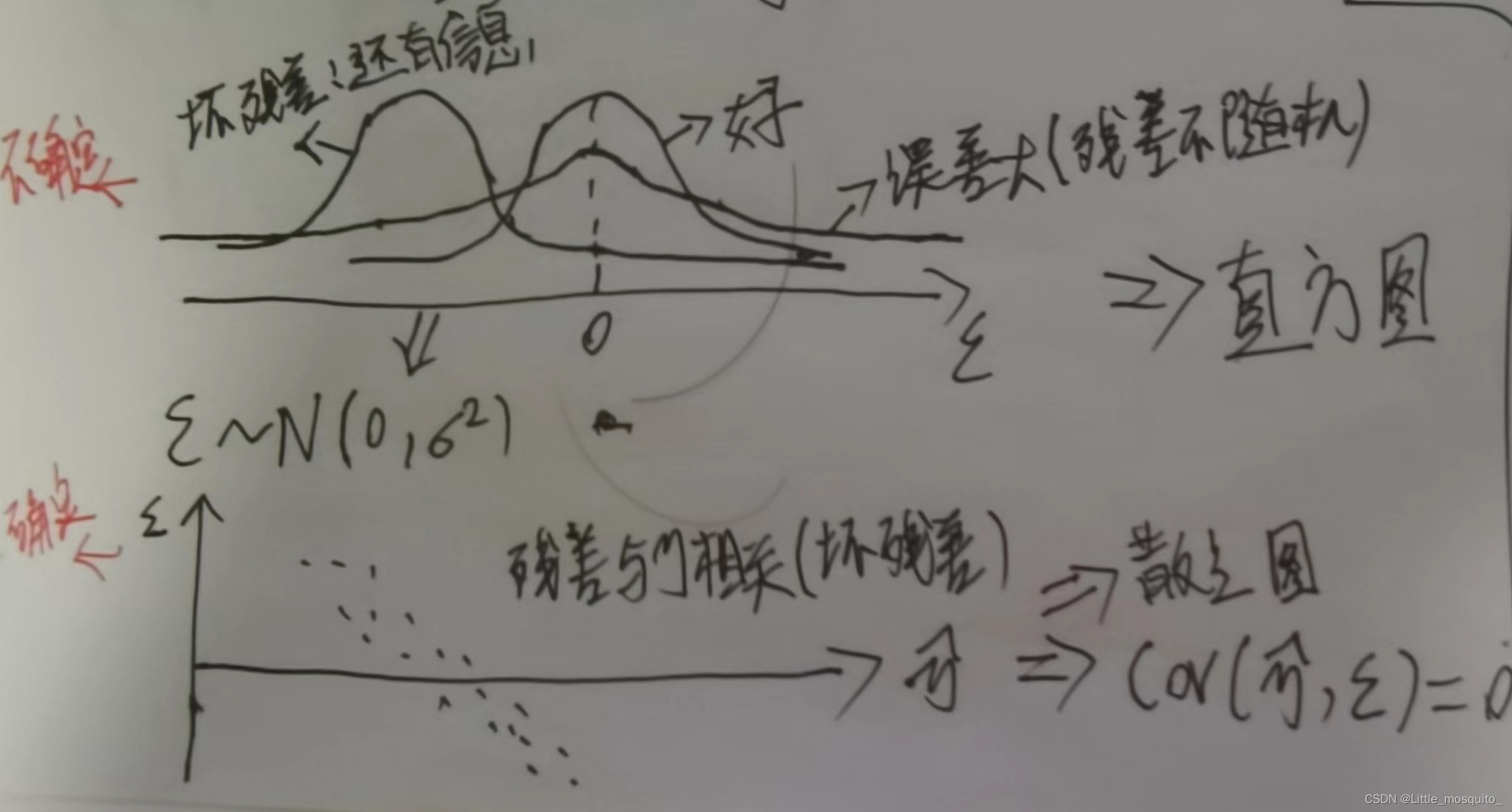
4.1、残差判定
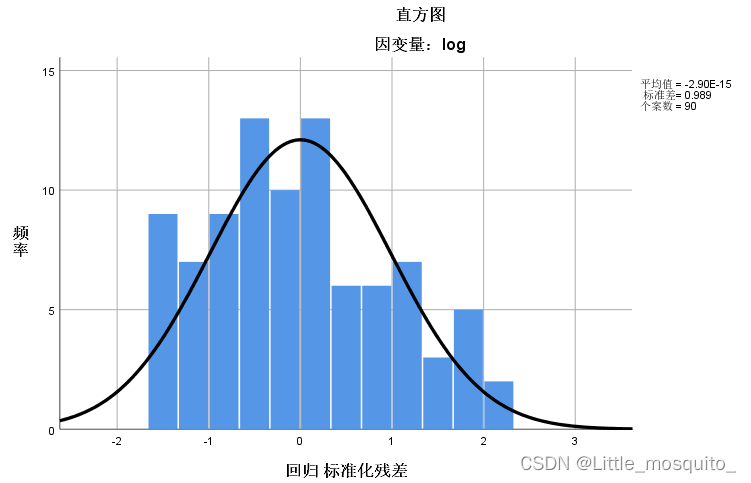
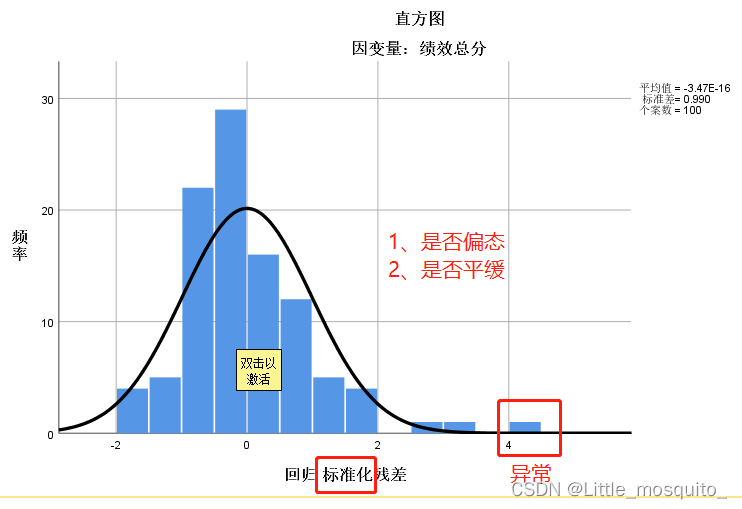
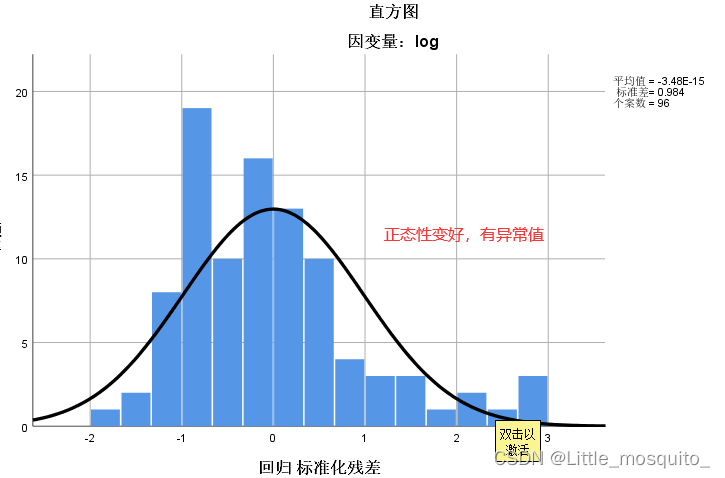
残差服从均值为0的正态分布:残差是否随机; → 通过画直方图判断;
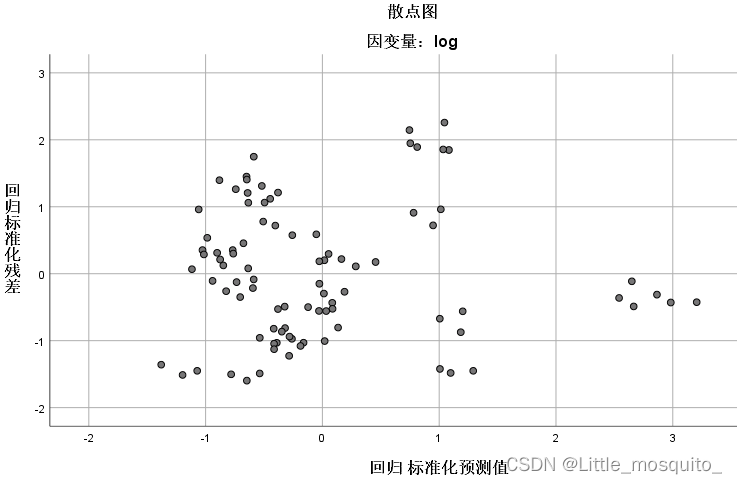
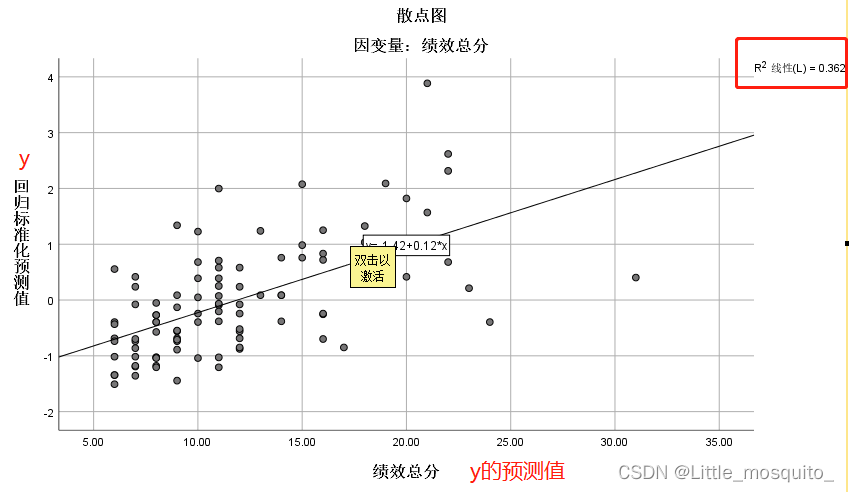
残差与y的预测值不相关:残差是否有确定的东西; → 散点图(y的预测值与残差的协方差等于0);
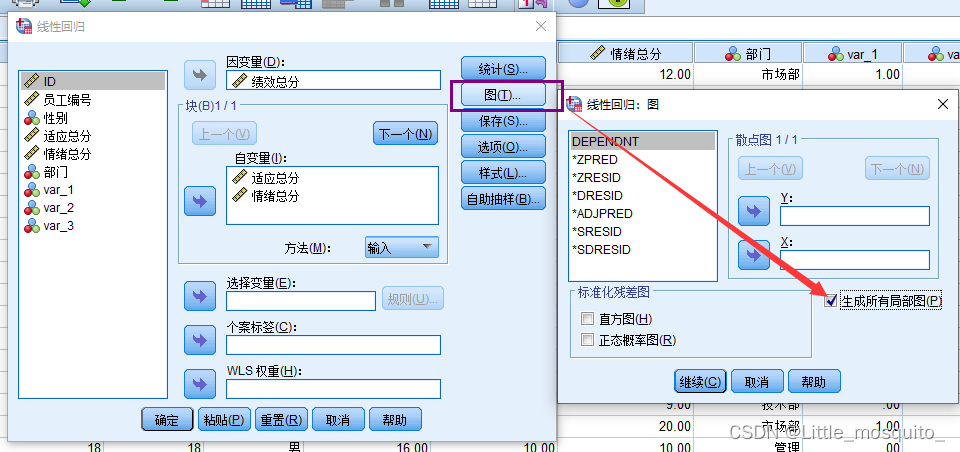
4.2、spss操作
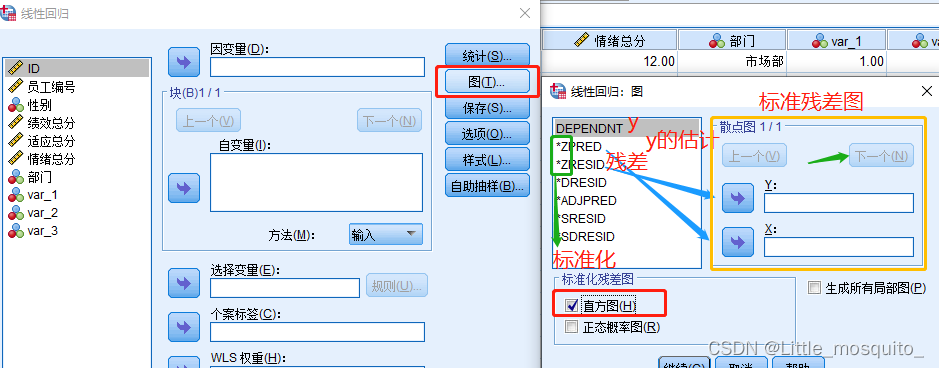
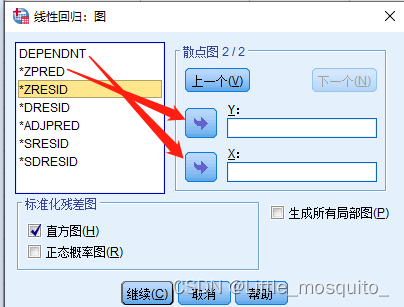
4.3、结果解读
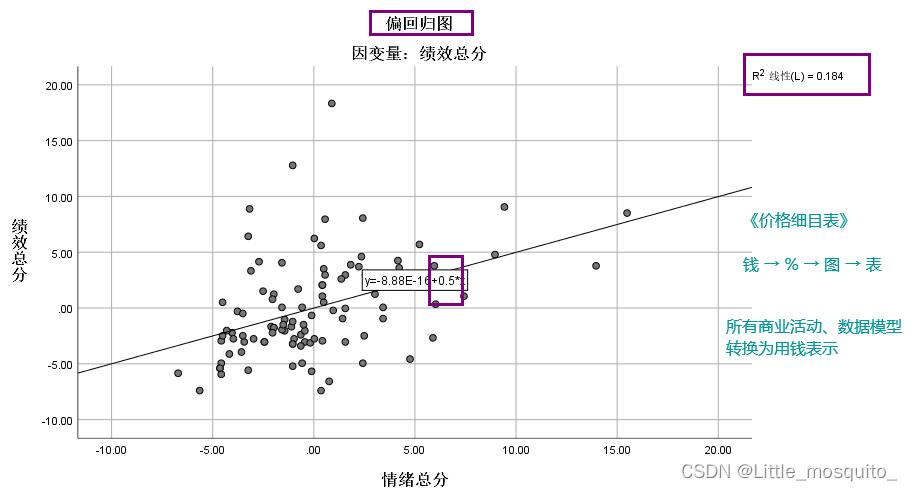
残差分布图
y与y的预测R2图
y的预测与残差散点图;
可以求y的预测与残差相关系数判断是否相关;
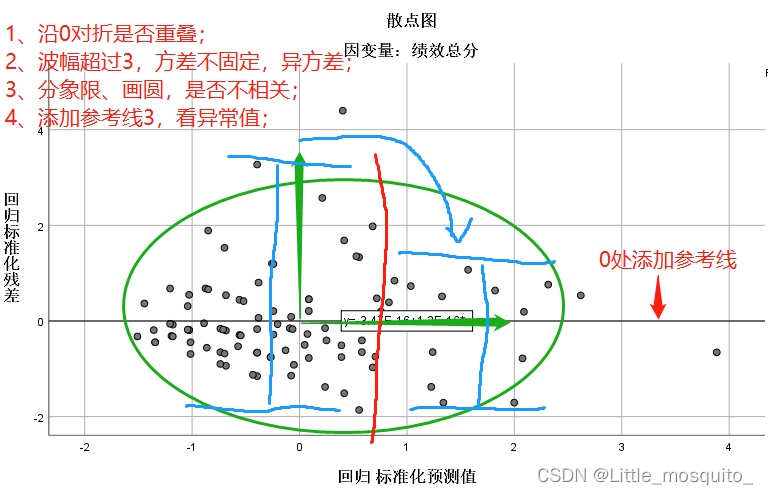
删除俩个异常值,丢失俩行信息,换来更高的准确度;
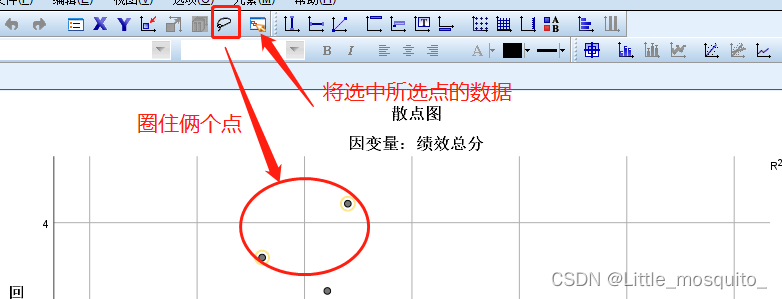
5、模型应用
金融、电商经常做服务器的卡壳分析;
5.1、预测
老样本的预测:内衍; 新样本的预测:外推;
真分数:预测出的值; 实际是带误差的; 相信预测值;
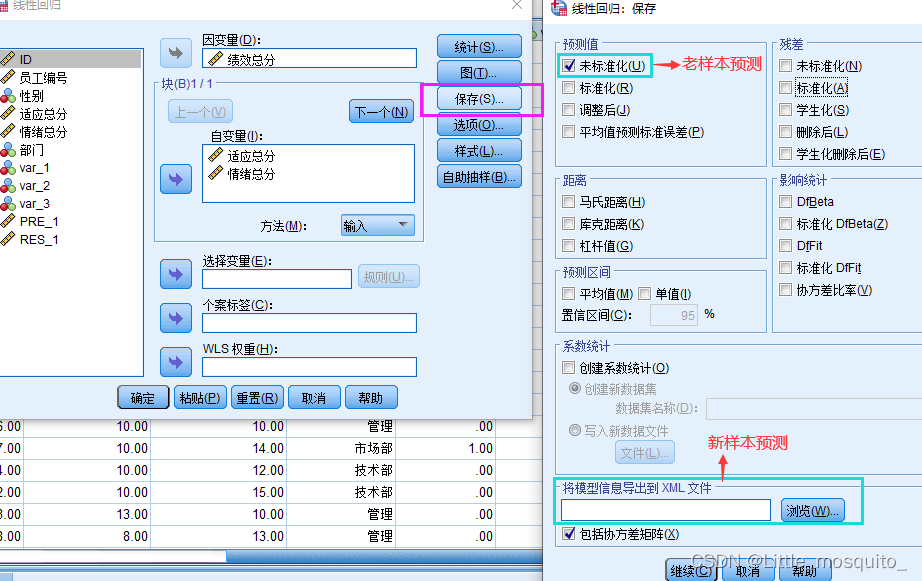
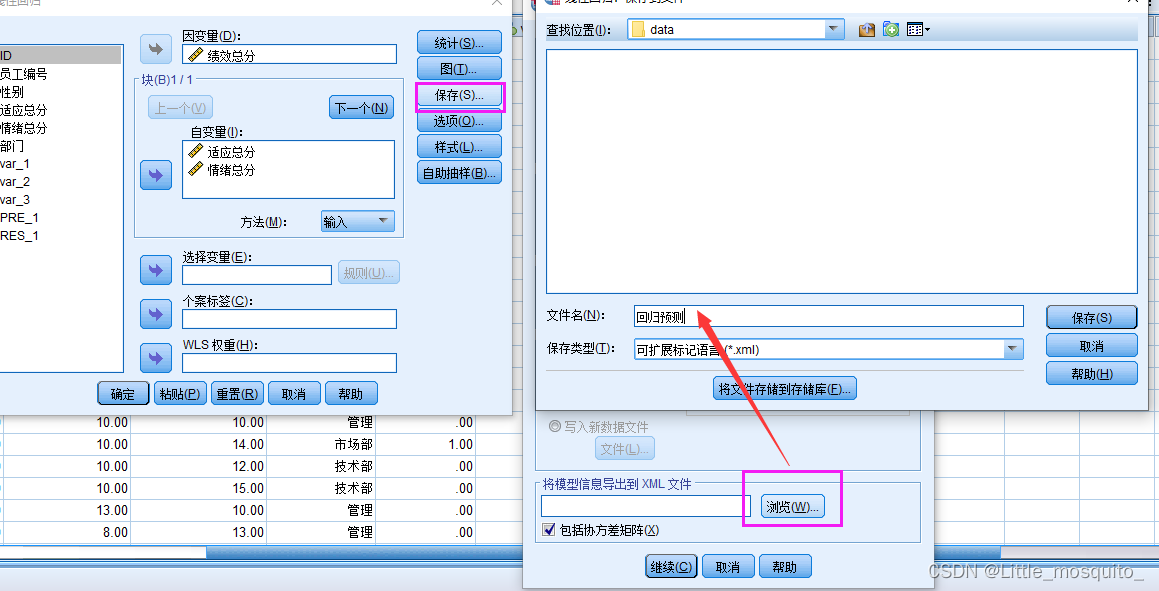
此文件用处:1、新样本预测; 2、软件二次开发;
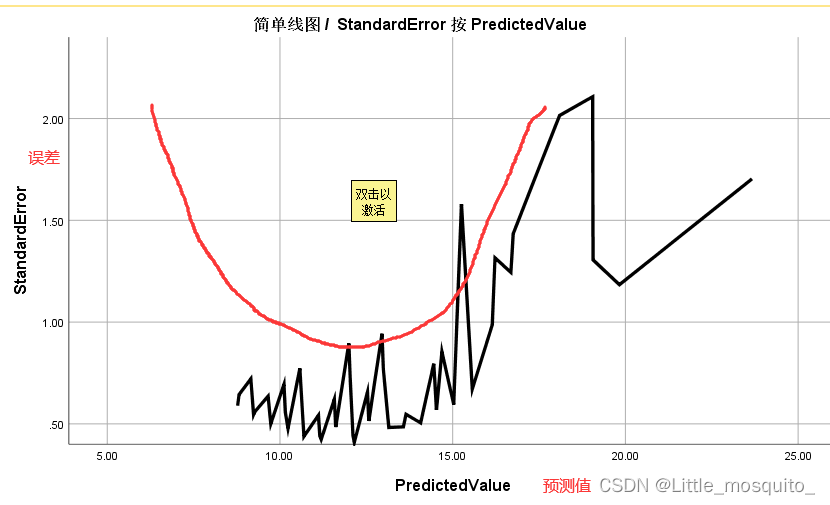
预测值与误差往往呈U型,U型底部为y的均值;
5.2、归因
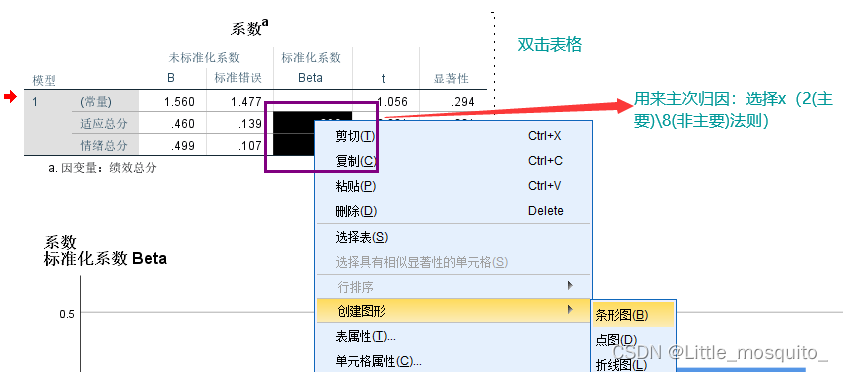
主次归因:主:20%;次:80%;(单个变量)
规则归因:所有x组合发生的概率;(整体)
- 联合分析 小
- 对应分析 小
- 决策树 大
- 贝叶斯 大
三、案例
1、y与x散点图
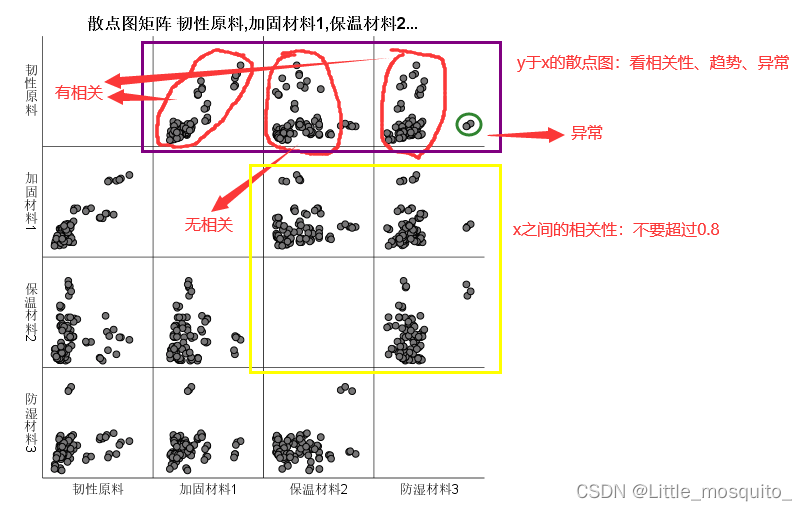
2、求相关
3、构建回归
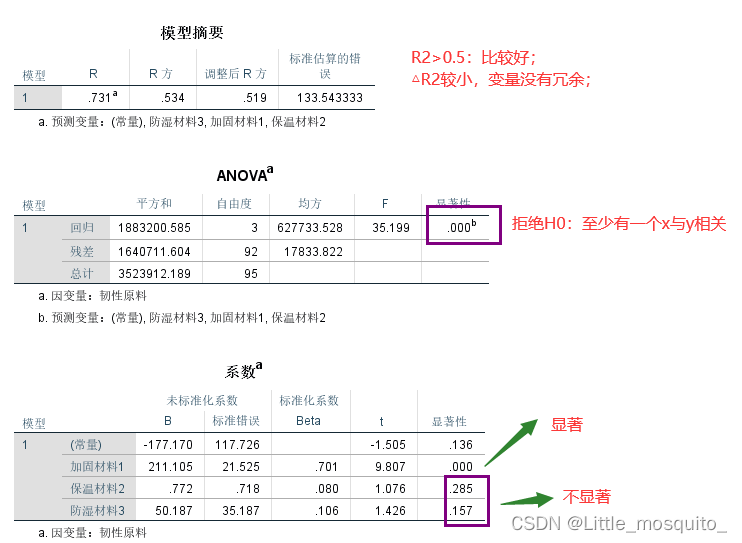
4、残差
五个问题主要的是内生性问题,次要的是异常值问题;
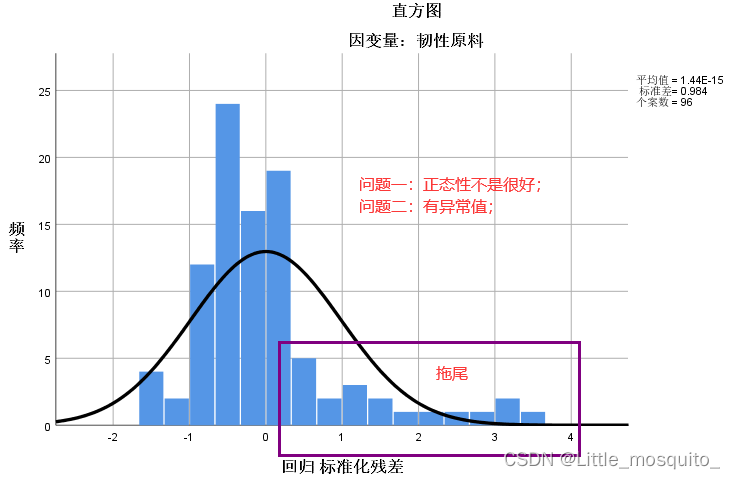
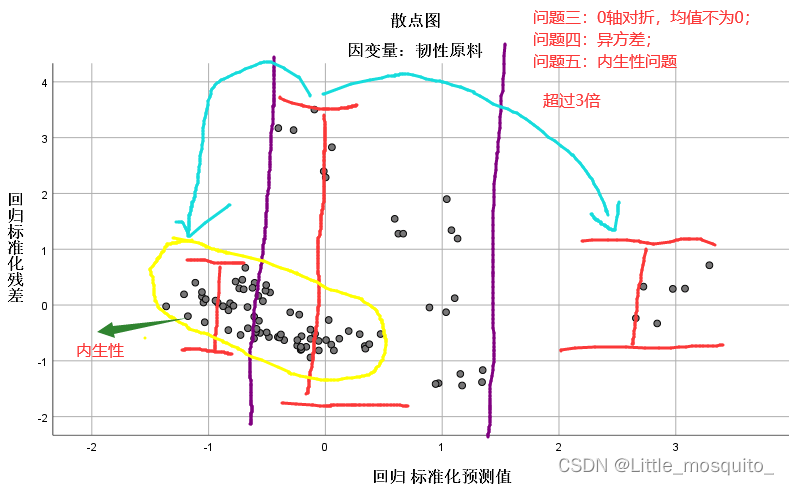
4.1、解决内生性
对y值进行变化(变化只能削弱内生性,不能消除内生性)
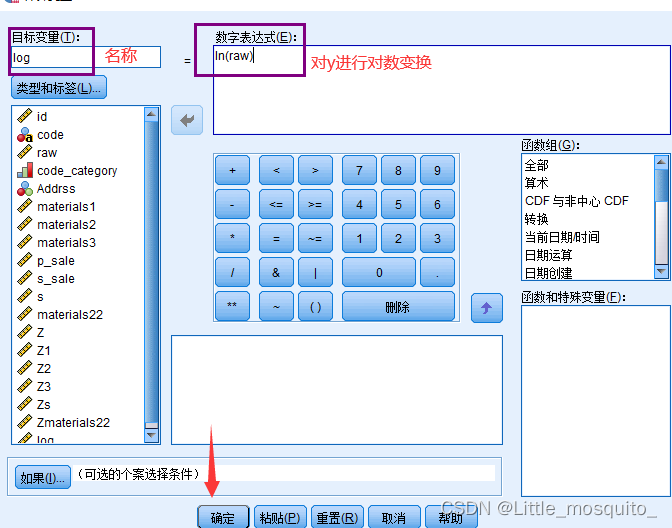
重新建模
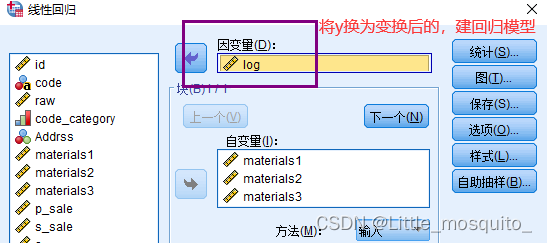
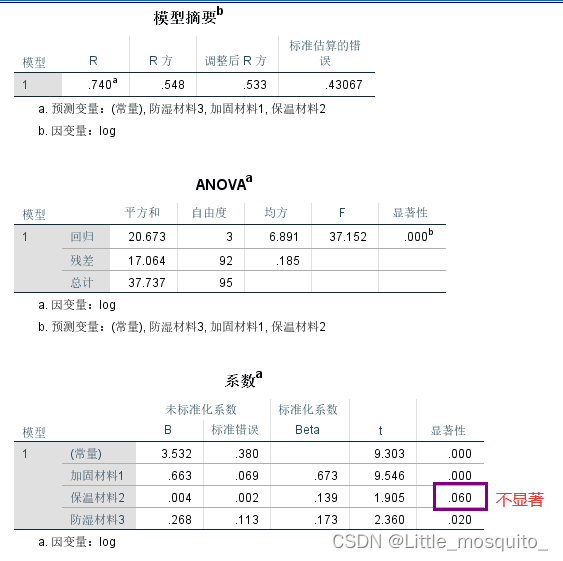
结果解读
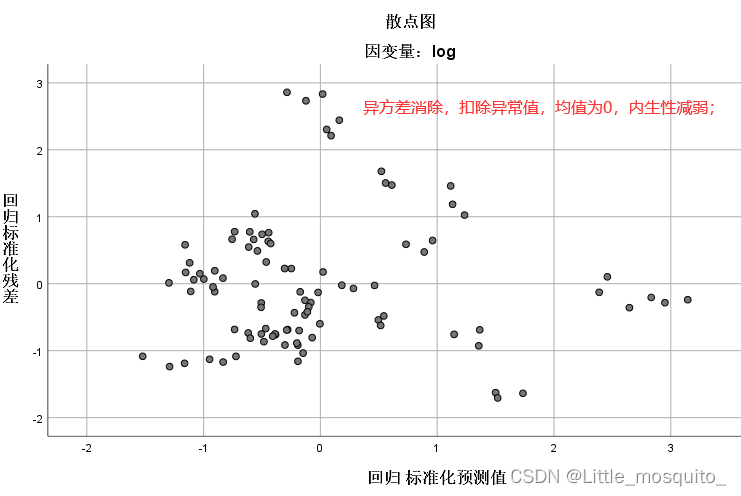
4.2、解决异常值
删掉异常值
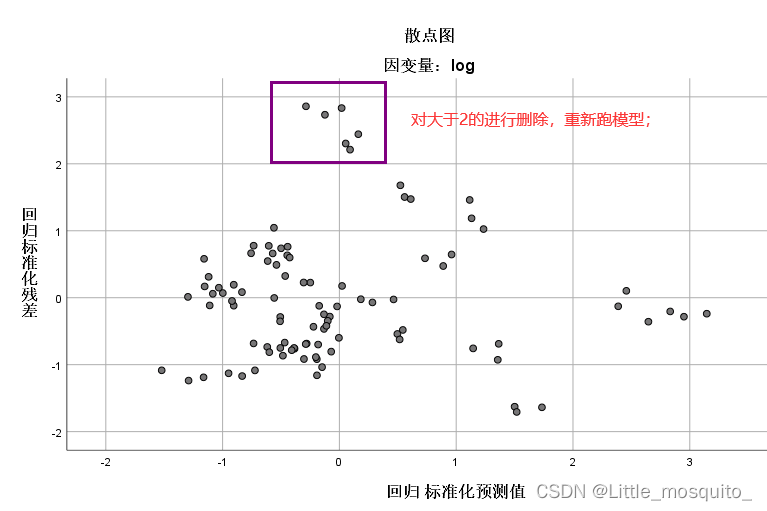
重新跑模型
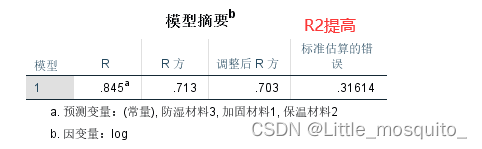
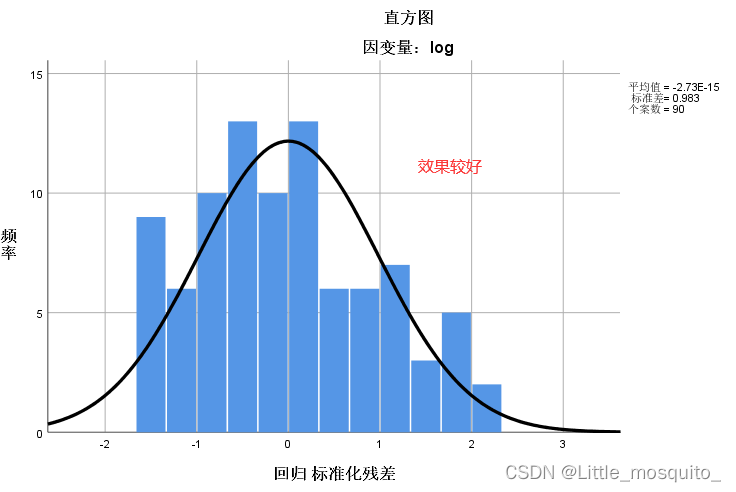
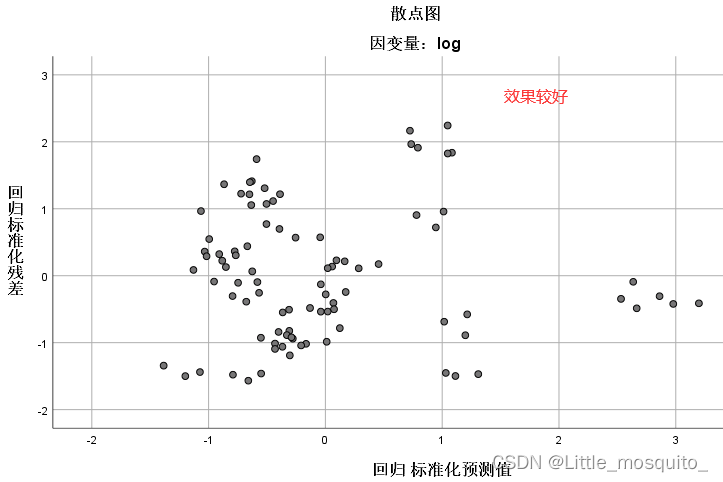
4.3、最终模型
删除不相关变量
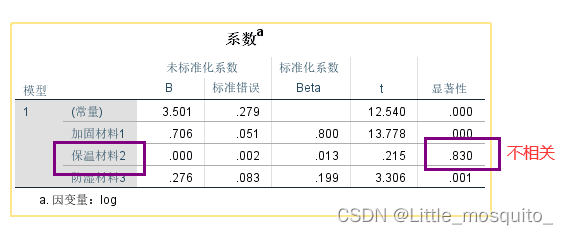
最终结果:广义线性回归模型