上一篇文章针对机床热误差预测建立了回归模型,本篇在原有基础上通过对热误差值进行残差分析,提供一种模型优化思路。
我们都知道,立式加工中心Z向温升增长量测量值,受主轴端面跳动影响,测量值中会带有端面跳动值,若直接测量端面到主轴分析仪的距离,该值是无法避免的,如何通过统计学思想解决由于系统(实验)方法导致的误差呢?
这里就要设计到残差的概念。什么是残差呢?
残差(residual):又称剩余误差,是某一物理量与该物理量均值的差值,定义如下:
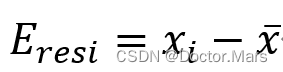
举例说明,期末考试老师给某班级学生试卷评分,该班级分数残差的散点图一定是在y=0这条直线上下均匀分布的。
反过来,用剩余误差(残差)观察法可以检验出变值系统误差。如果残差大体上在y=0这条直线上下波动,正负相间,而且无明显变化规律时,则不考虑系统误差,如果误差有规律变化时,比如残差在散点图上方或下方大量分布,则认为存在系统误差。
在对本项目的热误差残差观测时,发现确实存在系统误差。在有了统计学知识的铺垫下,针对本项目的问题,开展优化方案。
1.绘制热误差残差散点图
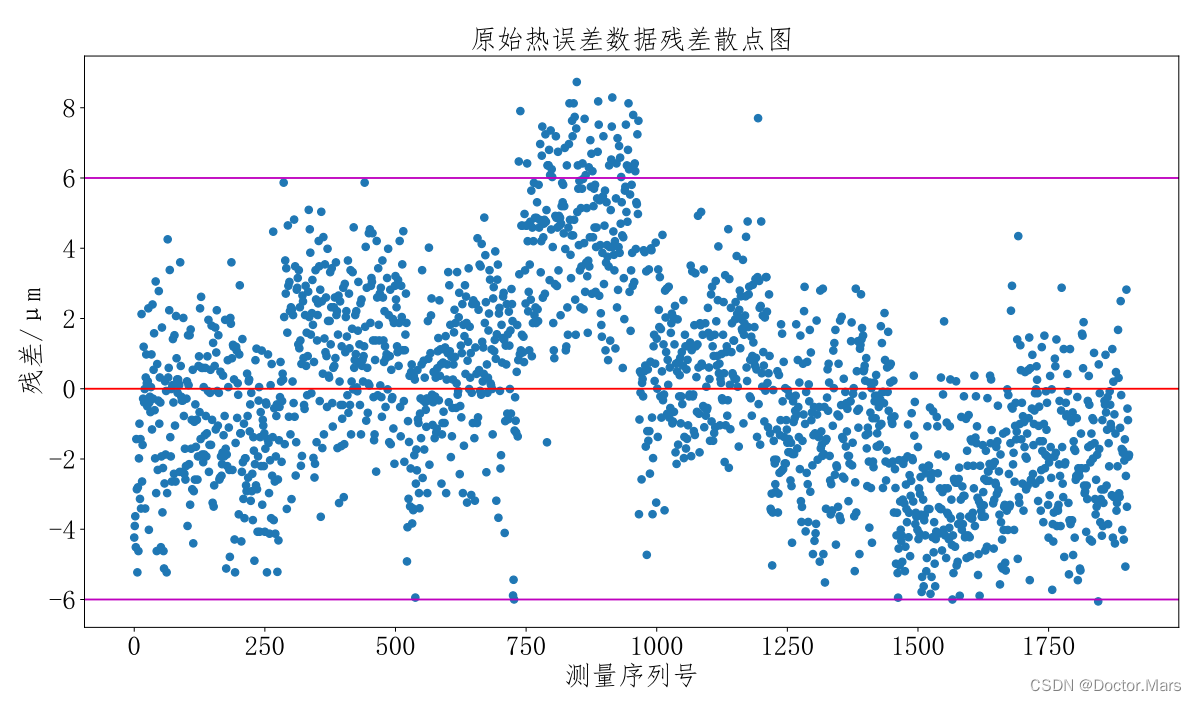
对本项目的热误差数据绘制散点图后,发现:[750,100]区间的残差主要分布在上方,这显然不符合统计学规律,其他区间的数据也有该种问题,很显然,实验过程中测得的热误差值带入了系统误差。
2.热误差值修正
对区间存在系统误差的热误差值加入修正值c,即可消除系统误差,公式如下。
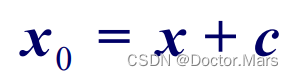
加入修正值后,重新绘制散点图。
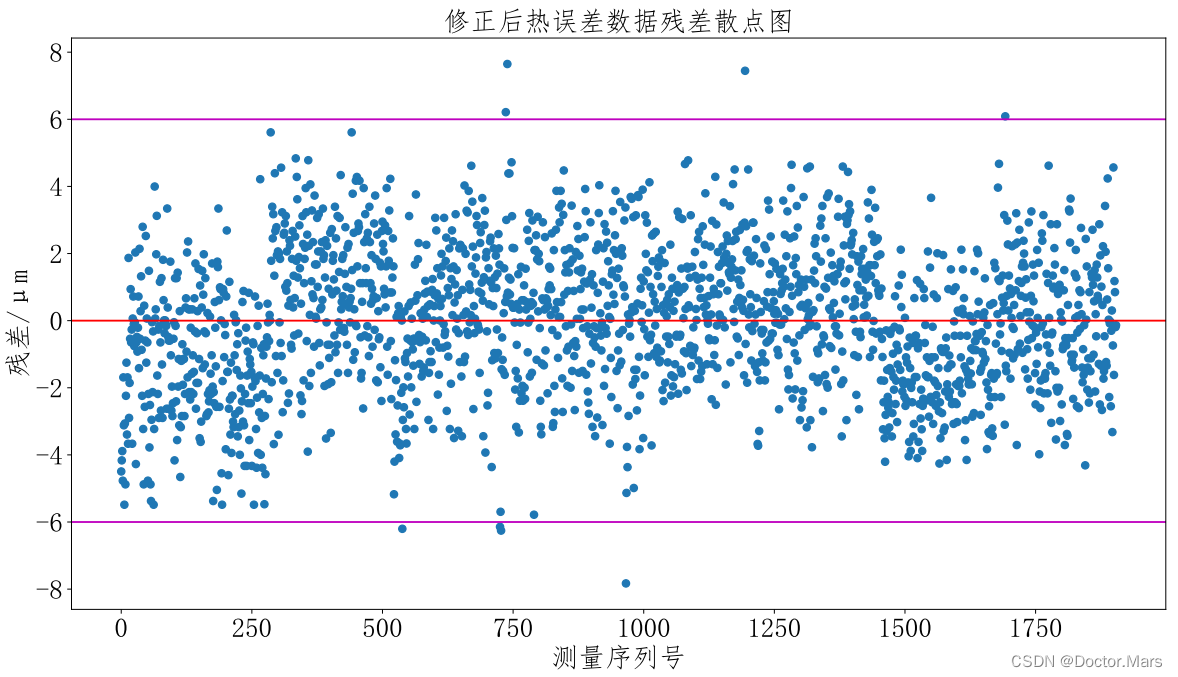
我们发现:修正后的散点图数值正负相间, 说明通过残差分析完美解决了系统误差问题。
接下来,我们做对比分析。
残差观测法前后,模型的对比分析
为了展示经过残差观察法优化前后模型预测精度的变化,做了两组对比试验,同样的数据集,同样的训练流程,训练完后保存各自的模型,在线测量20组数据,分别输入两个预测模型,预测的结果通过下图反映,我们发现,优化后的模型预测精度显著提升了,模型的适应性也大幅提升,这也就说明了,残差观察法很好的解决了系统误差问题。
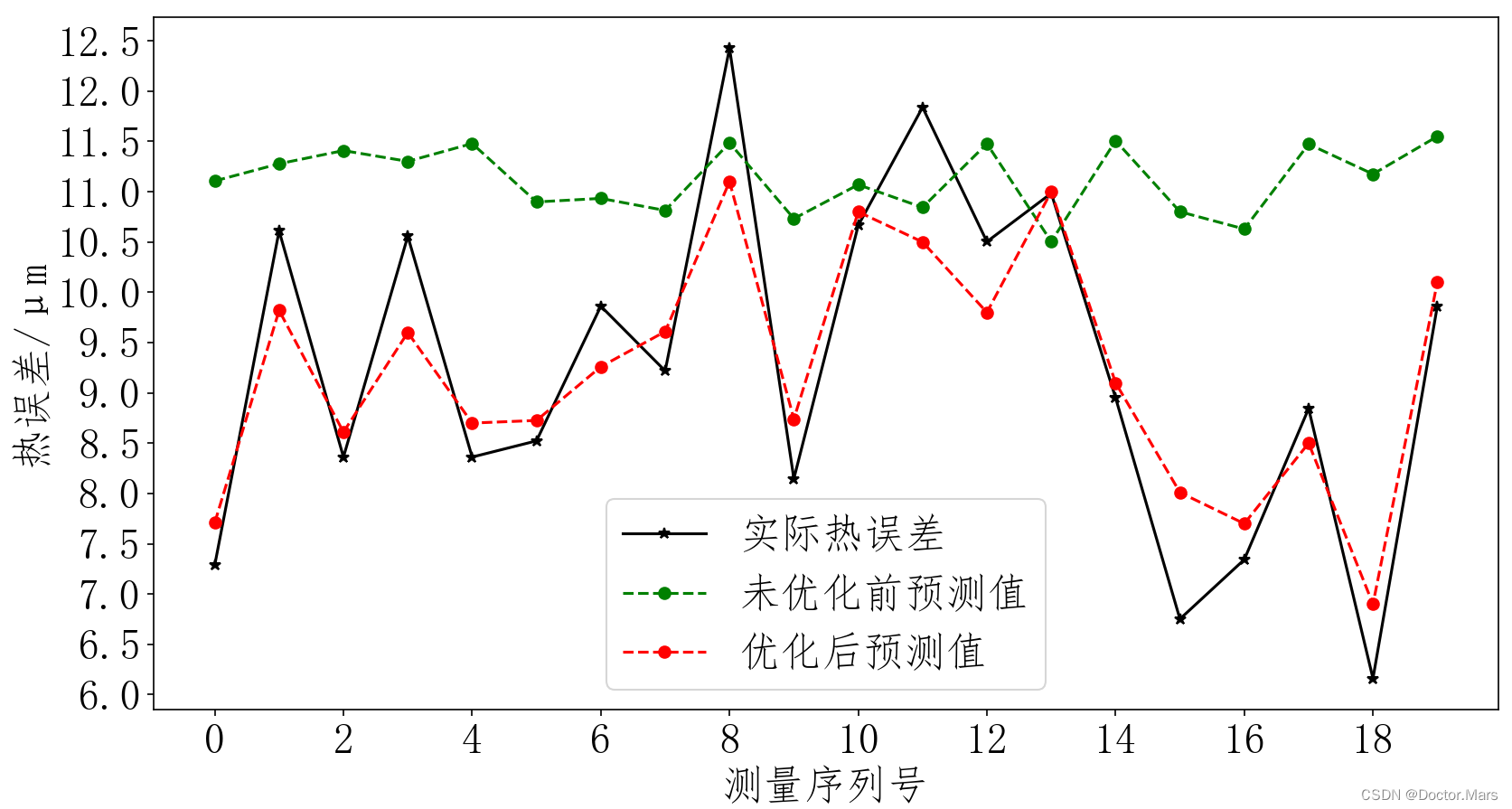
多回归模型的对比分析
除了上述对比试验之外,还做了其他回归模型的对比试验。
我们知道,热误差预测属于典型的非线性,多耦合性问题,传统的支持向量回归(Support Vector Regression, SVR)、随机森林回归(RandomForest Regression)模型和本项目所用的人工神经网络(Artificial Neural Network,ANN)对比,究竟有怎样的预测精度呢?这组对比实验我们也做了。
同样的数据集,采用三种模型,在线测量20组数据,预测结果如下,说明了,传统的回归模型在解决非线性问题上是没有ANN模型效果好的,所以,实际场景中的回归问题往往要通过神经网络进行预测。
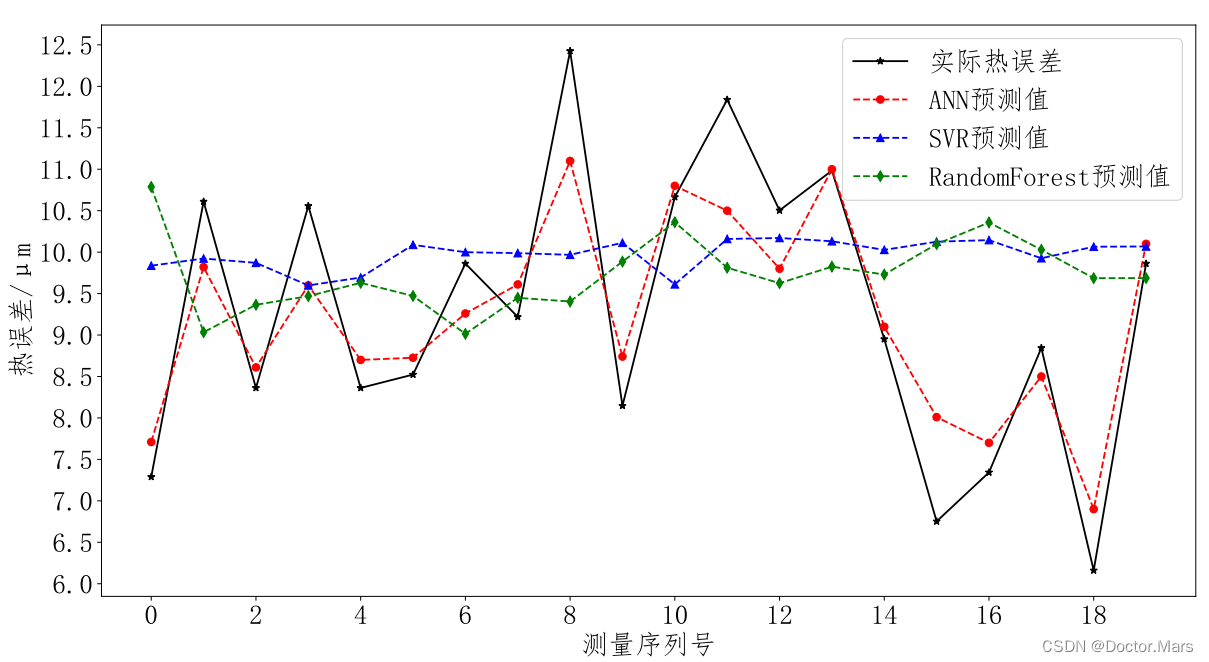
残差观察法作为统计学中的基础方法,在实际的应用中往往能发挥重要作用。
这篇博客,展示了统计学方法的重要性,一点小小的分析对于模型的精度提升至关重要。由此可见,深度学习不仅仅要求计算机知识,对于数学、统计学的要求也是有的。